Использование социальных сетей с помощью Azure Cosmos DB
Область применения: ![]() Nosql
Nosql ![]() Mongodb
Mongodb ![]() Кассандра
Кассандра ![]() Гремлин
Гремлин ![]() Таблица
Таблица
Жизнь в сильно взаимосвязанном обществе означает, что в определенный момент вы присоединяетесь к социальной сети. Вы используете социальные сети, чтобы поддерживать связь с друзьями, коллегами и родными, а иногда — чтобы делиться увлечением с теми, кто разделяет ваши интересы.
Как инженер или разработчик, вы могли интересоваться, как эти сети хранят и соединяют ваши данные между собой. Вам также могли поручить создание или проектирование новой социальной сети для специализированного рынка. Именно тогда возникает важный вопрос: как хранятся все эти данные?
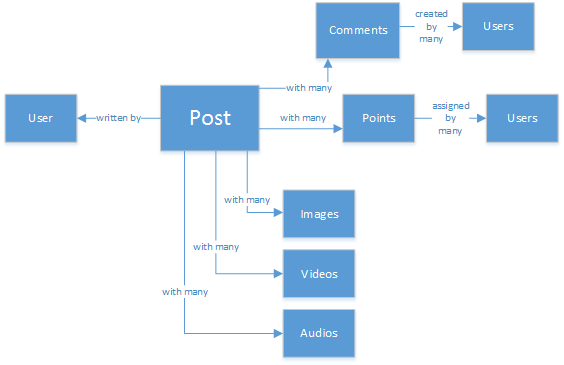
Предположим, что вы создаете новую яркую социальную сеть, где ваши пользователи могут публиковать статьи с сопутствующими материалами, например изображениями, видео или даже музыкой. Пользователи могут комментировать записи и оценивать их с помощью очков. В сети будет веб-канал записей, которые будут видны пользователям. Кроме того, пользователи смогут взаимодействовать с целевой страницей основного веб-сайта. Поначалу этот способ может показаться несложным, предлагаем на этом остановиться, чтобы не усложнять его. (Вы можете подробнее изучить настраиваемые каналы пользователей, но это не относится к теме данной статьи.)
Итак, как и где хранить все эти данные?
Возможно, у вас есть опыт работы с базами данных SQL или представление о реляционном моделировании данных. Вы можете начать рисовать нечто подобное:
Идеально нормализованная и аккуратная структура данных, которая не масштабируется.
Поймите меня правильно, я всю жизнь работаю с базами данных SQL. Они полезны, но как и все остальные шаблоны, практики и программные платформы, они подходят не для каждого сценария.
Почему SQL — не наилучший вариант для этого сценария? Рассмотрим структуру одной записи. Если мне нужно показать запись на веб-сайте или в приложении, потребуется отправить запрос, объединив восемь таблиц (!) только для того, чтобы показать одну запись. Теперь представьте поток записей, которые динамически загружаются и отображаются на экране, и вы поймете, о чем я.
Вы могли бы использовать огромный экземпляр SQL с вычислительной мощностью, достаточной для обработки тысяч запросов с большим количеством соединений, чтобы обслуживать ваше содержимое. Но зачем это делать, если есть более простое решение?
Путь NoSQL
В этой статье представлены инструкции по экономичному моделированию данных социальной платформы с помощью базы данных NoSQL Azure Cosmos DB. В нем также рассказывается, как использовать другие функции Azure Cosmos DB, такие как API для Gremlin. Используя NoSQL, храня данные в формате JSON и применяя денормализацию, запись, которая ранее представлялась сложной, можно преобразовать в один документ.
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
И его можно получить с помощью одного запроса без каких-либо операций соединения. Эти запросы выполняются намного проще, эффективнее и экономнее, и для достижения наилучшего результата требуется меньше ресурсов.
Azure Cosmos DB обеспечивает индексирование всех свойств с помощью автоматического индексирования. Автоматическое индексирование даже можно настраивать. Подход без схемы позволяет хранить документы с различными динамическими структурами. Возможно, завтра вам потребуется, чтобы с записями были связаны списки категорий или хэштегов? Azure Cosmos DB будет обрабатывать новые документы с добавленными атрибутами без дополнительной работы, необходимой для нас.
Комментарии к записи можно считать такими же записями, но со свойством родительской записи. (Такой подход упрощает сопоставление объектов.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
И все взаимодействия в социальной сети могут храниться в отдельном объекте как счетчики.
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Создание веб-каналов — это просто создание документов, которые могут содержать список идентификаторов записей в указанном ниже порядке релевантности.
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Можно создать поток новейших записей, отсортированных по дате создания, или поток самых популярных записей, которые понравились наибольшему количеству пользователей за последние 24 часа. Вы даже можете реализовать специальный поток для каждого пользователя по таким критериям, как подписчики и интересы. Это по-прежнему будет список записей. Важно то, как создаются эти списки, а производительность чтения остается неизменной. После получения одного из этих списков вы получите один запрос в Azure Cosmos DB с помощью ключевого слова IN, чтобы получить страницы записей за раз.
Потоки веб-канала можно создать с использованием фоновых процессов служб приложений Azure — веб-заданий. После создания записи фоновая обработка может быть активирована с помощью служба хранилища Azure очередей и веб-заданий, активированных с помощью пакета SDK веб-заданий Azure, реализуя распространение после распространения внутри потоков на основе собственной пользовательской логики.
Очки и отметки "Нравится" записи могут обрабатываться с отсрочкой, этот же подход применяется для создания согласованной среды.
С читателями все сложнее. Azure Cosmos DB имеет ограничение размера документа, а чтение и запись больших документов может повлиять на масштабируемость приложения. Поэтому можно рассмотреть хранение читателей в документе со следующей структурой.
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Эта структура может подойти пользователю с несколькими тысячами подписчиков. Однако если к вам присоединится какая-либо знаменитость, то при данном подходе размер документа увеличится, а вы все равно натолкнетесь на ограничение размера.
Чтобы решить эту проблему, можно применить смешанный подход. В документе статистики пользователей вы можете хранить количество читателей.
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Вы можете сохранить фактический граф подписчиков с помощью API Azure Cosmos DB для Gremlin , чтобы создать вершины для каждого пользователя и ребра , которые поддерживают отношения "A-follows-B". С помощью API для Gremlin вы можете получить последователей определенного пользователя и создать более сложные запросы, чтобы предложить людей в общем. Если добавить в граф категории содержимого, которые нравятся пользователям, вы сможете добавить возможности связывания, включая интеллектуальное обнаружение содержимого, предложение содержимого, интересующего пользователей, на которых вы подписаны, или поиск людей, с которыми у вас могут быть общие интересы.
С помощью документа "Статистика пользователей" также можно создавать карточки в пользовательском интерфейсе или просматривать краткие профили.
Дублирование данных и шаблон "Лестница"
Как вы могли заметить, в документе JSON, на который ссылается запись, имеется множество вхождений данных пользователя. Как вы уже догадались, это означает, что данные, описывающие пользователя (с учетом денормализации), могут находиться в нескольких местах.
Чтобы ускорить обработку запросов, вы применяете дублирование данных. Побочный эффект состоит в том, что если какое-либо действие меняет данные пользователя, вам нужно найти все действия, которые он когда-либо выполнил, и обновить их. Звучит не слишком практично, верно?
Вы решите эту проблему, определив ключевые атрибуты пользователя, которые отображаются в вашем приложении для каждого действия. Если вы показываете запись в приложении только с именем и изображением автора, зачем хранить в атрибуте createdBy все данные пользователя? Если для каждого комментария вы показываете только изображение пользователя, остальные его данные не нужны. Вот когда нам пригодится так называемый шаблон "Лестница".
Для примера рассмотрим информацию о пользователе.
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Посмотрев на эту информацию, вы можете быстро определить, какая информация важна, а какая — нет, тем самым строя "Лестницу".

Наименьший объект называется блоком пользователя, это минимальный объем информации, идентифицирующий пользователя и используемый для дублирования данных. Уменьшая размер дублируемых данных только до "видимой" информации, вы снизите вероятность масштабных обновлений.
Средний объект называется пользователем. Это полные данные, которые будут использоваться для большинства запросов, зависящих от производительности, в Azure Cosmos DB, наиболее доступных и критически важных. Пользователь содержит информацию, представленную в блоке пользователя.
Самый большой объект — расширенный пользователь. Он включает критически важные сведения о пользователях и другие данные, которые не требуется быстро считывать или которые применяются время от времени, например для входа. Эти данные можно хранить за пределами Azure Cosmos DB в База данных SQL Azure или служба хранилища Azure таблицах.
Зачем разделять данные пользователя и хранить эту информацию в разных местах? Это необходимо, поскольку с точки зрения производительности, чем больше документы, тем дороже обходятся запросы. Оставляйте документы небольшими, сохраняя только необходимую информацию для всех зависящих от производительности запросов в вашей социальной сети. Сохраняйте дополнительные сведения для редко используемых сценариев, например полного редактирования профиля, входа и интеллектуального анализа данных для аналитики использования и инициатив с большими данными. Для вас не имеет значения, что данные для интеллектуального анализа собираются медленнее, так как это происходит в Базе данных SQL Azure. Однако для вас важны скорость и удобство работы пользователей. Пользователь, хранящийся в Azure Cosmos DB, будет выглядеть следующим образом:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
И запрос POST будет выглядеть следующим образом.
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
При редактировании, влияющем на атрибут блока, вы можете легко найти соответствующие документы. Просто используйте запросы, указывающие на индексированные атрибуты, например SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", а затем обновите блоки.
Поле поиска
К счастью, пользователи будут формировать много содержимого. И вы должны дать возможность искать и находить содержимое, которое может отсутствовать непосредственно в их потоках содержимого, возможно потому, что они не подписались на их авторов или просто пытаются найти старую запись, созданную шесть месяцев назад.
Так как вы используете Azure Cosmos DB, вы можете легко реализовать поисковую систему с помощью службы "Поиск ИИ Azure" за несколько минут без ввода кода, отличного от процесса поиска и пользовательского интерфейса.
Почему этот процесс так прост?
Поиск ИИ Azure реализует то, что они называют индексаторами, фоновыми процессами, которые перехватываются в репозиториях данных и автоматически добавляют, обновляют или удаляют объекты в индексах. Они поддерживают индексаторы базы данных SQL Azure, индексаторы больших двоичных объектов Azure и, к счастью, индексаторы Azure Cosmos DB. Переход информации из Azure Cosmos DB в поиск по искусственному интеллекту Azure прост. Обе технологии хранят данные в формате JSON, поэтому вам достаточно создать индекс и сопоставить индексируемые атрибуты документов. Вот и все! В зависимости от размера данных, все содержимое станет доступно для поиска в течение нескольких минут благодаря лучшему решению "поиск как служба" в облачной инфраструктуре.
Дополнительные сведения о поиске ИИ Azure см. в руководстве по поиску hitchhiker.
Базовый набор знаний
Храня все это содержимое, которое ежедневно увеличивается, вы можете задуматься: что делать с потоком информации, поступающей от моих пользователей?
Ответ прост: включить его в работу и учиться.
Но как вы можете учиться? Из простых примеров можно привести анализ тональности, т. е. рекомендации содержимого на основе предпочтений пользователя, или даже автоматический модератор содержимого, который гарантирует, что все содержимое, публикуемое в вашей социальной сети, безопасно для семьи.
Теперь, когда я заинтересовал вас, скорее всего вы думаете, что нужна кандидатская степень по математике, чтобы извлечь эти шаблоны и информацию из простых баз данных и файлов, но это не так.
Машинное обучение Azure — это полностью управляемая облачная служба, которая позволяет создавать рабочие процессы с помощью алгоритмов в простом интерфейсе перетаскивания, кодировать собственные алгоритмы в R или использовать некоторые уже созданные и готовые к использованию API, такие как Анализ текста, Content Moderator или рекомендации.
Чтобы реализовать любой из этих сценариев машинного обучения, вы можете использовать Azure Data Lake для приема информации из различных источников. Вы также можете использовать U-SQL для обработки информации и создания выходных данных, которые может обрабатывать Машинное обучение Azure.
Еще одним доступным вариантом является использование служб ИИ Azure для анализа содержимого пользователей. Вы не только можете лучше понять их (проанализировав то, что они пишут с помощью API Анализ текста), но также можно обнаружить нежелательное или зрелое содержимое и действовать соответствующим образом с помощью API Компьютерное зрение. Службы ИИ Azure включают множество встроенных решений, которые не требуют каких-либо Машинное обучение знаний для использования.
Глобально масштабируемое социальное взаимодействие
Последняя, но совсем не маловажная тема, которую необходимо рассмотреть, — масштабируемость. При проектировании архитектуры каждый компонент должен масштабироваться отдельно. Со временем вам понадобится обрабатывать больше данных или потребуется более широкий географический охват. К счастью, достижение обоих задач — это готовый опыт работы с Azure Cosmos DB.
Azure Cosmos DB поддерживает динамическое секционирование вне поля. Она автоматически создает секции в соответствии с определенным ключом секции, заданным в качестве атрибута документов. Определять правильный ключ секции необходимо во время разработки. Дополнительные сведения см. в статье Общие сведения о секционировании в Azure Cosmos DB.
Для социального взаимодействия необходимо согласовать стратегию секционирования со способом отправки запросов и записи. (Например, предпочтительно чтение в пределах одной секции избегание "горячих точек" с распределением записи по нескольким разделам.) Некоторые варианты: секции на основе временного ключа (день/месяц/неделя), по категориям содержимого, по географическим регионам или по пользователям. На самом деле все зависит от того, как вы будете запрашивать данные и отображать их при социальном взаимодействии.
Azure Cosmos DB будет выполнять запросы (включая агрегаты) во всех разделах прозрачно, поэтому вам не нужно добавлять логику по мере роста данных.
Со временем у вас увеличатся трафик и потребление ресурсов (измеряемое в единицах запроса, ЕЗ). По мере роста пользовательской базы чтение и запись будут выполняться все чаще. Пользовательская база начнет создавать и считывать больше содержимого. Поэтому возможность масштабирования пропускной способности крайне важна. Увеличить количество единиц запросов легко. Это можно сделать, нажав несколько кнопок на портале Azure или выполнив команды через интерфейс API.
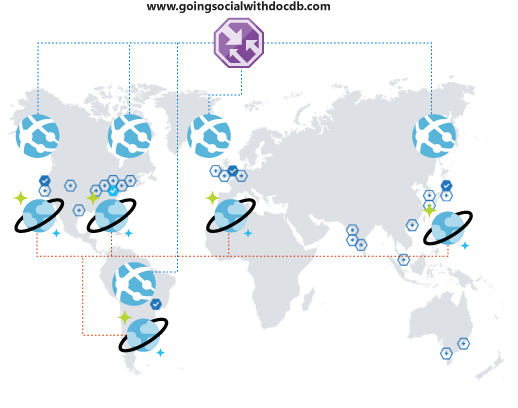
Что произойдет, если ваше решение продолжит набирать популярность? Предположим, что пользователи из другой страны или региона или континента заметят свою платформу и начинают использовать ее. Какой приятный сюрприз!
Но подождите! Скоро вы поймете, что им неудобно работать с вашей платформой. Они находятся так далеко от вашего рабочего региона, что возникает огромная задержка. Естественно, вы не хотите, чтобы они покидали вашу платформу. Было бы очень удобно иметь возможность охватить весь мир. И такая возможность есть!
Azure Cosmos DB позволяет глобально и прозрачно реплицировать данные с помощью нескольких щелчков и автоматически выбирать между доступными регионами из клиентского кода. Это также означает, что у вас может быть несколько регионов отработки отказа.
При глобальной репликации данных необходимо убедиться, что ваши клиенты могут этим воспользоваться. Если вы используете веб-интерфейс или получаете доступ к API с мобильных клиентов, то вы можете развернуть диспетчер трафика Azure и клонировать свою службу приложений Azure во всех необходимых регионах, используя конфигурацию производительности для поддержки расширенного глобального покрытия. Когда клиенты обращаются к интерфейсу или API, они будут перенаправлены в ближайшие Служба приложений, которые, в свою очередь, будут подключаться к локальной реплике Azure Cosmos DB.
Заключение
В этой статье описываются некоторые альтернативы созданию социальных сетей исключительно в Azure с использованием недорогих служб. Она приносит результаты, способствуя использованию многоуровневого решения для хранения и распространения данных под названием "Лестница".
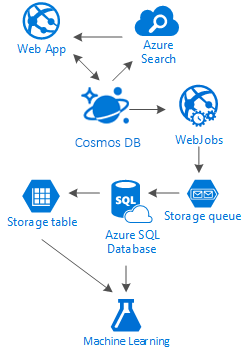
Дело в том, что универсального решения для таких сценариев не существует. Это взаимодействие, созданное сочетанием отличных служб, которые позволяют нам создавать отличные возможности: скорость и свобода Azure Cosmos DB для предоставления отличного социального приложения, аналитики за решением для поиска первого класса, таким как поиск ИИ Azure, гибкость приложение Azure Services для размещения не даже языковых приложений, но мощных фоновых процессов и расширяемых процессов. служба хранилища Azure и База данных SQL Azure для хранения огромных объемов данных и аналитических возможностей Машинное обучение Azure для создания знаний и аналитики, которые могут предоставлять отзывы вашим процессам и помочь нам предоставить правильное содержимое правильным пользователям.
Следующие шаги
Дополнительные сведения об вариантах использования Azure Cosmos DB см. в статье "Распространенные варианты использования Azure Cosmos DB".