Развертывание рабочей нагрузки IoT Edge с помощью совместного использования GPU на Azure Stack Edge Pro
В этой статье описывается, как контейнерные рабочие нагрузки могут совместно использовать GPU на устройстве Azure Stack Edge Pro GPU. Этот подход включает в себя включение многопроцессной службы (MPS) и указание рабочих нагрузок GPU с помощью развертывания IoT Edge.
Необходимые компоненты
Перед тем как начать, убедитесь в следующем.
У вас есть доступ к подключенному устройству Azure Stack Edge Pro GPU, которое было активировано и настроено для вычислений. У вас есть Конечная точка API Kubernetes, и вы добавили эту конечную точку в файл
hostsна клиенте, который будет получать доступ к устройству.У вас есть доступ к клиентской системе с поддерживаемой операционной системой. При использовании клиента Windows система должна запустить PowerShell 5.0 или более поздней версии для доступа к устройству.
Сохраните следующее развертывание
jsonв локальной системе. Вы будете использовать сведения из этого файла для запуска развертывания IoT Edge. Это развертывание основано на простых контейнерах CUDA, общедоступных из NVIDIA.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Проверка драйвера GPU, версия CUDA
Первым делом необходимо убедиться, что на устройстве выполняются требуемые версии драйвера GPU и CUDA.
Выполните следующую команду:
Get-HcsGpuNvidiaSmiВ выходных данных устройства NVIDIA SMI запишите версию GPU и версию CUDA, установленные на вашем устройстве. Если вы используете программное обеспечение Azure Stack Edge 2102, эта версия будет соответствовать следующим версиям драйвера:
- Версия драйвера GPU: 460.32.03
- Версия CUDA: 11.2
Пример выходных данных:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Не закрывайте эту сессию, так как она будет использоваться для просмотра выходных данных SMI для NVIDIA в этой статье.
Развертывание без общего доступа к контексту
Теперь вы можете развернуть приложение на устройстве, если служба многопроцессной обработки не запущена и нет общего доступа к контексту. Развертывание осуществляется через портал Azure в пространстве имен iotedge, которое существует на вашем устройстве.
Создание пользователя в пространстве имен IoT Edge
Сначала вы создадите пользователя, который будет подключаться к пространству имен iotedge. Модули IoT Edge развертываются в пространстве имен iotedge. Дополнительные сведения см. в разделе пространства имен Kubernetes на устройстве.
Выполните следующие действия, чтобы создать пользователя и предоставить ему доступ к пространству имен iotedge.
Создайте нового пользователя в пространстве имен
iotedge. Выполните следующую команду:New-HcsKubernetesUser -UserName <user name>Пример выходных данных:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Скопируйте выходные данные в виде обычного текста. Сохраните выходные данные в виде файла конфигурации (без расширения) в папке
.kubeвашего профиля пользователя на локальном компьютере, напримерC:\Users\<username>\.kube.Предоставьте созданному вами пользователю доступ к пространству имен
iotedge. Выполните следующую команду:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Пример выходных данных:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Подробные инструкции см. в статье Подключение к кластеру Kubernetes и управление им с помощью kubectl на устройстве Azure Stack Edge Pro GPU.
Развертывание модулей с помощью портала
Развертывание и мониторинг модулей IoT Edge с помощью портала Azure. Вы развернете общедоступные образцы модулей NVIDIA CUDA, которые выполняют имитацию n-Body.
Убедитесь, что на вашем устройстве запущена служба IoT Edge.
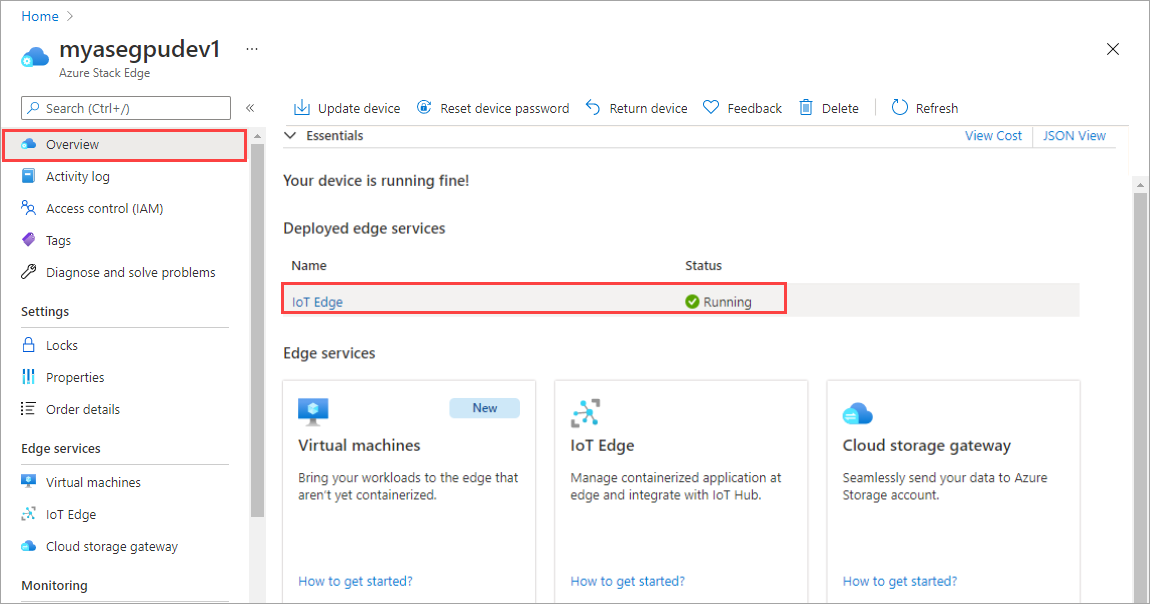
Щелкните плитку IoT Edge на правой панели. Перейдите к свойствам IoT Edge>. На правой панели выберите ресурс центра Интернета вещей, связанный с устройством.
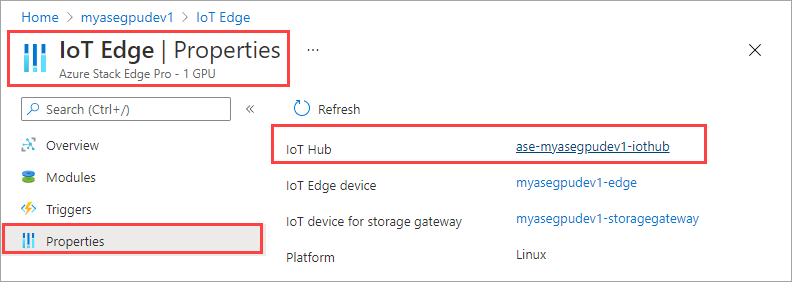
В ресурсе Центр Интернета вещей перейдите в раздел "Автоматический Управление устройствами > IoT Edge". На правой панели выберите устройство IoT Edge, связанное с устройством.
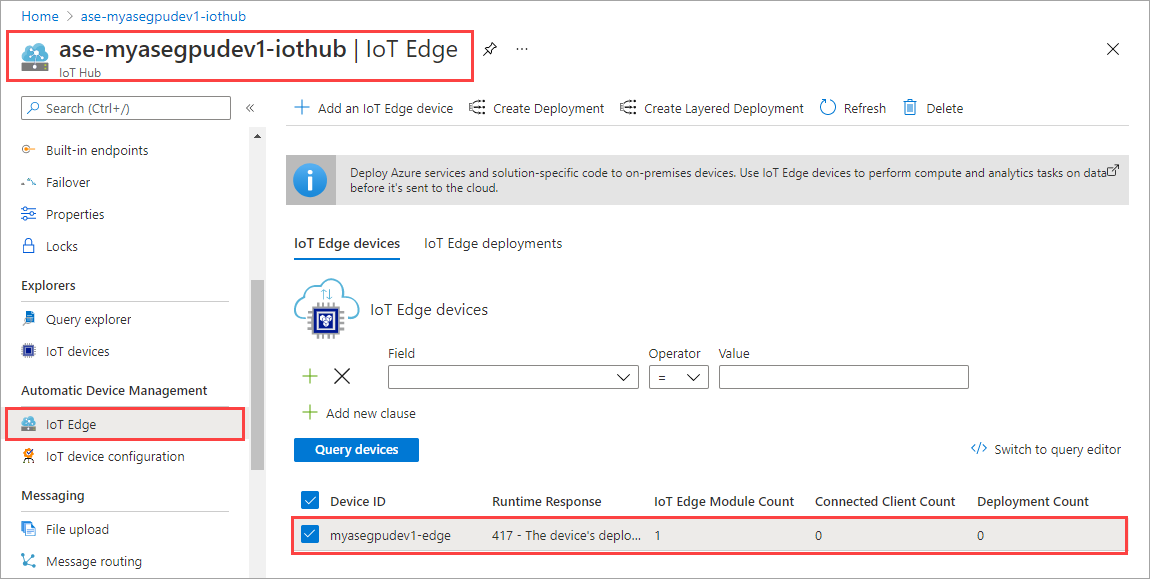
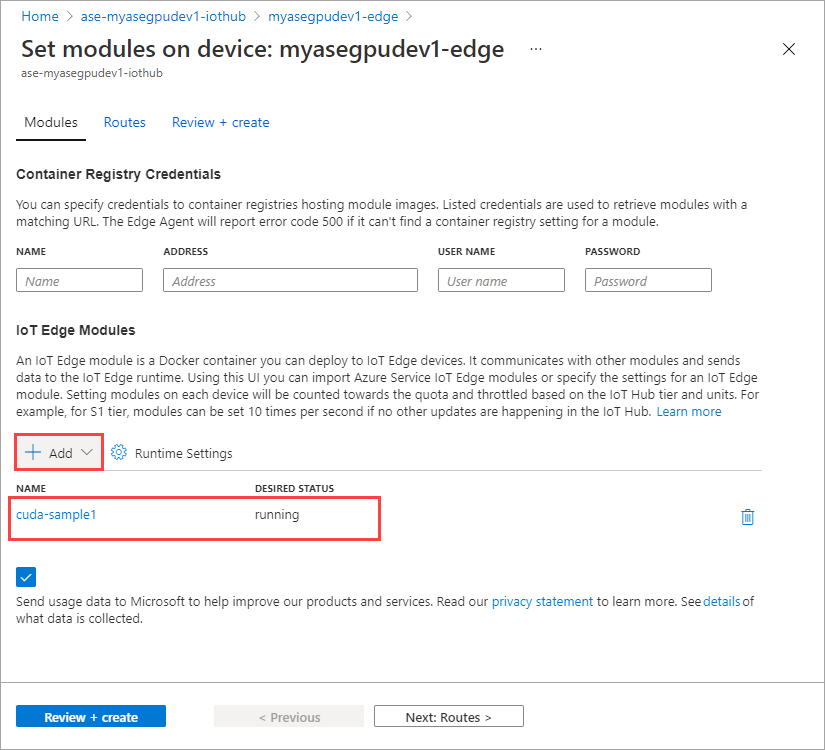
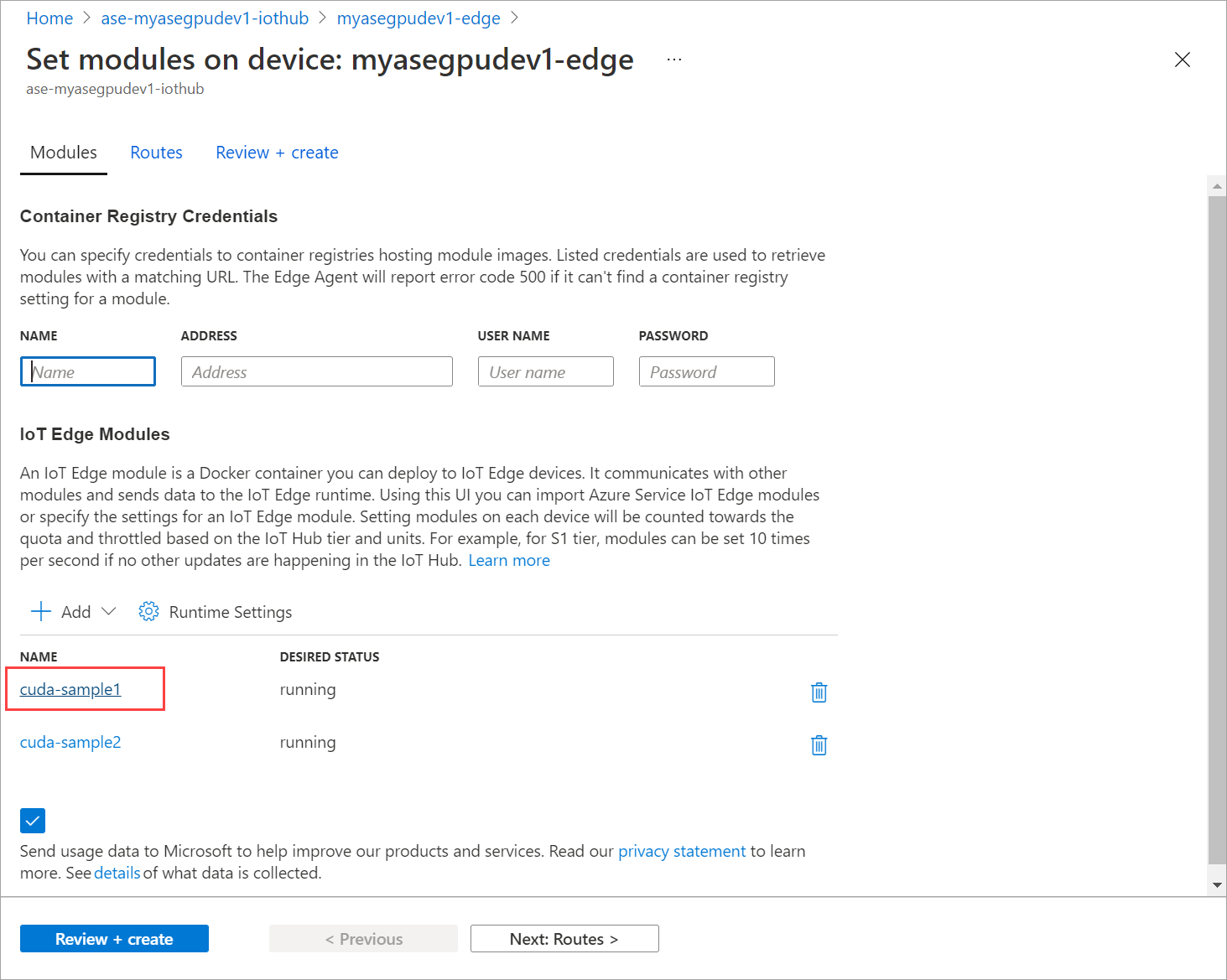
Щелкните Set modules (Настроить модули).
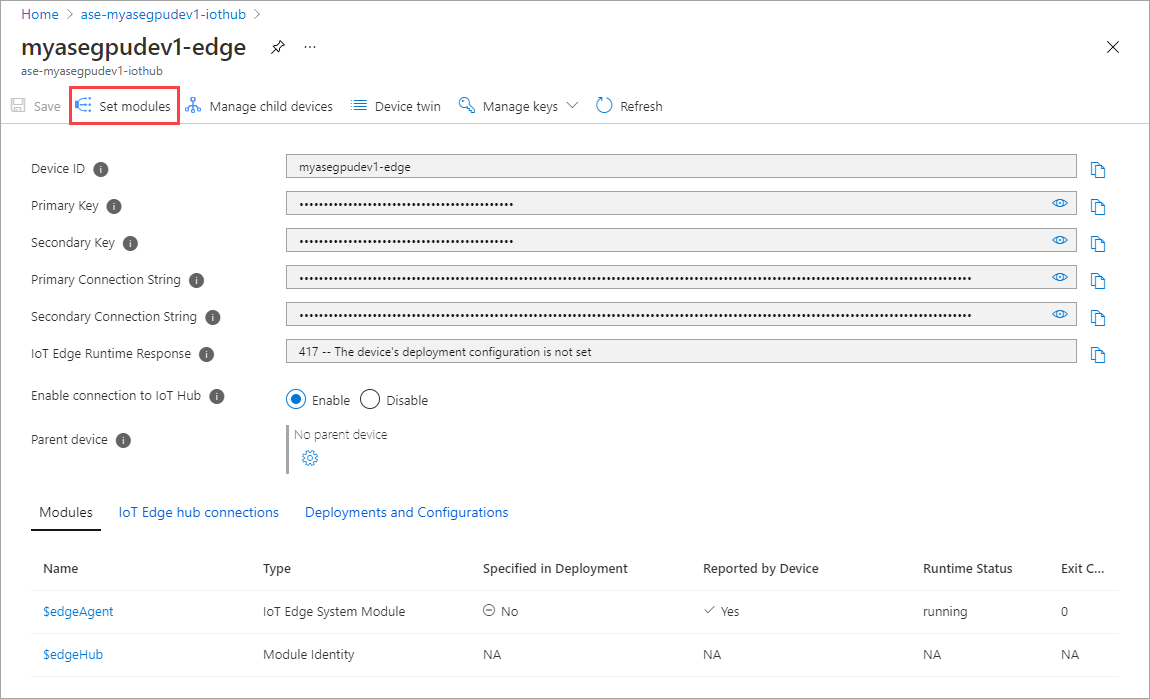
Выберите и добавьте и модуль > IoT Edge.
