Руководство. Обнаружение и анализ аномалий с помощью возможностей машинного обучения KQL в Azure Monitor
Язык запросов Kusto (KQL) включает операторы машинного обучения, функции и подключаемые модули для анализа временных рядов, обнаружения аномалий, прогнозирования и анализа первопричин. Используйте эти возможности KQL для выполнения расширенного анализа данных в Azure Monitor без дополнительных затрат на экспорт данных во внешние средства машинного обучения.
В этом руководстве описано следующее:
- Создание временных рядов
- Определение аномалий в временных рядах
- Настройка параметров обнаружения аномалий для уточнения результатов
- Анализ первопричин аномалий
Примечание.
В этом руководстве содержатся ссылки на демонстрационную среду Log Analytics, в которой можно запустить примеры запросов KQL. Данные в демонстрационной среде являются динамическими, поэтому результаты запроса не совпадают с результатами запроса, показанным в этой статье. Однако вы можете реализовать одни и те же запросы KQL и субъекты в собственной среде, а также все средства Azure Monitor, использующие KQL.
Необходимые компоненты
- Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
- Рабочая область с данными журнала.
Требуемые разрешения
У вас должны быть Microsoft.OperationalInsights/workspaces/query/*/read разрешения на запрашиваемые рабочие области Log Analytics, как указано встроенной ролью Log Analytics Reader, например.
Создание временных рядов
Используйте оператор KQL make-series для создания временных рядов.
Давайте создадим временные ряды на основе журналов в таблице "Использование", в которой содержатся сведения о том, сколько данных каждой таблицы в рабочей области приема каждый час, включая оплачиваемые и неплатежественные данные.
Этот запрос используется make-series для диаграммы общего объема оплачиваемых данных, принятых каждой таблицей в рабочей области каждый день за последние 21 дней:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
На результирующей диаграмме можно четко увидеть некоторые аномалии, например в AzureDiagnostics типах данных и SecurityEvent типах данных:
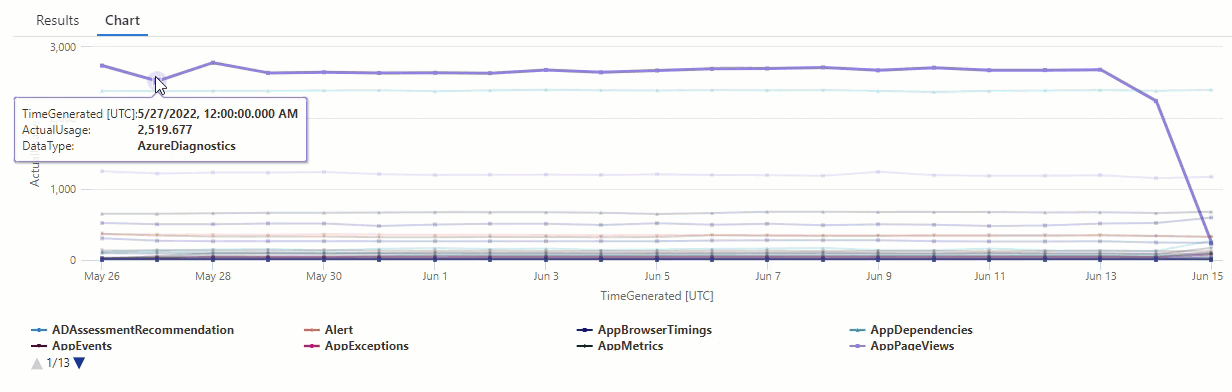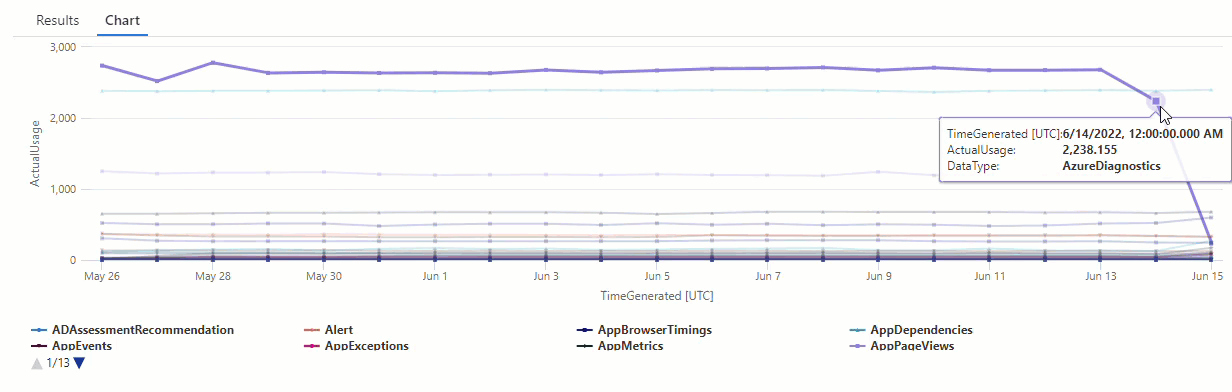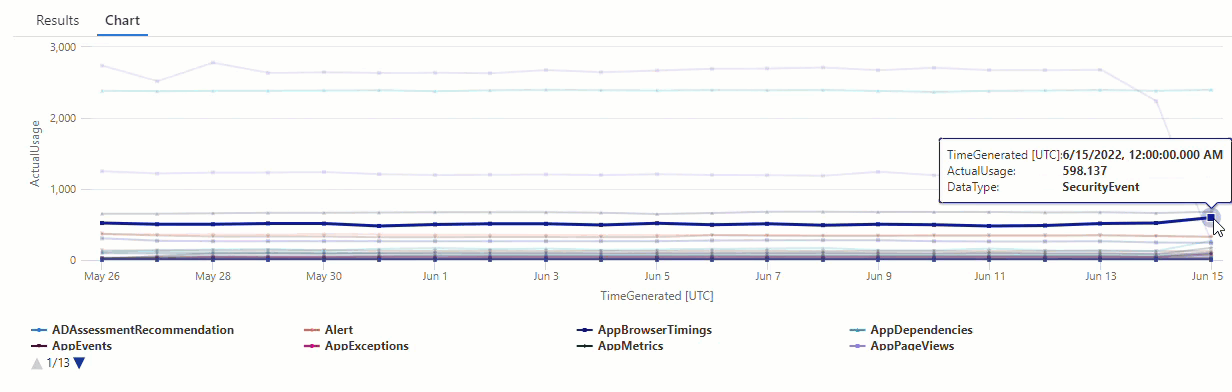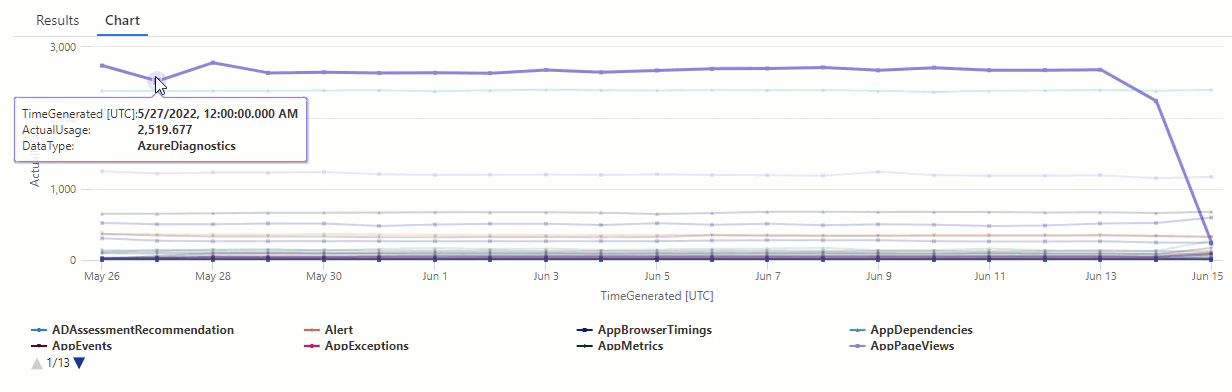
Затем мы будем использовать функцию KQL для перечисления всех аномалий в временных рядах.
Примечание.
Дополнительные сведения о синтаксисе и использовании см. в make-series операторе make-series.
Поиск аномалий в временных рядах
Функция series_decompose_anomalies() принимает ряд значений в качестве входных данных и извлекает аномалии.
Давайте предоставим результирующий набор запроса временных рядов в качестве входных данных функции series_decompose_anomalies() :
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Этот запрос возвращает все аномалии использования для всех таблиц за последние три недели:

Глядя на результаты запроса, можно увидеть, что функция:
- Вычисляет ожидаемое ежедневное использование для каждой таблицы.
- Сравнивает фактическое ежедневное использование с ожидаемым использованием.
- Назначает оценку аномалий каждой точке данных, указывающую степень отклонения фактического использования от ожидаемого использования.
- Определяет положительные (
1) и отрицательные (-1) аномалии в каждой таблице.
Примечание.
Дополнительные сведения о синтаксисе и использовании см. в series_decompose_anomalies() разделе series_decompose_anomalies().
Настройка параметров обнаружения аномалий для уточнения результатов
Рекомендуется просмотреть начальные результаты запроса и при необходимости внести настройки в запрос. Выбросы входных данных могут повлиять на обучение функции, и может потребоваться настроить параметры обнаружения аномалий функции, чтобы получить более точные результаты.
Отфильтруйте результаты series_decompose_anomalies() запроса на аномалии в типе AzureDiagnostics данных:

Результаты показывают две аномалии 14 июня и 15 июня. Сравните эти результаты с диаграммой из первого make-series запроса, где можно увидеть другие аномалии 27 мая и 28:

Разница в результатах возникает, так как series_decompose_anomalies() функция оценивает аномалии относительно ожидаемого значения использования, которое функция вычисляет на основе полного диапазона значений входного ряда.
Чтобы получить более подробные результаты из функции, исключите использование 15 июня - которое является вылитым по сравнению с другими значениями в серии - из процесса обучения функции.
Синтаксис series_decompose_anomalies() функции:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points указывает количество точек в конце ряда, которые следует исключить из процесса обучения (регрессии).
Чтобы исключить последнюю точку данных, установите значение Test_points 1:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Отфильтруйте результаты для AzureDiagnostics типа данных:

Все аномалии на диаграмме из первого make-series запроса теперь отображаются в результирующем наборе.
Анализ первопричин аномалий
Сравнение ожидаемых значений с аномальными значениями помогает понять причину различий между двумя наборами.
Подключаемый модуль KQL diffpatterns() сравнивает два набора данных одной структуры и находит шаблоны, характеризующие различия между двумя наборами данных.
Этот запрос сравнивает AzureDiagnostics использование 15 июня, крайнее вылитее в нашем примере с использованием таблицы в другие дни:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Запрос идентифицирует каждую запись в таблице, как происходит в AnomalyDate (15 июня) или OtherDates. Затем diffpatterns() подключаемый модуль разделяет эти наборы данных с именем A (OtherDates в нашем примере) и B (AnomalyDate в нашем примере) и возвращает несколько шаблонов, которые способствуют различиям в двух наборах:

Глядя на результаты запроса, вы можете увидеть следующие различия:
- Существует 24 892 147 экземпляров приема из ресурса CH1-GEARAMAAKS в течение всех остальных дней в диапазоне времени запроса, а прием данных из этого ресурса не выполняется 15 июня. Данные из ресурса CH1-GEARAMAAKS составляют 73,36% от общего приема в другие дни в диапазоне времени запроса и 0% от общего приема 15 июня.
- Существует 2 168 448 экземпляров приема из ресурса NSG-TESTSQLMI519 в течение всех остальных дней в диапазоне времени запроса и 110 544 экземпляров приема из этого ресурса 15 июня. Данные из ресурса NSG-TESTSQLMI519 составляют 6,39% от общего приема в другие дни в диапазоне времени запроса и 25,61% приема 15 июня.
Обратите внимание, что в среднем существует 108 422 экземпляров приема из ресурса NSG-TESTSQLMI519 в течение 20 дней, составляющих другие дни (деление 2 168 448 на 20). Поэтому прием из ресурса NSG-TESTSQLMI519 15 июня существенно отличается от приема этого ресурса в другие дни. Тем не менее, потому что приема из CH1-GEARAMAAKS 15 июня нет, прием из NSG-TESTSQLMI519 составляет значительно больший процент общего приема на дату аномалии по сравнению с другими днями.
В столбце PercentDiffAB отображается абсолютное процентное различие между A и B (|PercentA — PercentB|), которая является основной мерой разницы между двумя наборами. По умолчанию подключаемый diffpatterns() модуль возвращает разницу в размере более 5 % между двумя наборами данных, но этот порог можно изменить. Например, чтобы вернуть только различия в 20 % или более между двумя наборами данных, можно задать | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) в приведенном выше запросе. Теперь запрос возвращает только один результат:

Примечание.
Дополнительные сведения о синтаксисе и использовании см. в diffpatterns() подключаемых модулях diff.
Следующие шаги
Дополнительные сведения: