Рабочие процессы LLMOps в Azure Databricks
Эта статья дополняет рабочие процессы MLOps в Databricks , добавляя сведения, относящиеся к рабочим процессам LLMOps. Дополнительные сведения см . в статье "Большая книга MLOps".
Как изменяется рабочий процесс MLOps для LLM?
LLMs — это класс моделей обработки естественного языка (NLP), которые значительно превзошли своих предшественников в размерах и производительности в различных задачах, таких как открытый ответ на вопросы, сводка и выполнение инструкций.
Разработка и оценка LLM отличаются некоторыми важными способами от традиционных моделей машинного обучения. В этом разделе кратко описаны некоторые ключевые свойства LLM и последствия для MLOps.
| Ключевые свойства LLM | Последствия для MLOps |
|---|---|
| LLM доступны во многих формах. — Общие собственные модели и модели OSS, к которым обращается доступ с помощью платных API. — вне полки открытый код модели, которые различаются от общих до конкретных приложений. — Пользовательские модели, которые были точно настроены для конкретных приложений. — Пользовательские предварительно обученные приложения. |
Процесс разработки: проекты часто разрабатываются постепенно, начиная с существующих, сторонних или открытый код моделей и заканчивая пользовательскими точно настроенными моделями. |
| Многие LLM принимают общие запросы естественного языка и инструкции в качестве входных данных. Эти запросы могут содержать тщательно разработанные запросы, чтобы вызвать нужные ответы. |
Процесс разработки: проектирование текстовых шаблонов для запроса LLM часто является важной частью разработки новых конвейеров LLM. Упаковка артефактов машинного обучения. Многие конвейеры LLM используют существующие конечные точки обслуживания LLM или LLM. Логика машинного обучения, разработанная для этих конвейеров, может сосредоточиться на шаблонах запросов, агентах или цепочках вместо самой модели. Артефакты машинного обучения, упакованные и продвигаемые в рабочую среду, могут быть этими конвейерами, а не моделями. |
| Многие модули LLM могут быть предоставлены запросы с примерами, контекстом или другими сведениями, которые помогут ответить на запрос. | Инфраструктура обслуживания. При увеличении запросов LLM с контекстом можно использовать дополнительные средства, такие как векторные базы данных для поиска соответствующего контекста. |
| Сторонние API предоставляют собственные и открытые модели. | управление API: Использование централизованного управления API обеспечивает возможность легко переключаться между поставщиками API. |
| LLM — это очень большие модели глубокого обучения, часто начиная от гигабайтов до сотен гигабайтов. |
Инфраструктура обслуживания: для обслуживания моделей в режиме реального времени могут потребоваться графические процессоры, а также быстрое хранилище для моделей, которые должны быть загружены динамически. Компромиссы по затратам и производительности: поскольку для более крупных моделей требуется больше вычислений и более дорогих для обслуживания, могут потребоваться методы сокращения размера модели и вычислений. |
| LLM трудно оценить с помощью традиционных метрик машинного обучения, так как часто нет единого "правильного" ответа. | Человеческая обратная связь: человеческая обратная связь важна для оценки и тестирования LLM. Вы должны включить отзывы пользователей непосредственно в процесс MLOps, в том числе для тестирования, мониторинга и последующей тонкой настройки. |
Общие особенности между MLOps и LLMOps
Многие аспекты процессов MLOps не изменяются для LLM. Например, следующие рекомендации также применяются к LLM:
- Используйте отдельные среды для разработки, промежуточной и рабочей среды.
- Использовать Git для управления версиями.
- Управление разработкой моделей с помощью MLflow и использование моделей в каталоге Unity для управления жизненным циклом модели.
- Храните данные в архитектуре lakehouse, используя таблицы Delta.
- Существующая инфраструктура CI/CD не должна требовать никаких изменений.
- Модульная структура MLOps остается той же, что и конвейеры для создания признаков, обучения моделей, вывода моделей и т. д.
Эталонные схемы архитектуры
В этом разделе используются два приложения на основе LLM, чтобы проиллюстрировать некоторые корректировки эталонной архитектуры традиционных MLOps. На схемах показана рабочая архитектура для 1) приложения для получения дополненного поколения (RAG) с помощью стороннего API и 2) приложения RAG с помощью локальной точно настроенной модели. На обеих схемах показана необязательная векторная база данных. Этот элемент можно заменить, напрямую запрашивая LLM через конечную точку обслуживания модели.
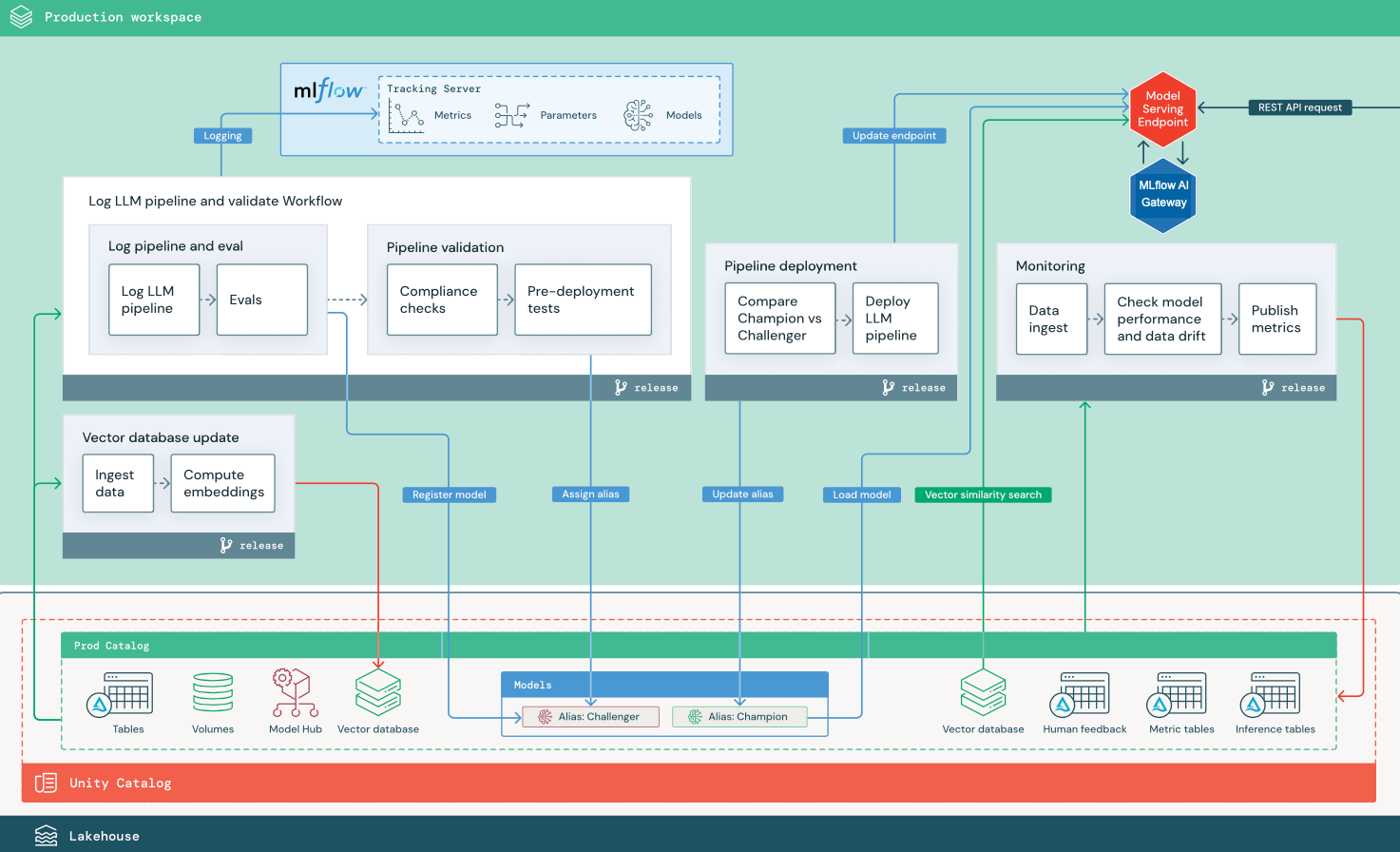
RAG с сторонним API LLM
На схеме показана рабочая архитектура для приложения RAG, подключающегося к стороннему API LLM с помощью Databricks External Models.
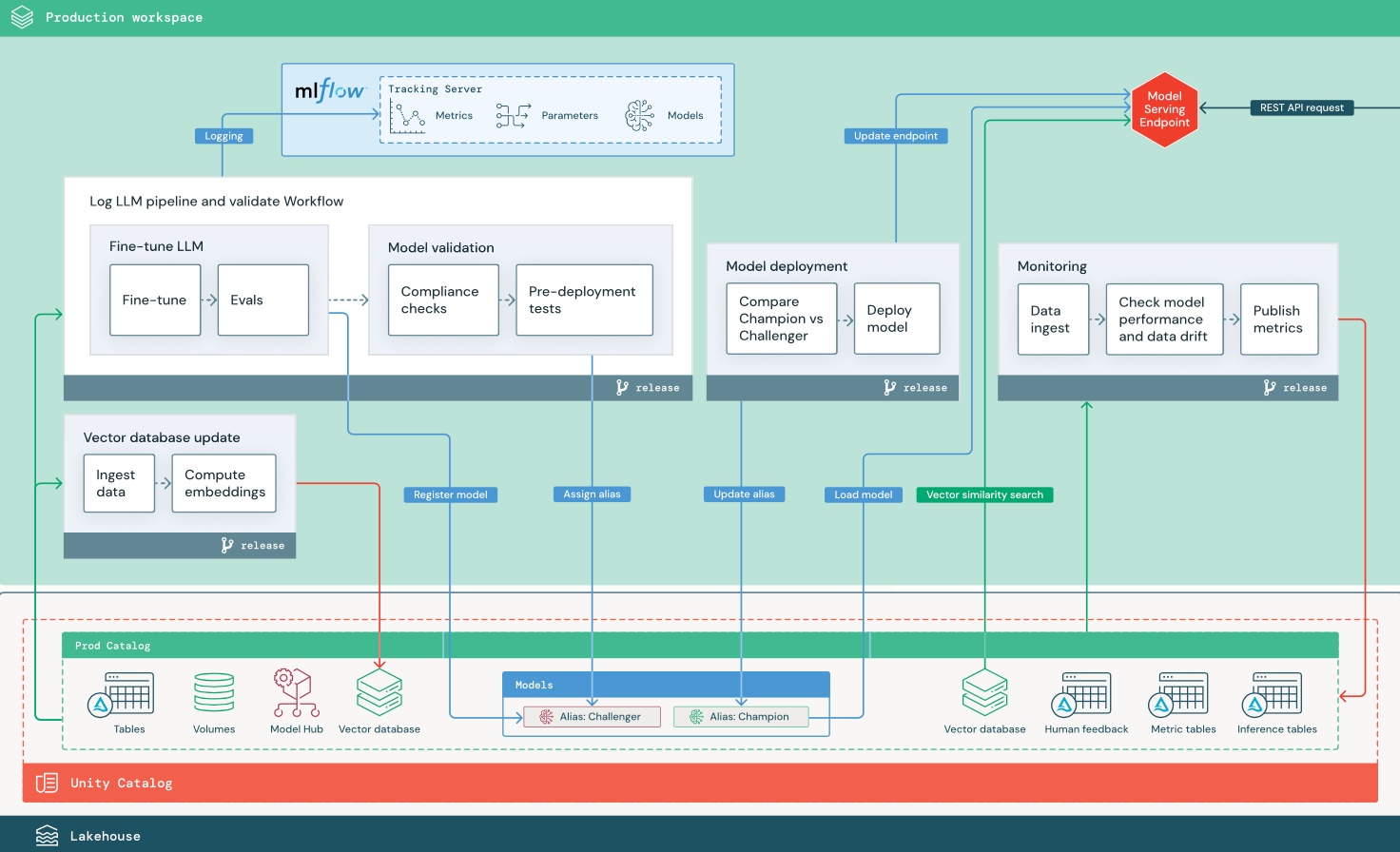
RAG с точно настроенной моделью открытый код
На схеме показана рабочая архитектура для приложения RAG, которое настраивает модель открытый код.
Изменения LLMOps в рабочей архитектуре MLOps
В этом разделе рассматриваются основные изменения эталонной архитектуры MLOps для приложений LLMOps.
Центр моделей
Приложения LLM часто используют существующие предварительно обученные модели, выбранные из внутреннего или внешнего концентратора моделей. Модель можно использовать как есть или точно настроить.
Databricks включает в себя выбор высококачественных предварительно обученных базовых моделей в каталоге Unity и в Databricks Marketplace. Эти предварительно обученные модели можно использовать для доступа к возможностям искусственного интеллекта, что позволяет сэкономить время и затраты на создание собственных пользовательских моделей. Для получения подробной информации см. раздел предобученные модели в каталоге Unity и Marketplace.
Векторная база данных
Некоторые приложения LLM используют векторные базы данных для быстрого поиска сходства, например для предоставления контекста или знаний домена в запросах LLM. Databricks предоставляет встроенную функцию поиска векторов, которая позволяет использовать любую таблицу Delta в каталоге Unity в качестве векторной базы данных. Индекс векторного поиска автоматически синхронизируется с таблицей Delta. Дополнительные сведения см. в разделе "Векторный поиск".
Вы можете создать артефакт модели, который инкапсулирует логику для получения информации из векторной базы данных и предоставляет возвращаемые данные в качестве контекста llM. Затем можно записать модель с помощью вкуса модели MLflow LangChain или PyFunc.
Точное настройка LLM
Так как модели LLM являются дорогостоящими и трудоемкими для создания с нуля, приложения LLM часто настраивают существующую модель для повышения производительности в определенном сценарии. В эталонной архитектуре развертывание точной настройки и модели представлены в виде отдельных заданий Databricks. Проверка точно настроенной модели перед развертыванием часто является ручным процессом.
Databricks предоставляет базовую настройку модели, которая позволяет использовать собственные данные для настройки существующего LLM для оптимизации производительности для конкретного приложения. Дополнительные сведения см. в разделе "Тонкое настройка модели Foundation".
Обслуживание модели
В RAG с помощью сценария сторонних API важное изменение архитектуры заключается в том, что конвейер LLM выполняет внешние вызовы API, от конечной точки обслуживания модели до внутренних или сторонних API LLM. Это повышает сложность, потенциальную задержку и дополнительное управление учетными данными.
Databricks предоставляет службу модели ИИ Для Мозаики, которая предоставляет унифицированный интерфейс для развертывания, управления и запроса моделей ИИ. Дополнительные сведения см. в разделе "Мозаичная модель ИИ", обслуживающая модель.
Человеческая обратная связь в мониторинге и оценке
Циклы обратной связи человека важны в большинстве приложений LLM. Человеческая обратная связь должна управляться, как и другие данные, в идеале включаемые в мониторинг на основе почти потоковой передачи в режиме реального времени.
Приложение проверки агента ИИ Мозаики помогает собрать отзывы от рецензентов. Дополнительные сведения см. в разделе Получение отзывов о качестве агентского приложения.