Databricks Runtime для Машинного обучения
В этой статье описывается Среда выполнения Databricks для машинного обучения и приведены рекомендации по созданию кластера, использующего его.
Что такое Databricks Runtime для машинного обучения?
Databricks Runtime для Машинное обучение (Databricks Runtime ML) автоматизирует создание кластера с предварительно созданной инфраструктурой машинного обучения и глубокого обучения, включая наиболее распространенные библиотеки машинного обучения и библиотеки DLL.
Библиотеки, включенные в состав Databricks Runtime ML
Databricks Runtime ML включает различные популярные библиотеки машинного обучения. Библиотеки обновляются в каждом выпуске, включая в себя новые функции и исправления.
Databricks назначил подмножество поддерживаемых библиотек в качестве библиотек верхнего уровня. Для этих библиотек Databricks обеспечивает более быструю частоту обновления, обновляя до последних выпусков пакетов с каждым выпуском среды выполнения (за исключением конфликтов зависимостей). Databricks также предоставляет расширенную поддержку, тестирование и внедренную оптимизацию для библиотек верхнего уровня. Библиотеки верхнего уровня добавляются или удаляются только с основными выпусками.
- Полный список библиотек высшего уровня и других предоставленных библиотек можно найти в заметках о выпуске для Databricks Runtime по машинному обучению.
- Сведения о том, как часто обновляются библиотеки и когда библиотеки объявляются устаревшими, см. в политике обслуживания Databricks Runtime ML.
Вы можете установить дополнительные библиотеки, чтобы создать пользовательскую среду для записной книжки или кластера.
- Чтобы библиотека была доступна для всех записных книжек, работающих в кластере, создайте библиотеку кластера. Для установки библиотек на кластерах после создания также можно использовать скрипт инициализации.
- Чтобы установить библиотеку, доступную только для определенного сеанса записной книжки, используйте библиотеки Python с областью действия записной книжки.
Настройка вычислительных ресурсов для машинного обучения среды выполнения Databricks
Процесс создания вычислительных ресурсов на основе среды выполнения машинного обучения Databricks зависит от того, включена ли ваша рабочая область в общедоступную предварительную версию кластера выделенной группы или нет. Рабочие области, включенные для предварительного просмотра, имеют новый упрощенный интерфейс вычислений.
Создание кластера с помощью машинного обучения Databricks Runtime
При создании кластера выберите версию среды выполнения Databricks для машинного обучения из раскрывающегося меню версии среды выполнения Databricks . Доступны среды выполнения ML с поддержкой ЦП и GPU.
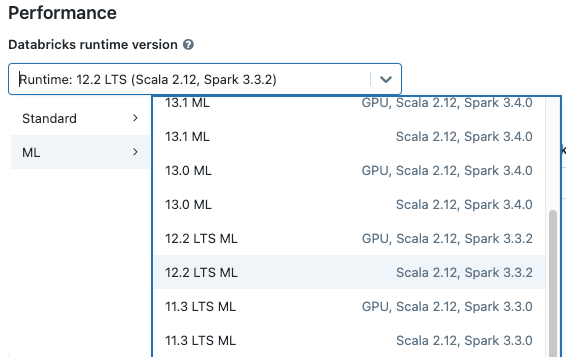
Если выбрать кластер из раскрывающегося меню в блокноте, версия среды выполнения Databricks отображается справа от названия кластера.
Если вы выберете среду выполнения машинного обучения с поддержкой GPU, вам будет предложено выбрать совместимый тип драйвера и, а также тип рабочей роли и. Несовместимые типы экземпляров неактивны в раскрывающемся меню. Типы экземпляров с поддержкой GPU перечислены под меткой ускорения GPU. Сведения о создании кластеров GPU Azure Databricks см. в разделе вычислений с поддержкой GPU. Среда Databricks Runtime ML включает драйверы для оборудования GPU и библиотеки NVIDIA, например CUDA.
Создание кластера с помощью нового упрощенного пользовательского интерфейса вычислений
Используйте действия, описанные в этом разделе, только, если рабочая область активирована для предпросмотра кластера выделенной группы.
Чтобы использовать версию среды выполнения Databricks с поддержкой машинного обучения, установите флажок Машинное обучение.
выбор пользовательского интерфейса вычислений
Для вычислений на основе GPU выберите тип экземпляра с поддержкой GPU. Полный список поддерживаемых типов GPU см. в разделе Поддерживаемые типы экземпляров.
Фотон и Databricks Runtime ML
При создании кластера ЦП под управлением Databricks Runtime 15.2 ML или более поздней версии можно включить Photon. Photon повышает производительность приложений с помощью Spark SQL, Spark DataFrames, проектирования функций, GraphFrames и xgboost4j. Ожидается, что это не повысит производительность приложений с помощью RDD Spark, пользовательских файлов Pandas и языков, отличных от JVM, таких как Python. Таким образом, пакеты Python, такие как XGBoost, PyTorch и TensorFlow, не увидят улучшения с Photon.
API-интерфейсы Spark RDD и Spark MLlib имеют ограниченную совместимость с Photon. При обработке больших наборов данных с помощью Spark RDD или Spark MLlib могут возникнуть проблемы с памятью Spark. См . статью о проблемах с памятью Spark.
Режим доступа для кластеров Databricks Runtime ML
Чтобы получить доступ к данным в каталоге Unity в кластере под управлением Databricks Runtime ML, необходимо выполнить одно из следующих действий:
- Настройте кластер с помощью режима доступа с одним пользователем.
- Настройте кластер с помощью режима выделенного доступа . Режим выделенного доступа в настоящее время находится в общедоступной предварительной версии. Выделенный режим доступа предоставляет функции общего режима доступа в Databricks Runtime для машинного обучения.
Если вычислительный ресурс имеет выделенный доступ, ресурс можно назначить одному пользователю или группе. При назначении в группу разрешения пользователя автоматически снижаются до разрешений группы, что позволяет пользователю безопасно делиться ресурсом с другими членами группы.
При использовании режима доступа с одним пользователем следующие функции доступны только в Databricks Runtime 15.4 LTS ML и более поздних версиях: