Повышение устойчивости путем репликации рабочей области Log Analytics в регионах (предварительная версия)
Репликация рабочей области Log Analytics в разных регионах повышает устойчивость, позволяя переключиться на реплицированную рабочую область и продолжить операции, если произошел региональный сбой. В этой статье объясняется, как работает репликация рабочей области Log Analytics, как реплицировать рабочую область, как переключиться и вернуться, а также как решить, когда переключаться между реплицированными рабочими областями.
Ниже приведено видео, в которое приведены краткие сведения о том, как работает репликация рабочей области Log Analytics:
Внимание
Хотя иногда мы используем термин отработки отказа, например в вызове API, отработка отказа также часто используется для описания автоматического процесса. Поэтому в этой статье используется переключение терминов, чтобы подчеркнуть, что переключение на реплицированную рабочую область — это действие, которое вы активируете вручную.
Как работает репликация рабочей области Log Analytics
Исходная рабочая область и регион называются основной. Реплицированная рабочая область и альтернативный регион называются вторичными.
Процесс репликации рабочей области создает экземпляр рабочей области в дополнительном регионе. Процесс создает вторичную рабочую область с той же конфигурацией, что и основная рабочая область, и Azure Monitor автоматически обновляет вторичную рабочую область с любыми будущими изменениями, внесенными в конфигурацию основной рабочей области.
Вторичная рабочая область — это теневая рабочая область только для целей устойчивости. В портал Azure не отображается вторичная рабочая область, и вы не можете напрямую управлять и получать к ней доступ.
При включении репликации рабочих областей Azure Monitor отправляет новые журналы, которые отправляются в основную рабочую область в дополнительный регион. Журналы, которые вы отправляете в рабочую область, прежде чем включить репликацию рабочей области, не копируются.
Если сбой влияет на основной регион, вы можете переключиться и перенаправить все запросы приема и запроса в дополнительный регион. После устранения сбоя Azure и работоспособности основной рабочей области вы можете вернуться к основному региону.
При переключении вторичная рабочая область становится активной, а основная становится неактивной. Затем Azure Monitor выполняет прием новых данных с помощью конвейера приема в дополнительном регионе, а не основного региона. При переключении на дополнительный регион Azure Monitor реплицирует все данные, которые вы отправляете из дополнительного региона в основной регион. Процесс асинхронный и не влияет на задержку приема.
Примечание.
После перехода на дополнительный регион, если основной регион не может обрабатывать входящие данные журнала, Azure Monitor буферизирует данные в дополнительном регионе до 11 дней. В течение первых четырех дней Azure Monitor автоматически повторяет повторную репликацию данных периодически.

Защита от потери передаваемых данных во время регионального сбоя
Azure Monitor имеет несколько механизмов, чтобы гарантировать, что данные во время передачи не будут потеряны при сбое в основном регионе.
Azure Monitor защищает данные, которые достигают конечной точки приема основного региона, когда конвейер основного региона недоступен для обработки данных. Когда конвейер становится доступным, он продолжает обрабатывать данные при передаче, а Azure Monitor получает и реплицирует данные в дополнительный регион.
Если конечная точка приема основного региона недоступна, агент Azure Monitor регулярно повторяет отправку данных журнала в конечную точку. Конечная точка приема данных в дополнительном регионе начинает получать данные от агентов через несколько минут после переключения.
Если вы напишете собственный клиент для отправки данных журнала в рабочую область Log Analytics, убедитесь, что клиент обрабатывает неудачные запросы приема.
Рекомендации по развертыванию
Репликация рабочих областей Log Analytics, связанных с выделенным кластером, в настоящее время не поддерживается.
Операция очистки, которая удаляет записи из рабочей области, удаляет соответствующие записи из основной и вторичной рабочих областей. Если один из экземпляров рабочей области недоступен, операция очистки завершается ошибкой.
Azure Monitor поддерживает запросы неактивного региона. Оповещения на основе запросов продолжают работать при переключении между регионами, если служба оповещений в активном регионе не работает должным образом или правила генерации оповещений недоступны. Репликация правил генерации оповещений в регионах в настоящее время не поддерживается.
При включении репликации для рабочих областей, взаимодействующих с Sentinel, может занять до 12 дней, чтобы полностью реплицировать данные списка наблюдения и аналитики угроз в вторичную рабочую область.
Операции управления рабочей областью не могут быть инициированы во время переключения, в том числе:
- Изменение срока хранения рабочей области, ценовой категории, ежедневного ограничения и т. д.
- Изменение параметров сети
- Изменение схемы с помощью новых пользовательских журналов или подключения журналов платформы от новых поставщиков ресурсов, таких как отправка журналов диагностики из нового типа ресурса
Возможности решения, предназначенные для устаревшего агента Log Analytics, не поддерживаются во время переключения. Во время переключения данные решения приемируются от всех агентов.
Процесс отработки отказа обновляет записи системы доменных имен (DNS), чтобы перенаправить все запросы приема в дополнительный регион для обработки. Некоторые HTTP-клиенты имеют "липкие подключения" и могут занять больше времени, чтобы забрать обновленный DNS DNS. Во время переключения эти клиенты могут попытаться принять журналы через основной регион в течение некоторого времени. Вы можете принять журналы в основную рабочую область с помощью различных клиентов, включая устаревший агент Log Analytics, агент Azure Monitor, код (с помощью API приема журналов или устаревшего API сбора данных HTTP), а также другие службы, такие как Microsoft Sentinel.
Сейчас эти функции не поддерживаются или поддерживаются только частично.
Функция Поддержка Вспомогательные планы таблиц Не поддерживается. Azure Monitor не реплицирует данные в таблицах с планом вспомогательного журнала в вторичную рабочую область. Таким образом, эти данные не защищены от потери данных в случае регионального сбоя и недоступны при переключении на вторичную рабочую область. Поиск заданий, восстановление Частично поддерживается— операции поиска и восстановления создают таблицы и заполняют их результатами поиска или восстановленными данными. После включения репликации рабочей области новые таблицы, созданные для этих операций, реплицируются в вторичную рабочую область. Таблицы, заполненные перед включением репликации, не реплицируются. Если эти операции выполняются при переключении, результат непредвиден. Он может завершиться успешно, но не реплицироваться или может завершиться ошибкой в зависимости от работоспособности рабочей области и точного времени. Application Insights по рабочим областям Log Analytics Не поддерживается Аналитика виртуальных машин Не поддерживается Аналитика контейнеров Не поддерживается Приватные каналы Не поддерживается во время отработки отказа
Поддерживаемые регионы
Репликация рабочей области в настоящее время поддерживается для рабочих областей в ограниченном наборе регионов, упорядоченных группами регионов (группами географически смежных регионов). При включении репликации выберите дополнительное расположение из списка поддерживаемых регионов в той же группе регионов, что и основное расположение рабочей области. Например, рабочая область в Западной Европе может быть реплицирована в Северной Европе, но не в западной части США 2, так как эти регионы находятся в разных группах регионов.
В настоящее время поддерживаются следующие группы регионов и регионы:
| Группа регионов | Регионы | Примечания. | ||
|---|---|---|---|---|
| Северная Америка | Восточная часть США | Восточная часть США не может реплицироваться в регионы "Восточная часть США 2" и "Южная часть США". | ||
| Восточная часть США 2 | Восточная часть США 2 не может реплицироваться в регионы "Восточная часть США" и "Южная часть США". | |||
| Западная часть США | ||||
| Западная часть США 2 | ||||
| Центральная часть США | ||||
| Центрально-южная часть США | Южная центральная часть США не может реплицироваться в регионы "Восточная часть США" и "Восточная часть США 2". | |||
| Центральная Канада | ||||
| Европа | Западная Европа | |||
| Северная Европа | ||||
| Южная часть Соединенного Королевства | ||||
| Западная часть Соединенного Королевства | ||||
| Центрально-Западная Германия | ||||
| Центральная Франция |
Требования к месту расположения данных
Разные клиенты имеют разные требования к месту размещения данных, поэтому важно контролировать место хранения данных. Azure Monitor обрабатывает и сохраняет журналы в основных и вторичных регионах, которые вы выбираете. Дополнительные сведения см. в разделе "Поддерживаемые регионы".
