Копирование данных в хранилище Azure Databricks Delta Lake и из него с помощью Фабрики данных Azure или Azure Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия Copy в Фабрике данных Azure и Azure Synapse копировать данные в службу Azure Databricks Delta Lake и из нее. Это продолжение статьи Действие Copy, в которой представлены общие сведения о действии копирования.
Поддерживаемые возможности
Этот соединитель Azure Databricks Delta Lake поддерживается для следующих возможностей.
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/приемник) | (1) (2) |
| Поток данных для сопоставления (источник/приемник) | (1) |
| Действие поиска | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
В целом служба поддерживает работу с Delta Lake, предоставляя следующие функции для реализации различных задач.
- Действие Copy поддерживает соединитель Azure Databricks Delta при выполнении копирования данных из любого поддерживаемого хранилища данных-источника в таблицу Azure Databricks Delta Lake и из таблицы Delta Lake в любое поддерживаемое хранилище данных-приемник. Оно задействует для выполнения перемещения данных кластер Databricks — подробнее см. в разделе "Предварительные требования".
- Поток данных для сопоставления поддерживает общий разностный формат в службе хранилища Microsoft Azure в качестве источника и приемника для чтения и записи разностных файлов, позволяя производить извлечение, преобразование и загрузку (ETL) без написания кода, и выполняется в управляемой среде Azure Integration Runtime.
- Действия в Databricks поддерживают оркестрацию рабочих нагрузок извлечения, преобразования и нагрузки (ETL) или машинного обучения, ориентированных на написание кода, и выполняющихся поверх Delta Lake.
Необходимые компоненты
Для использования этого соединителя Azure Databricks Delta Lake необходимо настроить кластер в Azure Databricks.
- Чтобы скопировать данные в Delta Lake, действие Copy вызывает кластер Azure Databricks для считывания данных из службы хранилища Microsoft Azure, которая представляет либо первоначальный источник данных, либо область промежуточного хранения, в которую служба сначала записывает исходные данные с помощью встроенной операции промежуточного копирования. Подробнее об использовании Delta Lake в качестве приемника.
- Аналогично, чтобы скопировать данные из Delta Lake, действие Copy вызывает кластер Azure Databricks для записи данных в службу хранилища Microsoft Azure, которая представляет либо первоначальный приемник, либо область промежуточного хранения, из которой служба продолжит записывать данные в конечный приемник с помощью встроенной операции промежуточного копирования. Подробнее об использовании Delta Lake в качестве источника.
У кластера Databricks должен быть доступ к хранилищу BLOB-объектов Azure или учетной записи Azure Data Lake Storage 2-го поколения, к обоим контейнерам хранилищ/обеим файловым системам, используемым в качестве источника/приемника/места промежуточного хранения, а также к контейнеру/файловой системе, в которые следует записать таблицы Delta Lake.
Чтобы использовать Azure Data Lake Storage 2-го поколения, можно настроить субъект-службу в кластере Databricks в составе конфигурации Apache Spark. Выполните действия, описанные в разделе Непосредственный доступ с помощью субъекта-службы.
Чтобы использовать хранилище BLOB-объектов Azure, можно настроить ключ доступа к учетной записи хранения или маркер SAS в кластере Databricks в составе конфигурации Apache Spark. Выполните действия, описанные в статье Доступ к хранилищу BLOB-объектов Azure с помощью API RDD.
Если при выполнении действия копирования оказывается, что работа настроенного в нем кластера завершена, служба автоматически его запускает. Если вы создаете конвейер с помощью пользовательского интерфейса разработки, для таких операций, как предварительный просмотр данных, вам понадобится уже работающий кластер. Служба не запускает кластер от вашего имени.
Указание конфигурации кластера
В раскрывающемся списке Режим кластера выберите Стандартный.
В раскрывающемся списке Версия Azure Databricks Runtime выберите версию среды выполнения Databricks.
Включите Автоматическую оптимизацию, добавив следующие свойства в конфигурацию Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueНастройте кластер в соответствии с вашими потребностями в интеграции и масштабировании.
Подробные сведения о настройке кластера см. в статье Настройка кластеров.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
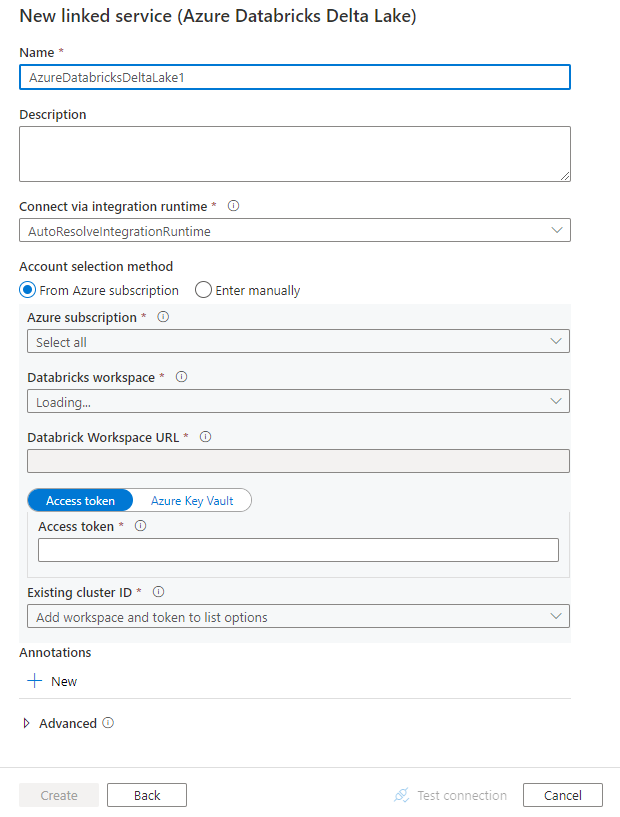
Создание службы, связанной с Azure Databricks Delta Lake, с помощью пользовательского интерфейса
Выполните приведенные ниже действия, чтобы создать службу, связанную с Azure Databricks Delta Lake, с помощью пользовательского интерфейса на портале Azure.
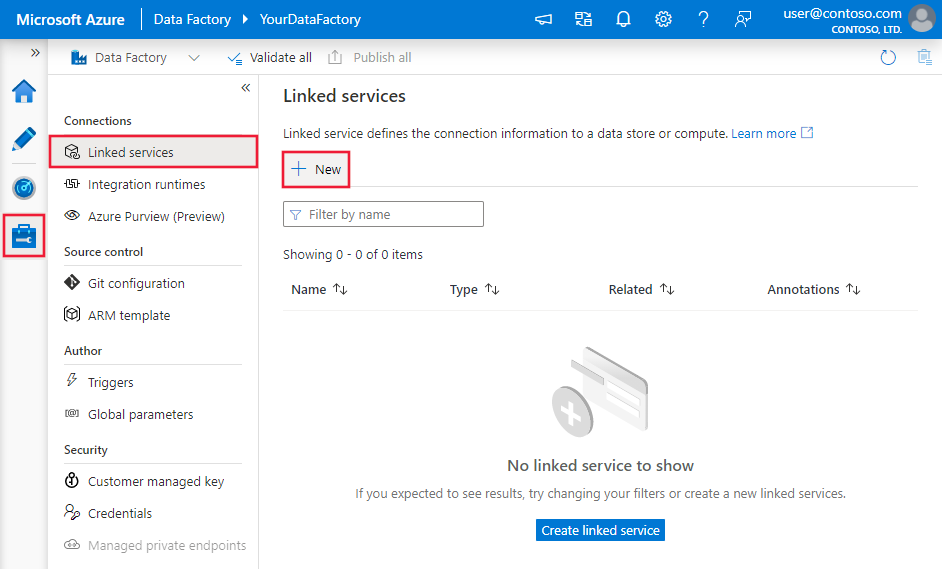
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск по слову delta и выберите соединитель Azure Databricks Delta Lake.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые определяют сущности, относящиеся к соединителю Azure Databricks Delta Lake.
Свойства связанной службы
Соединитель Azure Databricks Delta Lake поддерживает приведенные ниже типы проверки подлинности. Дополнительные сведения см. в соответствующих разделах.
- Маркер доступа
- Проверка подлинности с помощью назначенного системой управляемого удостоверения
- Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Маркер доступа
Для связанной службы Azure Databricks Delta Lake поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type следует задать значение AzureDatabricksDeltaLake. | Да |
| domain | Укажите URL-адрес рабочей области Azure Databricks, например https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Укажите идентификатор кластера для существующего кластера. Это должен быть уже созданный интерактивный кластер. Идентификатор интерактивного кластера можно найти, выбрав "Рабочая область Databricks" -> "Кластеры" -> "Имя интерактивного кластера" -> "Конфигурация" -> "Теги". Подробнее. |
|
| accessToken | Чтобы служба прошла аутентификацию в Azure Databricks, необходим маркер доступа. Маркер доступа должен быть создан в рабочей области Databricks. Подробные инструкции по поиску маркера доступа см. в этой статье. | |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется среда выполнения интеграции Azure. | No |
Пример:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Проверка подлинности с помощью назначенного системой управляемого удостоверения
Дополнительные сведения об управляемых удостоверениях, назначаемых системой для ресурсов Azure, см. в этой статье.
Для использования проверки подлинности с помощью управляемого удостоверения, назначаемого системой, выполните приведенные ниже действия по предоставлению разрешений.
Получите сведения об управляемом удостоверении, скопировав значение идентификатора объекта управляемого удостоверения, созданного вместе с фабрикой или рабочим пространством Synapse.
Предоставьте управляемому удостоверению правильные разрешения в Azure Databricks. В большинстве случаев нужно предоставить управляемому удостоверению, назначаемому системой, по меньшей мере роль участника в системе управления доступом (IAM) Azure Databricks.
Для связанной службы Azure Databricks Delta Lake поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type следует задать значение AzureDatabricksDeltaLake. | Да |
| domain | Укажите URL-адрес рабочей области Azure Databricks, например https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Да |
| clusterId | Укажите идентификатор кластера для существующего кластера. Это должен быть уже созданный интерактивный кластер. Идентификатор интерактивного кластера можно найти, выбрав "Рабочая область Databricks" -> "Кластеры" -> "Имя интерактивного кластера" -> "Конфигурация" -> "Теги". Подробнее. |
Да |
| workspaceResourceId | Укажите идентификатор ресурса рабочей области Azure Databricks. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется среда выполнения интеграции Azure. | No |
Пример:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Дополнительные сведения об управляемых удостоверениях, назначаемых пользователем, см. в этой статье.
Для использования проверки подлинности с помощью управляемого удостоверения, назначаемого пользователем, выполните приведенные ниже действия.
Создайте одно или несколько удостоверенный, назначаемых пользователем, и предоставьте разрешение в Azure Databricks. В большинстве случаев нужно предоставить управляемому удостоверению, назначаемому пользователем, по меньшей мере роль участника в системе управления доступом (IAM) Azure Databricks.
Присвойте Фабрике данных или рабочему пространству Synapse одно или несколько управляемых удостоверений, назначаемых пользователем, и создайте учетные данные для каждого подобного удостоверения.
Для связанной службы Azure Databricks Delta Lake поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type следует задать значение AzureDatabricksDeltaLake. | Да |
| domain | Укажите URL-адрес рабочей области Azure Databricks, например https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Да |
| clusterId | Укажите идентификатор кластера для существующего кластера. Это должен быть уже созданный интерактивный кластер. Идентификатор интерактивного кластера можно найти, выбрав "Рабочая область Databricks" -> "Кластеры" -> "Имя интерактивного кластера" -> "Конфигурация" -> "Теги". Подробнее. |
Да |
| учетные данные | Укажите назначаемое пользователем управляемое удостоверение в качестве объекта учетных данных. | Да |
| workspaceResourceId | Укажите идентификатор ресурса рабочей области Azure Databricks. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется среда выполнения интеграции Azure. | No |
Пример:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных.
Для набора данных Azure Databricks Delta Lake поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение AzureDatabricksDeltaLakeDataset. | Да |
| database | Имя базы данных . | "Нет" для источника, "Да" для приемника |
| table | Имя таблицы разности. | "Нет" для источника, "Да" для приемника |
Пример:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником и приемником Azure Databricks Delta Lake.
Delta Lake служит источником
Для копирования данных из Azure Databricks Delta Lake в разделе source для действия Copy поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия Copy должно иметь значение AzureDatabricksDeltaLakeSource. | Да |
| query | Укажите запрос SQL для чтения данных. Для элемента управления переходом по времени используйте следующий шаблон: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
No |
| exportSettings | Дополнительные параметры, используемые для получения данных из разностной таблицы. | No |
В разделе exportSettings: |
||
| type | Тип команды экспорта — установите его в значение AzureDatabricksDeltaLakeExportCommand. | Да |
| dateFormat | Тип даты приводится к типу строки с использованием этого формата даты. В пользовательских форматах даты применяются форматы следующих шаблонов даты и времени. Если он не указан, используется значение по умолчанию, yyyy-MM-dd. |
No |
| timestampFormat | Тип метки времени приводится к типу строки с использованием этого формата метки времени. В пользовательских форматах даты применяются форматы следующих шаблонов даты и времени. Если он не указан, используется значение по умолчанию, yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Прямое копирование из Delta Lake
Если хранилище данных и формат приемника соответствуют критериям, описанным в этом разделе, действие Copy можно использовать для прямого копирования из разностной таблицы Azure Databricks Delta в приемник. Служба проверяет параметры и не выполняет действие Copy, если не выполнены условия, описанные ниже.
Связанная служба-приемник — это хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения. Данные для входа учетной записи должны быть предварительно настроены в конфигурации кластера Azure Databricks. Дополнительные сведения см. в разделе Предварительные требования.
Формат данных приемника — Parquet, текст с символами-разделителями или Avro со следующими конфигурациями, причем он должен указывать на папку, а не на файл.
- Для формата Parquet должен быть выбран кодек сжатия none (нет), snappy или gzip.
- Для формата текста с разделителями:
-
rowDelimiter— любой одиночный символ. -
compressionможет иметь значение none (нет), bzip2 или gzip. -
encodingNameUTF-7 не поддерживается.
-
- Для формата Avro должен быть выбран кодек сжатия none (нет), deflate или snappy.
В источнике действия Copy не указано значение
additionalColumns.При копировании данных в текст с разделителями в приемнике действия копирования необходимо задать
fileExtension".csv".В сопоставлении действия Copy должно быть отключено преобразование типов.
Пример:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Промежуточное копирование из Delta Lake
Если хранилище данных или формат приемника не соответствуют критериям для прямого копирования, описанным в предыдущем разделе, включите встроенную функцию промежуточного копирования с задействованием промежуточного экземпляра хранилища Azure. Промежуточное копирование также обеспечивает лучшую пропускную способность. Служба экспортирует данные из Azure Databricks Delta Lake в промежуточное хранилище, затем копирует данные в приемник и, наконец, очищает промежуточное хранилище от временных данных. Подробные данные о копировании с использованием промежуточного процесса см. в разделе Промежуточное копирование.
Чтобы использовать эту функцию, создайте связанную службу хранения BLOB-объектов Azure или связанную службу Azure Data Lake Storage 2-го поколения, которая задействует учетную запись хранения в рамках промежуточного процесса. Затем укажите свойства enableStaging и stagingSettings в действии Copy.
Примечание.
Данные для входа учетной записи промежуточного хранения должны быть предварительно настроены в конфигурации кластера Azure Databricks. Дополнительные сведения см. в разделе Предварительные требования.
Пример:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake служит приемником
Для копирования данных в Azure Databricks Delta Lake в разделе sink для действия Copy поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type приемника действия Copy должно иметь значение AzureDatabricksDeltaLakeSink. | Да |
| preCopyScript | Укажите SQL-запрос, который будет выполняться в действии Copy перед записью данных в разностную таблицу Databricks при каждом запуске. Пример: VACUUM eventsTable DRY RUN. Это свойство можно использовать для очистки предварительно загруженных данных или для добавления инструкции усечения таблицы либо инструкции VACUUM. |
No |
| importSettings | Расширенные параметры, используемые при записи данных в разностную таблицу. | No |
В разделе importSettings: |
||
| type | Тип команды импорта — установите его в значение AzureDatabricksDeltaLakeImportCommand. | Да |
| dateFormat | Строковый тип приводится к типу даты с использованием этого формата даты. В пользовательских форматах даты применяются форматы следующих шаблонов даты и времени. Если он не указан, используется значение по умолчанию, yyyy-MM-dd. |
No |
| timestampFormat | Строковый тип приводится к типу метки времени с использованием этого формата метки времени. В пользовательских форматах даты применяются форматы следующих шаблонов даты и времени. Если он не указан, используется значение по умолчанию, yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Прямое копирование в Delta Lake
Если хранилище данных и формат источника соответствуют критериям, описанным в этом разделе, действие Copy можно использовать для прямого копирования из источника в Azure Databricks Delta Lake. Служба проверяет параметры и не выполняет действие Copy, если не выполнены условия, описанные ниже.
Связанная служба-источник — это хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения. Данные для входа учетной записи должны быть предварительно настроены в конфигурации кластера Azure Databricks. Дополнительные сведения см. в разделе Предварительные требования.
Формат данных источника — Parquet, текст с символами-разделителями или Avro со следующими конфигурациями, причем он должен указывать на папку, а не на файл.
- Для формата Parquet должен быть выбран кодек сжатия none (нет), snappy или gzip.
- Для формата текста с разделителями:
-
rowDelimiterустанавливается по умолчанию, или это может быть любой одиночный символ. -
compressionможет иметь значение none (нет), bzip2 или gzip. -
encodingNameUTF-7 не поддерживается.
-
- Для формата Avro должен быть выбран кодек сжатия none (нет), deflate или snappy.
В источнике действия Copy:
-
wildcardFileNameсодержит только подстановочный знак*, но не?, иwildcardFolderNameне указано. - Параметры
prefix,modifiedDateTimeStart,modifiedDateTimeEndиenablePartitionDiscoveryне указываются. -
additionalColumnsне указан.
-
В сопоставлении действия Copy должно быть отключено преобразование типов.
Пример:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Промежуточное копирование в Delta Lake
Если хранилище данных или формат источника не соответствуют критериям для прямого копирования, описанным в предыдущем разделе, включите встроенную функцию промежуточного копирования с задействованием промежуточного экземпляра хранилища Azure. Промежуточное копирование также обеспечивает лучшую пропускную способность. Служба автоматически преобразует данные, чтобы они соответствовали требованиям к формату данных, помещаемых в промежуточное хранилище, а затем загружает из него данные в Delta Lake. Наконец, производится очистка временных данных из хранилища. Подробные данные о копировании с использованием промежуточного процесса см. в статье Промежуточное копирование.
Чтобы использовать эту функцию, создайте связанную службу хранения BLOB-объектов Azure или связанную службу Azure Data Lake Storage 2-го поколения, которая задействует учетную запись хранения в рамках промежуточного процесса. Затем укажите свойства enableStaging и stagingSettings в действии Copy.
Примечание.
Данные для входа учетной записи промежуточного хранения должны быть предварительно настроены в конфигурации кластера Azure Databricks. Дополнительные сведения см. в разделе Предварительные требования.
Пример:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Наблюдение
Предоставляемые возможности мониторинга действий копирования аналогичны таким же возможностям для других соединителей. Кроме того, поскольку загрузка данных в Delta Lake или из него выполняется в вашем кластере Azure Databricks, вы можете дополнительно просматривать подробные журналы кластера и вести мониторинг производительности.
Свойства действия поиска
Дополнительные сведения о свойствах см. в статье об действии поиска.
Действие поиска может возвращать до 1000 строк. Если результирующий набор содержит больше записей, будут возвращены первые 1000 строк.
Связанный контент
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.