Начало работы. Импорт и визуализация ДАННЫХ CSV из записной книжки
В этой статье описывается использование записной книжки Azure Databricks для импорта данных из CSV-файла, содержащего данные имени ребенка из health.data.ny.gov в том каталога Unity с помощью Python, Scala и R. Вы также узнаете, как изменить имя столбца, визуализировать данные и сохранить их в таблице.
Требования
Чтобы выполнить задачи в этой статье, необходимо выполнить следующие требования:
- Рабочая область должна включать каталог Unity. Сведения о начале работы с каталогом Unity см. в разделе "Настройка каталога Unity" и управление ими.
- У вас должны быть
WRITE VOLUMEправа на том,USE SCHEMAпривилегии родительской схемы иUSE CATALOGпривилегии родительского каталога. - Необходимо иметь разрешение на использование существующего вычислительного ресурса или создать новый вычислительный ресурс. См. статью "Начало работы: настройка учетной записи и рабочей области " или просмотр администратора Databricks.
Совет
Полный записной книжки для этой статьи см. в разделе "Импорт и визуализация записных книжек данных".
Шаг 1. Создание записной книжки
Чтобы создать записную книжку в рабочей области, нажмите кнопку ![]() "Создать" на боковой панели и нажмите кнопку "Записная книжка". Пустая записная книжка открывается в рабочей области.
"Создать" на боковой панели и нажмите кнопку "Записная книжка". Пустая записная книжка открывается в рабочей области.
Дополнительные сведения о создании записных книжек и управлении ими см. в статье Управление записными книжками.
Шаг 2. Определение переменных
На этом шаге вы определите переменные для использования в примере записной книжки, создаваемой в этой статье.
Скопируйте и вставьте следующий код в новую пустую ячейку записной книжки. Замените
<catalog-name>,<schema-name>а также<volume-name>именами каталогов, схем и томов для тома каталога Unity. При необходимости заменитеtable_nameзначение именем таблицы. Данные имени ребенка будут сохранены в этой таблице далее в этой статье.Нажмите
Shift+Enter, чтобы запустить ячейку и создать пустую ячейку.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Шаг 3. Импорт CSV-файла
На этом шаге вы импортируете CSV-файл, содержащий данные имени ребенка из health.data.ny.gov в том каталога Unity.
Скопируйте и вставьте следующий код в новую пустую ячейку записной книжки. Этот код копирует
rows.csvфайл из health.data.ny.gov в том каталога Unity с помощью команды Databricks dbutuils .Нажмите
Shift+Enter, чтобы запустить ячейку, а затем перейдите к следующей ячейке.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Шаг 4. Загрузка данных CSV в кадр данных
На этом шаге вы создадите кадр данных с именем df ИЗ CSV-файла, который ранее был загружен в том каталога Unity с помощью метода spark.read.csv .
Скопируйте и вставьте следующий код в новую пустую ячейку записной книжки. Этот код загружает данные имени ребенка в кадр данных
dfиз CSV-файла.Нажмите
Shift+Enter, чтобы запустить ячейку, а затем перейдите к следующей ячейке.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Данные можно загрузить из многих поддерживаемых форматов файлов.
Шаг 5. Визуализация данных из записной книжки
На этом шаге вы используете display() метод для отображения содержимого кадра данных в таблице в записной книжке, а затем визуализировать данные в облачной диаграмме word в записной книжке.
Скопируйте и вставьте следующий код в новую пустую ячейку записной книжки, а затем нажмите кнопку "Запустить ячейку ", чтобы отобразить данные в таблице.
Python
display(df)Scala
display(df)R
display(df)Просмотрите результаты в таблице.
Рядом с вкладкой "Таблица " щелкните + и щелкните " Визуализация".