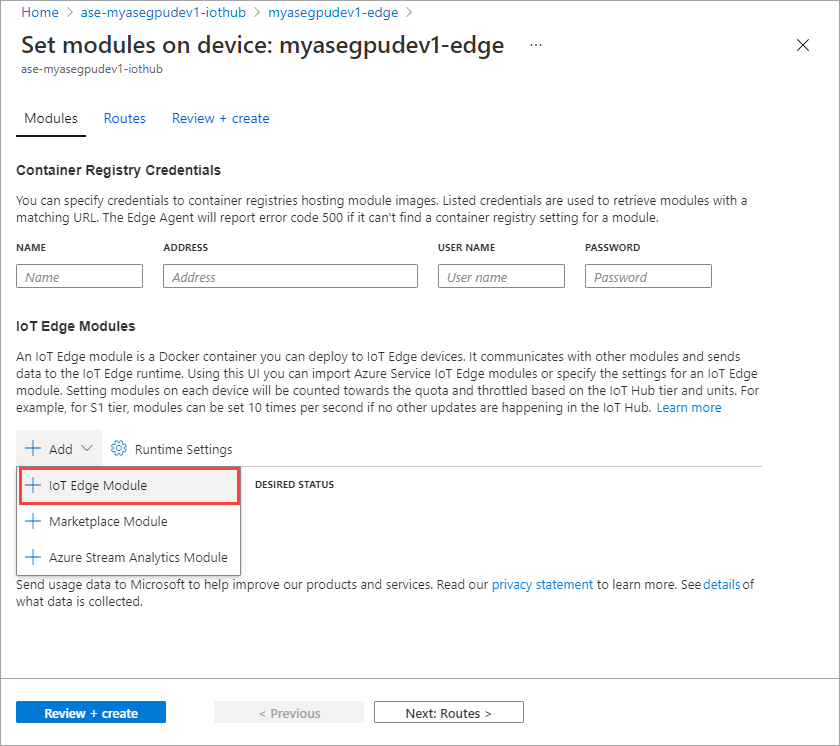
На вкладке Параметры модуля укажите имя модуля IOT Edge и URI образа. Задайте для параметра опрашивающей политики образа значение При создании.
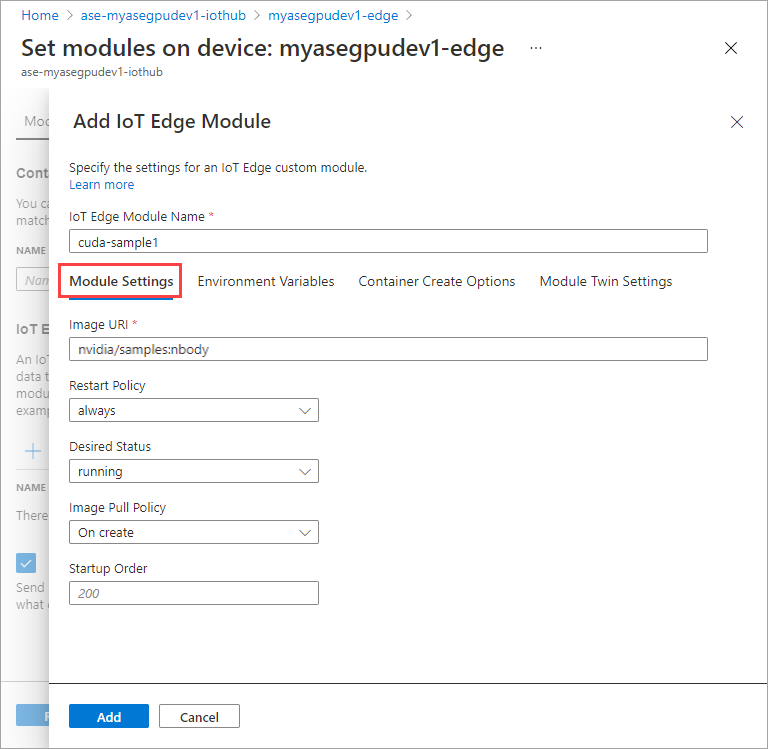
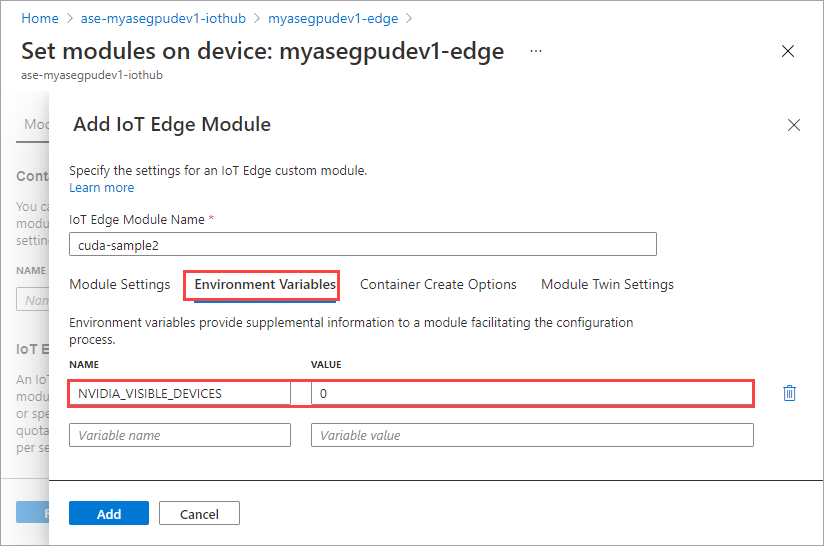
На вкладке переменные среды укажите NVIDIA_VISIBLE_DEVICES как 0.
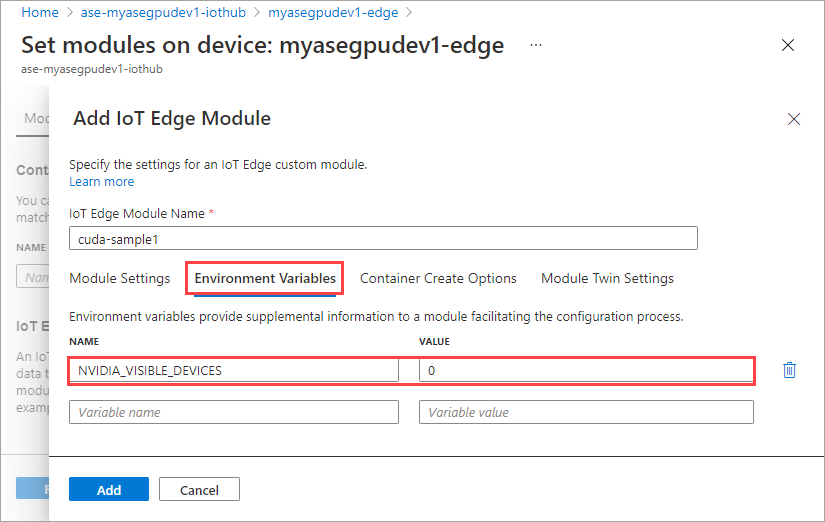
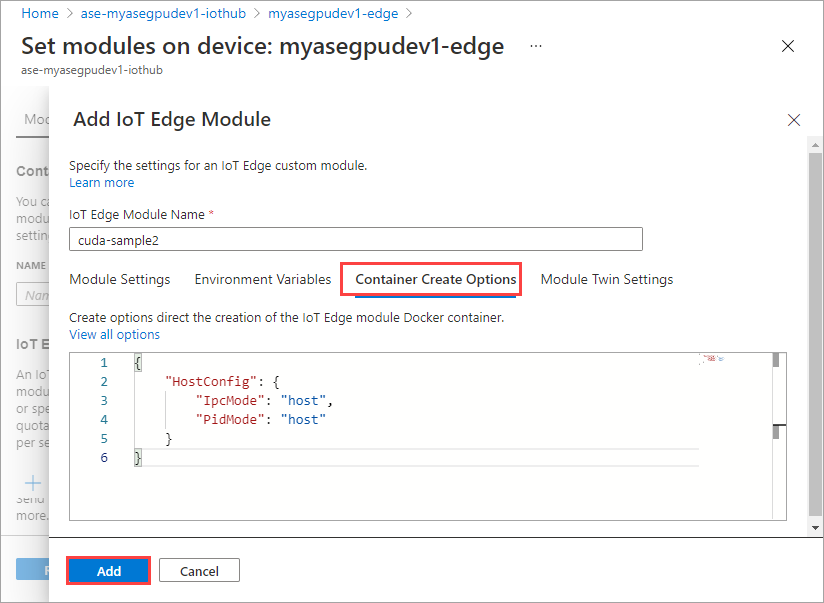
На вкладке Параметры создания контейнера укажите следующие параметры:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Параметры определяются следующим образом:
Выберите Добавить.
Добавленный модуль должен отображаться как выполняемый.
Повторите все шаги, чтобы добавить модуль, который вы составите при добавлении первого модуля. В этом примере укажите имя модуля в виде
cuda-sample2.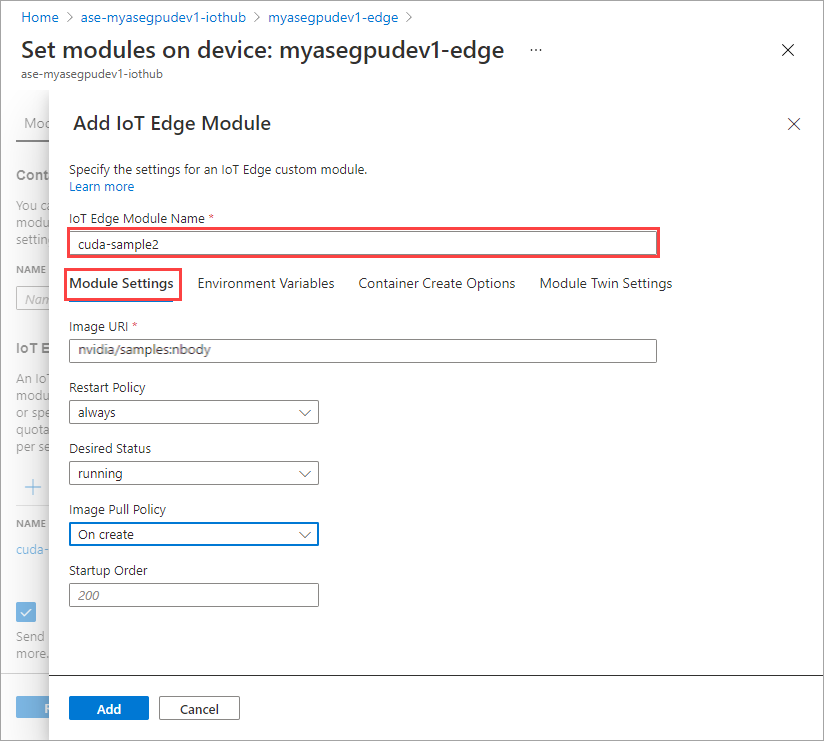
Используйте ту же переменную среды, в которой оба модуля будут совместно использовать один GPU.
Используйте те же параметры создания контейнера, которые вы указали для первого модуля, и нажмите кнопку Добавить.
На странице Установка модулей выберите Проверить и создать, а затем щелкните Создать.
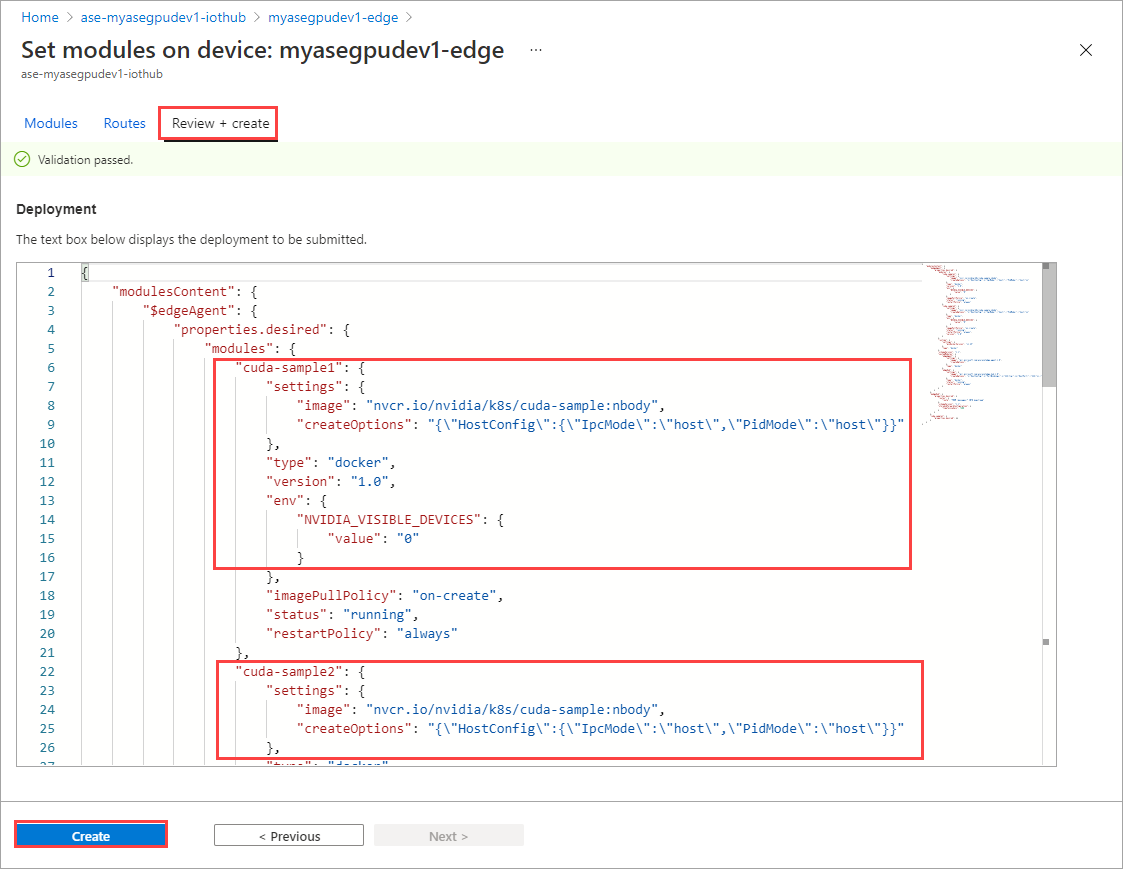
Состояние среды выполнения обоих модулей должно отобразиться как выполняемое.
