Прогнозирование с помощью AutoML (классические вычисления)
Используйте AutoML для автоматического поиска оптимального алгоритма прогнозирования и конфигурации гиперпараметров для прогнозирования значений на основе данных временных рядов.
Прогнозирование временных рядов доступно только для Databricks Runtime 10.0 ML или более поздней версии.
Настройка эксперимента прогнозирования с помощью пользовательского интерфейса
Вы можете настроить проблему прогнозирования с помощью пользовательского интерфейса AutoML, выполнив следующие действия.
- На боковой панели выберите "Эксперименты".
- В карточке прогнозирования нажмите кнопку "Начать обучение".
Интерфейс прогнозирования по умолчанию настроен на бессерверное прогнозирование. Чтобы получить доступ к прогнозированию с помощью собственных вычислений, выберите вернуться к старому интерфейсу.
настройка эксперимента AutoML
Откроется страница Настройка эксперимента AutoML. На этой странице вы настроите процесс AutoML, указав набор данных, тип задачи, целевой столбец или столбец меток для прогнозирования, метрику, используемую для оценки результатов экспериментальных запусков, а также условия остановки.
В поле Вычисления выберите кластер, на котором работает Databricks Runtime 10.0 ML или более поздней версии.
В разделе Набор данных нажмите Обзор. Перейдите к таблице, которую необходимо использовать, и нажмите кнопку Выбрать. Отобразится схема таблицы.
Щелкните поле Цель прогнозирования. Откроется раскрывающееся меню, в котором перечислены столбцы, отображаемые в схеме. Выберите столбец, для которого модель должна создать прогноз.
Щелкните поле Столбец времени. Отобразится раскрывающийся список столбцов набора данных, имеющих тип
timestampилиdate. Выберите столбец, содержащий временные периоды для временных рядов.Для прогнозирования с несколькими рядами выберите столбцы, которые идентифицируют отдельные временные ряды, из раскрывающегося списка Идентификаторы временных рядов. AutoML группирует данные по этим столбцам как различные временные ряды и проводит обучение модели для каждого ряда отдельно. Если оставить это поле пустым, AutoML предположит, что набор данных содержит один временной ряд.
В полях Горизонт и частота прогнозирования укажите количество периодов времени в будущем, для которых AutoML должен рассчитывать прогнозируемые значения. В левом поле введите целое число периодов для прогнозирования. В правом поле выберите единицы измерения.
Примечание.
Для использования auto-ARIMA временные ряды должны иметь обычную частоту, в которой интервал между двумя точками должен совпадать в течение временных рядов. Частота должна соответствовать единице частоты, указанной в вызове API или в пользовательском интерфейсе AutoML. AutoML обрабатывает пропущенные временные шаги, заполняя эти значения предыдущим.
В Databricks Runtime 11.3 LTS ML и более поздних версиях можно сохранить результаты прогнозирования. Для этого укажите базу данных в поле Output Database (Выходная база данных). Нажмите кнопку Обзор и выберите базу данных в диалоговом окне. AutoML запишет результаты прогнозирования в таблицу в этой базе данных.
В поле Имя эксперимента отображается имя по умолчанию. Чтобы изменить его, введите новое имя в поле.
Кроме того, вы можете сделать следующее:
- Укажите дополнительные параметры конфигурации.
- Используйте существующие таблицы функций в Магазине компонентов для расширения исходного входного набора данных.
Дополнительные конфигурации
Откройте раздел Расширенная конфигурация (необязательно), чтобы получить доступ к этим параметрам.
- Метрика оценки — это основная метрика, используемая для оценки запусков.
- В Databricks Runtime 10.4 LTS ML и более поздних версиях можно исключить платформы обучения из рассмотрения. По умолчанию AutoML обучает модели с использованием платформ, перечисленных в разделе Алгоритмы AutoML.
- Вы можете изменить условия остановки. Условия остановки по умолчанию:
- В экспериментах прогнозирования остановка происходит через 120 минут.
- В Databricks Runtime 10.4 LTS ML и ниже для экспериментов классификации и регрессии остановится через 60 минут или после завершения 200 испытаний, в зависимости от того, что происходит сначала. После версии Databricks Runtime 11.0 ML количество пробных выполнений не учитывается в качестве условия остановки.
- В Databricks Runtime 10.4 LTS ML и более поздних версий для экспериментов классификации и регрессии AutoML включает ранние остановки; Он останавливает обучение и настройку моделей, если метрика проверки больше не улучшается.
- В Databricks Runtime 10.4 LTS ML и более поздних версиях можно выбрать
time columnспособ разделения данных для обучения, проверки и тестирования в хронологическом порядке (применяется только к классификации и регрессии). - Databricks рекомендует не заполнять поле каталога данных. Это активирует поведение по умолчанию безопасного хранения набора данных в качестве артефакта MLflow. Путь к DBFS можно указать, но в этом случае набор данных не наследует разрешения на доступ к эксперименту AutoML.
Запуск эксперимента и проверка результатов
Чтобы запустить эксперимент AutoML, нажмите кнопку Запустить AutoML. Начнется запуск эксперимента, и появится страница обучения AutoML. Чтобы обновить таблицу запусков, нажмите кнопку  .
.
Просмотр хода выполнения эксперимента
На этой странице можно выполнить следующие действия.
- Остановить эксперимент в любое время.
- Открыть записную книжку исследования данных.
- Отслеживание выполнений.
- Перейдите на страницу запуска для любого запуска.
В Databricks Runtime 10.1 ML и более поздних версий AutoML отображает предупреждения о потенциальных проблемах с набором данных, таких как неподдерживаемые типы столбцов или столбцы с высокой кратностью.
Примечание.
Databricks делает все возможное, чтобы указать на потенциальные ошибки или проблемы. Однако это может быть не исчерпывающим и может не записывать проблемы или ошибки, которые могут возникнуть при поиске.
Чтобы просмотреть предупреждения для набора данных, щелкните вкладку "Предупреждения " на странице обучения или на странице эксперимента после завершения эксперимента.
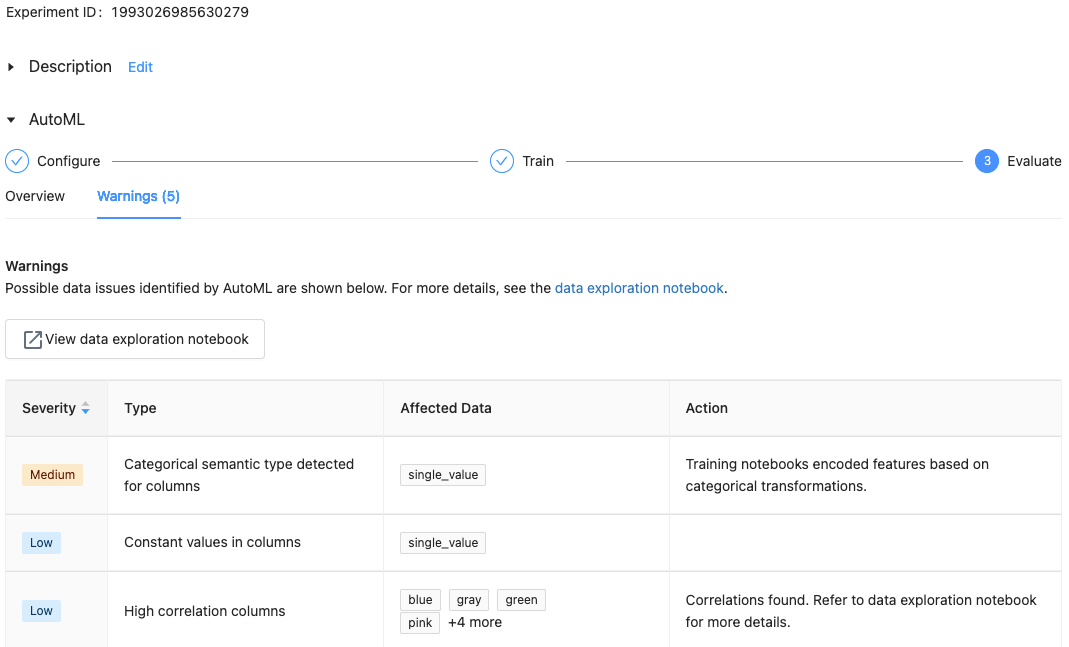
Показать результаты
После завершения эксперимента можно выполнить следующие действия.
- Зарегистрируйте и разверните одну из моделей с помощью MLflow.
- Выберите "Просмотреть записную книжку" для лучшей модели , чтобы просмотреть и изменить записную книжку, которая создала лучшую модель.
- Выберите "Просмотреть записную книжку для просмотра данных", чтобы открыть записную книжку для просмотра данных.
- Поиск, фильтрация и сортировка запусков в таблице запусков.
- Дополнительные сведения о любом запуске:
- Созданная записная книжка, содержащая исходный код для пробного запуска, можно найти, щелкнув в запуске MLflow. Записная книжка сохраняется в разделе "Артефакты" страницы запуска. Эту записную книжку можно скачать и импортировать в рабочую область, если скачивание артефактов включено администраторами рабочей области.
- Чтобы просмотреть результаты выполнения, щелкните столбец "Модели " или столбец "Время начала". Откроется страница запуска, показывающая сведения о пробной версии (например, параметрах, метриках и тегах) и артефактах, созданных с помощью запуска, включая модель. На этой странице также содержатся фрагменты кода, которые можно использовать для создания прогнозов с помощью модели.
Чтобы вернуться к этому эксперименту AutoML позже, найдите его в таблице на странице Эксперименты. Результаты каждого эксперимента AutoML, включая записные книжки исследования данных и обучения, хранятся в папке databricks_automl в домашней папке пользователя, запустившего эксперимент.
Регистрация и развертывание модели
Вы можете зарегистрировать и развернуть модель с помощью пользовательского интерфейса AutoML:
- Выберите ссылку в столбце "Модели" для регистрации модели. По завершении выполнения верхняя строка является лучшей моделью (на основе основной метрики).
- Выберите
 , чтобы зарегистрировать модель в реестре моделей.
, чтобы зарегистрировать модель в реестре моделей. - Выберите
 модели на боковой панели, чтобы перейти к реестру моделей.
модели на боковой панели, чтобы перейти к реестру моделей. - Выберите имя модели в таблице моделей.
- На странице зарегистрированной модели можно обслуживать модель с помощью службы моделей.
Нет модуля с именем Pandas.core.indexes.numeric
При обслуживании модели, созданной с помощью AutoML с обслуживанием моделей, может возникнуть ошибка: No module named 'pandas.core.indexes.numeric
Это связано с несовместимой pandas версией между AutoML и средой конечной точки обслуживания модели. Эту ошибку можно устранить, выполнив скрипт add-pandas-dependency.py. Скрипт изменяет requirements.txt модель и conda.yaml для нее, чтобы включить соответствующую pandas версию зависимостей: pandas==1.5.3
- Измените скрипт, чтобы включить
run_idзапуск MLflow, в котором была зарегистрирована модель. - Повторно зарегистрируйте модель в реестре моделей MLflow.
- Попробуйте использовать новую версию модели MLflow.