Копирование и преобразование данных в Snowflake с помощью Фабрика данных Azure или Azure Synapse Analytics (устаревшая версия)
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описано использование действия Copy в Фабрике данных Azure и конвейерах Azure Synapse, чтобы копировать данные в хранилище Snowflake и из него, а также использовать Поток данных для преобразования данных в Snowflake. Подробнее см. во вводной статье о Фабрике данных или Azure Synapse Analytics.
Внимание
Новый соединитель Snowflake обеспечивает улучшенную встроенную поддержку Snowflake. Если вы используете устаревший соединитель Snowflake в решении, обновите соединитель Snowflake до 31 октября 2024 года. Дополнительные сведения о различиях между устаревшей и последней версией см. в этом разделе .
Поддерживаемые возможности
Этот соединитель Snowflake поддерживается для возможностей, указанных ниже:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/приемник) | (1) (2) |
| Поток данных для сопоставления (источник/приемник) | (1) |
| Действие поиска | (1) (2) |
| Действие скрипта | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Для действия Copy данный соединитель Snowflake поддерживает функции, описанные ниже.
- Копирование данных из Snowflake, при котором используется команда Snowflake КОПИРОВАТЬ в [расположение] для наибольшей производительности.
- Копирование данных в Snowflake, при котором используется преимущество команды Snowflake КОПИРОВАТЬ в [таблицу] для наибольшей производительности. Поддерживает Snowflake в Azure.
- Если для подключения к Snowflake из автономной среды выполнения интеграции требуется прокси-сервер, необходимо настроить переменные среды для HTTP_PROXY и HTTPS_PROXY на узле среды выполнения интеграции.
Необходимые компоненты
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции. Обязательно добавьте IP-адреса, которые использует локальная среда выполнения интеграции, в список разрешенных.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешенных.
Учетная запись Snowflake, используемая для источника или приемника, должна иметь необходимый USAGE доступ к базе данных и доступ на чтение и запись в схеме и таблицах и представлениях под ним. Кроме того, у нее должны быть права CREATE STAGE для схемы, чтобы создавать внешний этап с URI SAS.
Необходимо задать приведенные ниже значения свойств учетной записи.
| Свойство | Описание: | Обязательное поле | По умолчанию. |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Указывает, требуется ли объект интеграции хранилища в качестве облачных учетных данных при создании именованного внешнего этапа (с помощью CREATE STAGE) для доступа к расположению частного облака. | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Указывает, требуется ли использовать именованный внешний этап, который ссылается на объект интеграции хранилища в качестве облачных учетных данных при загрузке данных из частного облачного хранилища или выгрузке данных в него. | FALSE | FALSE |
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
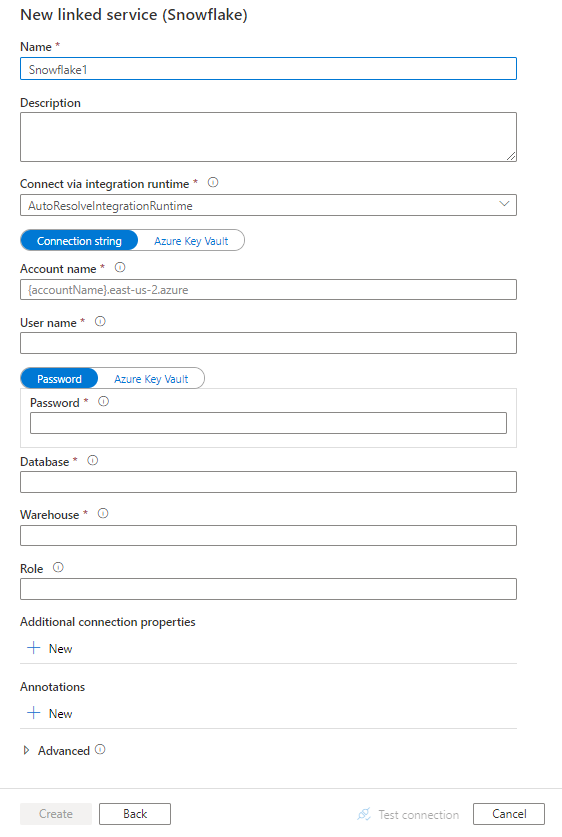
Создание связанной службы со Snowflake с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Snowflake с помощью пользовательского интерфейса на портале Azure.
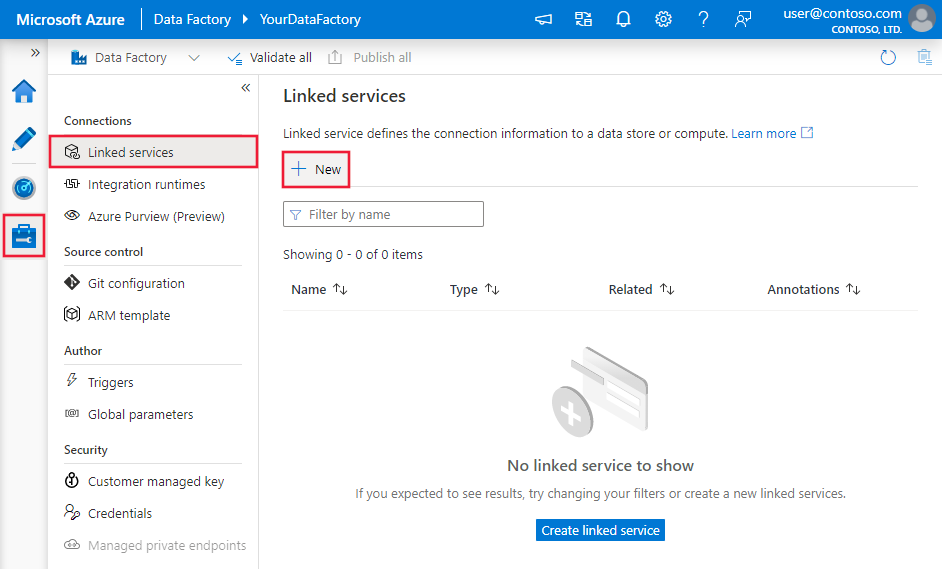
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Snowflake и выберите соединитель Snowflake.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, используемых для определения сущностей, относящихся к соединителю Snowflake.
Свойства связанной службы
Этот соединитель Snowflake поддерживает следующие типы проверки подлинности. Дополнительные сведения см. в соответствующих разделах.
Обычная проверка подлинности
Следующие свойства поддерживаются для связанной службы Snowflake при использовании базовой проверки подлинности.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение Snowflake. | Да |
| connectionString | Указывает сведения, необходимые для подключения к экземпляру Snowflake. Можно указать ввод пароля или всей строки подключения в Azure Key Vault. Дополнительные сведения см. в примерах ниже таблицы и учетных данных Магазина в Azure Key Vault . Ниже приведены некоторые стандартные параметры. - Имя учетной записи: полное имя учетной записи для учетной записи Snowflake (в том числе дополнительные сегменты, обозначающие регион и облачную платформу), например xy12345.east-us-2.azure. - Имя пользователя: регистрационное имя пользователя для подключения. - Пароль: пароль пользователя. - База данных: база данных по умолчанию, используемая после подключения. Следует указать существующую базу данных, для которой указанная роль имеет привилегии. - Хранилище: виртуальное хранилище, которое будет использоваться после подключения. Следует указать существующее хранилище, для которого указанная роль имеет привилегии. - Роль: роль управления доступом по умолчанию для использования в сеансе Snowflake. Указанная роль должна быть существующей ролью, уже назначенной указанному пользователю. Ролью по умолчанию является PUBLIC. |
Да |
| authenticationType | Задайте для этого свойства значение Basic. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется среда выполнения интеграции Azure. | No |
Пример:
{
"name": "SnowflakeLinkedService",
"properties": {
"type": "Snowflake",
"typeProperties": {
"authenticationType": "Basic",
"connectionString": "jdbc:snowflake://<accountname>.snowflakecomputing.com/?user=<username>&password=<password>&db=<database>&warehouse=<warehouse>&role=<myRole>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пароль в Azure Key Vault.
{
"name": "SnowflakeLinkedService",
"properties": {
"type": "Snowflake",
"typeProperties": {
"authenticationType": "Basic",
"connectionString": "jdbc:snowflake://<accountname>.snowflakecomputing.com/?user=<username>&db=<database>&warehouse=<warehouse>&role=<myRole>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных.
Для набора данных Snowflake поддерживаются свойства, указанные ниже.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение SnowflakeTable. | Да |
| schema | Имя схемы. Обратите внимание, что имя схемы чувствительно к регистру. | "Нет" для источника, "Да" для приемника |
| table | Имя таблицы или представления. Обратите внимание, что имя таблицы чувствительно к регистру. | "Нет" для источника, "Да" для приемника |
Пример:
{
"name": "SnowflakeDataset",
"properties": {
"type": "SnowflakeTable",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе приведен список свойств, поддерживаемых источником и приемником Snowflake.
Snowflake в качестве источника
Соединитель Snowflake использует команду Snowflake КОПИРОВАТЬ в [расположение] для наибольшей производительности.
Если хранилище данных приемника и формат изначально поддерживаются командой COPY из Snowflake, можно использовать действие Copy для прямого копирования из Snowflake в приемник. Дополнительные сведения см. в разделе Прямое копирование из Snowflake. В ином случае используйте встроенную функцию Промежуточное копирование из Snowflake.
Для копирования данных из Snowflake в разделе источник для действия Copy поддерживаются свойства, описанные ниже.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type действия Copy должно иметь значение SnowflakeSource. | Да |
| query | Определяет SQL-запрос для чтения данных из Snowflake. Если имена схемы, таблицы и столбцов содержат строчные буквы, заключайте идентификатор объекта в кавычки, например select * from "schema"."myTable".Выполнение хранимой процедуры не поддерживается. |
No |
| exportSettings | Дополнительные параметры, используемые для получения данных из Snowflake. Можно настроить параметры, поддерживаемые командой COPY, в команде, которую будет передавать служба при вызове оператора. | Да |
В разделе exportSettings: |
||
| type | Тип команды экспорта устанавливается как SnowflakeExportCopyCommand. | Да |
| additionalCopyOptions | Дополнительные параметры копирования, предоставляемые в виде словаря для пар "ключ-значение". Примеры: MAX_FILE_SIZE, OVERWRITE. Дополнительные сведения см. в разделе Параметры копирования в Snowflake. | No |
| additionalFormatOptions | Дополнительные параметры формата файла, предоставляемые для команды КОПИРОВАТЬ в виде словаря для пар "ключ-значение". Примеры: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Дополнительные сведения см. в разделе Параметры типа формата в Snowflake. | No |
Примечание.
Убедитесь, что у вас есть разрешение на выполнение следующей команды и доступ к схеме INFORMATION_SCHEMA и таблице COLUMNS.
COPY INTO <location>
Прямое копирование из Snowflake
Если хранилище данных приемника и формат соответствуют критериям, описанным в этом разделе, действие Copy можно использовать для прямого копирования из Snowflake в приемник. Служба проверяет параметры и завершает выполнение действие Copy, если следующие критерии не выполнены:
Связанная служба приемника — это хранилище BLOB-объектов Azure с проверкой подлинности подписанного URL-адреса. Если надо напрямую копировать данные в Azure Data Lake Storage 2-го поколения в следующем поддерживаемом формате, можно создать связанную службу BLOB-объектов Azure с проверкой подлинности SAS в соответствии с учетной записью ADLS 2-го поколения, чтобы не применять промежуточное копирование из Snowflake.
Формат данных приемника — Parquet, текст с разделителями или JSON с нижеуказанными конфигурациями.
- Для формата Parquet кодек сжатия — None, Snappyили LZO.
- Для формата текста с разделителями:
- для
rowDelimiterможно указать \r\n или любой отдельный символ; - параметр
compressionможет иметь значение no compression, gzip, bzip2 или deflate. - В параметре
encodingNameоставляется значение по умолчанию или задается значение utf-8. - для
quoteCharможет использоваться двойная кавычка, одинарная кавычкаили пустая строка (без кавычек).
- для
- Для формата JSON прямое копирование поддерживается только в том случае, если таблица источника Snowflake или результат запроса содержат только один столбец, и для данных этого столбца задан тип VARIANT, OBJECT или ARRAY.
- параметр
compressionможет иметь значение no compression, gzip, bzip2 или deflate. - В параметре
encodingNameоставляется значение по умолчанию или задается значение utf-8. - В параметре
filePatternв приемнике действия копирования оставляется значение по умолчанию или задается значение setOfObjects.
- параметр
В источнике
additionalColumnsдействия копирования не указано.Сопоставление столбцов не указано.
Пример:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Промежуточное копирование из Snowflake
Если хранилище данных приемника или формат не совместимы с командой Snowflake COPY, как упоминалось в последнем разделе, включите встроенную поэтапное копирование с помощью промежуточного экземпляра хранилища BLOB-объектов Azure. Функция поэтапного копирования также обеспечивает более высокую пропускную способность. Служба экспортирует данные из Snowflake в промежуточное хранилище, затем копирует данные в приемник и, наконец, очищает промежуточное хранилище от временных данных. Подробные данные о копировании с использованием промежуточного процесса см. в разделе Промежуточное копирование.
Чтобы использовать эту функцию, создайте связанную службу хранения BLOB-объектов Azure, которая обращается к учетной записи хранения Azure в рамках промежуточного процесса. Затем укажите свойства enableStaging и stagingSettings в действии Copy.
Примечание.
Связанная служба промежуточного хранилища BLOB-объектов Azure должна использовать проверку подлинности подписанного URL-адреса, как это требуется для команды КОПИРОВАТЬ в Snowflake. Убедитесь, что вы предоставляете правильное разрешение на доступ к Snowflake в промежуточном хранилище BLOB-объектов Azure. Дополнительные сведения об этом см. в этой статье.
Пример:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Snowflake в качестве приемника
Соединитель Snowflake использует команду Snowflake КОПИРОВАТЬ в [таблицу] для наибольшей производительности. Он поддерживает запись данных в Snowflake в Azure.
Если хранилище данных источника и формат изначально поддерживаются командой КОПИРОВАТЬ из Snowflake, можно использовать действие копирования для прямого копирования из источника в Snowflake. Дополнительные сведения см. в разделе Прямое копирование в Snowflake. В ином случае используйте встроенную функцию Промежуточное копирование в Snowflake.
Для копирования данных в Snowflake в разделе источник для действия Copy поддерживаются свойства, указанные ниже.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для приемника действия Copy должно иметь значение SnowflakeSink. | Да |
| preCopyScript | Перед записью данных в базу данных Snowflake при каждом запуске указывайте SQL-запрос для выполнения действия Copy. Это свойство используется для очистки предварительно загруженных данных. | No |
| importSettings | Дополнительные параметры, используемые для записи данных в Snowflake. Можно настроить параметры, поддерживаемые командой COPY, в команде, которую будет передавать служба при вызове оператора. | Да |
В разделе importSettings: |
||
| type | Тип команды импорта устанавливается как SnowflakeImportCopyCommand. | Да |
| additionalCopyOptions | Дополнительные параметры копирования, предоставляемые в виде словаря для пар "ключ-значение". Примеры: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Дополнительные сведения см. в разделе Параметры копирования в Snowflake. | No |
| additionalFormatOptions | Дополнительные параметры формата файла, предоставляемые для команды КОПИРОВАТЬ, предоставляются в виде словаря для пар "ключ-значение". Примеры: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Дополнительные сведения см. в разделе Параметры типа формата в Snowflake. | No |
Примечание.
Убедитесь, что у вас есть разрешение на выполнение следующей команды и доступ к схеме INFORMATION_SCHEMA и таблице COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Прямое копирование в Snowflake
Если хранилище данных источника и формат соответствуют критериям, описанным в этом разделе, действие Copy можно использовать для прямого копирования из источника в Snowflake. Служба проверяет параметры и завершает выполнение действие Copy, если следующие критерии не выполнены:
Связанная служба источника — это хранилище BLOB-объектов Azure с проверкой подлинности подписанного URL-адреса. Если вы хотите напрямую копировать данные из Azure Data Lake Storage 2-го поколения в следующем поддерживаемом формате, можно создать связанную службу BLOB-объектов Azure с проверкой подлинности SAS в учетной записи ADLS 2-го поколения, чтобы избежать использования поэтапной копии в Snowflake.
Формат данных источника — Parquet, текст с разделителями или JSON с нижеуказанными конфигурациями.
Для формата Parquet кодек сжатия — None или Snappy.
Для формата текста с разделителями:
- для
rowDelimiterможно указать \r\n или любой отдельный символ; Если разделитель строк не является "\r\n",firstRowAsHeaderнеобходимо иметь значение false иskipLineCountне указан. - параметр
compressionможет иметь значение no compression, gzip, bzip2 или deflate. - Для
encodingNameостается значение по умолчанию или устанавливается как "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". - для
quoteCharможет использоваться двойная кавычка, одинарная кавычкаили пустая строка (без кавычек).
- для
Для формата JSON прямое копирование поддерживается только в том случае, если таблица приемника Snowflake содержит только один столбец, и для данных этого столбца задан тип VARIANT, OBJECT или ARRAY.
- параметр
compressionможет иметь значение no compression, gzip, bzip2 или deflate. - В параметре
encodingNameоставляется значение по умолчанию или задается значение utf-8. - Сопоставление столбцов не указано.
- параметр
В источнике действия Copy:
additionalColumnsне указан.- Если источником является папка, для
recursiveустановлено значение true. prefix,modifiedDateTimeStart,modifiedDateTimeEndиenablePartitionDiscoveryне указаны.
Пример:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeSink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
}
}
}
}
}
]
Промежуточное копирование в Snowflake
Если исходное хранилище данных или формат не совместимы с командой Snowflake COPY, как упоминалось в последнем разделе, включите встроенную поэтапное копирование с помощью промежуточного экземпляра хранилища BLOB-объектов Azure. Функция поэтапного копирования также обеспечивает более высокую пропускную способность. Служба автоматически преобразует данные, чтобы они соответствовали требованиям к формату данных Snowflake. Затем она вызывает команду КОПИРОВАТЬ для загрузки данных в Snowflake. Наконец, она очищает ваши временные данные из хранилища BLOB-объектов. Подробные данные о копировании с использованием промежуточного процесса см. в статье Промежуточное копирование.
Чтобы использовать эту функцию, создайте связанную службу хранения BLOB-объектов Azure, которая обращается к учетной записи хранения Azure в рамках промежуточного процесса. Затем укажите свойства enableStaging и stagingSettings в действии Copy.
Примечание.
Связанная служба промежуточного хранилища BLOB-объектов Azure должна использовать проверку подлинности подписанного URL-адреса, как это требуется для команды КОПИРОВАТЬ в Snowflake.
Пример:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeSink",
"importSettings": {
"type": "SnowflakeImportCopyCommand"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Свойства потока данных для сопоставления
При преобразовании данных в потоке данных для сопоставления можно выполнять операции чтения и записи в таблицах в Snowflake. Дополнительные сведения см. в описаниях преобразования источника и преобразования приемника в разделе, посвященном потокам данных для сопоставления. В качестве типа источника и приемника можно выбрать использование набора данных Snowflake или встроенного набора данных.
Преобразование источника
В таблице, приведенной ниже, указаны свойства, поддерживаемые источником Snowflake. Эти свойства можно изменить на вкладке Параметры источника. Соединитель использует внутреннюю передачу данных Snowflake.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Таблица | Если в качестве входных данных выбрать вариант "Таблица", поток данных будет получать все данные из таблицы, указанной в наборе данных Snowflake, или в параметрах источника при использовании встроенного набора данных. | Нет | Строка | (только для встроенного набора данных) tableName schemaName |
| Query | Если в качестве входных данных выбрать "Запрос", введите запрос для получения данных из Snowflake. Этот параметр переопределяет любую таблицу, выбранную в наборе данных. Если имена схемы, таблицы и столбцов содержат строчные буквы, заключайте идентификатор объекта в кавычки, например select * from "schema"."myTable". |
Нет | Строка | query |
| Включение добавочного извлечения (предварительная версия) | Используйте этот параметр, чтобы сообщить ADF обработать только строки, которые изменились с момента последнего выполнения конвейера. | No | Логический | enableCdc |
| Добавочный столбец | При использовании функции добавочного извлечения необходимо выбрать столбец даты и времени и числового столбца, который вы хотите использовать в качестве водяного знака в исходной таблице. | Нет | Строка | waterMarkColumn |
| Включение snowflake Отслеживание изменений (предварительная версия) | Этот параметр позволяет ADF использовать технологию отслеживания измененных данных Snowflake для обработки только разностных данных с момента выполнения предыдущего конвейера. Этот параметр автоматически загружает разностные данные с операциями вставки строк, обновления и удаления без необходимости добавлять добавочный столбец. | No | Логический | enableNativeCdc |
| Чистые изменения | При использовании отслеживания изменений snowflake можно использовать этот параметр, чтобы получить дедупликированные измененные строки или исчерпывающие изменения. Дедупликированные измененные строки будут отображать только последние версии строк, которые изменились с заданной точки во времени, в то время как исчерпывающие изменения будут отображать все версии каждой строки, которая изменилась, включая те, которые были удалены или обновлены. Например, при обновлении строки вы увидите версию удаления и версию вставки в исчерпывающих изменениях, но только версию вставки в дедуппированных измененных строках. В зависимости от варианта использования можно выбрать вариант, соответствующий вашим потребностям. Параметр по умолчанию имеет значение false, что означает исчерпывающие изменения. | No | Логический | netChanges |
| Включение системных столбцов | При использовании отслеживания изменений snowflake можно использовать параметр systemColumns, чтобы контролировать, включены ли или исключены столбцы потока метаданных, предоставляемые Snowflake, в выходные данные отслеживания изменений. По умолчанию systemColumns имеет значение true, что означает, что столбцы потока метаданных включены. Если вы хотите исключить их, можно задать значение false systemColumns. | No | Логический | systemColumns |
| Начало чтения с начала | Установка этого параметра с добавочным извлечением и отслеживанием изменений приведет к тому, что ADF будет считывать все строки при первом выполнении конвейера с включенным добавочным извлечением. | No | Логический | skipInitialLoad |
Примеры сценариев для источника Snowflake
При использовании набора данных Snowflake в качестве типа источника связанный сценарий потока данных будет следующим:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Если используется встроенный набор данных, связанный сценарий потока данных будет следующим:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Собственные Отслеживание изменений
Фабрика данных Azure теперь поддерживает встроенную функцию в Snowflake, которая называется отслеживанием изменений, которая включает отслеживание изменений в виде журналов. Эта функция snowflake позволяет отслеживать изменения данных с течением времени, что делает его полезным для добавочной загрузки и аудита данных. Чтобы использовать эту функцию, при включении отслеживания измененных данных и выборе Отслеживание изменений Snowflake мы создадим объект Stream для исходной таблицы, которая позволяет отслеживать изменения в исходной таблице snowflake. Затем мы используем предложение CHANGES в нашем запросе для получения только новых или обновленных данных из исходной таблицы. Кроме того, рекомендуется запланировать конвейер, чтобы изменения потреблялись в течение интервала времени хранения данных, заданного для исходной таблицы snowflake, другие пользователи могут видеть несогласованное поведение в захваченных изменениях.
Преобразование приемника
В таблице, приведенной ниже, указаны свойства, поддерживаемые приемником Snowflake. Эти свойства можно изменить на вкладке "Параметры ". При использовании встроенного набора данных вы увидите дополнительные параметры, которые совпадают с свойствами, описанными в разделе свойств набора данных. Соединитель использует внутреннюю передачу данных Snowflake.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Метод обновления | Определение операций, разрешенных в назначении Snowflake. Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) строк требуется преобразование alter-row, чтобы отметить строки для этих действий. |
Да | true или false |
deletable Вставляемый доступный для обновления подлежит обновлению или вставке |
| Ключевые столбцы | Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) должен быть установлен ключевой столбец (или столбцы), позволяющий определить строки для изменения. | No | Массив | клиентом |
| Действие таблицы | Определяет, следует ли повторно создавать или удалять все строки в целевой таблице перед записью. - Нет: действия с таблицей не будут выполняться. - Создать повторно: таблица будет удалена и создана повторно. Это действие необходимо, если новая таблица создается динамически. - Усечь: все строки из целевой таблицы будут удалены. |
No | true или false |
создать повторно truncate |
Примеры сценариев для приемника Snowflake
При использовании набора данных Snowflake в качестве типа приемника связанный сценарий потока данных будет следующим:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Если используется встроенный набор данных, связанный сценарий потока данных будет следующим:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Оптимизация pushdown запроса
При задании уровня ведения журнала конвейера значение None мы исключим передачу промежуточных метрик преобразования, предотвращая потенциальные помехи оптимизации Spark и обеспечивая оптимизацию pushdown запросов, предоставляемую Snowflake. Эта оптимизация pushdown позволяет значительно повысить производительность больших таблиц Snowflake с обширными наборами данных.
Примечание.
Мы не поддерживаем временные таблицы в Snowflake, так как они являются локальными для сеанса или пользователя, который создает их, что делает их недоступными для других сеансов и подвержены перезаписи как обычные таблицы Snowflake. Хотя Snowflake предлагает временные таблицы в качестве альтернативы, которые доступны глобально, они требуют ручного удаления, что противоречит нашей основной цели использования временных таблиц, что позволяет избежать любых операций удаления в исходной схеме.
Свойства действия поиска
Дополнительные сведения о свойствах см. в статье об действии поиска.
Связанный контент
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.