Что означает диапазон токенов в секунду в предоставленной пропускной способности?
В этой статье описывается, как и почему Databricks измеряет токены в секунду для подготовленных нагрузок с пропускной способностью для API модели Foundation .
Производительность для больших языковых моделей (LLM) часто измеряется с точки зрения токенов в секунду. При настройке рабочих моделей, обслуживающих конечные точки, важно учитывать количество запросов, отправляемых приложению в конечную точку. Это помогает понять, нужно ли настроить конечную точку для масштабирования, чтобы не влиять на задержку.
При настройке диапазонов горизонтального масштабирования для конечных точек, развернутых с подготовленной пропускной способностью, Databricks было проще упорядочить вводимые в систему данные при помощи токенов.
Что такое токены?
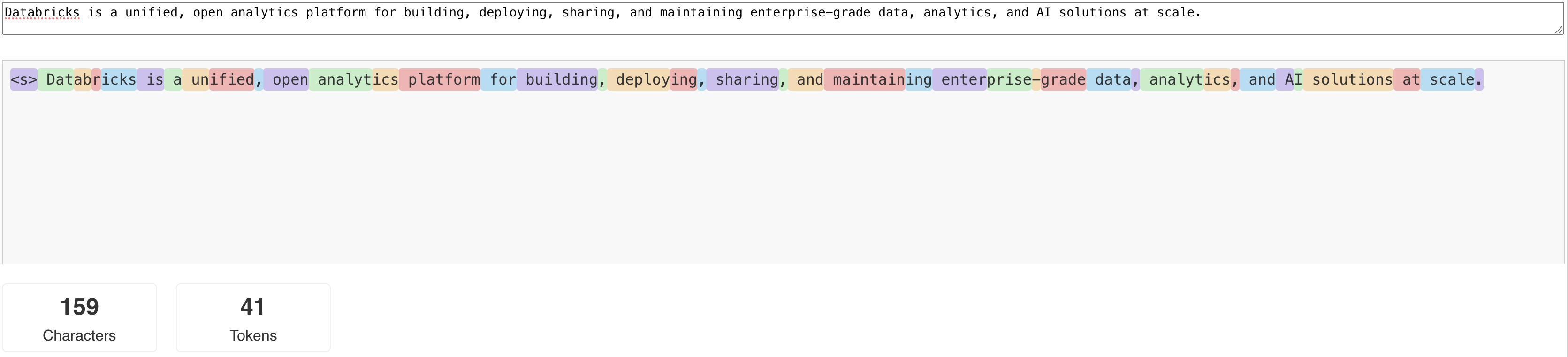
LLM считывают и генерируют текст в терминах так называемого токена . Маркеры могут быть словами или вложенными словами, а точные правила разделения текста на маркеры зависят от модели. Например, вы можете использовать онлайн-инструменты, чтобы узнать, как токенизатор Ламы преобразует слова в токены.
На следующей схеме показан пример того, как токенизатор модели Llama разбивает текст.
Зачем измерять производительность LLM с точки зрения токенов в секунду?
Обычно конечные точки обслуживания настраиваются на основе числа одновременных запросов в секунду (RPS). Однако время выполнения запроса ввода LLM различается в зависимости от количества передаваемых токенов и количества генерируемых токенов, что может привести к дисбалансу во времени обработки разных запросов. Таким образом, чтобы определить, каков должен быть масштаб вашей конечной точки, необходимо действительно измерить масштаб в терминах содержания вашего запроса — токенов.
Варианты использования различаются соотношениями входных и выходных токенов.
- различные длины входных контекстов: хотя некоторые запросы могут включать только несколько входных маркеров, например короткий вопрос, другие могут включать сотни или даже тысячи маркеров, например длинный документ для суммирования. Эта вариативность делает настройку конечной точки обслуживания только на основе RPS сложной, так как она не учитывает различные требования обработки различных запросов.
- различные длины выходных данных в зависимости от случая использования. Различные случаи использования для LLM могут привести к значительно различной длине выходных токенов. Создание выходных маркеров является наиболее интенсивной частью вывода LLM, поэтому это может значительно повлиять на пропускную способность. Например, сжатое изложение предполагает более короткие, лаконичные ответы, но создание текста, такое как написание статей или описаний продуктов, может создавать значительно более длинные ответы.
Как выбрать диапазон токенов в секунду для конечной точки?
Выделенные конечные точки с пропускной способностью настраиваются в терминах диапазона токенов в секунду, которые можно отправить в конечную точку. Конечная точка масштабируется вверх и вниз для обработки нагрузки вашего производственного приложения. Плата взимается за час, в зависимости от диапазона токенов в секунду, до которых конечная точка масштабируется.
Лучший способ определить диапазон токенов в секунду, который подойдет для вашей конечной точки с заранее подготовленной пропускной способностью в вашем случае использования, — это провести нагрузочный тест с репрезентативным набором данных. См. Проводите собственное тестирование конечных точек LLM.
Существует два важных фактора, которые следует учитывать:
- Как Databricks измеряет производительность LLM в токенах в секунду.
- Как работает автомасштабирование.
