Пример реестра моделей рабочей области
Примечание.
В этой документации рассматривается реестр моделей рабочей области. Azure Databricks рекомендует использовать модели в Unity Catalog. Модели в Unity Catalog обеспечивают централизованное управление моделями, кросс-доступ между рабочими областями, прослеживаемость и развертывание. Реестр моделей рабочей области будет нерекомендуем в будущем.
В этом примере показано, как использовать реестр моделей рабочей области для создания приложения машинного обучения, которое прогнозирует ежедневные выходные данные энергии ветряной фермы. В примере показано, как выполнить следующие задачи.
- отслеживание и регистрация моделей с помощью MLflow;
- регистрация моделей в реестре моделей;
- описание моделей и перехода между этапами версий моделей;
- интеграция зарегистрированных моделей с рабочими приложениями;
- поиск и обнаружение моделей в реестре моделей;
- Архивация и удаление моделей
В этой статье объясняется, как выполнить эти действия с помощью пользовательских интерфейсов и API-интерфейсов отслеживания MLflow и реестра моделей MLflow.
Сведения о записной книжке, в рамках которой все эти действия выполняются с использованием API-интерфейсов отслеживания и реестра, см. в разделе Пример записной книжки реестра моделей.
Загрузка набора данных, обучение модели и отслеживание с помощью функции отслеживания MLflow
Перед регистрацией модели в реестре необходимо обучить и зарегистрировать модель во время выполнения эксперимента. В этом разделе показано, как загрузить набор данных, обучить модель и зарегистрировать запуск обучения в MLflow.
Загрузка набора данных
Следующий код позволяет загрузить набор данных, содержащий данные о погоде и производстве электроэнергии ветряной электростанцией в США. Набор данных содержит компоненты wind direction,wind speed и air temperature, выборка которых выполняется каждые шесть часов (в 00:00, в 08:00 и в16:00), а также суммарные суточные данные производства электроэнергии (power) за несколько лет.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Обучение модели
Следующий код обучает нейронную сеть с помощью TensorFlow Keras для прогнозирования выходных данных на основе погодных возможностей в наборе данных. MLflow дает возможность отслеживать гиперпараметры, показатели производительности, исходный код и артефакты модели.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Регистрация модели и управление ею с помощью пользовательского интерфейса MLflow
В этом разделе рассматриваются следующие вопросы.
- создание новой зарегистрированной модели;
- изучение интерфейса реестра моделей;
- добавление описания модели;
- переход на другой этап для этой версии модели.
создание новой зарегистрированной модели;
Перейдите на боковую панель "Эксперимент MLflow", щелкнув Experiment iconзначок эксперимента в правой боковой панели записной книжки Azure Databricks.

Найдите MLflow Run, соответствующий сеансу обучения модели TensorFlow Keras, и откройте его в пользовательском интерфейсе запуска MLflow, щелкнув значок "Просмотр сведений о выполнении".
В пользовательском интерфейсе MLflow прокрутите страницу вниз до раздела артефактов и выберите каталог с именем model. Нажмите появившуюся кнопку регистрации модели.

Select создать новую модель из раскрывающегося меню и введите следующее имя модели:
power-forecasting-model.Щелкните Зарегистрировать. Будет зарегистрирована новая модель с именем
power-forecasting-modelи создана новая версия модели:Version 1.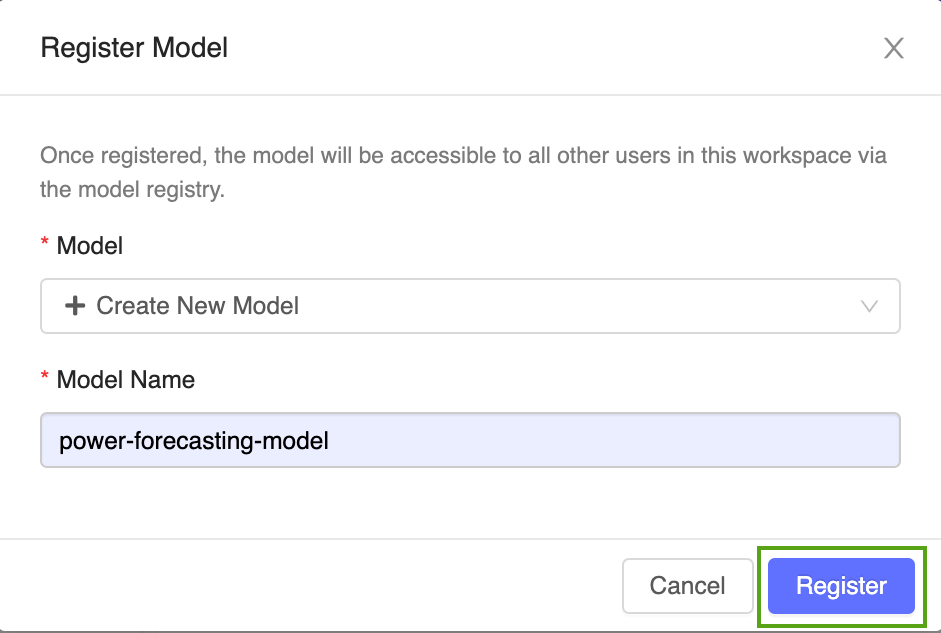
Через несколько минут в пользовательском интерфейсе MLflow отобразится ссылка на новую зарегистрированную модель. Щелкните эту ссылку, чтобы открыть новую версию модели в пользовательском интерфейсе реестра моделей.
изучение интерфейса реестра моделей;
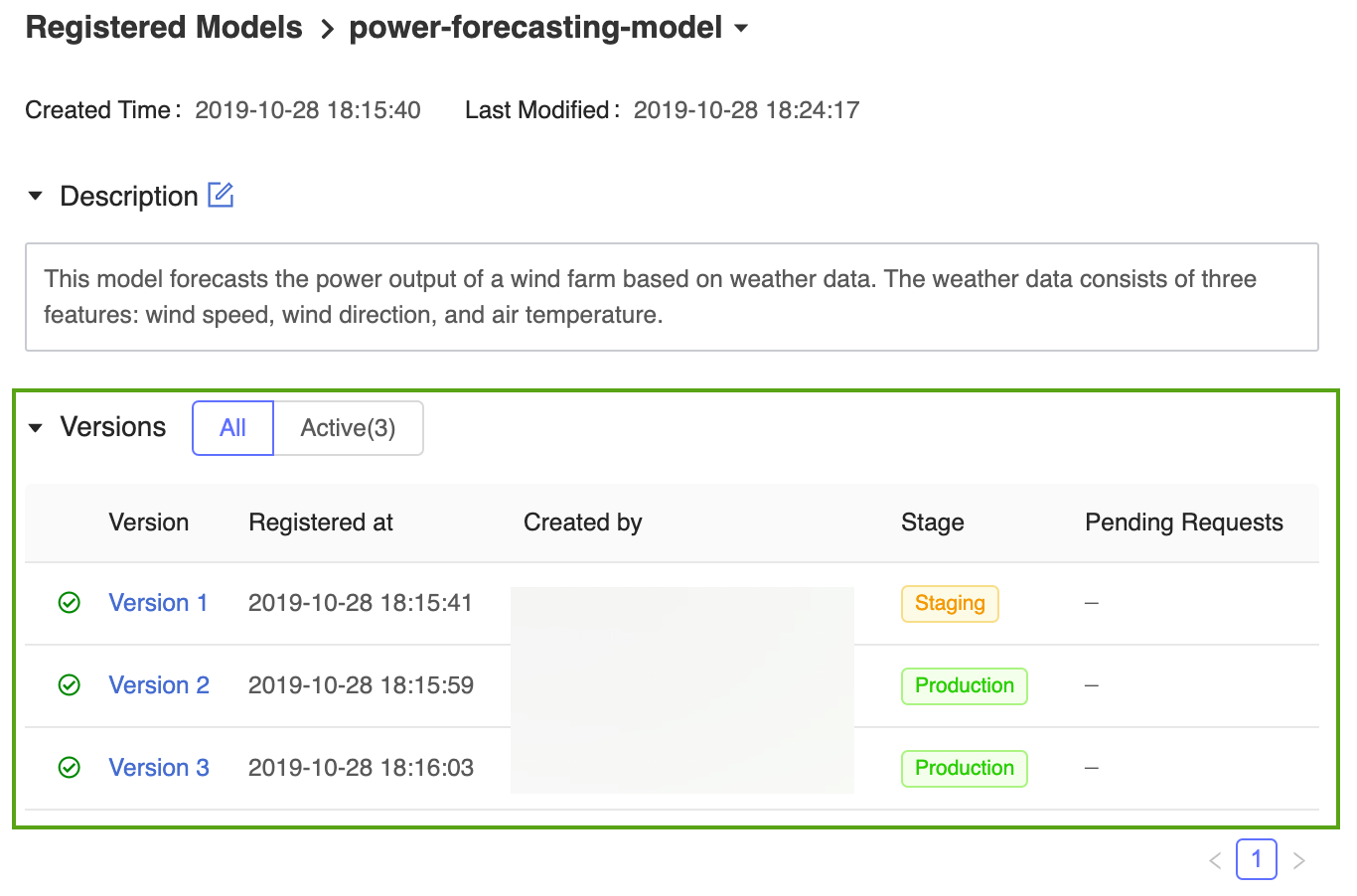
На странице версии модели в пользовательском интерфейсе реестра моделей MLflow содержатся сведения о Version 1 зарегистрированной модели прогнозирования, включая сведения о ее авторе, времени создания и текущем этапе.
