Точное управление доступом для отдельных пользователей
В этой статье представлена функция фильтрации данных, которая обеспечивает детальное управление доступом к запросам, выполняющимся на вычислительных ресурсах одного пользователя (все назначения или задания, настроенные в режиме доступа с одним пользователем). См . режимы доступа.
Фильтрация данных выполняется за кулисами с помощью бессерверных вычислений.
Почему некоторые запросы к вычислительным ресурсам одного пользователя требуют фильтрации данных?
Каталог Unity позволяет управлять доступом к табличным данным на уровне столбца и строки (также известного как точное управление доступом) с помощью следующих функций:
Когда пользователи запрашивают представления, которые исключают данные из ссылочных таблиц или таблиц запросов, которые применяют фильтры и маски, они могут использовать любой из следующих вычислительных ресурсов без ограничений:
- Хранилища SQL
- Общие вычислительные ресурсы
Однако если вы используете однопользовательские вычисления для выполнения таких запросов, вычислительные ресурсы и рабочая область должны соответствовать определенным требованиям:
Вычислительный ресурс одного пользователя должен находиться в Databricks Runtime 15.4 LTS или более поздней версии.
Рабочая область должна быть включена для бессерверных вычислений для заданий, записных книжек и разностных динамических таблиц.
Чтобы убедиться, что регион рабочей области поддерживает бессерверные вычисления, см. сведения о функциях с ограниченной региональной доступностью.
Если вычислительный ресурс и рабочая область одного пользователя соответствуют этим требованиям, фильтрация данных выполняется автоматически при запросе представления или таблицы, использующего точное управление доступом.
Поддержка материализованных представлений, потоковых таблиц и стандартных представлений
Помимо динамических представлений, фильтров строк и маскировок столбцов, фильтрация данных также включает запросы к следующим представлениям и таблицам, которые не поддерживаются для отдельных пользовательских вычислений, работающих под управлением Databricks Runtime 15.3 и ниже:
В вычислительной среде для одного пользователя, работающей под управлением Databricks Runtime версии 15.3 и ниже, пользователь, выполняющий запрос к представлению, должен иметь SELECT на таблицах и представлениях, упомянутых в этом представлении. Это означает, что использование представлений для обеспечения детального управления доступом невозможно. В Databricks Runtime 15.4 с фильтрацией данных пользователь, запрашивающий представление, не нуждается в доступе к указанным таблицам и представлениям.
Как фильтрация данных работает на вычислительных ресурсах одного пользователя?
Каждый раз, когда запрос обращается к следующим объектам базы данных, один пользователь вычислительный ресурс передает запрос на бессерверные вычисления для фильтрации данных:
- Представления, созданные на основе таблиц, где у пользователя нет привилегий
SELECT - Динамические представления
- Таблицы с определенными фильтрами строк или масками столбцов
- Материализованные представления и потоковые таблицы
На следующей схеме пользователь включен SELECTtable_1view_2и table_w_rlsимеет примененные фильтры строк. Пользователь не имеет на SELECTtable_2ней ссылки view_2.

Запрос table_1 полностью обрабатывается одним пользовательским вычислительным ресурсом, так как фильтрация не требуется. Запросы view_2 и table_w_rls требуют фильтрации данных для возврата данных, к которым у пользователя есть доступ. Эти запросы обрабатываются функцией фильтрации данных на бессерверных вычислениях.
Какие расходы взимается?
Клиентам взимается плата за бессерверные вычислительные ресурсы, используемые для выполнения операций фильтрации данных. Сведения о ценах см. в разделе "Уровни платформы" и "Надстройки".