Поддержка Microsoft Sentinel и других служб
Различные службы и функции, использующие рабочие области Log Analytics, совместимы с репликацией и переключением рабочих областей. Эти службы и функции продолжают работать при переключении на вторичную рабочую область.
Например, проблемы с региональной сетью, вызывающие задержку приема журналов, могут повлиять на клиентов Microsoft Sentinel. Клиенты, использующие реплицированные рабочие области, могут переключиться на дополнительный регион, чтобы продолжить работу с рабочей областью Log Analytics и Sentinel. Однако если проблема с сетью влияет на работоспособность службы Sentinel, переключение на другой регион не устраняет проблему.
Некоторые возможности Azure Monitor, включая Application Insights и VM Insights, в настоящее время полностью совместимы с репликацией рабочей области и переключением. Полный список см. в разделе "Рекомендации по развертыванию".
Модель ценообразования
При включении репликации рабочей области взимается плата за репликацию всех данных, которые вы используете в рабочей области.
Внимание
Если вы отправляете данные в рабочую область с помощью агента Azure Monitor, API приема журналов, Центры событий Azure или других источников данных, использующих правила сбора данных, обязательно свяжите правила сбора данных с конечной точкой сбора данных рабочей области. Эта связь гарантирует, что данные, которые вы отправляете, реплицируются в вторичную рабочую область. Если вы не связываете правила сбора данных с конечной точкой сбора данных рабочей области, вы по-прежнему взимаете плату за все данные, которые вы выполняете прием в рабочую область, даже если данные не реплицируются.
Требуемые разрешения
| Действие | Требуемые разрешения |
|---|---|
| Включение репликации рабочей области |
Microsoft.OperationalInsights/workspaces/write и Microsoft.Insights/dataCollectionEndpoints/write разрешения, предоставляемые встроенной ролью участника мониторинга, например |
| Переключение и переключение обратно (отработка отказа триггера и восстановление размещения) |
Microsoft.OperationalInsights/locations/workspaces/failover, , Microsoft.OperationalInsights/workspaces/failbackMicrosoft.Insights/dataCollectionEndpoints/triggerFailover/actionи Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action разрешения, предоставляемые встроенной ролью участника мониторинга, например |
| Проверка состояния рабочей области |
Microsoft.OperationalInsights/workspaces/read разрешения на рабочую область Log Analytics, как указано встроенной ролью участника мониторинга, например |
Включение и отключение репликации рабочей области
Вы включаете и отключаете репликацию рабочей области с помощью команды REST. Команда запускает длинную операцию, что означает, что для применения новых параметров может потребоваться несколько минут. После включения репликации может потребоваться до одного часа для начала репликации всех таблиц (типов данных), а некоторые типы данных могут начать репликацию до других. Изменения, внесенные в схемы таблиц после включения репликации рабочей области, например новые пользовательские таблицы журналов или настраиваемые поля, создаваемые, или журналы диагностики, настроенные для новых типов ресурсов, могут занять до одного часа, чтобы начать репликацию.
Включение репликации рабочей области
Чтобы включить репликацию в рабочей области Log Analytics, используйте следующую PUT команду:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Где:
-
<subscription_id>: идентификатор подписки, связанный с рабочей областью. -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области Log Analytics. -
<workspace_name>: имя рабочей области. -
<primary_region>: основной регион для рабочей области Log Analytics. -
<secondary_region>: регион, в котором Azure Monitor создает вторичную рабочую область.
Поддерживаемые значения см. в разделе "Поддерживаемые location регионы".