Как Databricks измеряет производительность LLM в токенах в секунду
Databricks проводит сравнительный анализ конечных точек для рабочей нагрузки, представляющей типичные задачи суммирования для случаев использования генерации с дополненным извлечением. В частности, рабочая нагрузка состоит из следующих элементов:
- 2048 входных маркеров
- 256 выходных маркеров
Диапазоны токенов, отображаемые , объединяют пропускную способность входных и выходных токенов и по умолчанию оптимизируются для балансировки пропускной способности и задержки.
Databricks предоставляет данные о производительности, показывающие, что пользователи могут отправлять столько токенов в секунду одновременно на конечную точку при размере пакета 1 на запрос. Это имитирует несколько запросов, поступающих в конечную точку одновременно, что более точно представляет, как вы фактически используете конечную точку в рабочей среде.
- Например, если подготовленная конечная точка обслуживания пропускной способности имеет заданную скорость 2304 токенов в секунду (2048 + 256), то один запрос с входными данными 2048 токенов и ожидаемый результат 256 токенов, как ожидается, займет около одной секунды.
- Аналогичным образом, если для скорости задано значение 5600, можно ожидать, что один запрос, с указанным выше числом входных и выходных маркеров, потребуется около 0,5 секунд для выполнения. Это конечная точка может обрабатывать два аналогичных запроса примерно в одну секунду.
Если рабочая нагрузка отличается от приведенной выше, задержка может отличаться в зависимости от указанной выше подготовленной пропускной способности. Как упоминалось ранее, создание большего объема выходных маркеров является более трудоемким, чем включение большего объема входных маркеров. Если вы выполняете пакетный инференс и хотите оценить продолжительность выполнения, вы можете вычислить среднее количество входных и выходных маркеров и сравнить с рабочей нагрузкой Databricks Benchmark выше.
- Например, если у вас есть 1000 строк, со средним числом входных токенов 3000 и средним числом выходных токенов 500, а также с подготовленной пропускной способностью 3500 токенов в секунду, это может занять больше 1000 секунд в общей сложности (одна секунда на строку) из-за того, что среднее количество ваших токенов больше, чем эталон Databricks.
