Оценка производительности: метрики, которые имеют значение
В этой статье описывается измерение производительности приложения RAG для качества получения, ответа и производительности системы.
Извлечение данных, ответ и производительность
С помощью набора для оценки можно измерять производительность приложения RAG по ряду параметров, в том числе:
- Качество получения: метрики получения оценивают, как приложение RAG успешно извлекает соответствующие вспомогательные данные. Точность и отзыв — это две ключевые метрики извлечения.
- Качество ответа: метрики качества ответа оценивают, насколько хорошо приложение RAG отвечает на запрос пользователя. Метрики ответа могут измерять, например, насколько точным является результирующий ответ относительно истинных значений, насколько хорошо ответ был обоснован с учётом полученного контекста (например, не были ли у LLM галлюцинации?), или насколько безопасным был ответ (иными словами, отсутствует токсичность).
- Производительность системы (затраты и задержка): метрики фиксируют общую стоимость и производительность приложений RAG. Полная задержка и использование токенов являются примерами метрик производительности цепи.
Очень важно собирать метрики ответа и извлечения. Приложение RAG может плохо реагировать, даже при правильном получении контекста; оно также может предоставлять хорошие ответы на основе неисправных извлечений. Только измеряя оба компонента, мы можем точно диагностировать и устранять проблемы в приложении.
Подходы к измерению производительности
Существует два ключевых подхода к измерению производительности для этих метрик:
- Детерминированное измерение: метрики затрат и задержки можно вычислять детерминированным образом на основе выходных данных приложения. Если ваш набор для оценки включает список документов, которые содержат ответ на вопрос, то подмножество метрик извлечения также можно вычислить детерминированным образом.
- Измерение на основе судьи LLM: в этом подходе отдельный LLM выступает в качестве судьи для оценки качества получения и ответа приложения RAG. Некоторые параметры оценки LLM, как, например, правильность ответа, сравнивают человечески размеченную эталонную информацию с выходными данными приложения. Другие судьи LLM, такие как обоснованность, не требуют человеческой истинных данных для оценки их выходных данных приложения.
Внимание
Чтобы судья LLM был эффективным, его необходимо настроить, чтобы понять вариант использования. Это требует тщательного внимания, чтобы понять, где судья работает хорошо и где - нет, а затем настроить его, чтобы усовершенствовать недоработки.
Оценка агента ИИ Мозаики предоставляет готовую из коробки реализацию, используя размещённые модели LLM-судьи для каждой метрики, описанной на этой странице. Документация по оценке агентов описывает в деталях, как реализованы эти метрики и судьи, а также предоставляет возможность настройки судей с помощью ваших данных для повышения их точности.
Общие сведения о метриках
Ниже приведена сводка метрик, которые Databricks рекомендует для измерения качества, стоимости и задержки приложения RAG. Эти метрики реализованы в оценке агента искусственного интеллекта Mosaic.
| Измерение | Имя метрики | Вопрос | Измерено с помощью | Нуждается в проверенной информации? |
|---|---|---|---|---|
| Извлечение | chunk_relevance/точность | Какие % полученных блоков относятся к запросу? | Судья LLM | Нет |
| Извлечение данных | отзыв документа | Какой процент эталонных документов представлен в фрагментах, извлеченных? | Детерминированный | Да |
| Извлечение | достаточность контекста | Являются ли полученные блоки достаточны для получения ожидаемого ответа? | Судья LLM | Да |
| Ответ | корректность | В целом, сгенерировал ли агент правильный ответ? | Судья LLM | Да |
| Ответ | релевантность_запросу | Относится ли ответ к запросу? | Судья LLM | Нет |
| Ответ | укоренённость | Это ответ является галлюцинацией или основан на контексте? | Судья LLM | Нет |
| Ответ | безопасность | Есть ли вредное содержимое в ответе? | Судья LLM | Нет |
| Себестоимость | сумма_токенов, сумма_входных_токенов, сумма_выходных_токенов | Каково общее количество токенов для генераций LLM? | Детерминированное | Нет |
| Задержка | задержка_в_секундах | Какова задержка выполнения приложения? | Детерминированное | Нет |
Как работают метрики извлечения
Метрики получения помогают понять, предоставляет ли извлекатель соответствующие результаты. Метрики извлечения основаны на точности и полноте.
| Имя метрики | Ответ на вопрос | Сведения |
|---|---|---|
| Точность | Какие % полученных блоков относятся к запросу? | Точность — это доля извлеченных документов, которые фактически относятся к запросу пользователя. Модель LLM можно использовать для оценки релевантности каждого фрагмента, полученного в ответ на запрос пользователя. |
| Отзыв | Какой процент истинных данных представлен в извлеченных фрагментах? | Напомним, это доля наземных документов истины, представленных в извлеченных фрагментах. Это мера полноты результатов. |
Точность и полнота
Ниже приведено краткое введение в точность и полноту, адаптированное из отличной статьи Википедии.
Формула точности
Меры точности "Из полученных фрагментов, какие% из этих элементов фактически относятся к запросу моего пользователя?" Точность вычислений не требует знания всех соответствующих элементов.
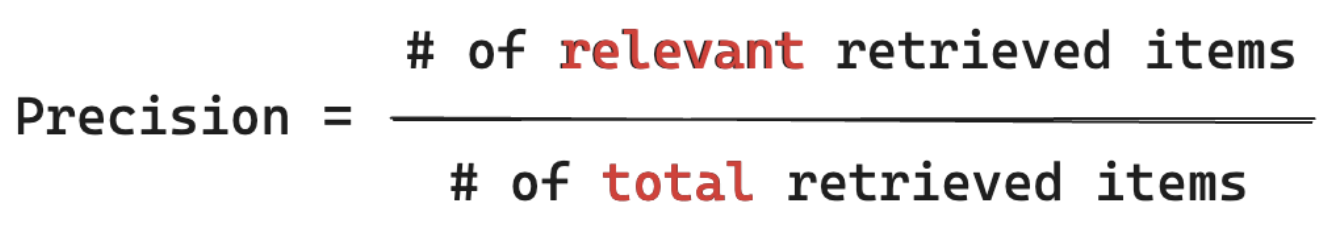
Формула отзыва
Из всех документов, которые, как я знаю, относятся к запросу моего пользователя, из какого процента я извлёк фрагмент? Вычисление полноты требует, чтобы ваши эталонные данные включали все соответствующие элементы. Элементы могут быть документом или блоком документа.
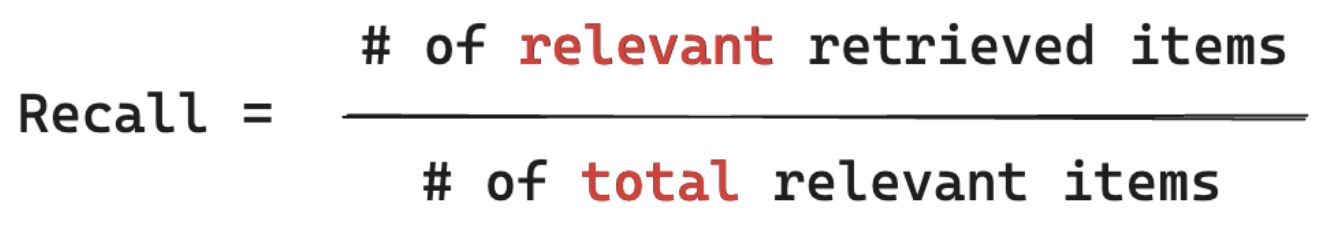
В приведенном ниже примере два из трех полученных результатов относятся к запросу пользователя, поэтому точность составила 0,66 (2/3). Полученные документы включали два из четырех соответствующих документов, поэтому отзыв был 0,5 (2/4).