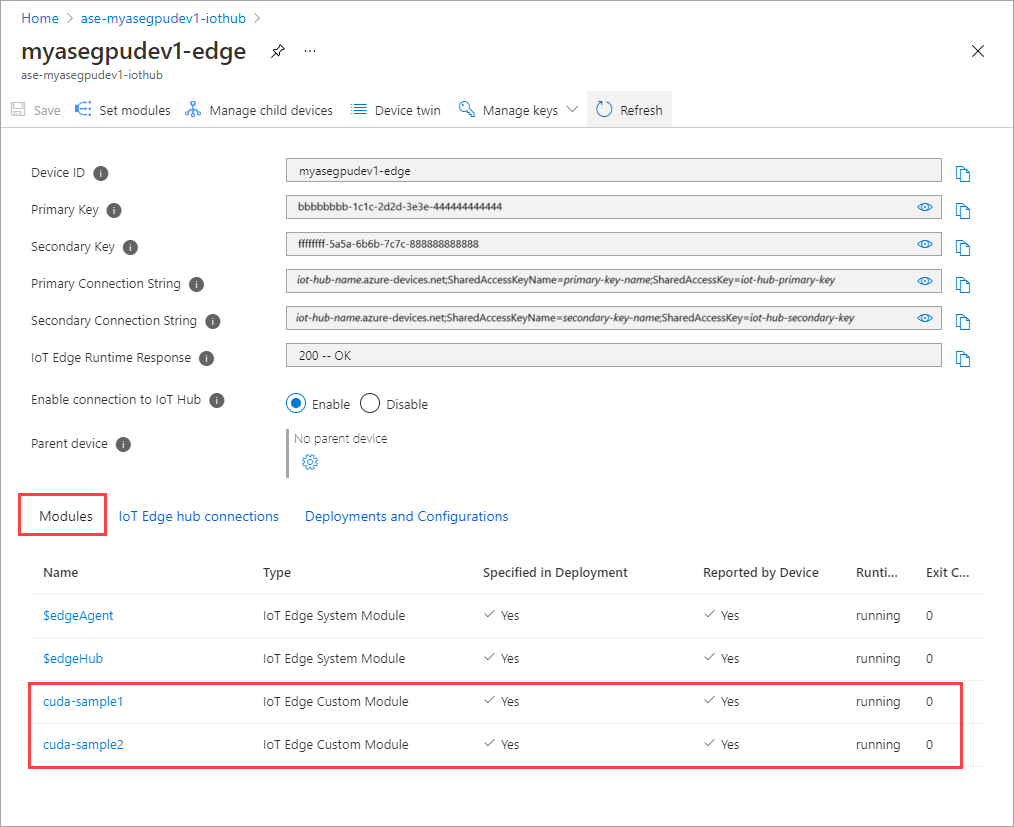
Мониторинг развертывания рабочей нагрузки
Запустите новый сеанс PowerShell.
Выведите список модулей Pod, выполняющихся в пространстве имен
iotedge. Выполните следующую команду:kubectl get pods -n iotedgeПример выходных данных:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>На вашем устройстве работают два модуля (Pod):
cuda-sample1-97c494d7f-lnmnsиcuda-sample2-d9f6c4688-2rld9.Пока оба контейнера работают с имитацией n-Body, просмотрите использование GPU из выходных данных NVIDIA SMI. Перейдите к интерфейсу PowerShell устройства и выполните команду
Get-HcsGpuNvidiaSmi.Ниже приведен пример выходных данных, когда оба контейнера работают с имитацией n-Body:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Как видите, существует два контейнера, работающих с имитацией n-Body в GPU 0. Можно также просмотреть соответствующее использование памяти.
После завершения моделирования выходные данные NVIDIA SMI будут показывать, что на устройстве не запущено ни одного процесса.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>После завершения имитации n-Body просмотрите журналы, чтобы понять сведения о развертывании и время, необходимое для завершения моделирования.
Ниже приведен пример вывода в первом контейнере:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Ниже приведен пример вывода во втором контейнере:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Останавливает развертывание модуля. В ресурсе центра Интернета вещей для вашего устройства:
Перейдите в раздел " Автоматическое развертывание > устройств IoT Edge". Выберите устройство IoT Edge, соответствующее устройству.
Перейдите к разделу Настройка модулей и выберите модуль.
На вкладке Модули выберите модуль.
На вкладке Параметры модуля задайте для параметра Желательное состояние значение остановлено. Выберите Обновить.
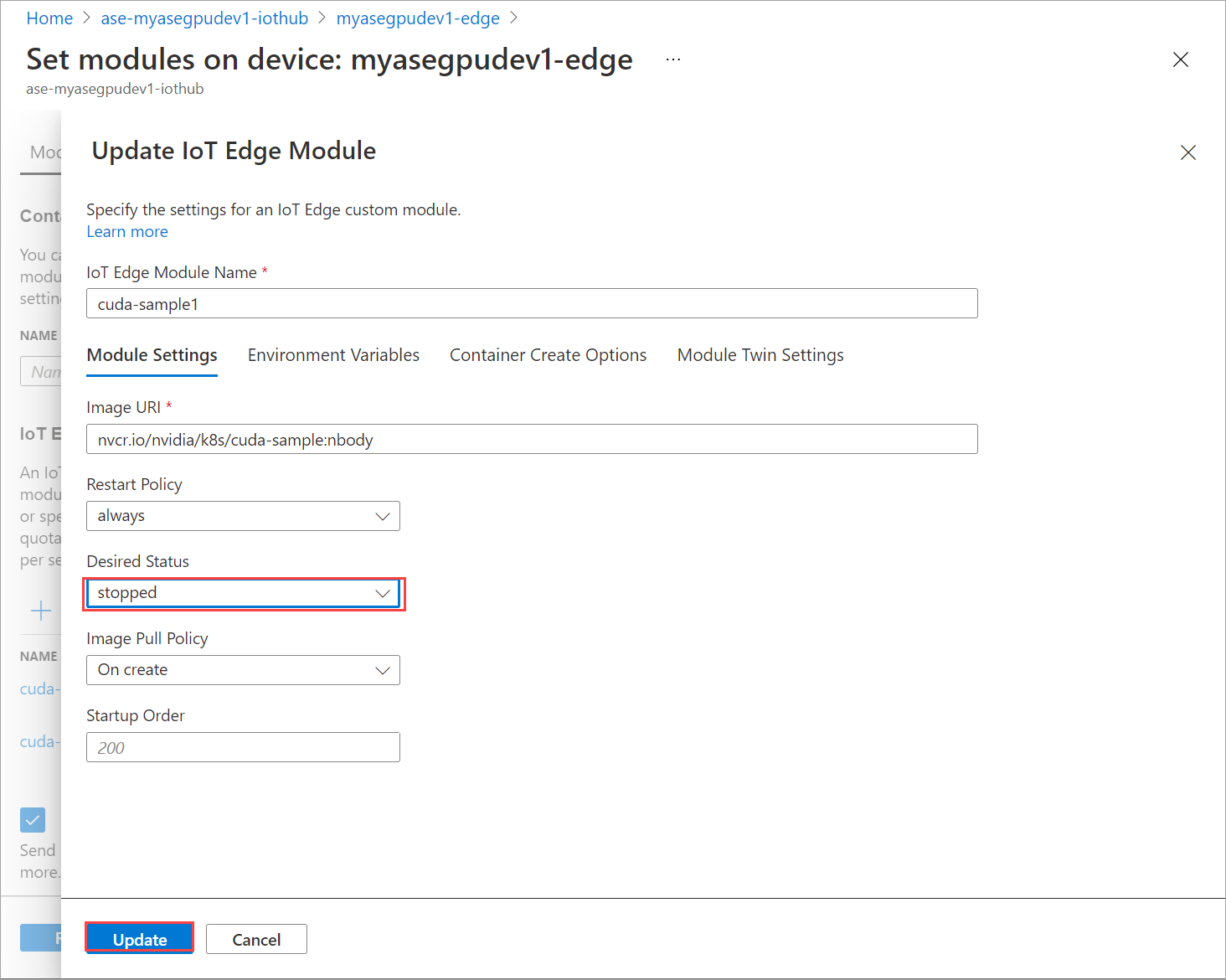
Повторите шаги, чтобы закрыть второй модуль, развернутый на устройстве. Выберите Просмотр и создание, а затем нажмите кнопку Создать. Это должно обновить развертывание.
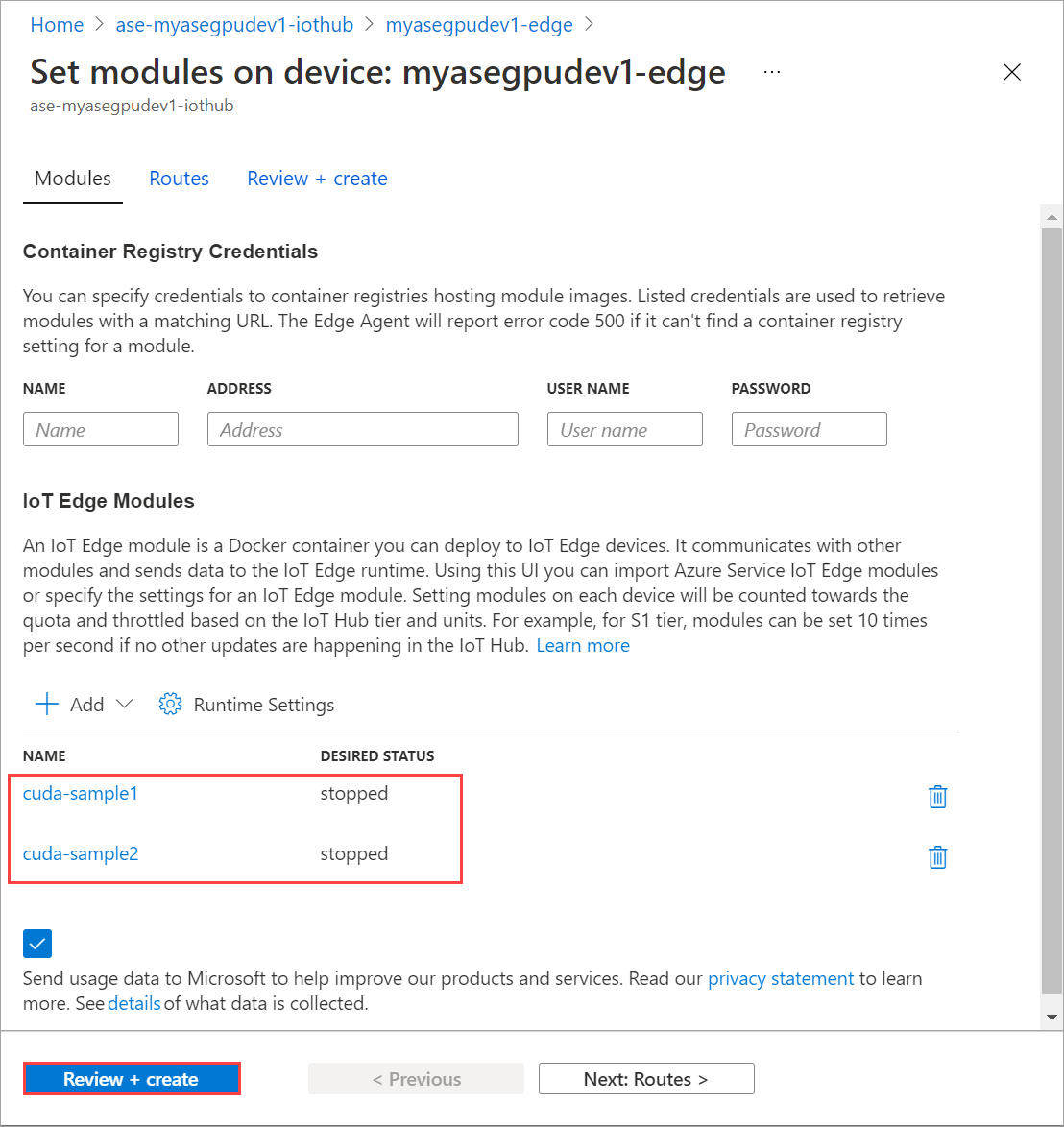
Перезагрузите страницу Установка модулей несколько раз, пока состояние выполнения модуля не будет отображаться как остановленное.
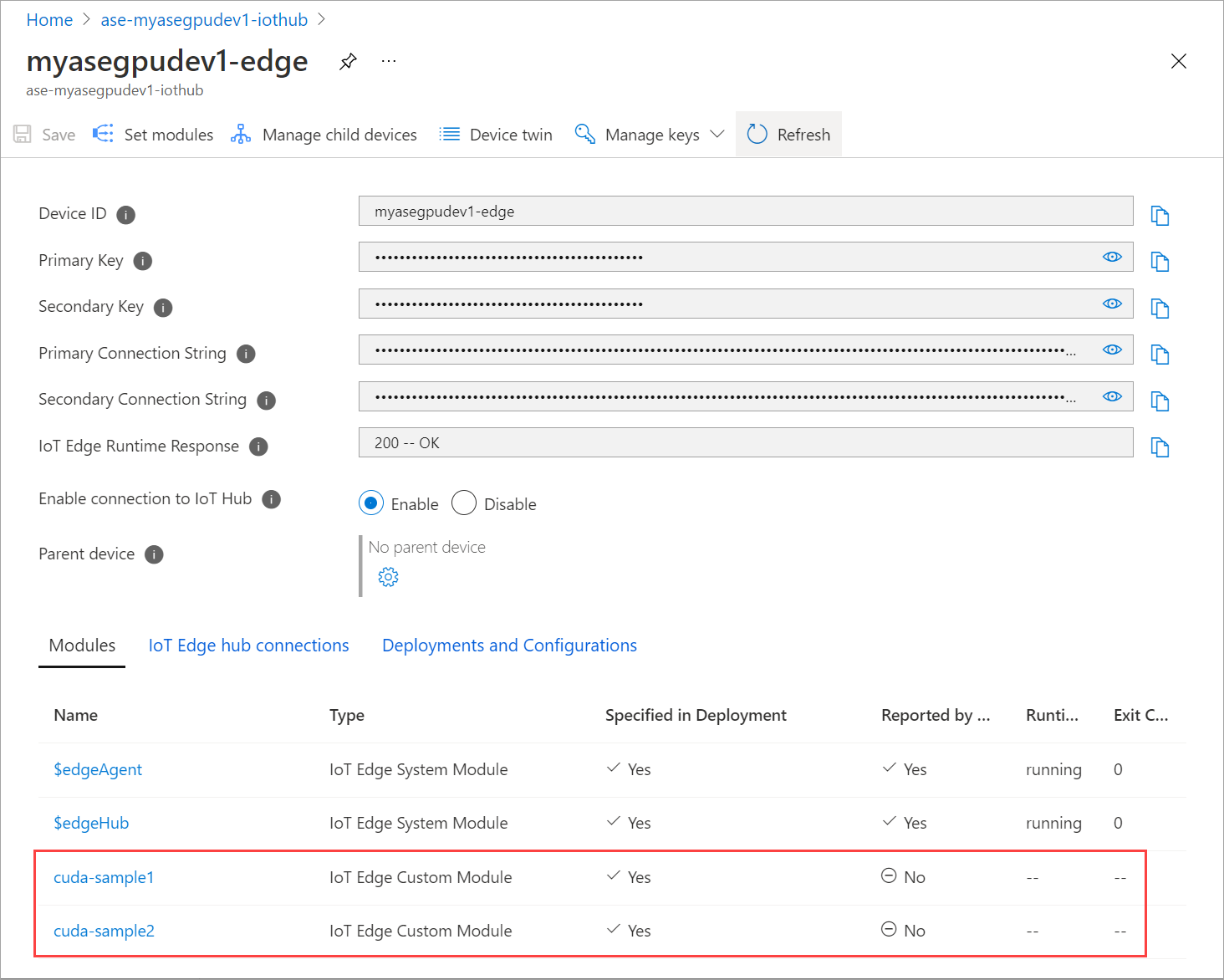
Развертывание с совместно используемым контекстом
Теперь можно развернуть модель n-Body в двух контейнерах CUDA при выполнении MPS на устройстве. Во-первых, вы включите MPS на устройстве.
Чтобы включить MPS на устройстве, выполните команду
Start-HcsGpuMPS.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Получение выходных данных NVIDIA SMI из интерфейса PowerShell устройства. На устройстве можно увидеть, что процесс
nvidia-cuda-mps-serverили служба MPS запущена.Пример выходных данных:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiРазверните модули, которые были остановлены ранее. Задайте требуемое состояние для выполнения через Настройку модулей.
Ниже приведен пример выходных данных.
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Вы увидите, что модули развернуты и запущены на вашем устройстве.
При развертывании модулей эмуляция n-Body также начинает работать в обоих контейнерах. Ниже приведен пример выходных данных при завершении имитации в первом контейнере:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Ниже приведен пример выходных данных по завершении имитации во втором контейнере:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Получите выходные данные NVIDIA SMI из интерфейса PowerShell устройства, когда оба контейнера работают с имитацией n-Body. Ниже приведен пример выходных данных. Существует три процесса: процесс
nvidia-cuda-mps-server(тип C) соответствует службе MPS, а процессы/tmp/nbody(тип M + C) соответствуют рабочим нагрузкам n-Body, развернутым модулями.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi