Производительность и устранение неполадок при извлечении данных SAP
Эта статья является частью серии статей "Расширение и внедрение инновационных данных SAP: рекомендации".
- Определение источников данных SAP
- Выбор лучшего соединителя SAP
- Производительность и устранение неполадок при извлечении данных SAP
- Безопасность интеграции данных для SAP в Azure
- Универсальная архитектура интеграции данных SAP
Существует множество способов подключения к системе SAP для интеграции данных. В следующих разделах описываются общие и конкретные рекомендации и рекомендации по соединителям.
Производительность
Важно настроить оптимальные параметры для источника и целевого объекта, чтобы обеспечить максимальную производительность при извлечении и обработке данных.
Общие рекомендации
- Убедитесь, что заданы правильные параметры SAP для максимального количества одновременных подключений.
- Рассмотрите возможность использования типа входа в группу SAP для повышения производительности и распределения нагрузки.
- Убедитесь, что виртуальная машина локальной среды выполнения интеграции (SHIR) имеет достаточный размер и высокую доступность.
- При работе с большими наборами данных проверка, предоставляет ли соединитель возможность секционирования. Многие соединители SAP поддерживают возможности секционирования и параллелизации для ускорения загрузки данных. При использовании этого метода данные упакованы в небольшие блоки, которые можно загрузить с помощью нескольких параллельных процессов. Дополнительные сведения см. в документации по соединителю.
Общие рекомендации
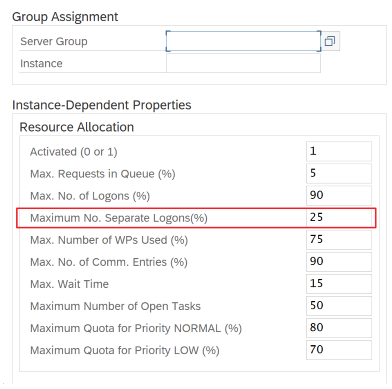
Используйте транзакцию SAP RZ12 для изменения значений максимального количества одновременных подключений.
Параметры SAP для RFC — RZ12. Следующий параметр может ограничить количество вызовов RFC, разрешенных для одного пользователя или одного приложения, поэтому убедитесь, что это ограничение не вызывает узких мест.
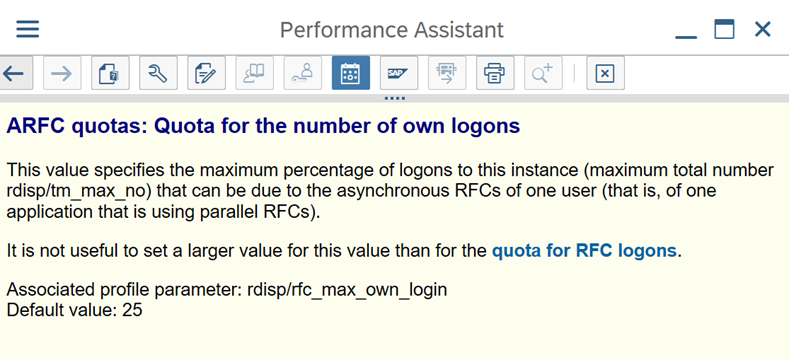
Подключение к SAP с помощью группы входа. SHIR (локальная среда выполнения интеграции) должна подключаться к SAP с помощью группы входа SAP (через сервер сообщений), а не к конкретному серверу приложений, чтобы обеспечить распределение рабочей нагрузки между всеми доступными серверами приложений.
Примечание
Кластер Spark потока данных и SHIR являются мощными. Многие внутренние действия копирования SAP, например 16, можно активировать и выполнить. Но если число одновременных подключений сервера SAP невелико, например 8, производительность считывает данные со стороны SAP.
Начните с 4 ЦП и виртуальных машин размером 16 ГБ для SHIR. Ниже показано подключение рабочего процесса диалога в SAP к SHIR.
- Проверьте, использует ли клиент плохой физический компьютер для настройки и установки SHIR для запуска внутренней копии SAP.
- Перейдите на портал Фабрика данных Azure и найдите связанную службу SAP CDC, которая используется в потоке данных. Проверьте указанное имя SHIR.
- Проверьте параметры ЦП, памяти, сети и диска физического компьютера, на котором установлен SHIR.
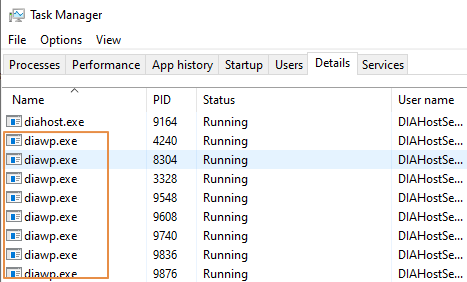
- Проверьте, сколько
diawp.exeзапущено на компьютере SHIR. Можноdiawp.exeвыполнить одно действие копирования. Количество зависит отdiawp.exeпараметров ЦП, памяти, сети и диска компьютера.
Если вы хотите одновременно запускать несколько секций в SHIR, используйте мощную виртуальную машину для настройки SHIR. Или используйте горизонтальное масштабирование с помощью функций высокой доступности и масштабируемости SHIR, чтобы иметь несколько узлов. Дополнительные сведения см. в разделе Высокий уровень доступности и масштабируемость.
Секции
В следующем разделе описывается процесс секционирования для соединителя SAP CDC. Процесс одинаков для таблицы SAP и соединителя SAP BW Open Hub.

Масштабирование можно выполнить в локальной среде ir или Azure IR в зависимости от требований к производительности. Просмотрите сведения о потреблении ЦП SHIR, чтобы просмотреть метрики, которые помогут вам выбрать подход к масштабированию. SHIR можно масштабировать по вертикали или горизонтали в соответствии с вашими потребностями. Рекомендуется развернуть Azure IR по более низкому номеру SKU. Масштабирование в соответствии с требованиями к производительности, определенными с помощью нагрузочного тестирования, а не начиная с более высокого уровня без необходимости.
Примечание
Если вы достигли 70 % емкости, масштабируйте или масштабируйте для SHIR.

Секционирование полезно для начальных или больших полных нагрузок и обычно не требуется для разностных нагрузок. Если не указать секцию, по умолчанию 1 "производитель" в системе SAP (как правило, один пакетный процесс) извлекает исходные данные в очередь операционных данных (ODQ), а SHIR — данные из ODQ. По умолчанию SHIR использует четыре потока для получения данных из ODQ, поэтому в SAP в это время занято четыре диалоговых процесса.
Идея секционирования заключается в том, чтобы разделить большой исходный набор данных на несколько небольших несвязанных подмножеств, которые в идеале равны по размеру и могут обрабатываться параллельно. Этот метод сокращает время, необходимое для линейного создания данных из исходной таблицы в ODQ. Этот метод предполагает, что на стороне SAP достаточно ресурсов для обработки нагрузки.
Примечание
- Число секций, выполняемых параллельно, ограничено количеством ядер драйверов в Azure IR. В настоящее время ведется решение этого ограничения.
- Каждая единица или пакет в ODQMON транзакции SAP является одним файлом в промежуточной папке.
Рекомендации по проектированию при выполнении конвейеров с помощью CDC
Проверьте продолжительность sap для этапа.
Проверьте производительность среды выполнения в приемнике.
Рассмотрите возможность использования функции секционирования для повышения производительности для повышения пропускной способности.
Если продолжительность sap to stage выполняется медленно, рассмотрите возможность изменения размера SHIR до более высоких спецификаций.
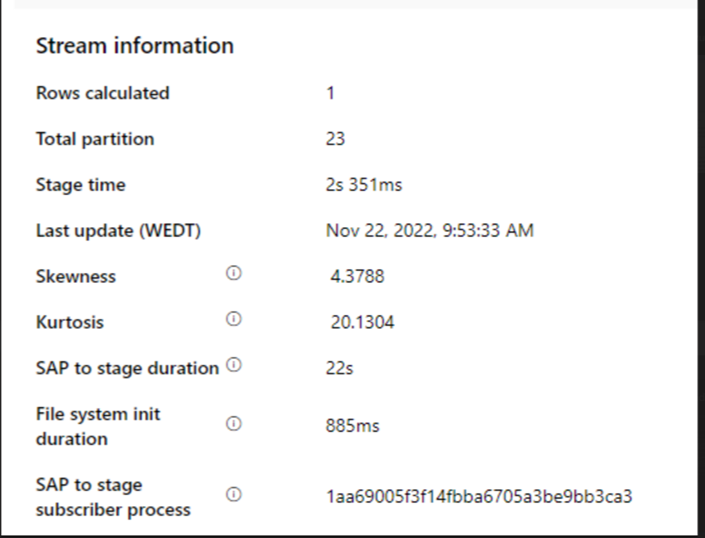
Проверьте, слишком ли медленное время обработки приемника.
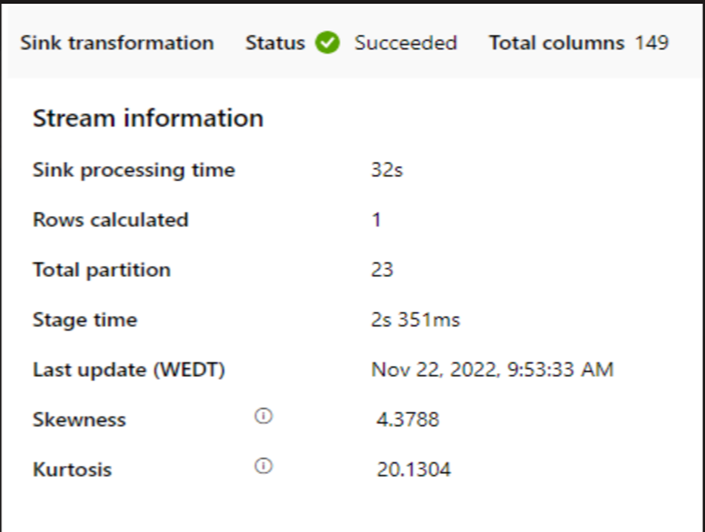
Если для запуска потока данных для сопоставления используется небольшой кластер, это может повлиять на производительность приемника. Используйте большой кластер, например 16 + 256 ядер, поэтому производительность считывает данные из этапа и записывает в приемник.
Для больших томов данных рекомендуется секционировать нагрузку для выполнения параллельных заданий, но не превышать число секций ядра Azure IR, которое также называется ядром кластера Spark.
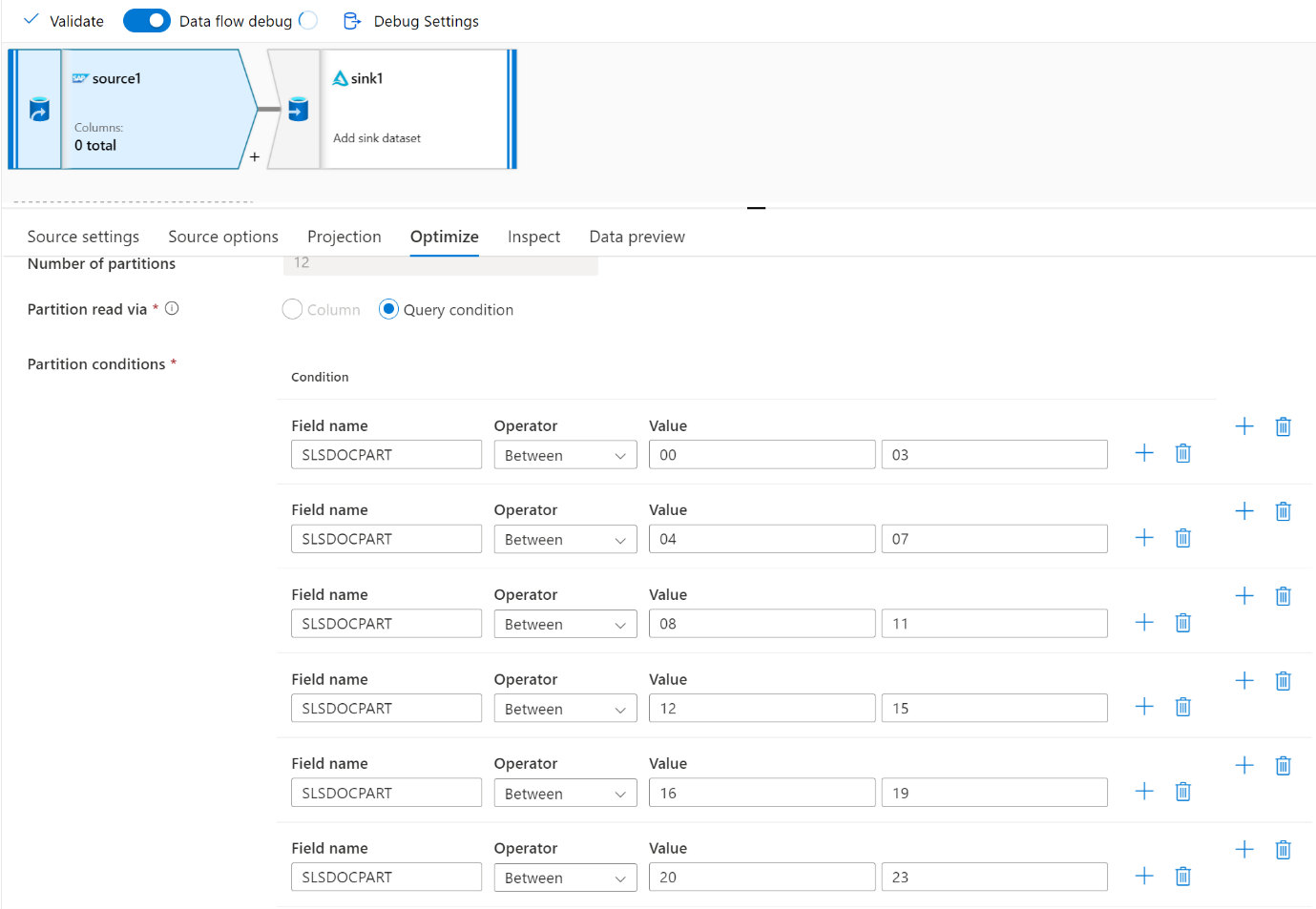
Используйте вкладку Оптимизация , чтобы определить секции. Секционирование исходного кода можно использовать в соединителе CDC.
Примечание
- Существует прямая корреляция между количеством секций с ядрами SHIR и узлами Azure IR.
- Соединитель SAP CDC указан как тип подписчика Odata "Odata access for Operational Data Provisioning" (Доступ Odata для подготовки операционных данных) в odQMON в системе SAP.
Рекомендации по проектированию при использовании соединителя таблиц
- Оптимизируйте секционирование для повышения производительности.
- Рассмотрим степень параллелизма из таблицы SAP.
- Рассмотрим один проект файла для целевого приемника.
- Производительность пропускной способности при использовании больших объемов данных.
Рекомендации по проектированию при использовании соединителя таблиц
Раздел: При секционирования в соединителе таблиц SAP один базовый оператор select разбивается на несколько, используя , где предложения находятся в подходящем поле, например поле с высокой кратностью. Если таблица SAP содержит большой объем данных, включите секционирование, чтобы разделить данные на меньшие секции. Попробуйте оптимизировать количество секций (параметр
maxPartitionsNumber), чтобы секции были достаточно маленькими, чтобы избежать дампов памяти в SAP, но достаточно большими для ускорения извлечения.Параллелизма: Степень параллелизма копирования (параметр
parallelCopies) работает в тандеме с секционированием и предписывает SHIR выполнять параллельные вызовы RFC к системе SAP. Например, если задать для этого параметра значение 4, служба одновременно создает и выполняет четыре запроса на основе указанного параметра секции и параметров. Каждый запрос извлекает часть данных из таблицы SAP.Для достижения оптимальных результатов количество секций должно быть кратным степени параллелизма копирования.
При копировании данных из таблицы SAP в двоичные приемники фактическое число параллельных операций автоматически корректируется в зависимости от объема памяти, доступного в SHIR. Запишите размер виртуальной машины SHIR для каждого цикла тестирования, степень параллелизма копирования и количество секций. Наблюдайте за производительностью виртуальной машины SHIR, производительностью исходной системы SAP и требуемой степенью параллелизма. Используйте итеративный процесс, чтобы определить оптимальные параметры и идеальный размер для виртуальной машины SHIR. Рассмотрим все конвейеры приема, которые одновременно загружают данные из одной или нескольких систем SAP.
Обратите внимание на наблюдаемое количество вызовов RFC к SAP с заданной степенью параллелизма. Если количество вызовов RFC к SAP меньше степени параллелизма, убедитесь, что виртуальная машина SHIR имеет достаточно памяти и ресурсов ЦП. При необходимости выберите виртуальную машину большего размера. Исходная система SAP настроена таким образом, чтобы ограничить количество параллельных подключений. Дополнительные сведения см. в разделе Общие рекомендации этой статьи.
Количество файлов: При копировании данных в файловое хранилище данных, а целевой приемник настроен как папка, по умолчанию создается несколько файлов. Если задать
fileNameсвойство в приемнике, данные записываются в один файл. Рекомендуется выполнять запись в папку в виде нескольких файлов, так как она получает более высокую пропускную способность записи по сравнению с записью в один файл.Производительность производительности: Мы рекомендуем использовать упражнение по анализу производительности для приема больших объемов данных. Этот метод зависит от параметров, таких как секционирование, степень параллелизма и количество файлов, чтобы определить оптимальную настройку для заданной архитектуры, объема и типа данных. Сбор данных из тестов в следующем формате.


Устранение неполадок
Для медленного или неудачного извлечения из системы SAP используйте журналы SAP из SM37 и сопоставляйте их с показаниями в Фабрике данных.
Если активируется только одно пакетное задание, задайте для исходных секций SAP повышение производительности потока данных для сопоставления в Фабрике данных. Дополнительные сведения см. в шаге 6 статьи Сопоставление свойств потока данных.
Если в системе SAP активируется несколько пакетных заданий и время запуска каждого пакетного задания существенно отличается, измените размер Azure IR. При увеличении числа узлов драйверов в Azure IR увеличивается параллелизм пакетных заданий на стороне SAP.
Примечание
Максимальное число узлов драйверов для Azure IR — 16. Каждый узел драйвера может активировать только один пакетный процесс.
Проверьте журналы в SHIR. Чтобы просмотреть журналы, перейдите к виртуальной машине SHIR. Откройте средство просмотра > событий Приложения и журналы > служб Среды выполнения интеграции Соединители > .
Чтобы отправить журналы в службу поддержки, перейдите на виртуальную машину SHIR. Откройте журналы отправки > Integration Runtime configuration manager>. Это действие отправляет журналы за последние семь дней и предоставляет идентификатор отчета. Вам потребуется этот идентификатор отчета и идентификатор запуска. Задокументируйте идентификатор отчета для дальнейшего использования.
При использовании соединителя SAP CDC в сценарии SLT:
Убедитесь, что выполнены предварительные требования. Роли требуются пользователю sap Landscape Transformation (SLT), например ADFSLTUSER в системах OLTP или ECC для работы репликации SLT. Дополнительные сведения см. в статье Необходимые разрешения и роли.
Если в сценарии SLT возникают ошибки, ознакомьтесь с рекомендациями по анализу. Сначала изолируйте и протестируйте сценарий в решении SAP. Например, протестируйте его за пределами фабрики данных, запустив тестовую программу, предоставляемую SAP
RODPS_REPL_TESTв SE38. Если проблема возникает на стороне SAP, при использовании отчета возникает та же ошибка. Вы можете проанализировать извлечение данных в SAP с помощью кодаODQMONтранзакции .Если репликация работает при использовании этого тестового отчета, но не с Фабрикой данных, обратитесь в службу поддержки Azure или Фабрики данных.
В следующем примере показан отчет для
RODPS_REPL_TESTв SE38:

В следующем примере показан код
ODQMONтранзакции :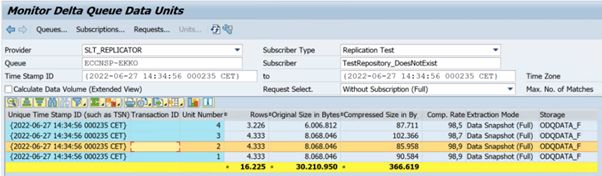
Когда связанная служба Фабрики данных подключается к системе SLT, она не отображает идентификаторы массовой передачи SLT при обновлении поля Контекст .
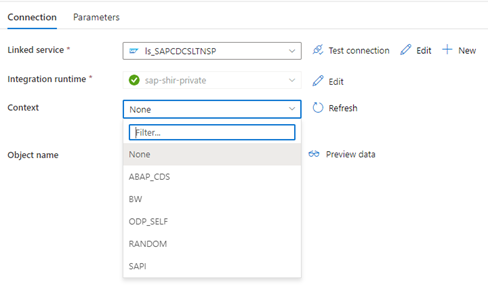
Чтобы запустить сценарий репликации ODP/ODQ для сервера репликации SAP LT, активируйте следующую реализацию бизнес-надстройки (BAdI).
Badi:
BADI_ODQ_QUEUE_MODELРеализация усовершенствования:
ODQ_ENH_SLT_REPLICATIONВ транзакции LTRC перейдите на вкладку Функция эксперта и выберите Активировать или деактивировать реализацию BAdI , чтобы активировать реализацию.
Выберите ответ Да.
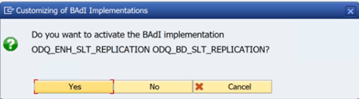
В папке функций ODQ/ODP выберите Проверить, активна ли реализация BAdI.

В диалоговом окне отображается действие программы.
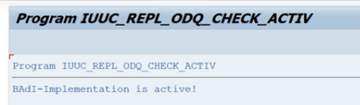
Сброс подписок. Чтобы начать с нового извлечения или остановить репликацию данных, удалите подписку в ODQMON. Это действие также удаляет записи из LTRC. После сброса подписки может потребоваться несколько минут, прежде чем вы увидите эффект в LTRC. Планирование заданий подготовки рабочих данных (ODP) для поддержания чистоты разностных очередей, например
ODQ_CLEANUP_CLIENT_004CDS_VIEW (транзакция DHCDCMON). Начиная с S/4HANA 1909, SAP реплицирует данные из представлений CDS, которые используют триггеры на основе данных вместо столбцов даты. Концепция аналогична SLT, но вместо использования транзакции LTRC для ее мониторинга используется транзакция DHCDCMON.
Устранение неполадок SLT
Сервер репликации SLT обеспечивает репликацию данных в режиме реального времени из источников SAP и (или) источников, не относящихся к SAP, в целевые объекты SAP и (или) целевые объекты, не относящиеся к SAP. Существует три типа наборов инструментов для мониторинга извлечения из SLT в Azure.
- ODQMON — это общее средство мониторинга для извлечения данных. Запустите анализ с помощью ODQMON, чтобы отслеживать несоответствия данных, первоначальный анализ производительности, а также открывать запросы на подписку и извлечение.
- LTRC — это транзакция, используемая для проверка анализа производительности. Это полезно при возникновении проблем с репликацией данных из исходной системы в ODP, так как вы можете отслеживать поток данных и обнаруживать несоответствия.
- SM37 обеспечивает подробный мониторинг каждого шага извлечения SLT.
Обычное ведение домашнего хозяйства должно выполняться с помощью ODQMON, где вы можете управлять подпиской напрямую, и не следует использовать LTRC для того же.
При извлечении данных из SLT могут возникнуть проблемы, например:
Извлечение не выполняется. Проверьте, создано ли подключение SAP CDC в ODQMON, и проверка, существует ли подписка.
Несоответствия данных. Проверьте ODQMON, чтобы просмотреть отдельный запрос данных, и убедитесь, что вы можете видеть данные там. Если данные отображаются в ODQMON, но не в Azure Synapse или фабрике данных, исследование должно выполняться на стороне Azure. Если данные в ODQMON не отображаются, выполните анализ платформы SLT с помощью LTRC.
Проблемы с производительностью. Извлечение данных — это двухэтапный подход. Сначала SLT считывает данные из исходной системы и передает их в ODP. Во-вторых, соединитель SAP CDC получает данные из ODP и передает их в выбранное хранилище данных. Транзакция LTRC позволяет проанализировать первую часть процесса извлечения. Чтобы проанализировать извлечение данных из ODP в Azure, используйте ODQMON и фабрику данных или средства мониторинга Synapse.
Примечание
Для получения дополнительных сведений см. следующие ресурсы.
Производительность SLT
В режиме начальной загрузки (ODPSLT) необходимо выполнить три шага для извлечения данных из SLT в ODP:
- Создание объектов миграции. Этот процесс занимает всего пару секунд.
- Получите доступ к вычислению плана, разделяющего исходную таблицу на небольшие блоки. Этот шаг зависит от начального режима загрузки, выбранного во время настройки SLT, и размера таблицы. Рекомендуется использовать параметр , оптимизированный для ресурсов.
- Нагрузка данных передает данные из исходной системы в ODP.
Каждый шаг управляется фоновыми заданиями. Для отслеживания длительности можно использовать транзакции SM37 и LTRC. Если ваша система используется чрезмерно, фоновые задания могут начаться позже, так как не хватает бесплатных процессов пакетной работы. При бездействии задач производительность снижается.
Если вычисление плана доступа занимает много времени и для начального режима загрузки задано значение "оптимизировано для производительности", измените его на "оптимизированный для ресурсов" и повторно запустите извлечение. Если загрузка данных занимает много времени, увеличьте число параллельных потоков в конфигурации.
При использовании автономной архитектуры для репликации SLT (выделенный сервер репликации SLT) пропускная способность сети между исходной системой и сервером репликации может повлиять на производительность извлечения.
Для репликации:
- Убедитесь, что у вас достаточно заданий передачи данных, которые не зарезервированы для начальной загрузки.
- Убедитесь, что в статистике загрузки нет необработанной записи таблицы ведения журнала.
- Убедитесь, что для параметра репликации задано значение в режиме реального времени.
Дополнительные параметры репликации доступны в LTRS. Дополнительные сведения см. в руководстве по устранению неполадок SLT.
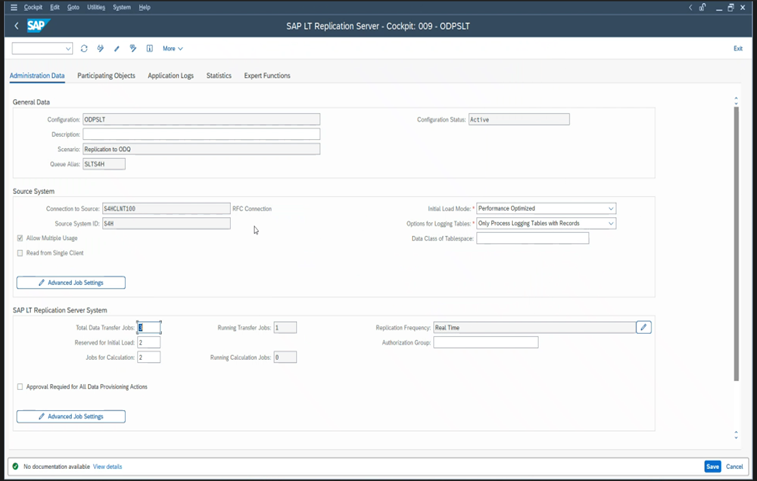
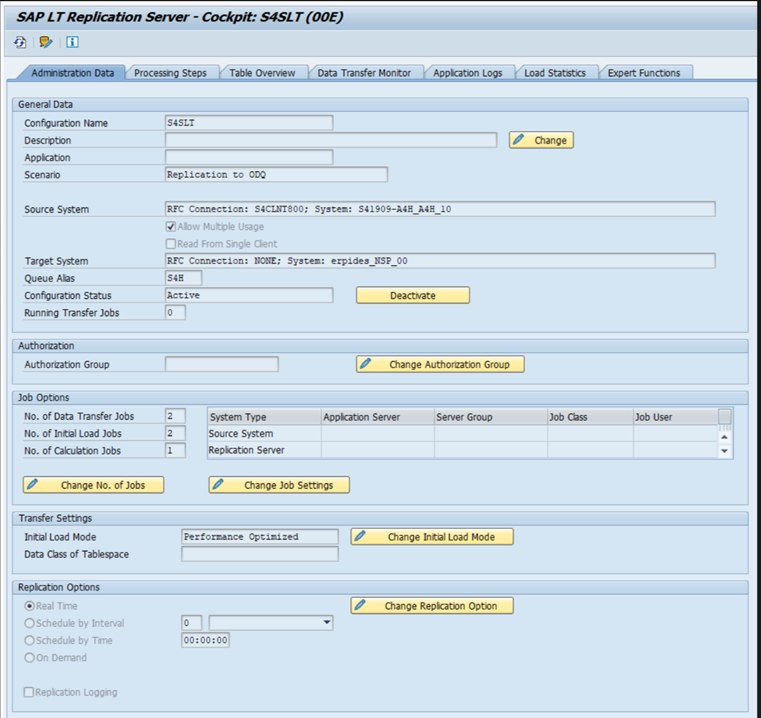
Разные выпуски SAP имеют разные пользовательские интерфейсы LTRC. На следующих снимках экрана показана та же страница для двух разных выпусков.
SAP S/4HANA:
SAP ECC:


Azure Monitor
Сведения о мониторинге извлечения данных SAP см. в следующих ресурсах: