Обучение моделей рекомендаций
В этой статье приведены два примера моделей рекомендаций на основе глубокого обучения в Azure Databricks. По сравнению с традиционными моделями рекомендаций модели глубокого обучения могут достичь более качественных результатов и масштабирования до больших объемов данных. По мере развития этих моделей Databricks предоставляет платформу для эффективной подготовки крупномасштабных моделей рекомендаций, способных обрабатывать сотни миллионов пользователей.
Общая система рекомендаций может рассматриваться как воронка с этапами, показанными на схеме.
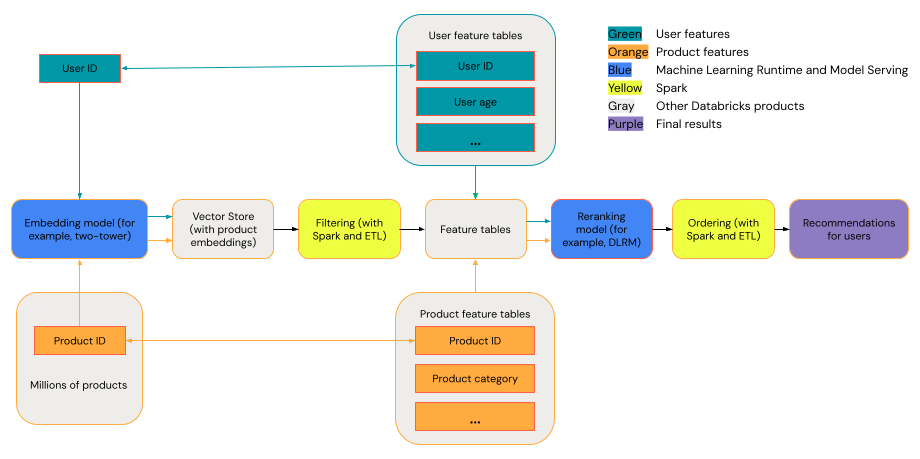
Некоторые модели, такие как модель с двумя башнями, лучше работают как модели извлечения. Эти модели меньше и могут эффективно работать с миллионами точек данных. Другие модели, такие как DLRM или DeepFM, лучше выполняются при повторном выполнении моделей. Эти модели могут принимать больше данных, более крупные и могут предоставлять подробные рекомендации.
Требования
Databricks Runtime 14.3 LTS ML
Инструменты
Примеры, приведенные в этой статье, иллюстрируют следующие средства:
- TorchDistributor: TorchDistributor — это платформа, которая позволяет выполнять обучение модели PyTorch большого масштаба в Databricks. Он использует Spark для оркестрации и может масштабироваться до такого количества GPU, как и в кластере.
- Mosaic StreamingDataset: StreamingDataset повышает производительность и масштабируемость обучения для больших наборов данных в Databricks с помощью таких функций, как предварительная выборка и переключение.
- MLflow: Mlflow позволяет отслеживать параметры, метрики и контрольные точки модели.
- TorchRec: Современные системы рекомендаций используют внедренные таблицы подстановки для обработки миллионов пользователей и элементов для создания высококачественных рекомендаций. Более крупные размеры внедрения повышают производительность модели, но требуют существенной памяти GPU и многопроцессорных настроек GPU. TorchRec предоставляет платформу для масштабирования моделей рекомендаций и таблиц подстановки в нескольких GPU, что делает его идеальным для больших внедрения.
Пример. Рекомендации по фильмам с использованием архитектуры модели с двумя башнями
Модель с двумя башнями предназначена для обработки крупномасштабных задач персонализации путем обработки данных пользователей и элементов отдельно перед объединением их. Он способен эффективно создавать сотни или тысячи достойных рекомендаций по качеству. Модель обычно ожидает три входных данных: функция user_id, функция product_id и двоичная метка, определяющая, был ли <пользователь, взаимодействие с продуктом> положительным (пользователь приобрел продукт) или отрицательным (пользователь дал продукту одну звездочку). Выходные данные модели внедряются как для пользователей, так и для элементов, которые затем обычно объединяются (часто с помощью точечных продуктов или сходства) для прогнозирования взаимодействия с пользовательским элементом.
Так как модель с двумя башнями обеспечивает внедрение для пользователей и продуктов, вы можете поместить эти внедрения в векторную базу данных, например Databricks Vector Store, и выполнять операции сходства и поиска, подобные пользователям и элементам. Например, можно поместить все элементы в векторное хранилище, а для каждого пользователя запросить векторное хранилище, чтобы найти первые сотни элементов, внедрение которых похожи на пользователей.
В следующем примере записная книжка реализует обучение модели с двумя башнями с помощью набора данных "Обучение из наборов элементов" для прогнозирования вероятности того, что пользователь будет оценивать определенный фильм высоко. В ней используется Набор Данных Для потоковой передачи Мозаики для распределенной загрузки данных, TorchDistributor для обучения распределенной модели и mlflow для отслеживания и ведения журнала моделей.
Записная книжка модели с двумя башнями
Эта записная книжка также доступна в Databricks Marketplace: записная книжка с двумя башнями модели
Примечание.
- Входные данные для двухбашней модели чаще всего являются категориальными функциями user_id и product_id. Модель можно изменить для поддержки нескольких векторов функций для пользователей и продуктов.
- Выходные данные для модели с двумя башнями обычно являются двоичными значениями, указывающими, будет ли пользователь иметь положительное или отрицательное взаимодействие с продуктом. Модель можно изменить для других приложений, таких как регрессия, классификация нескольких классов и вероятности для нескольких действий пользователей (например, увольнение или покупка). Сложные выходные данные следует тщательно реализовать, так как конкурирующие цели могут снизить качество внедрения, созданных моделью.
Пример. Обучение архитектуры DLRM с помощью искусственного набора данных
DLRM — это архитектура нейронной сети, разработанная специально для персонализации и рекомендаций. Он объединяет категориальные и числовые входные данные для эффективного моделирования взаимодействия с элементами пользователя и прогнозирования предпочтений пользователей. DLRM обычно ожидают входных данных, которые включают как разреженные функции (например, идентификатор пользователя, идентификатор элемента, географическое расположение или категорию продуктов), так и плотные функции (например, возраст пользователя или цена на элемент). Выходные данные DLRM обычно являются прогнозом взаимодействия с пользователем, например коэффициентами щелчка или вероятностью покупки.
DLRMs предлагает высоко настраиваемую платформу, которая может обрабатывать крупномасштабные данные, что делает его подходящим для сложных задач рекомендаций в различных доменах. Так как это более большая модель, чем двухбашенный архитектуры, эта модель часто используется на этапе повторного использования.
В следующем примере записная книжка создает модель DLRM для прогнозирования двоичных меток с помощью плотных (числовых) функций и разреженных (категориальных) функций. В нем используется искусственный набор данных для обучения модели, набора Данных Mosaic StreamingDataset для распределенной загрузки данных, TorchDistributor для обучения распределенной модели и Mlflow для отслеживания и ведения журнала моделей.
Записная книжка DLRM
Эта записная книжка также доступна в Databricks Marketplace: записная книжка DLRM.
Сравнение двухбашенных моделей и моделей DLRM
В таблице приведены некоторые рекомендации по выбору используемой модели рекомендаций.
| Тип модели | Размер набора данных, необходимый для обучения | Размер модели | Поддерживаемые типы входных данных | Поддерживаемые типы вывода | Случаи использования |
|---|---|---|---|---|---|
| Две башни | Меньше | Меньше | Обычно две функции (user_id, product_id) | В основном двоичная классификация и внедрение поколений | Создание сотен или тысяч возможных рекомендаций |
| DLRM | Больше | Больше | Различные категориальные и плотные признаки (user_id, пол, geographic_location, product_id, product_category, ...) | Классификация нескольких классов, регрессия, другие | Точное извлечение (рекомендуется десятки важных элементов) |
В итоге модель с двумя башнями лучше всего используется для создания тысяч хороших рекомендаций по качеству очень эффективно. Примером могут быть рекомендации по фильмам от поставщика кабелей. Модель DLRM лучше всего используется для создания очень конкретных рекомендаций на основе дополнительных данных. Пример может быть розничным продавцом, который хочет представить клиенту меньшее количество товаров, которые они, скорее всего, приобрести.