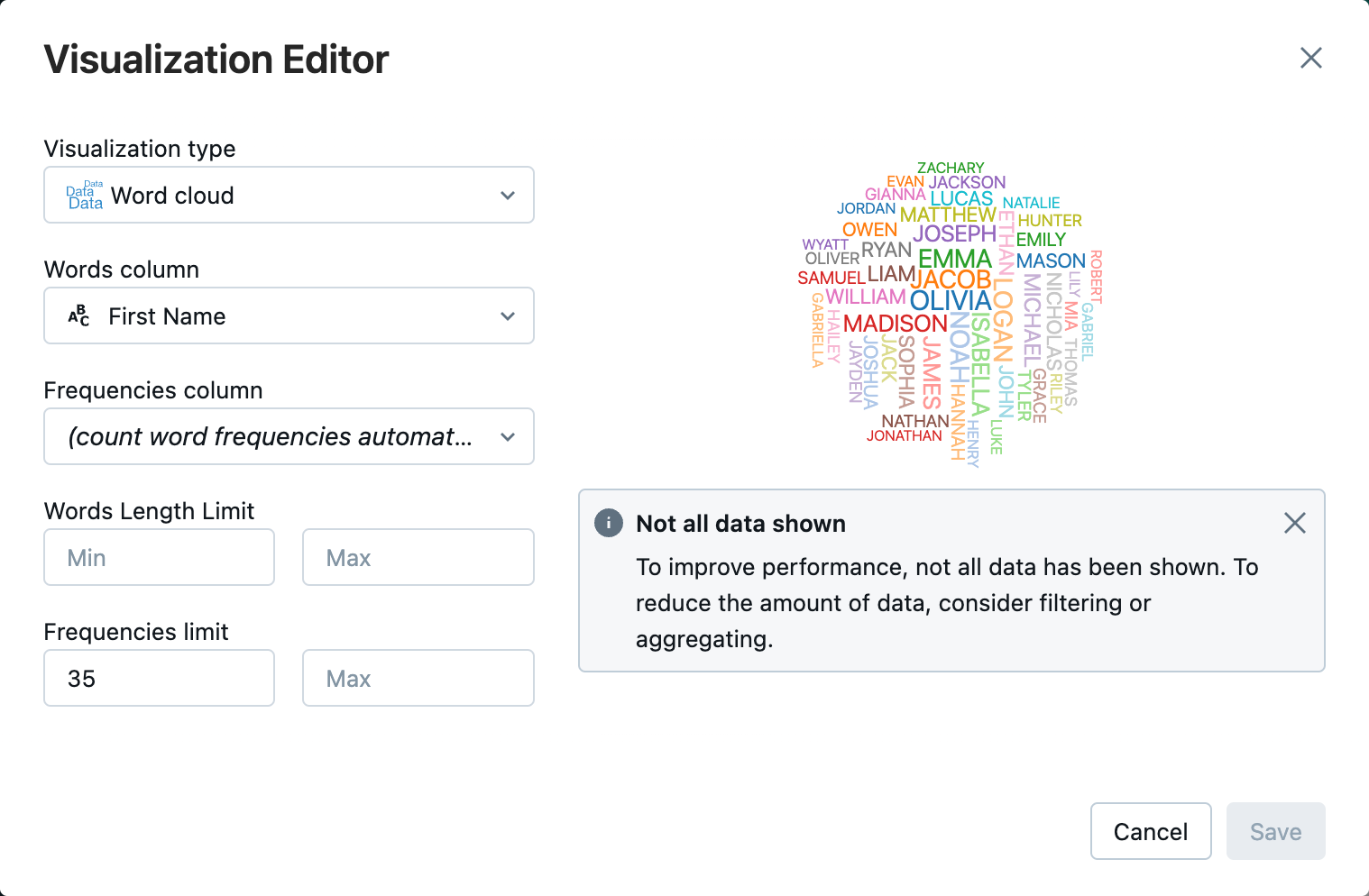
В редакторе визуализации щелкните "Тип визуализации" и убедитесь, что выбрано облако Word.
В столбце "Слова" убедитесь, что
First Nameвыбрано.В ограничении частот нажмите кнопку
35.
Нажмите кнопку Сохранить.
Шаг 6. Сохранение кадра данных в таблице
Внимание
Чтобы сохранить кадр данных в каталоге Unity, необходимо иметь CREATE права на таблицу в каталоге и схеме. Сведения о разрешениях в каталоге Unity см. в разделе "Привилегии и защищаемые объекты в каталоге Unity" и "Управление привилегиями" в каталоге Unity.
Скопируйте и вставьте следующий код в пустую ячейку записной книжки. Этот код заменяет пробел в имени столбца. Специальные символы, такие как пробелы, не допускаются в именах столбцов. Этот код использует метод Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Скопируйте и вставьте следующий код в пустую ячейку записной книжки. Этот код сохраняет содержимое кадра данных в таблицу в каталоге Unity с помощью переменной имени таблицы, определенной в начале этой статьи.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Чтобы убедиться, что таблица сохранена, щелкните каталог в левой боковой панели, чтобы открыть пользовательский интерфейс обозревателя каталогов. Откройте каталог, а затем схему, чтобы убедиться, что таблица появится.
Щелкните таблицу, чтобы просмотреть схему таблицы на вкладке "Обзор ".
Щелкните " Пример данных" , чтобы просмотреть 100 строк данных из таблицы.
Импорт и визуализация записных книжек данных
Чтобы выполнить действия, описанные в этой статье, используйте одну из следующих записных книжек. Замените <catalog-name>, <schema-name>а также <volume-name> именами каталогов, схем и томов для тома каталога Unity. При необходимости замените table_name значение именем таблицы.
Python
Импорт данных из CSV с помощью Python
Scala
Импорт данных из CSV с помощью Scala
R
Импорт данных из CSV с помощью R
Следующие шаги
- Сведения о добавлении дополнительных данных в существующую таблицу из CSV-файла см. в статье "Начало работы: прием и вставка дополнительных данных".
- Дополнительные сведения о очистке и улучшении данных см. в статье "Начало работы: улучшение и очистка данных".