Создание и запрос индекса векторного поиска
В этой статье описывается, как создать и выполнять запросы в векторном поисковом индексе с использованием мозаичного векторного поиска АИ .
Вы можете создавать и управлять компонентами векторного поиска, например конечной точкой векторного поиска и индексами векторного поиска, с помощью пользовательского интерфейса,пакета SDK для Python
Требования
- Включённая рабочая область Unity Catalog.
- Бессерверные вычисления включены. Инструкции см. в статье Подключение к бессерверным вычислительным.
- Исходный table должен иметь включённый поток изменения данных. Инструкции см. в разделе Использование потока данных изменений Delta Lake в Azure Databricks.
- Чтобы создать индекс векторного поиска, необходимо иметь CREATE TABLE привилегии на catalogschema, где будет создан индексwhere.
- Чтобы запросить индекс, принадлежащий другому пользователю, необходимо иметь дополнительные привилегии. См. Запросите конечную точку векторного поиска.
Разрешение на создание конечных точек поиска векторов и управление ими настраивается с помощью списков управления доступом. См. списки контроля доступа (ACL) конечных точек поиска векторов.
Установка
Чтобы использовать пакет SDK для векторного поиска, необходимо установить его в записную книжку. Используйте следующий код:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Аутентификация
См. Защита данных иПроверка подлинности.
Создание конечной точки векторного поиска
Вы можете создать конечную точку векторного поиска с помощью пользовательского интерфейса Databricks, пакета SDK для Python или API.
Создание конечной точки векторного поиска с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать конечную точку векторного поиска с помощью пользовательского интерфейса.
На левой боковой панели щелкните Вычисления.
Щелкните вкладку "Поиск вектора" и нажмите "Создать".

Откроется форма создания конечной точки
. Введите имя этой конечной точки. Нажмите Подтвердить.
Создание конечной точки векторного поиска с помощью пакета SDK для Python
В следующем примере используется функция пакета SDK create_endpoint() для создания конечной точки векторного поиска.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Создание конечной точки векторного поиска с помощью REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/endpoints.
(Необязательно) Создание и настройка конечной точки для обслуживания модели внедрения
Если вы решили использовать Databricks для вычисления эмбеддингов, вы можете воспользоваться предварительно настроенным конечным узлом API модели Foundation или создать узел обслуживания модели для выбранной вами эмбеддинговой модели. См. API моделей с оплатой за токены или Создание конечных точек для обслуживания базовой модели для получения инструкций. Примеры блокнотов см. в в разделе примеров для вызова модели внедрения.
При настройке конечной точки внедрения Databricks рекомендует remove выбор по умолчанию Масштабирование до нуля. Активация конечных точек обслуживания может занять несколько минут, и начальный запрос в индексе с уменьшенной конечной точкой может завершиться тайм-аутом.
Заметка
Инициализация индекса векторного поиска может истекть, если конечная точка внедрения не настроена соответствующим образом для набора данных. Для небольших наборов данных и тестов следует использовать только конечные точки ЦП. Для больших наборов данных используйте конечную точку GPU для оптимальной производительности.
Создание индекса векторного поиска
Индекс векторного поиска можно создать с помощью пользовательского интерфейса, пакета SDK Для Python или REST API. Пользовательский интерфейс — это самый простой подход.
Существует два типа индексов:
- Delta Sync Index автоматически синхронизируется с источником Delta Table, автоматически и постепенно обновляя индекс по мере изменения базовых данных в Delta Table.
- индекс прямого векторного доступа поддерживает прямое чтение и запись векторов и метаданных. Пользователь отвечает за обновление этого table с помощью REST API или пакета SDK для Python. Этот тип индекса нельзя создать с помощью пользовательского интерфейса. Необходимо использовать REST API или пакет SDK.
Создание индекса с помощью пользовательского интерфейса
На левой боковой панели щелкните Catalog, чтобы открыть пользовательский интерфейс обозревателя Catalog.
Перейдите к Delta table, которую вы хотите использовать.
Нажмите кнопку Создать в правом верхнем углу, затем выберите selectиндекс векторного поиска из раскрывающегося меню.
Используйте селекторы в диалоговом окне для настройки индекса.