Вы можете запросить таблицу учета использования системы выставления счетов, чтобы узнать, сколько с вас списали. Например, следующий запрос разбивает затраты на вычисления пользователем:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Просмотр производительности запросов при использовании фильтрации данных
Пользовательский интерфейс Spark для одного пользователя отображает метрики, которые можно использовать для понимания производительности запросов. Для каждого запроса, выполняемого на вычислительном ресурсе, вкладка SQL/Dataframe отображает представление графа запросов. Если запрос был вовлечен в фильтрацию данных, пользовательский интерфейс отображает узел оператора RemoteSparkConnectScan в нижней части графа. На этом узле отображаются метрики, которые можно использовать для изучения производительности запросов. Просмотр сведений о вычислениях в пользовательском интерфейсе Apache Spark.
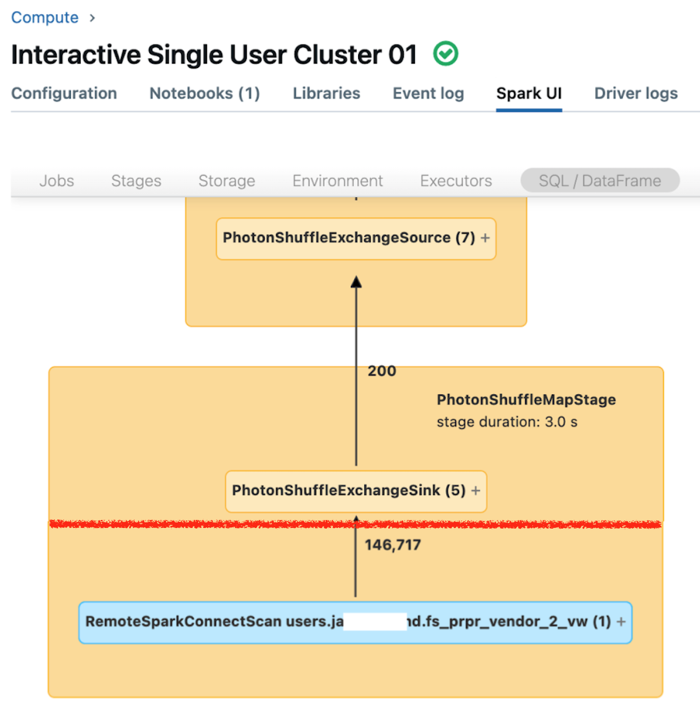
Разверните узел оператора RemoteSparkConnectScan, чтобы просмотреть метрики, которые касаются следующих вопросов:
- Сколько времени занимает фильтрация данных? Просмотрите "общее время удаленного выполнения".
- Сколько строк осталось после фильтрации данных? Просмотр выходных данных строк.
- Сколько данных (в байтах) было возвращено после фильтрации данных? Просмотрите "размер выходных данных строк".
- Сколько файлов данных было исключено благодаря секционированию и которые не нужно было считывать из хранилища? Просмотрите "Файлы, отрезаемые" и "Размер файлов, отрезаемых".
- Сколько файлов данных не удалось выполнить и нужно было считывать из хранилища? Просмотр "Файлы считываются" и "Размер файлов считываются".
- Из файлов, которые должны были быть прочитаны, сколько уже было в кэше? Просмотр "Размер попаданий кэша" и "Кэш пропускает размер".
Ограничения
Нет поддержки операций записи или обновления таблиц в таблицах с примененными фильтрами строк или масками столбцов.
В частности, операции DML, такие как
INSERT,DELETE,UPDATEREFRESH TABLEи , неMERGEподдерживаются. Из этих таблиц можно читать только (SELECT).Самосоединения блокируются по умолчанию при вызове фильтрации данных, но их можно разрешить, установив
spark.databricks.remoteFiltering.blockSelfJoinsзначение false для вычислений, в которых выполняются эти команды.Прежде чем включить самостоятельное присоединение к одному вычислительному ресурсу пользователя, помните, что запрос самосоединения, обрабатываемый функцией фильтрации данных, может возвращать различные моментальные снимки одной удаленной таблицы.
Если рабочая область была развернута с брандмауэром до ноября 2024 года, необходимо открыть порты 8443 и 8444, чтобы обеспечить точное управление доступом на вычислительных ресурсах с одним пользователем. См. правила группы безопасности сети .