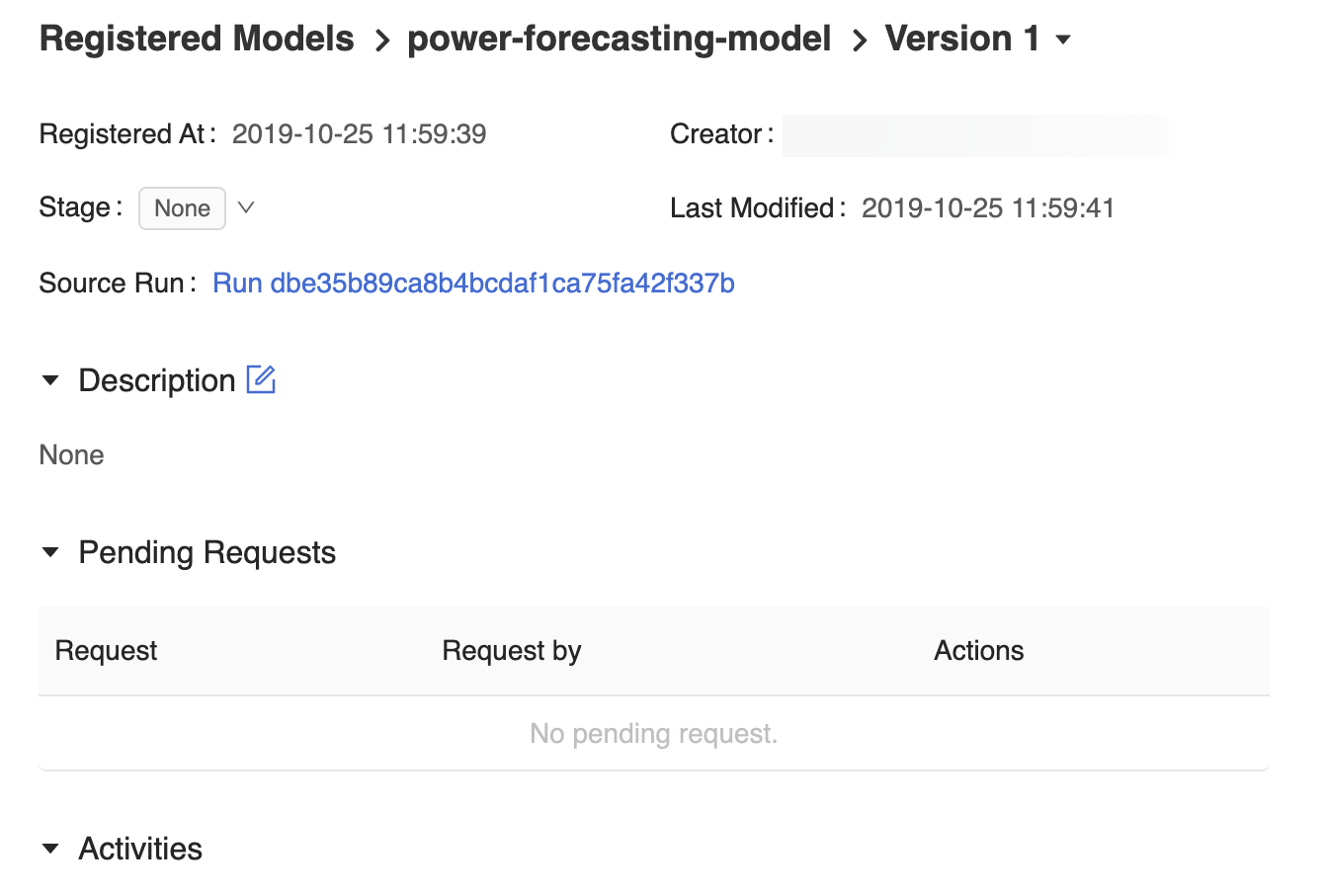
Кроме того, на странице версии модели предоставляется ссылка Source Run (Исходное выполнение), по которой открывается выполнение MLflow, использованное для создания модели в пользовательском интерфейсе выполнения MLflow. В пользовательском интерфейсе выполнения MLflow можно получить доступ к ссылке на исходную записную книжку, чтобы просмотреть моментальный снимок записной книжки Azure Databricks, которая использовалась для обучения модели.


Чтобы вернуться к реестру моделей MLflow, щелкните ![]() "Модели " на боковой панели.
"Модели " на боковой панели.
На домашней странице реестра моделей MLflow отображается list всех зарегистрированных моделей в рабочей области Azure Databricks, включая их версии и этапы.
Щелкните ссылку power-forecasting-model, чтобы открыть страницу зарегистрированных моделей, на которой отображаются все версии модели прогнозирования.
добавление описания модели;
Вы можете добавить описания к сведениям о зарегистрированных моделях и версиях моделей. Описания зарегистрированных моделей полезны для записи информации, которая относится к нескольким версиям модели (например, общие сведения о проблеме моделирования и наборе данных). Описания версий модели полезны для получения подробных сведений об уникальных атрибутах определенной версии модели (например, о методологии и алгоритме, используемом для разработки модели).
Добавьте высокоуровневое описание к сведениям о зарегистрированной модели прогнозирования производства электроэнергии.
 Щелкните значок и введите следующее описание:
Щелкните значок и введите следующее описание:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.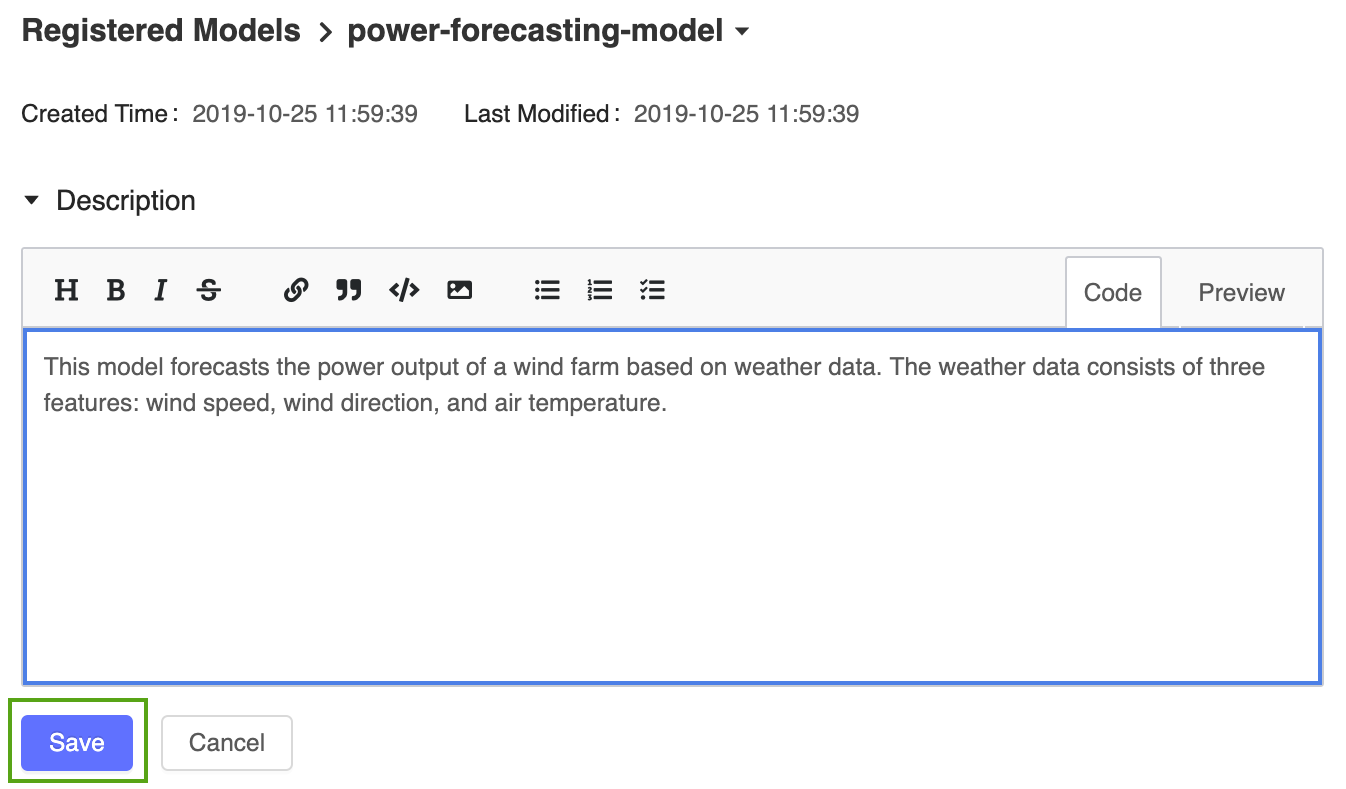
Нажмите кнопку Сохранить.
Щелкните ссылку Version 1 (Версия 1) на странице зарегистрированных моделей, чтобы вернуться к странице версий моделей.
-
Щелкните значок и введите следующее описание:
This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.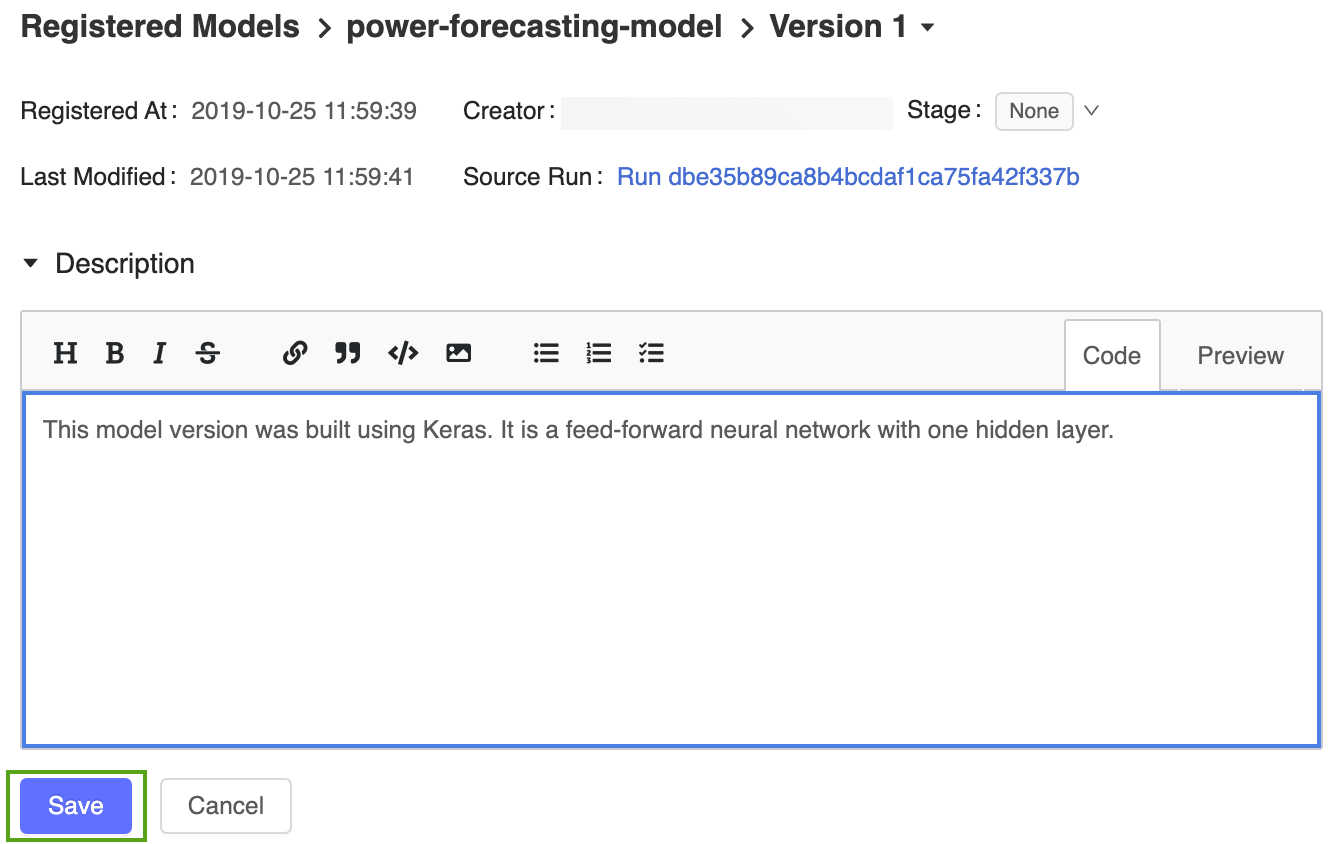
Нажмите кнопку Сохранить.
переход на другой этап для этой версии модели.
Реестр моделей MLflow определяет несколько этапов моделей: Нет, Промежуточная среда, Рабочая среда и Archived. Каждый этап имеет уникальное значение. Например, этап Промежуточная среда предназначен для тестирования модели, а этап Рабочая среда — для тех моделей, которые уже прошли все процессы тестирования и проверки, а теперь развернуты в приложениях.
Нажмите кнопку "Этап", чтобы отобразить list доступных этапов модели и доступные варианты перехода между этапами.
Select переход на> производство и нажмите ОК на этапе подтверждения перехода window для перехода модели на производство.

Когда версия модели будет переведена на этап Рабочая среда, сведения о текущем этапе отобразятся в пользовательском интерфейсе, а запись будет добавлена в журнал действий для регистрации перехода.


Реестр моделей MLflow позволяет использовать несколько версий модели на одном и том же этапе. При ссылке на модель по этапам в реестре моделей используется последняя версия модели (версия модели с самым большим значением идентификатора версии). На странице зарегистрированных моделей отображаются все версии конкретной модели.
Регистрация модели и управление ею с помощью API MLflow
В этом разделе рассматриваются следующие вопросы.
- программное определение имени модели;
- Регистрация модели.
- добавление описаний модели и версии модели с помощью API;
- перевод версии модели и получение сведений с помощью API;
Программное определение имени модели
Теперь, когда модель зарегистрирована и переведена на этап Рабочая среда, вы можете ссылаться на нее с помощью программных API-интерфейсов MLflow. Определите имя зарегистрированной модели следующим образом:
model_name = "power-forecasting-model"
Регистрация модели.
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Добавление описаний модели и версии модели с помощью API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Перевод версии модели и получение сведений с помощью API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Загрузка версий зарегистрированной модели с помощью API
Компонент моделей MLflow определяет функции для загрузки моделей с нескольких платформ машинного обучения. Например, mlflow.tensorflow.load_model() используется для загрузки моделей TensorFlow, сохраненных в формате MLflow, и mlflow.sklearn.load_model() используется для загрузки моделей scikit-learn, сохраненных в формате MLflow.
С помощью этих функций можно загружать модели из реестра моделей MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Прогнозирование объема произведенной электроэнергии с помощью модели для рабочей среды
В этом разделе модель для рабочей среды используется для вычисления данных прогноза погоды для ветряной электростанции. Приложение forecast_power() загружает последнюю версию модели прогнозирования с указанного этапа и использует и п прогнозирует с ее помощью объем произведенной электроэнергии на следующие пять дней.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Создание новой версии модели
Классические методы машинного обучения также эффективны для прогнозирования производства электроэнергии. Следующий код позволяет обучить модель случайного леса с помощью scikit-learn и зарегистрировать ее в реестре моделей MLflow с помощью функции mlflow.sklearn.log_model().
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Получение идентификатора новой версии модели с помощью функции поиска в реестре моделей MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Добавление описания к сведениям о новой версии модели
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Перевод новой версии модели на этап "Промежуточная среда" и тестирование модели
Перед развертыванием модели в приложении для рабочей среды рекомендуется протестировать ее в промежуточной среде. Следующий код позволяет перевести новую версию модели на этап Промежуточная среда и оценить ее производительность.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Развертывание новой версии модели в рабочей среде
После проверки того, хорошо ли новая версия модели работает в промежуточной среде, следующий код переводит модель на этап Рабочая среда и использует тот же код приложения из раздела Прогнозирование объема произведенной электроэнергии с помощью модели для рабочей среды для создания прогноза объема произведенной электроэнергии.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Теперь на этапе Рабочая среда есть две версии модели прогнозирования: версия модели, обученная в модели Keras, и версия, обученная в scikit-learn.

Примечание.
При ссылке на модель по этапам в реестре моделей автоматически используется последняя версия модели для рабочей среды. Это позволяет update производственные модели, не изменяя код приложения.
Архивация и удаление моделей
Если версия модели больше не используется, ее можно заархивировать или удалить. Кроме того, вы можете полностью удалить зарегистрированную модель. При этом удаляются все связанные с ней версии.
Архивация Version 1 модели прогнозирования производства электроэнергии
Заархивируйте Version 1 модели прогнозирования производства электроэнергии, так как она больше не используется. Вы можете архивировать модели в пользовательском интерфейсе реестра моделей MLflow или через API MLflow.
Архивация Version 1 в пользовательском интерфейсе MLflow
Чтобы заархивировать модель Version 1 прогнозирования производства электроэнергии, сделайте следующее:
Откройте соответствующую страницу версии модели в пользовательском интерфейсе реестра моделей MLflow:

Нажмите кнопку Этап, selectПереход в -> Архивированные:
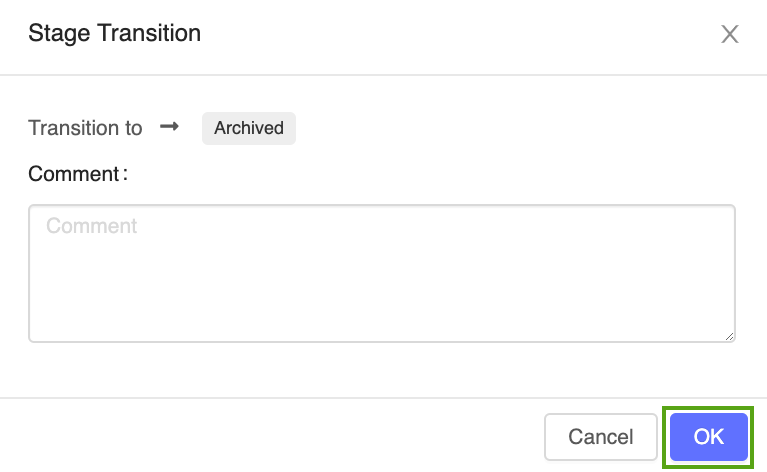
Нажмите ОК для подтверждения перехода этапа window.

Архивация Version 1 с помощью API MLflow
Следующий код позволяет с помощью функции MlflowClient.update_model_version() заархивировать Version 1 модели прогнозирования производства электроэнергии.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Удаление Version 1 модели прогнозирования производства электроэнергии
Для удаления версий модели также можно использовать пользовательский интерфейс MLflow или API MLflow.
Предупреждение
Удаление версии модели нельзя отменить.
Удаление Version 1 в пользовательском интерфейсе MLflow
Чтобы удалить модель Version 1 прогнозирования производства электроэнергии, сделайте следующее:
Откройте соответствующую страницу версии модели в пользовательском интерфейсе реестра моделей MLflow.
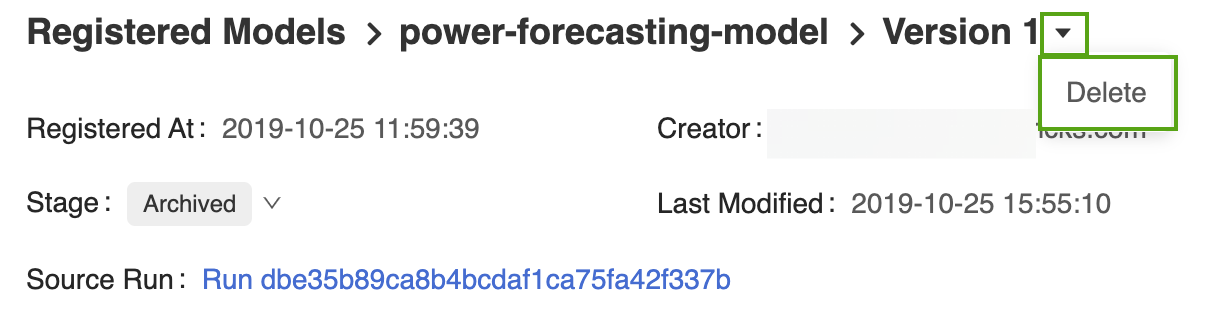
Select стрелку раскрывающегося списка рядом с версией identifier и щелкните Удалить.
Удаление Version 1 с помощью API MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Удаление модели с помощью API MLflow
Сначала необходимо перейти со всех остальных этапов версий модели на этапы в Нет или Архивировано.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)