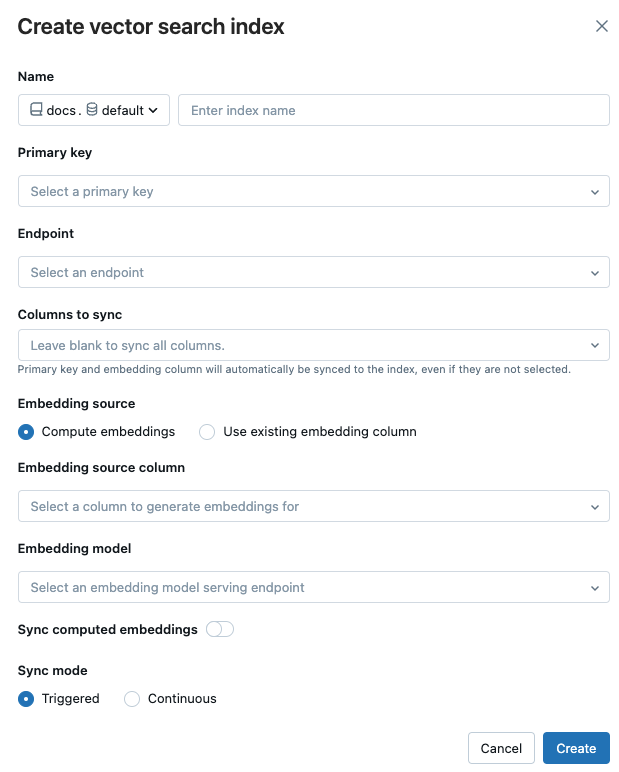
имя: имя, используемое для онлайн table в Unity Catalog. Для имени требуется трехуровневое пространство имен,
<catalog>.<schema>.<name>. Разрешены только буквенно-цифровые символы и символы подчеркивания.первичный ключ: Column использовать в качестве первичного ключа.
конечная точка: Select векторная поисковая конечная точка, которую вы хотите использовать.
Columns sync : Selectcolumnssync с индексом вектора. Если оставить это поле пустым, все columns из исходного table синхронизируются с индексом. Первичный ключ column и встроенные данные column или векторные вложения column всегда синхронизируются.
Встраивание источника: Укажите, требуется ли Databricks вычислить встраивание для текста column в Delta table (Вычисление встраивания), или если ваша Delta table содержит предварительно вычисленные встраивания (Использовать существующие встраивания column).
- Если вы выбрали , чтобы вычислить векторные представления для, select, column, и конечную точку, которая обслуживает модель для этих векторных представлений. Поддерживается только текст columns.
- Если вы выбрали Использовать существующие columnвектора, selectcolumn, которая содержит предварительно рассчитанные вектора и их размерность. Формат предварительно вычисленного встраивания column должен быть
array[float].
Sync вычисленные встраивания: включите этот параметр, чтобы сохранить созданные встраивания в Unity Catalogtable. Дополнительные сведения см. в разделе Сохранение созданного встраиваемого элемента table.
режима
: непрерывный сохраняет индекс в с задержкой в несколько секунд. Однако она сопровождается более высокими затратами, так как вычислительный кластер задействован для выполнения непрерывного sync стриминга. Для обеих непрерывной и активированнойupdate обработка инкрементальная — обрабатываются только те данные, которые изменились с момента последнего sync. При срабатывании режима sync вы используете Python SDK или REST API для запуска sync. См. Update индекс Delta Sync.
Закончив настройку индекса, нажмите кнопку Создать.
Создание индекса с помощью пакета SDK для Python
В следующем примере создается индекс Delta Sync с эмбеддингами, вычисленными Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
В следующем примере создается индекс Delta Sync с самостоятельно управляемыми встраиваниями. В этом примере также показано использование необязательного параметра columns_to_sync для select только подмножество columns, используемое в индексе.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
По умолчанию все columns из источника данных table синхронизируются с индексом. Чтобы sync только подмножество columns, используйте columns_to_sync. Первичный ключ и векторное представление columns всегда включаются в индекс.
Чтобы syncтолько первичный ключ и columnвнедрения, необходимо указать их в columns_to_sync, как показано ниже.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Для sync дополнительных columnsукажите их, как показано. Не нужно включать первичный ключ и эмбеддинг column, так как они всегда синхронизируются.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
В следующем примере создается индекс прямого векторного доступа.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Создание индекса с помощью REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes.
Сохранение созданного встраивания table
Если Databricks создает векторные представления, можно сохранить созданные векторные представления в table в Unity Catalog. Эта table создается в той же schema, что и векторный индекс, и связана со страницей векторного индекса.
Имя table — это имя индекса векторного поиска, дополненного _writeback_table. Имя не редактируется.
Вы можете получить доступ и делать запросы к table, как к любому другому table в Unity Catalog. Однако не следует удалять или изменять table, так как оно не предназначено для ручного обновления. table автоматически удаляется, если индекс удаляется.
Update индекс векторного поиска
Update разностный индекс Sync
Индексы, созданные с помощью непрерывного режима sync, автоматически update при изменении исходного Delta table. Если вы используете режим триггера sync, используйте Python SDK или REST API для запуска sync.
Python SDK
index.sync()
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Update индекс прямого векторного доступа
Пакет SDK для Python или REST API можно использовать для insert, updateили удаления данных из индекса прямого векторного доступа.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes.
В следующем примере кода показано, как update создать индекс с помощью персонального токена доступа (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
В следующем примере кода показано, как update индекс с помощью служебного принципала.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Запрос конечной точки векторного поиска
Вы можете запрашивать только конечную точку векторного поиска с помощью пакета SDK для Python, REST API или функции SQL vector_search() ИИ.
Заметка
Если пользователь, запрашивающий конечную точку, не является владельцем индекса векторного поиска, пользователь должен иметь следующие права UC:
- USE CATALOG находится на catalog, которая содержит индекс для векторного поиска.
- USE SCHEMA находится на schema, которая содержит индекс для векторного поиска.
- SELECT в индексе векторного поиска.
Чтобы выполнить гибридный поиск по ключевым словам и сходству, set параметр query_type на hybrid. Значение по умолчанию — ann (приблизительный ближайший сосед).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes/{index_name}/query.
В следующем примере кода показано, как запрашивать индекс с помощью токена личного доступа (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
В следующем примере кода показано, как выполнить запрос к индексу с использованием сервисного аккаунта.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Важный
Функция vector_search() ИИ находится в общедоступной предварительной версии.
Чтобы использовать эту функцию ИИ, см. функции vector_search.
Использовать фильтры для запросов
Запрос может определять фильтры на основе любых column в Delta table.
similarity_search возвращает только строки, соответствующие указанным фильтрам. Поддерживаются следующие фильтры:
| Оператор фильтра | Поведение | Примеры |
|---|---|---|
NOT |
Отрицает фильтр. Ключ должен заканчиваться значением NOT. Например, выражение "цвет НЕ" со значением "красный" подходит для документов, в которых where означает, что цвет не красный. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Проверяет, меньше ли значение поля, чем значение фильтра. Ключ должен заканчиваться "<". Например, "цена <" со значением 200 соответствует документам, where цена меньше 200. | {"id <": 200} |
<= |
Проверяет, меньше ли значение поля или равно значению фильтра. Ключ должен заканчиваться "<=". Например, "цена <=" со значением 200 соответствует документам, where цена меньше или равно 200. | {"id <=": 200} |
> |
Проверяет, больше ли значение поля, чем значение фильтра. Ключ должен заканчиваться ">". Например, "цена >" со значением 200 соответствует документам where, в которых цена превышает 200. | {"id >": 200} |
>= |
Проверяет, больше ли значение поля или равно значению фильтра. Ключ должен заканчиваться ">=". Например, "цена >=" со значением 200 соответствует документам where, где цена больше или равна 200. | {"id >=": 200} |
OR |
Проверяет, соответствует ли значение поля какому-либо фильтру values. Ключ должен содержать OR для разделения нескольких подключей. Например, color1 OR color2 со значением ["red", "blue"] соответствует документам wherecolor1red или color2blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Соответствует частичным строкам. | {"column LIKE": "hello"} |
| Оператор фильтра не указан | Фильтр проверяет точное совпадение. Если задано несколько values, он соответствует любому из values. |
{"id": 200}
{"id": [200, 300]}
|
См. следующие примеры кода:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
См. POST /api/2.0/vector-search/indexes/{index_name}/query.
примеры записных книжек
В примерах этого раздела демонстрируется использование пакета SDK для поиска векторов Python.
Примеры LangChain
См. , как использовать LangChain с Mosaic AI Vector Search для использования векторного поиска Mosaic AI в интеграции с пакетами LangChain.
В следующей записной книжке показано, как преобразовать результаты поиска сходства в документы LangChain.
Векторный поиск с помощью блокнота Python SDK
Примеры ноутбуков для вызова модели эмбеддингов
В следующих записных книжках показано, как настроить конечную точку обслуживания модели Mosaic AI для генерации эмбеддингов.