API модели предоставленной пропускной способности
В этой статье показано, как развертывать модели с помощью API Foundation Model с зарезервированной пропускной способностью. Databricks рекомендует выделенную пропускную способность для производственных рабочих нагрузок и обеспечивает оптимизированную инференцию для базовых моделей с гарантиями производительности.
Что такое подготовленная пропускная способность?
Выделенная пропускная способность относится к количеству единиц запроса, которые можно отправить в конечную точку одновременно. Конечные точки с заданной пропускной способностью — это выделенные конечные точки, настроенные на определенный диапазон токенов в секунду, которые можно отправить в конечную точку.
Дополнительные сведения см. в следующих ресурсах:
- Что означает маркеры в секунду в подготовленной пропускной способности?
- Проводите собственный бенчмаркинг конечных точек LLM
Список поддерживаемых архитектур моделей для подготовленных конечных точек пропускной способности см. в подготовленных конечных точек пропускной способности.
Требования
См. требования . Сведения о развертывании точно настроенных базовых моделей см. в статье Развертывание точно настроенных моделей фундамента.
[Рекомендуется] Развертывание базовых моделей из каталога Unity
Важный
Эта функция доступна в общедоступной предварительной версии.
Databricks рекомендует использовать базовые модели, предварительно установленные в каталоге Unity. Эти модели можно найти под номером system в каталоге и в схеме ai (system.ai).
Чтобы развернуть базовую модель, выполните приведенные действия.
- Перейдите к
system.aiв обозревателе каталогов. - Щелкните имя модели для развертывания.
- На странице модели нажмите кнопку Запустить эту модель.
- Откроется страница Создание конечной точки обслуживания. См. раздел Создание конечной точки с заданной пропускной способностью, используя пользовательский интерфейс.
Развертывание базовых моделей из Databricks Marketplace
Кроме того, можно установить базовые модели в каталог Unity из Databricks Marketplace.
Чтобы найти семейство моделей, перейдите на страницу модели, затем выберите Получить доступ и введите учетные данные для входа, чтобы установить модель в каталог Unity.
После установки модели в каталог Unity можно создать конечную точку обслуживания модели с помощью пользовательского интерфейса обслуживания.
Развертывание моделей DBRX
Databricks рекомендует обслуживать модель инструкции DBRX для рабочих нагрузок. Чтобы обслуживать модель DBRX Instruct, используя предоставленную пропускную способность, следуйте рекомендациям в [Рекомендуется] развернуть базовые модели из каталога Unity.
При обслуживании этих моделей DBRX выделенная пропускная способность поддерживает длину контекста до 16k.
Модели DBRX используют следующую системную строку по умолчанию для обеспечения релевантности и точности в ответах модели:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Развертывание точно настроенных базовых моделей
Если вы не можете использовать модели в схеме system.ai или устанавливать модели из Databricks Marketplace, можно развернуть настроенную основную модель, добавив её в Unity Catalog. В этом разделе и в следующих разделах показано, как настроить код для регистрации модели MLflow в каталоге Unity и создания подготовленной конечной точки пропускной способности с помощью пользовательского интерфейса или REST API.
Ознакомьтесь с установленными ограничениями пропускной способности для поддерживаемых моделей Meta Llama 3.1, 3.2 и 3.3 и их доступностью в регионах.
Требования
- Развертывание точно настроенных базовых моделей поддерживается только MLflow 2.11 или более поздней версии. Databricks Runtime 15.0 ML и выше предварительно устанавливает совместимую версию MLflow.
- Databricks рекомендует использовать модели в каталоге Unity для ускорения отправки и скачивания больших моделей.
Определение каталога, схемы и имени модели
Чтобы развернуть настраиваемую базовую модель, определите целевой каталог каталога Unity, схему и имя выбранной модели.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Зарегистрируйте свою модель
Чтобы включить выделенную пропускную способность для конечной точки модели, вы должны зарегистрировать вашу модель с использованием варианта MLflow transformers и указать аргумент task с соответствующим интерфейсом типа модели из следующих опций:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Эти аргументы указывают подпись API, используемую для конечной точки обслуживания модели. Для получения дополнительной информации об этих задачах и соответствующих схемах ввода/вывода обратитесь к документации по MLflow.
Ниже приведен пример регистрации языковой модели завершения текста, зарегистрированной с помощью MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Заметка
Если вы используете версию MLflow ниже 2.12, необходимо указать задачу в параметре metadata той же функции mlflow.transformer.log_model().
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Подготовленная пропускная способность также поддерживает базовые и крупные модели внедрения GTE. Ниже приведен пример логирования модели Alibaba-NLP/gte-large-en-v1.5, чтобы ее можно было предоставлять с выделенной пропускной способностью.
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
После входа модели в каталог Unity перейдите к создайте подготовленную конечную точку пропускной способности с помощью пользовательского интерфейса для создания конечной точки обслуживания модели с подготовленной пропускной способностью.
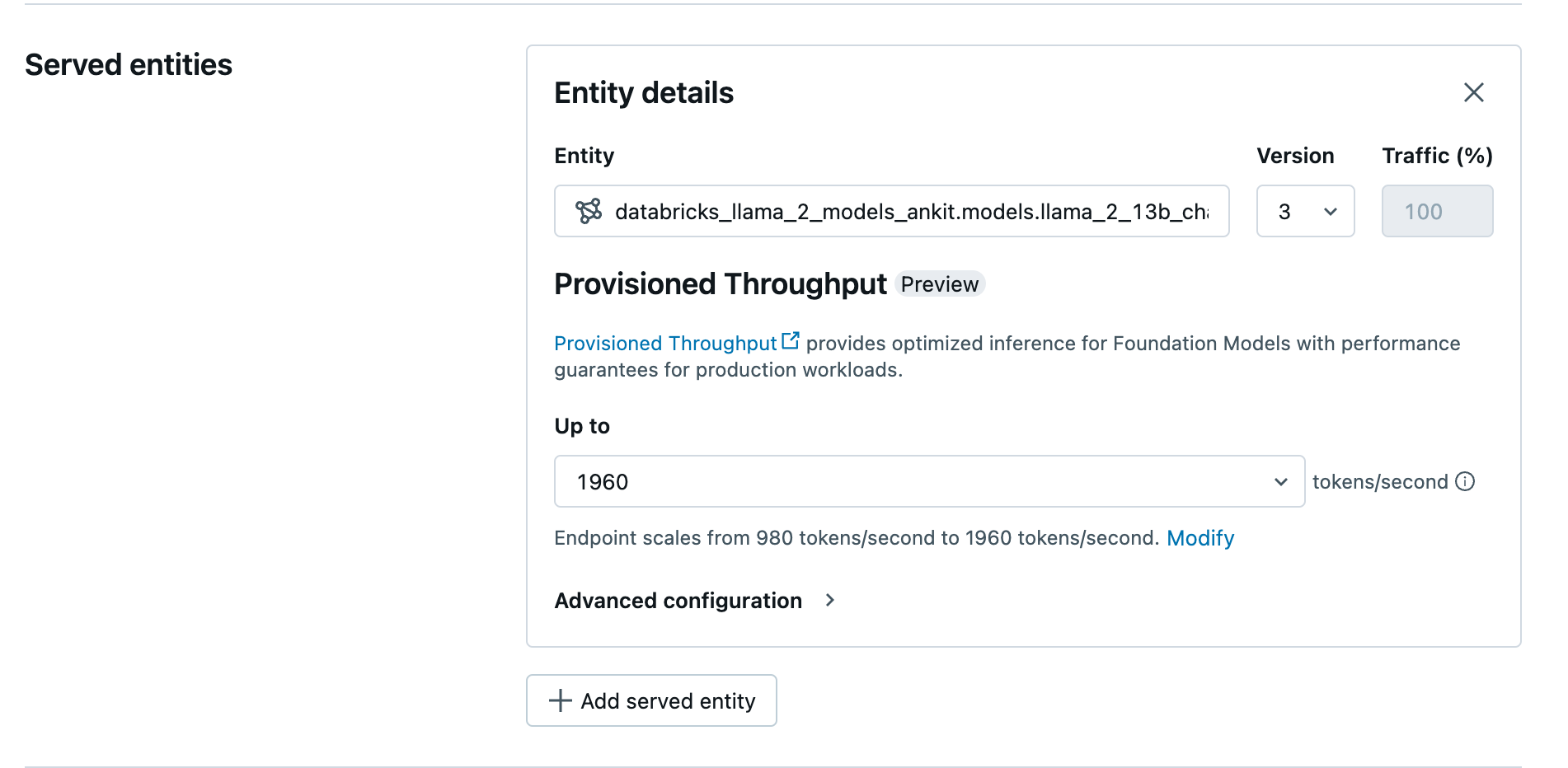
Создание подготовленной конечной точки пропускной способности с помощью пользовательского интерфейса
После регистрации модели в каталоге Unity создайте подготовленную конечную точку обслуживания пропускной способности, выполнив следующие действия:
- Перейдите к пользовательскому интерфейсу обслуживания в рабочей области.
- Выберите Создать конечную точку обслуживания.
- В поле сущности выберите вашу модель из каталога Unity. Для подходящих моделей пользовательский интерфейс для обслуживаемой сущности отображает экран предоставленной пропускной способности.
- В раскрывающемся списке до можно настроить максимальную пропускную способность маркеров в секунду для конечной точки.
- Подготовленные конечные точки пропускной способности автоматически масштабируются, поэтому вы можете выбрать Изменить, чтобы просмотреть минимальное количество токенов в секунду, до которого ваша конечная точка может снизить масштаб.
Создание подготовленной конечной точки пропускной способности с помощью REST API
Чтобы развернуть модель в подготовленном режиме пропускной способности с помощью REST API, необходимо указать в запросе поля min_provisioned_throughput и max_provisioned_throughput. Если вы предпочитаете Python, вы также можете создать конечную точку, используя SDK для развертывания MLflow.
Сведения о том, как определить подходящий диапазон подготовленной пропускной способности для модели, см. в разделах иотносительно получения этой информации.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Логарифмическая вероятность для задач завершения чата
Для задач завершения чата можно использовать параметр logprobs для предоставления логарифмической вероятности выбора токена при выборке в процессе генерации крупной языковой модели. Вы можете использовать logprobs для различных сценариев, включая классификацию, оценку неопределенности модели и выполнение метрик оценки. См. задачу чата для получения подробной информации о параметрах.
увеличение подготовленной пропускной способности
Выделенная пропускная способность доступна в виде приростов токенов в секунду, причем конкретные приросты зависят от модели. Чтобы определить подходящий диапазон для ваших потребностей, Databricks рекомендует использовать API сведений об оптимизации модели на платформе.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Ниже приведен пример ответа api:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Примеры ноутбуков
В следующих блокнотах показаны примеры создания API базовой модели с назначенной пропускной способностью.
Назначенная пропускная способность для блокнота модели GTE
Выделенная пропускная способность для ноутбука модели BGE
В следующей записной книжке показано, как скачать и зарегистрировать дистиллированную модель DeepSeek R1 в каталоге Unity, чтобы развернуть ее с помощью API-интерфейсов модели Foundation, подготовленных конечной точки пропускной способности.
Подготовленная пропускная способность для дистиллированной записной книжки модели DeepSeek R1
Ограничения
- Развертывание модели может завершиться сбоем из-за проблем с пропускной способностью GPU, что приводит к истечению времени ожидания во время создания или обновления конечной точки. Обратитесь к команде менеджеров по работе с клиентами Databricks, чтобы помочь устранить эту проблему.
- Автоматическое масштабирование для API моделей Foundation медленнее, чем обслуживание моделей на ЦП. Databricks рекомендует избыточное provisionig, чтобы избежать таймаутов запросов.
- GTE версии 1.5 (английский) не создает нормализованные внедрения.