- Аналогичным образом, если у вас есть 1000 строк, среднее количество входных данных из 1500 маркеров, среднее значение 100 маркеров и подготовленная пропускная способность 1600 маркеров в секунду, то может потребоваться меньше 1000 секунд (один секунду на строку) из-за меньше, чем тест Databricks.
Чтобы оценить идеальную подготовленную пропускную способность, необходимую для завершения вашей пакетной рабочей нагрузки вывода, можно использовать ноутбук в для выполнения пакетного вывода LLM с помощью ai_query
Как работает автомасштабирование
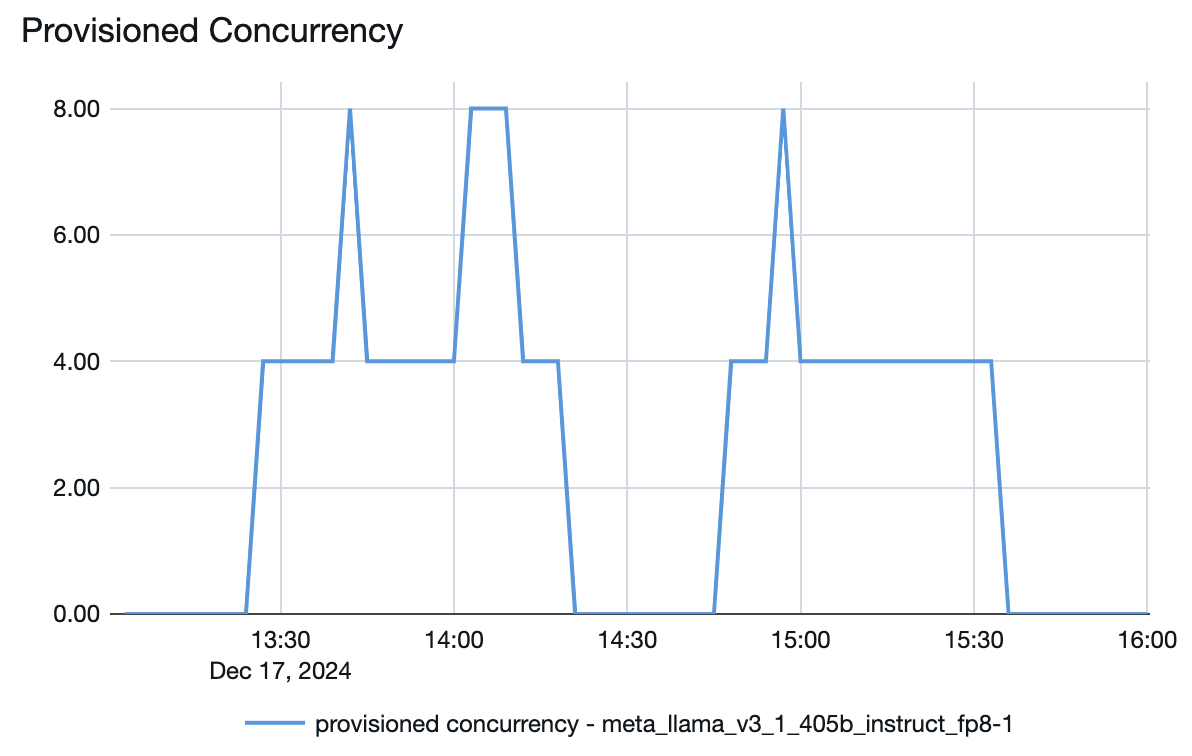
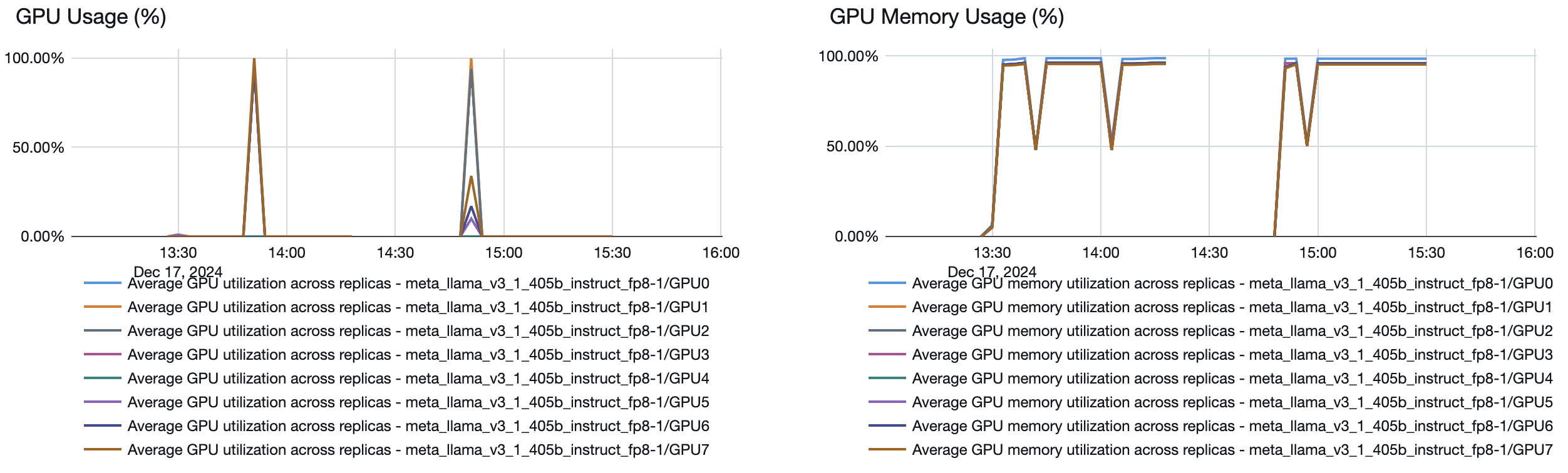
Обслуживание моделей включает быструю систему автомасштабирования, которая масштабирует вычислительные мощности для удовлетворения требований по количеству токенов в секунду для приложения. Databricks масштабирует подготовленную пропускную способность в блоках токенов в секунду, поэтому плата взимается за дополнительные единицы подготовленной пропускной способности только при их использовании.
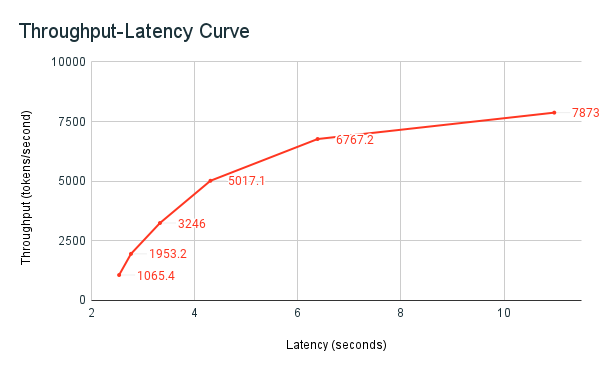
На следующем графике задержки пропускной способности показана проверенная подготовленная конечная точка пропускной способности с увеличением числа параллельных запросов. Первая точка представляет 1 запрос, второй, 2 параллельных запроса, третий, 4 параллельных запроса и т. д. По мере увеличения числа запросов и, соответственно, токенов в секунду вы увидите, что выделенная пропускная способность также увеличивается. Это увеличение означает, что автоматическое масштабирование увеличивает доступные вычислительные ресурсы. Однако вы можете начать замечать, что пропускная способность становится стабильной, достигая предела около 8000 токенов в секунду по мере увеличения числа параллельных запросов. Общая задержка увеличивается, так как больше запросов приходится ждать в очереди, прежде чем обрабатываться, так как выделенные вычислительные ресурсы используются одновременно.
Заметка
Вы можете обеспечить согласованность пропускной способности, отключив масштабирование до нуля и настроив минимальную пропускную способность в конечной точке обслуживания. Это позволяет избежать необходимости ждать масштабирования конечной точки.
Кроме того, в конечной точке развертывания модели можно увидеть, как ресурсы могут увеличиваться или уменьшаться в зависимости от спроса.