Настройка шлюза ИИ на конечных точках обслуживания моделей
Из этой статьи вы узнаете, как настроить шлюз ИИ Мозаики в конечной точке обслуживания модели.
Требования
- Рабочая область Databricks в внешних моделях поддерживает регион или подготовленную пропускную способность, поддерживаемую.
- Конечная точка обслуживания модели машинного обучения.
- Чтобы создать точку доступа для обслуживания внешней модели, выполните шаги 1 и 2 из Создание точки доступа для обслуживания внешней модели.
- Чтобы создать конечную точку для зарезервированной пропускной способности, см. интерфейсы API моделей на основе платформы.
Настройка шлюза искусственного интеллекта с помощью пользовательского интерфейса
В этом разделе показано, как настроить шлюз искусственного интеллекта во время создания конечной точки с помощью пользовательского интерфейса обслуживания. Если вы предпочитаете выполнять это программным способом, см. пример записной книжки.
В разделе AI Gateway страницы создания конечной точки можно настроить отдельные функции шлюза AI Gateway. См. поддерживаемые функции, для которых доступны функции во внешних конечных точках обслуживания моделей и подготовленных конечных точках пропускной способности.
| Функция | Включение | Сведения |
|---|---|---|
| Отслеживание использования | Выберите Включить отслеживание использования, чтобы активировать отслеживание и мониторинг показателей использования данных. | — У вас должен быть включен каталог Unity. — администраторы учетных записей должны включить схему системной таблицы перед использованием системных таблиц: system.serving.endpoint_usage, которая фиксирует количество маркеров для каждого запроса к конечной точке и system.serving.served_entities, где хранятся метаданные для каждой базовой модели.— См. схемы таблиц отслеживания использования — Только администраторы учетных записей имеют разрешение на просмотр или запрос таблицы served_entities или endpoint_usage, даже если пользователь, управляющий конечной точкой, должен включить отслеживание использования. См. Предоставить доступ к системным таблицам— Число входных и выходных маркеров оценивается как ( text_length+1)/4, если число маркеров не возвращается моделью. |
| Ведение журнала полезных данных | Выберите Включить таблицы вывода результатов, чтобы с вашего конечного узла автоматически записывать запросы и ответы в таблицы Delta, управляемые каталогом Unity. | — Необходимо включить каталог Unity и доступ CREATE_TABLE в указанной схеме каталога.- Таблицы вывода, активированные шлюзом ИИ, имеют иную схему, чем таблицы вывода , созданные для конечных точек, обслуживающих пользовательские модели. См. схему таблицы вывода заключений с поддержкой шлюза ИИ . — Данные журнала о полезной нагрузке заполняют эти таблицы менее чем через час после выполнения запроса к конечной точке. — Полезные данные размером более 1 МБ не регистрируются. — Полезные данные ответа агрегируют ответ всех возвращаемых блоков. — поддерживается потоковая передача. В сценариях потоковой передачи полезные данные ответа агрегируют ответ возвращаемых блоков. |
| AI Guardrails | См. раздел "Настройка AI Guardrails" в пользовательском интерфейсе. | — Guardrails предотвращает взаимодействие модели с небезопасным и вредным содержимым, обнаруженным в входных и выходных данных модели. — Выходные ограждения не поддерживаются для моделей внедрения или потоковой передачи. |