Эта PUT команда является длительной операцией, которая может занять некоторое время. Успешный 200 вызов возвращает код состояния. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки запроса".
Проверка состояния подготовки запросов
Чтобы проверить состояние подготовки запроса, выполните следующую GET команду:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Где:
-
<subscription_id>: идентификатор подписки, связанный с рабочей областью. -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области Log Analytics. -
<workspace_name>: имя рабочей области Log Analytics.
GET Используйте команду, чтобы убедиться, что состояние подготовки рабочей области изменяется в UpdatingSucceeded, а дополнительный регион задан должным образом.
Примечание.
При включении репликации для рабочих областей, взаимодействующих с Sentinel, может занять до 12 дней, чтобы полностью реплицировать данные списка наблюдения и аналитики угроз в вторичную рабочую область.
Связывание правил сбора данных с конечной точкой сбора данных рабочей области
Агент Azure Monitor, API приема журналов и Центры событий Azure собирать данные и отправлять их в место назначения, указанное в зависимости от настройки правил сбора данных (DCR).
Если у вас есть правила сбора данных, которые отправляют данные в основную рабочую область, необходимо связать правила с конечной точкой сбора системных данных (DCE), которую Azure Monitor создает при включении репликации рабочей области. Имя конечной точки сбора данных рабочей области идентично идентификатору рабочей области. Только правила сбора данных, которые вы связываете с конечной точкой сбора данных рабочей области, обеспечивают репликацию и переключение. Это поведение позволяет указать набор потоков журналов для репликации, который помогает управлять затратами на репликацию.
Чтобы реплицировать данные, собранные с помощью правил сбора данных, свяжите правила сбора данных с конечной точкой сбора данных рабочей области:
В портал Azure выберите правила сбора данных.
На экране правил сбора данных выберите правило сбора данных, которое отправляет данные в основную рабочую область Log Analytics.
На странице обзора правила сбора данных выберите "Настроить DCE" и выберите конечную точку сбора данных рабочей области из доступного списка:
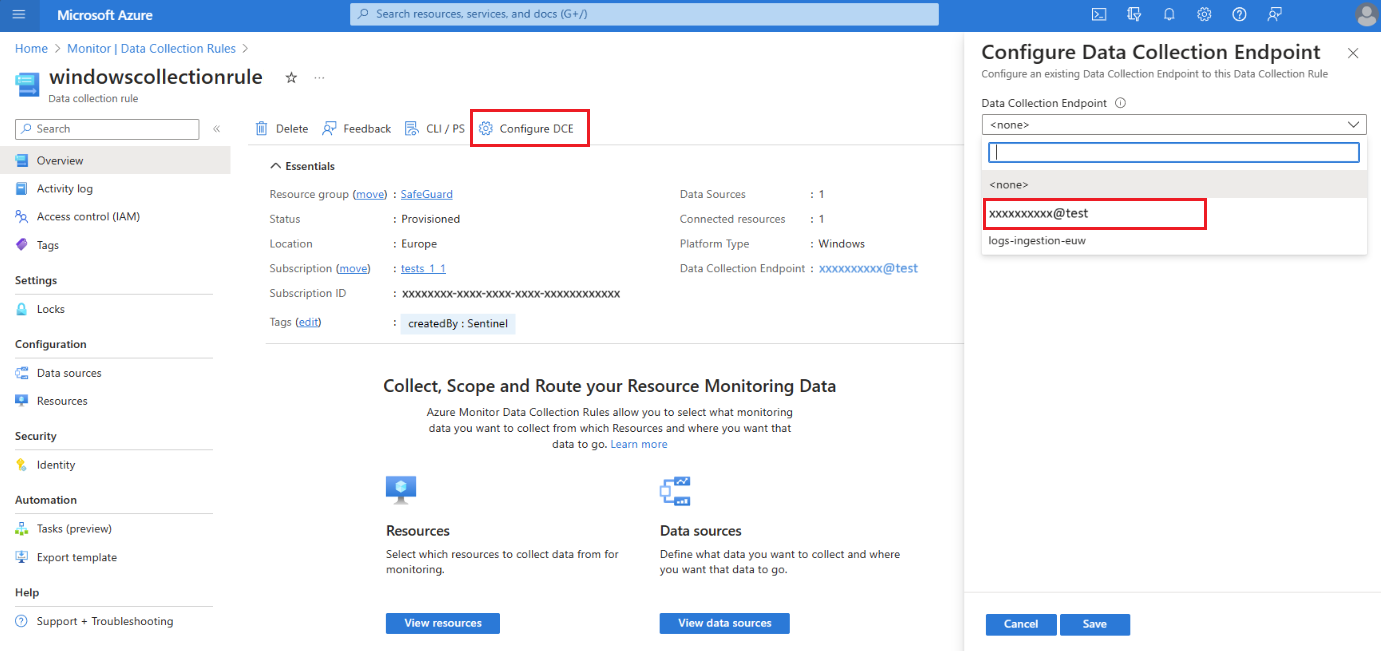 Дополнительные сведения о системе DCE см. в свойствах объекта рабочей области.
Дополнительные сведения о системе DCE см. в свойствах объекта рабочей области.

Внимание
Правила сбора данных, подключенные к конечной точке сбора данных рабочей области, могут ориентироваться только на определенную рабочую область. Правила сбора данных не должны нацелены на другие назначения, например другие рабочие области или учетные записи служба хранилища Azure.
Отключение репликации рабочей области
Чтобы отключить репликацию для рабочей области, используйте следующую PUT команду:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Где:
-
<subscription_id>: идентификатор подписки, связанный с рабочей областью. -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области. -
<workspace_name>: имя рабочей области. -
<primary_region>: основной регион для рабочей области.
Эта PUT команда является длительной операцией, которая может занять некоторое время. Успешный 200 вызов возвращает код состояния. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки запроса".
Мониторинг работоспособности рабочей области и службы
Задержка приема или сбои запросов — это примеры проблем, которые часто могут обрабатываться путем отработки отказа в дополнительный регион. Такие проблемы можно обнаружить с помощью уведомлений о работоспособности служб и запросов журналов.
Уведомления о работоспособности служб полезны для проблем, связанных со службой. Чтобы определить проблемы, влияющие на определенную рабочую область (и, возможно, не всю службу), можно использовать другие меры:
- Создание оповещений на основе работоспособности ресурсов рабочей области
- Настройка собственных пороговых значений для метрик работоспособности рабочей области
- Создайте собственные запросы мониторинга для использования в качестве пользовательских индикаторов работоспособности рабочей области, как описано в разделе "Мониторинг производительности рабочей области с помощью запросов", чтобы:
- Измерение задержки приема на таблицу
- Определите, является ли источник задержки агентами сбора или конвейером приема
- Мониторинг аномалий приема томов на таблицу и ресурс
- Мониторинг частоты успешного выполнения запросов на таблицу, пользователя или ресурс
- Создание оповещений на основе запросов
Примечание.
Вы также можете использовать запросы журналов для мониторинга вторичной рабочей области, но помните, что репликация журналов выполняется в пакетных операциях. Измеряемая задержка может колебаться и не указывает на проблемы со работоспособностью вторичной рабочей области. Дополнительные сведения см. в разделе "Аудит неактивной рабочей области".
Переключение на дополнительную рабочую область
При переключении большинство операций работают так же, как при использовании основной рабочей области и региона. Однако некоторые операции немного отличаются от поведения или блокируются. Дополнительные сведения см . в разделе "Рекомендации по развертыванию".
Когда следует переключиться?
Вы решите, когда переключиться на вторичную рабочую область и вернуться к основной рабочей области на основе текущего мониторинга производительности и работоспособности, а также системных стандартов и требований.
Существует несколько точек, которые следует учитывать в плане переключения, как описано в следующих подразделах.
Тип проблемы и область
Процесс переключения направляет прием и запросы в дополнительный регион, который обычно проходит любой неисправный компонент, который вызывает задержку или сбой в основном регионе. В результате переключение, скорее всего, не поможет:
- Существует межрегиональная проблема с базовым ресурсом. Например, если одни и те же типы ресурсов завершаются ошибкой как в основных, так и в дополнительных регионах.
- Возникает проблема, связанная с управлением рабочей областью, например изменением хранения рабочей области. Операции управления рабочей областью всегда обрабатываются в основном регионе. Во время переключения операции управления рабочими областями блокируются.
Длительность проблемы
Переключение не является мгновенным. Процесс перенаправки запросов зависит от обновлений DNS, которые некоторые клиенты получают в течение нескольких минут, а другие могут занять больше времени. Поэтому полезно понять, может ли проблема быть решена в течение нескольких минут. Если наблюдаемая проблема согласована или непрерывна, не подождите, чтобы переключиться. Далее приводятся некоторые примеры.
Прием. Проблемы с конвейером приема в основном регионе могут повлиять на репликацию данных в вторичной рабочей области. Во время переключения журналы отправляются в конвейер приема в дополнительном регионе.
Запрос. Если запросы в основной рабочей области завершаются сбоем или истечением времени ожидания, могут быть затронуты оповещения поиска по журналам. В этом сценарии переключитесь на вторичную рабочую область, чтобы убедиться, что все оповещения активируются правильно.
Вторичные данные рабочей области
Журналы, которые добавляются в основную рабочую область перед включением репликации, не копируются в вторичную рабочую область. Если вы включили репликацию рабочей области три часа назад и теперь переключитесь на вторичную рабочую область, запросы могут возвращать данные только за последние три часа.
Прежде чем переключать регионы во время переключения, вторичная рабочая область должна содержать полезный объем журналов. Перед активацией переключения рекомендуется ожидать по крайней мере одну неделю после включения репликации. Семь дней позволяют получить достаточные данные в дополнительном регионе.
Переключение триггера
Перед переключением убедитесь, что операция репликации рабочей области успешно завершена. Переключение выполняется только в том случае, если вторичная рабочая область настроена правильно.
Чтобы переключиться на вторичную рабочую область, используйте следующую POST команду:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Где:
-
<subscription_id>: идентификатор подписки, связанный с рабочей областью. -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области. -
<secondary_region>: регион, на который необходимо переключиться во время переключения. -
<workspace_name>: имя рабочей области для переключения.
Эта POST команда является длительной операцией, которая может занять некоторое время. Успешный 202 вызов возвращает код состояния. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки запроса".
Вернуться к основной рабочей области
Процесс обратного переключения отменяет перенаправление запросов и запросов приема журналов в вторичную рабочую область. При переключении Azure Monitor возвращается к запросам маршрутизации и запросам приема журналов в основную рабочую область.
При переключении на дополнительный регион Azure Monitor реплицирует журналы из вторичной рабочей области в основную рабочую область. Если сбой влияет на процесс приема журналов в основном регионе, может потребоваться время, чтобы Azure Monitor завершил прием реплицированных журналов в основную рабочую область.
Когда я должен вернуться?
Существует несколько точек, которые следует учитывать в плане обратного перехода, как описано в следующих подразделах.
Состояние репликации журнала
Прежде чем переключиться обратно, убедитесь, что Azure Monitor завершил репликацию всех журналов, которые будут приема во время переключения в основной регион. Если переключиться обратно, прежде чем все журналы реплицируются в основную рабочую область, запросы могут возвращать частичные результаты до завершения приема журналов.
Вы можете запросить основную рабочую область в портал Azure для неактивного региона, как описано в разделе "Аудит неактивной рабочей области".
Работоспособность основной рабочей области
Существует два важных элемента работоспособности для проверки подготовки к переключении в основную рабочую область:
- Убедитесь, что для основной рабочей области и региона отсутствуют невыполненные уведомления о работоспособности служб.
- Убедитесь, что основная рабочая область обрабатывает журналы и запросы, как ожидалось.
Примеры того, как запрашивать основную рабочую область, когда вторичная рабочая область активна и обходить перенаправление запросов в вторичную рабочую область, см. в разделе "Аудит неактивной рабочей области".
Обратный переключатель триггера
Прежде чем вернуться, подтвердите работоспособность основной рабочей области и завершите репликацию журналов.
Процесс обратного переключения обновляет записи DNS. После обновления записей DNS все клиенты могут получить обновленные параметры DNS и возобновить маршрутизацию в основную рабочую область.
Чтобы вернуться к основной рабочей области, используйте следующую POST команду:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Где:
-
<subscription_id>: идентификатор подписки, связанный с рабочей областью. -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области. -
<workspace_name>: имя рабочей области для переключения во время переключения.
Эта POST команда является длительной операцией, которая может занять некоторое время. Успешный 202 вызов возвращает код состояния. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки запроса".
Аудит неактивной рабочей области
По умолчанию активная область рабочей области — это регион, в котором создается рабочая область, а неактивный регион — это дополнительный регион, в котором Azure Monitor создает реплицированную рабочую область.
При активации отработки отказа этот параметр переключается — активируется дополнительный регион, а основной регион становится неактивным. Мы говорим, что это неактивно, так как это не прямой целевой объект приема журналов и запросов.
Перед переключением между регионами, чтобы убедиться, что рабочая область в неактивном регионе содержит журналы, которые вы ожидаете увидеть там, полезно выполнить запрос к неактивной области.
Неактивный регион запроса
Чтобы запросить данные журнала в неактивном регионе, используйте следующую команду GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Например, чтобы выполнить простой запрос, например Perf | count прошлый день в вашем дополнительном регионе, используйте следующее:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Вы можете убедиться, что Azure Monitor запускает запрос в предполагаемом регионе LAQueryLogs , проверив эти поля в таблице, которая создается при включении аудита запросов в рабочей области Log Analytics:
-
isWorkspaceInFailover: указывает, была ли рабочая область в режиме переключения во время запроса. Тип данных — логическое значение (True, False). -
workspaceRegion: регион рабочей области, предназначенной для запроса. Тип данных — String.
Мониторинг производительности рабочей области с помощью запросов
Мы рекомендуем использовать запросы в этом разделе, чтобы создать правила генерации оповещений, которые уведомляют вас о возможных проблемах с работоспособностью рабочей области или производительностью. Однако решение переключиться требует тщательного рассмотрения и не должно выполняться автоматически.
В правиле запроса можно определить условие для переключения на вторичную рабочую область после указанного количества нарушений. Дополнительные сведения см. в статье "Создание или изменение правила генерации оповещений поиска по журналам".
Два значительных измерения производительности рабочей области включают задержку приема и объем приема. В следующих разделах рассматриваются эти параметры мониторинга.
Мониторинг сквозной задержки приема
Задержка приема измеряет время приема журналов в рабочую область. Измерение времени начинается, когда происходит начальное событие журнала и заканчивается, когда журнал хранится в рабочей области. Общая задержка приема состоит из двух частей:
- Задержка агента: время, необходимое агенту для отчета о событии.
- Задержка конвейера приема (серверная часть): время, необходимое для обработки журналов и записи их в рабочую область.
Разные типы данных имеют разные задержки приема. Вы можете измерить прием для каждого типа данных отдельно или создать универсальный запрос для всех типов, а также более подробный запрос для конкретных типов, которые имеют более высокую важность. Мы рекомендуем измерять 90-й процентиль задержки приема, которая более чувствительна к изменению, чем среднее или 50-й процентиль (медиана).
В следующих разделах показано, как использовать запросы для проверки задержки приема для рабочей области.
Оценка задержки приема базовых таблиц
Начните с определения базовой задержки определенных таблиц в течение нескольких дней.
В этом примере запроса создается диаграмма 90-го процентиля задержки приема в таблице Perf:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
После выполнения запроса просмотрите результаты и отрисовку диаграммы, чтобы определить ожидаемую задержку для этой таблицы.
Мониторинг и оповещение о текущей задержке приема
После установления базовой задержки приема для определенной таблицы создайте правило генерации оповещений поиска по журналам для таблицы на основе изменений задержки за короткий период времени.
Этот запрос вычисляет задержку приема за последние 20 минут:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Так как можно ожидать некоторые колебания, создайте условие правила генерации оповещений, чтобы проверить, возвращает ли запрос значение значительно больше базового значения.
Определение источника задержки приема
Когда вы заметите, что общая задержка приема происходит, вы можете использовать запросы, чтобы определить, является ли источник задержки агентами или конвейером приема.
Этот запрос задает задержку 90-й процентиль агентов и конвейера отдельно:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Примечание.
Хотя на диаграмме отображаются 90-й процентиль данных в виде столбцов с накоплением, сумма данных в двух диаграммах не равна общему приему 90-го процентиля.
Мониторинг тома приема
Измерения тома приема могут помочь определить непредвиденные изменения в общем или табличном томе приема для рабочей области. Измерения тома запроса помогут определить проблемы с производительностью при приеме журналов. К некоторым полезным измерениям тома относятся:
- Общий объем приема на таблицу
- Том приема констант (стенд)
- Аномалии приема — пики и спады в томе приема
В следующих разделах показано, как использовать запросы для проверки тома приема для рабочей области.
Мониторинг общего объема приема на таблицу
Вы можете определить запрос для мониторинга тома приема на таблицу в рабочей области. Запрос может включать оповещение, которое проверяет наличие непредвиденных изменений в общих или табличных томах.
Этот запрос вычисляет общий объем приема за последний час на таблицу в мегабайтах в секунду (MB):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Проверка на стойку приема
При приеме журналов через агенты можно использовать пульс агента для обнаружения подключения. По-прежнему пульс может показать остановку приема журналов в вашей рабочей области. Когда данные запроса показывают нестойку приема, можно определить условие для активации требуемого ответа.
Следующий запрос проверяет пульс агента, чтобы обнаружить проблемы с подключением:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Мониторинг аномалий приема
Вы можете определить пики и спады в данных тома приема рабочей области различными способами. Используйте функцию series_decompose_anomalies() для извлечения аномалий из томов приема, которые вы отслеживаете в рабочей области, или создайте собственный детектор аномалий для поддержки уникальных сценариев рабочей области.
Определение аномалий с помощью series_decompose_anomalies
Функция series_decompose_anomalies() определяет аномалии в ряде значений данных. Этот запрос вычисляет почасовой объем приема каждой таблицы в рабочей области Log Analytics и используется series_decompose_anomalies() для выявления аномалий:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Дополнительные сведения об обнаружении series_decompose_anomalies() аномалий в данных журнала см. в статье "Обнаружение и анализ аномалий" с помощью возможностей машинного обучения KQL в Azure Monitor.
Создание собственного детектора аномалий
Вы можете создать пользовательский детектор аномалий для поддержки требований сценария для конфигурации рабочей области. В этом разделе представлен пример для демонстрации процесса.
Следующий запрос вычисляет:
- Ожидаемый объем приема: в час по таблицам (на основе медианы медианов, но можно настроить логику)
- Фактический объем приема: в час, по таблице
Чтобы отфильтровать незначительные различия между ожидаемым и фактическим томом приема, запрос применяет два фильтра:
- Частота изменений: более 150% или менее 66% ожидаемого тома на таблицу
- Объем изменений: указывает, составляет ли увеличение или уменьшение объема больше 0,1% ежемесячного объема этой таблицы.
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Мониторинг успешности и сбоя запросов
Каждый запрос возвращает код ответа, указывающий на успех или сбой. При сбое запроса ответ также включает типы ошибок. Высокий всплеск ошибок может указывать на проблему с доступностью рабочей области или производительностью службы.
Этот запрос подсчитывает количество запросов, возвращаемых кодом ошибки сервера:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count