| Ограничения скорости | Вы можете применить ограничения частоты запросов для управления трафиком для конечной точки на пользователя и на конечную точку | — Ограничения скорости определяются в запросах в минуту (QPM). — значение по умолчанию — нет ограничений для каждого пользователя и каждой конечной точки. |
| Маршрутизация трафика | Сведения о настройке маршрутизации трафика в конечной точке см. в статье "Обслуживание нескольких внешних моделей в конечной точке". |
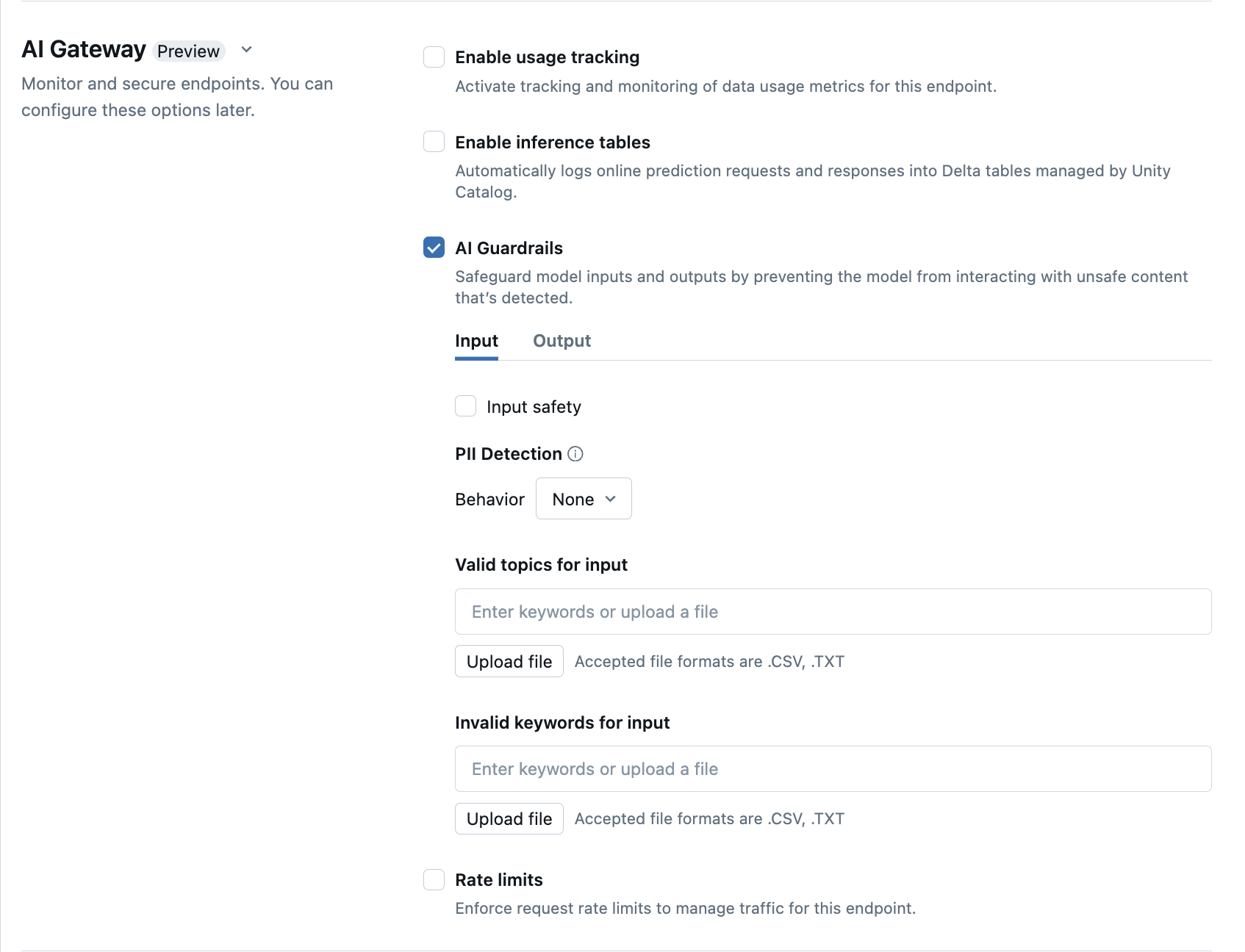
Настройка AI Guardrails в пользовательском интерфейсе
В следующей таблице показано, как настроить поддерживаемые ограничители.
| Проверка | Включение | Сведения |
|---|---|---|
| Безопасность | Выберите Безопасность, чтобы включить защитные меры и предотвратить взаимодействие модели с небезопасным и вредным содержимым. | |
| Обнаружение личных сведений (PII) | Выберите обнаружение PII для поиска данных PII, таких как имена, адреса, номера кредитной карты. | |
| Допустимые разделы | Вы можете вводить разделы непосредственно в это поле. Если у вас несколько записей, обязательно нажмите клавишу ВВОД после каждого раздела. Кроме того, можно отправить .csv файл или .txt файл. |
Можно указать не более 50 допустимых разделов. Каждый раздел не может превышать 100 символов |
| Недопустимые ключевые слова | Вы можете вводить разделы непосредственно в это поле. Если у вас несколько записей, обязательно нажмите клавишу ВВОД после каждого раздела. Кроме того, можно отправить .csv файл или .txt файл. |
Можно указать не более 50 недопустимых ключевых слов. Каждое ключевое слово не может превышать 100 символов. |
схемы таблиц отслеживания использования
Системная таблица отслеживания использования system.serving.served_entities имеет следующую схему:
| Имя столбца | Описание | Тип |
|---|---|---|
served_entity_id |
Уникальный идентификатор обслуживаемой сущности. | STRING |
account_id |
Идентификатор учетной записи клиента для разностного общего доступа. | STRING |
workspace_id |
Идентификатор рабочей области клиента конечной точки обслуживания. | STRING |
created_by |
Идентификатор создателя. | STRING |
endpoint_name |
Имя конечной точки обслуживания. | STRING |
endpoint_id |
Уникальный идентификатор конечной точки обслуживания. | STRING |
served_entity_name |
Имя обслуживаемой сущности. | STRING |
entity_type |
Тип обслуживаемой сущности. Может бытьFEATURE_SPEC, , EXTERNAL_MODELFOUNDATION_MODELилиCUSTOM_MODEL |
STRING |
entity_name |
Базовое имя сущности. Отличается от served_entity_name имени пользователя. Например, entity_name — это имя модели каталога Unity. |
STRING |
entity_version |
Версия обслуживаемой сущности. | STRING |
endpoint_config_version |
Версия конфигурации конечной точки. | INT |
task |
Тип задачи. Возможные значения: llm/v1/chat, llm/v1/completions или llm/v1/embeddings. |
STRING |
external_model_config |
Конфигурации для внешних моделей. Например: {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Конфигурации для базовых моделей. Например: {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400}. |
STRUCT |
custom_model_config |
Конфигурации для пользовательских моделей. Например: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU }. |
STRUCT |
feature_spec_config |
Конфигурации для спецификаций компонентов. Например: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Метка времени изменения для обслуживаемой сущности. | TIMESTAMP |
endpoint_delete_time |
Метка времени удаления сущности. Конечная точка — это контейнер для обслуживаемой сущности. После удаления конечной точки также удаляется обслуживаемая сущность. | TIMESTAMP |
Системная таблица отслеживания использования system.serving.endpoint_usage имеет следующую схему:
| Имя столбца | Описание | Тип |
|---|---|---|
account_id |
Идентификатор учетной записи клиента. | STRING |
workspace_id |
Идентификатор рабочей области клиента конечной точки обслуживания. | STRING |
client_request_id |
Пользователь предоставил идентификатор запроса, который можно указать в тексте запроса на обслуживание модели. | STRING |
databricks_request_id |
Идентификатор запроса, созданный Azure Databricks, присоединённый ко всем запросам для обработки модели. | STRING |
requester |
Идентификатор пользователя или субъекта-службы, разрешения которого используются для запроса вызова конечной точки обслуживания. | STRING |
status_code |
Код состояния HTTP, возвращенный из модели. | INTEGER |
request_time |
Метка времени получения запроса. | TIMESTAMP |
input_token_count |
Число маркеров входных данных. | LONG |
output_token_count |
Число маркеров выходных данных. | LONG |
input_character_count |
Число символов входной строки или запроса. | LONG |
output_character_count |
Число символов выходной строки ответа. | LONG |
usage_context |
Пользователь предоставил карту, содержащую идентификаторы конечного пользователя или клиентского приложения, которое вызывает конечную точку. См. дополнительные сведения об использовании с usage_context. | MAP |
request_streaming |
Указывает, находится ли запрос в режиме потоковой передачи. | BOOLEAN |
served_entity_id |
Уникальный идентификатор, используемый для соединения с таблицей измерений system.serving.served_entities для поиска сведений о конечной точке и обслуживаемой сущности. |
STRING |
Дальнейшее определение использования с помощью usage_context
При запросе внешней модели с включенным отслеживанием использования можно указать параметр с типом usage_contextMap[String, String]. Сопоставление контекста использования отображается в таблице отслеживания использования в столбце usage_context. Размер usage_context карты не может превышать 10 КИБ.
Администраторы учетных записей могут агрегировать различные строки в зависимости от контекста использования, чтобы получить аналитические сведения и присоединить эти сведения к данным в таблице ведения журнала полезных данных. Например, можно добавить end_user_to_chargeusage_context в отслеживание затраты на отслеживание для конечных пользователей.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Обновление функций шлюза искусственного интеллекта в конечных точках
Вы можете обновить функции шлюза ИИ на конечных точках обслуживания моделей как для тех, где они были ранее включены, так и для тех, где не были. Обновления конфигураций шлюза искусственного интеллекта занимают около 20–40 секунд, однако ограничение скорости обновлений может занять до 60 секунд.
Ниже показано, как обновить функции шлюза искусственного интеллекта в конечной точке обслуживания модели с помощью пользовательского интерфейса обслуживания.
В разделе шлюза на странице конечной точки можно увидеть, какие функции включены. Чтобы обновить эти функции, щелкните , чтобы изменить шлюз ИИ.

Пример записной книжки
В следующей записной книжке показано, как программно включить и использовать функции шлюза Databricks Mosaic AI для управления моделями от поставщиков. Дополнительные сведения об REST API см. в следующих статьях: