Проверка работоспособности узла и pod
Этот материал входит в цикл статей. Начните с обзора.
Если проверка кластера, выполненные на предыдущем шаге, ясно, проверка работоспособность рабочих узлов Служба Azure Kubernetes (AKS). Выполните шесть действий, описанных в этой статье, чтобы проверка работоспособности узлов, определить причину неработоспособного узла и устранить проблему.
Шаг 1. Проверка работоспособности рабочих узлов
Различные факторы могут способствовать неработоспособным узлам в кластере AKS. Одной из распространенных причин является разбивка связи между плоскостями управления и узлами. Эта ошибка часто вызвана неправильной настройкой в правилах маршрутизации и брандмауэра.
При настройке кластера AKS для определяемой пользователем маршрутизации необходимо настроить пути исходящего трафика через виртуальную (модуль) сети (NVA) или брандмауэр, например брандмауэр Azure. Чтобы устранить проблему неправильной настройки, рекомендуется настроить брандмауэр, чтобы разрешить необходимые порты и полные доменные имена (FQDN) в соответствии с руководством по исходящего трафика AKS.
Другая причина неработоспособных узлов может быть неадекватной вычислительной, памяти или ресурсов хранилища, которые создают давление kubelet. В таких случаях масштабирование ресурсов может эффективно устранить проблему.
В частном кластере AKS проблемы с разрешением системы доменных имен (DNS) могут вызвать проблемы связи между плоскостями управления и узлами. Необходимо убедиться, что DNS-имя СЕРВЕРА API Kubernetes разрешается на частный IP-адрес сервера API. Неправильная конфигурация настраиваемого DNS-сервера является распространенной причиной сбоев разрешения DNS. Если вы используете пользовательские DNS-серверы, убедитесь, что они правильно указаны в качестве DNS-серверов в виртуальной сети, где подготавливаются узлы. Кроме того, убедитесь, что частный сервер API AKS можно разрешить с помощью настраиваемого DNS-сервера.
После решения этих потенциальных проблем, связанных с обменом данными на уровне управления и разрешением DNS, вы можете эффективно решать и устранять проблемы со работоспособностью узлов в кластере AKS.
Вы можете оценить работоспособность узлов с помощью одного из следующих методов.
Представление работоспособности контейнеров Azure Monitor
Чтобы просмотреть работоспособность узлов, пользовательских модулей pod и системных модулей pod в кластере AKS, выполните следующие действия.
- В портал Azure перейдите в Azure Monitor.
- В разделе Аналитика области навигации выберите контейнеры.
- Выберите отслеживаемые кластеры для списка отслеживаемых кластеров AKS.
- Выберите кластер AKS из списка, чтобы просмотреть работоспособность узлов, модулей pod пользователей и системных модулей pod.

Представление узлов AKS
Чтобы убедиться, что все узлы в кластере AKS находятся в состоянии готовности, выполните следующие действия.
- В портал Azure перейдите в кластер AKS.
- В разделе Параметры области навигации выберите пулы узлов.
- Выберите Узлы.
- Убедитесь, что все узлы находятся в состоянии готовности.

Мониторинг в кластере с помощью Prometheus и Grafana
При развертывании Prometheus и Grafana в кластере AKS можно использовать панель мониторинга сведений о кластере K8 для получения аналитических сведений. На этой панели мониторинга показаны метрики кластера Prometheus и представлены важные сведения, такие как использование ЦП, использование памяти, сетевое действие и использование файловой системы. В нем также показаны подробные статистические данные для отдельных модулей pod, контейнеров и системных служб.
На панели мониторинга выберите условия узла, чтобы просмотреть метрики о работоспособности и производительности кластера. Вы можете отслеживать узлы, которые могут иметь проблемы с расписанием, сетью, давлением на диск, давлением памяти, пропорциональной производной (PID) или дисковым пространством. Отслеживайте эти метрики, чтобы упреждающее определение и устранение потенциальных проблем, влияющих на доступность и производительность кластера AKS.

Мониторинг управляемой службы для Prometheus и Управляемой Grafana Azure
Предварительно созданные панели мониторинга можно использовать для визуализации и анализа метрик Prometheus. Для этого необходимо настроить кластер AKS для сбора метрик Prometheus в управляемой службе Monitor для Prometheus и подключения рабочей области Monitor к рабочей области Azure Managed Grafana. Эти панели мониторинга предоставляют комплексное представление производительности и работоспособности кластера Kubernetes.
Панели мониторинга подготавливаются в указанном экземпляре Управляемой Grafana Azure в папке Managed Prometheus . К некоторым панелям мониторинга относятся:
- Kubernetes / Вычислительные ресурсы или кластер
- Kubernetes / Вычислительные ресурсы / пространство имен (Pods)
- Kubernetes / Вычислительные ресурсы / Узел (Pods)
- Kubernetes / Вычислительные ресурсы / Pod
- Kubernetes / Вычислительные ресурсы / пространство имен (рабочие нагрузки)
- Kubernetes / Вычислительные ресурсы / Рабочая нагрузка
- Kubernetes / Kubelet
- Метод "Экспортер узлов" / "Метод USE" / Node
- Экспортер узлов или узлы
- Kubernetes / Вычислительные ресурсы / кластер (Windows)
- Kubernetes / Вычислительные ресурсы / пространство имен (Windows)
- Kubernetes / Вычислительные ресурсы / Pod (Windows)
- Kubernetes / USE Method / Cluster (Windows)
- Kubernetes / USE Method / Node (Windows)
Эти встроенные панели мониторинга широко используются в сообществе с открытым кодом для мониторинга кластеров Kubernetes с помощью Prometheus и Grafana. Используйте эти панели мониторинга для просмотра метрик, таких как использование ресурсов, работоспособности pod и сетевое действие. Вы также можете создавать пользовательские панели мониторинга, адаптированные к вашим потребностям мониторинга. Панели мониторинга помогают эффективно отслеживать и анализировать метрики Prometheus в кластере AKS, что позволяет оптимизировать производительность, устранять проблемы и обеспечивать плавную работу рабочих нагрузок Kubernetes.
Панель мониторинга Kubernetes / Вычислительные ресурсы / Узлы (Pod) позволяет просматривать метрики для узлов агента Linux. Вы можете визуализировать использование ЦП, квоту ЦП, использование памяти и квоту памяти для каждого модуля pod.

Если кластер включает узлы агента Windows, можно использовать панель мониторинга Kubernetes / USE Method / Node (Windows) для визуализации метрик Prometheus, собранных с этих узлов. Эта панель мониторинга предоставляет комплексное представление о потреблении ресурсов и производительности для узлов Windows в кластере.
Воспользуйтесь этими выделенными панелями мониторинга, чтобы легко отслеживать и анализировать важные метрики, связанные с ЦП, памятью и другими ресурсами в узлах агента Linux и Windows. Эта видимость позволяет определить потенциальные узкие места, оптимизировать выделение ресурсов и обеспечить эффективную работу в кластере AKS.
Шаг 2. Проверка подключения уровня управления и рабочего узла
Если рабочие узлы работоспособны, следует проверить подключение между управляемым уровнем управления AKS и рабочими узлами кластера. AKS обеспечивает обмен данными между сервером API Kubernetes и отдельным узлом kubelets через безопасный метод связи туннеля. Эти компоненты могут взаимодействовать даже в разных виртуальных сетях. Туннель защищен с помощью шифрования взаимной безопасности уровня транспорта (mTLS). Основной туннель, который использует AKS, называется Konnectivity(прежнее название — apiserver-network-proxy). Убедитесь, что все правила сети и полные доменные имена соответствуют необходимым правилам сети Azure.
Чтобы проверить подключение между управляемым уровнем управления AKS и рабочими узлами кластера AKS, можно использовать средство командной строки kubectl .
Чтобы убедиться, что модули pod агента Konnectivity работают правильно, выполните следующую команду:
kubectl get deploy konnectivity-agent -n kube-system
Убедитесь, что модули pod находятся в состоянии готовности.
Если возникла проблема с подключением между плоскостями управления и рабочими узлами, установите подключение после того, как убедитесь, что необходимые правила исходящего трафика AKS разрешены.
Выполните следующую команду, чтобы перезапустить konnectivity-agent модули pod:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Если перезапуск модулей pod не исправляет подключение, проверка журналы для любых аномалий. Выполните следующую команду, чтобы просмотреть журналы konnectivity-agent модулей pod:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
В журналах должны отображаться следующие выходные данные:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Примечание.
При настройке кластера AKS с интеграцией виртуальной сети сервера API и сетевым интерфейсом контейнеров Azure (CNI) или Azure CNI с динамическим назначением IP-адресов pod не требуется развертывать агенты Konnectivity. Интегрированные модули pod СЕРВЕРА API могут устанавливать прямую связь с рабочими узлами кластера через частные сети.
Однако при использовании интеграции виртуальной сети сервера API с наложением Azure CNI или принести собственный CNI (BYOCNI), коннекттивность развертывается для упрощения обмена данными между серверами API и IP-адресами pod. Связь между серверами API и рабочими узлами остается прямой.
Вы также можете искать журналы контейнеров в службе ведения журнала и мониторинга, чтобы получить журналы. Пример поиска ошибок подключения aks-link см . в журналах запросов из аналитики контейнеров.
Выполните следующий запрос, чтобы получить журналы:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Выполните следующий запрос, чтобы выполнить поиск журналов контейнеров для любого неудачного модуля pod в определенном пространстве имен:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Если вы не можете получить журналы с помощью запросов или средства kubectl, используйте проверку подлинности Secure Shell (SSH). Этот пример находит модуль pod tunnelfront после подключения к узлу через SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Шаг 3. Проверка разрешения DNS при ограничении исходящего трафика
Разрешение DNS является важным аспектом кластера AKS. Если разрешение DNS работает неправильно, это может привести к ошибкам уровня управления или сбоям извлечения образа контейнера. Чтобы убедиться, что разрешение DNS на сервер API Kubernetes работает правильно, выполните следующие действия:
Выполните команду kubectl exec, чтобы открыть командную оболочку в контейнере, работающем в модуле pod.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashПроверьте, установлены ли средства nslookup или dig в контейнере.
Если ни одно средство не установлено в pod, выполните следующую команду, чтобы создать модуль pod служебной программы в том же пространстве имен.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shВы можете получить адрес сервера API на странице обзора кластера AKS в портал Azure или выполнить следующую команду.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvВыполните следующую команду, чтобы попытаться разрешить сервер API AKS. Дополнительные сведения см. в разделе "Устранение неполадок разрешения DNS" внутри модуля pod, но не с рабочего узла.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioПроверьте вышестоящий DNS-сервер из модуля pod, чтобы определить, работает ли разрешение DNS правильно. Например, для Azure DNS выполните
nslookupкоманду.nslookup microsoft.com 168.63.129.16Если предыдущие шаги не предоставляют аналитические сведения, подключитесь к одному из рабочих узлов и попытайтесь разрешить DNS с узла. Этот шаг помогает определить, связана ли проблема с AKS или конфигурацией сети.
Если разрешение DNS успешно выполнено с узла, но не из модуля pod, проблема может быть связана с DNS Kubernetes. Инструкции по отладке разрешения DNS из модуля pod см. в разделе "Устранение неполадок с разрешением DNS".
Если разрешение DNS завершается сбоем с узла, проверьте настройку сети, чтобы убедиться, что соответствующие пути маршрутизации и порты открыты для упрощения разрешения DNS.
Шаг 4. Проверка ошибок kubelet
Проверьте состояние процесса kubelet, выполняемого на каждом рабочем узле, и убедитесь, что он не находится под давлением. Потенциальное давление может относиться к ЦП, памяти или хранилищу. Чтобы проверить состояние отдельных узлов kubelets, можно использовать один из следующих методов.
Книга kubelet AKS
Чтобы убедиться, что узел kubelets агента работает правильно, выполните следующие действия.
Перейдите в кластер AKS в портал Azure.
В разделе "Мониторинг" области навигации выберите книги.
Выберите книгу Kubelet.
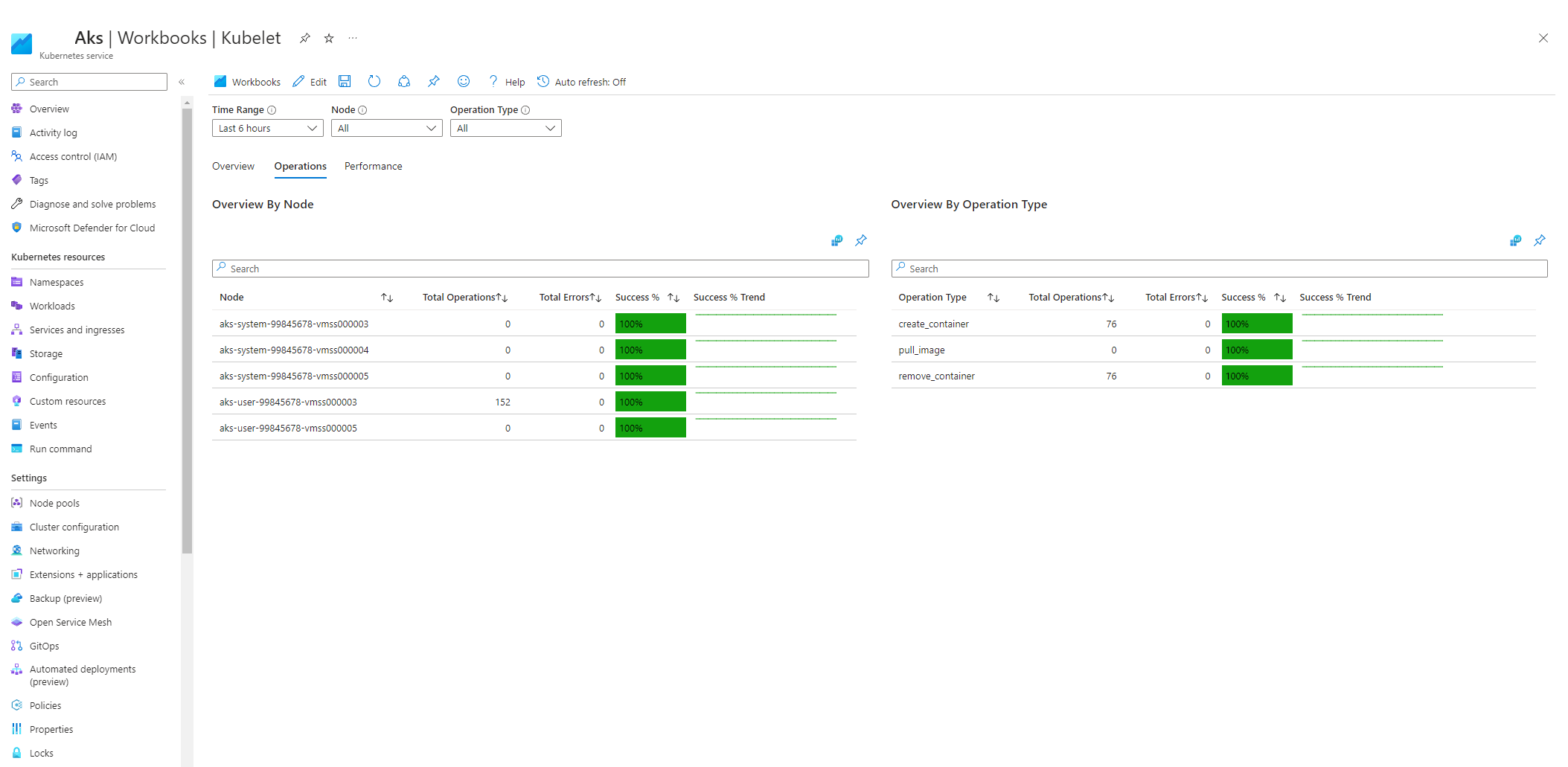
Выберите операции и убедитесь, что операции для всех рабочих узлов завершены.


Мониторинг в кластере с помощью Prometheus и Grafana
Если вы развернули Prometheus и Grafana в кластере AKS, вы можете использовать панель мониторинга Kubernetes / Kubelet для получения аналитических сведений о работоспособности и производительности отдельных узлов kubelets.

Мониторинг управляемой службы для Prometheus и Управляемой Grafana Azure
Предварительно созданную панель мониторинга Kubernetes / Kubelet можно использовать для визуализации и анализа метрик Prometheus для рабочих узлов kubelets. Для этого необходимо настроить кластер AKS для сбора метрик Prometheus в управляемой службе Monitor для Prometheus и подключения рабочей области Monitor к рабочей области Azure Managed Grafana.

Давление увеличивается, когда kubelet перезапускается и вызывает спорное, непредсказуемое поведение. Убедитесь, что количество ошибок не растет постоянно. Случайная ошибка допустима, но постоянный рост указывает на основную проблему, которую необходимо исследовать и устранить.
Шаг 5. Использование средства детектора проблем узла (NPD) для проверка работоспособности узлов
NPD — это средство Kubernetes, которое можно использовать для выявления и создания отчетов о проблемах, связанных с узлом. Она работает в качестве системной службы на каждом узле в кластере. Он собирает метрики и системные сведения, такие как использование ЦП, использование дисков и состояние сетевого подключения. При обнаружении проблемы средство NPD создает отчет о событиях и состоянии узла. В AKS средство NPD используется для мониторинга узлов и управления ими в кластере Kubernetes, размещенном в облаке Azure. Дополнительные сведения см. в разделе NPD на узлах AKS.
Шаг 6. Проверка операций ввода-вывода на диск в секунду (операций ввода-вывода) для регулирования
Чтобы убедиться, что операции ввода-вывода в секунду не регулируются и влияют на службы и рабочие нагрузки в кластере AKS, можно использовать один из следующих методов.
Книга диска ввода-вывода узла AKS
Чтобы отслеживать метрики операций ввода-вывода диска рабочих узлов в кластере AKS, можно использовать книгу ввода-вывода на диске узла. Выполните следующие действия, чтобы получить доступ к книге:
Перейдите в кластер AKS в портал Azure.
В разделе "Мониторинг" области навигации выберите книги.
Выберите книгу ввода-вывода на диске узла.
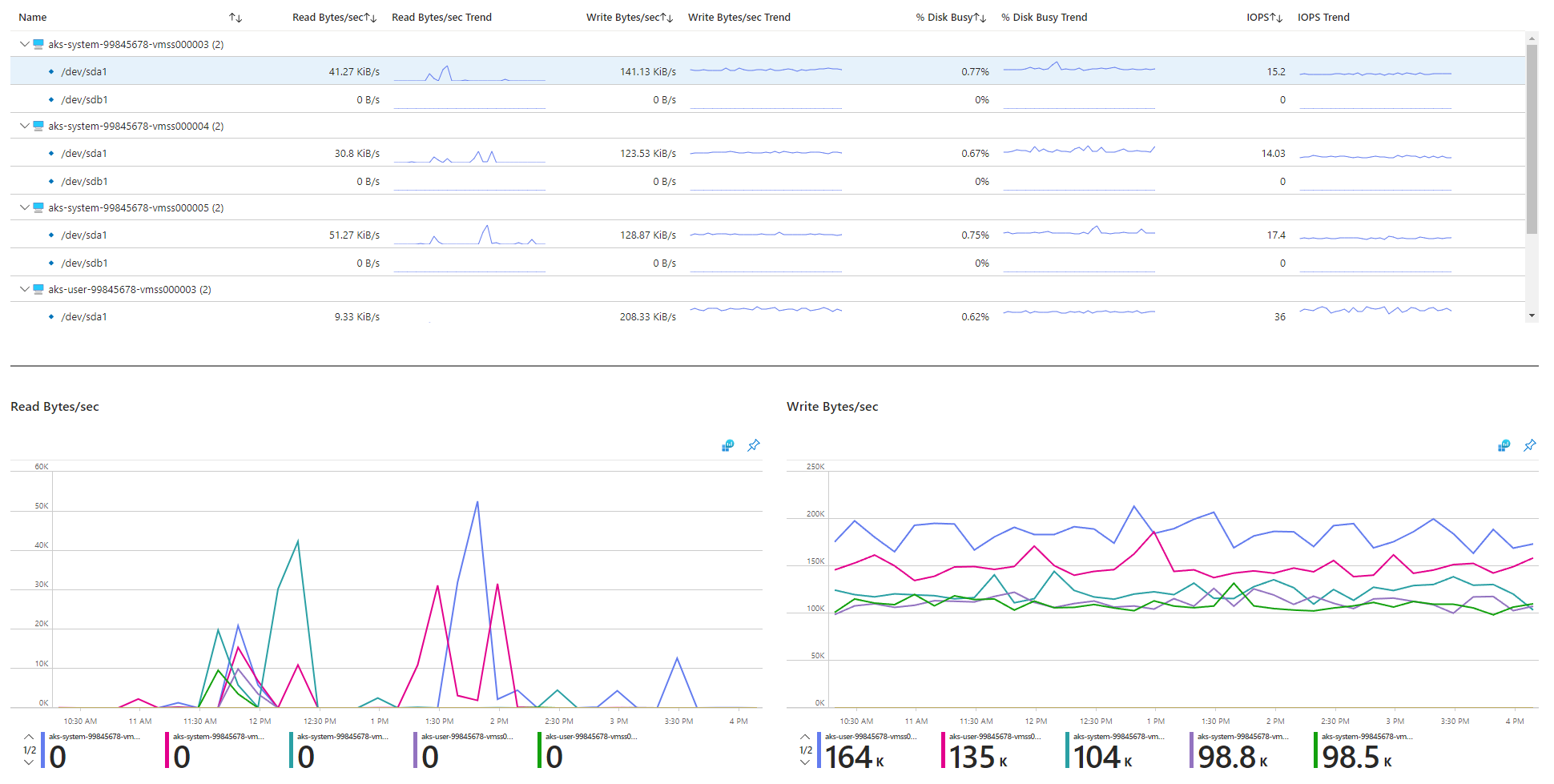
Просмотрите метрики, связанные с вводом-выводом.


Мониторинг в кластере с помощью Prometheus и Grafana
При развертывании Prometheus и Grafana в кластере AKS можно использовать панель мониторинга USE / Node, чтобы получить аналитические сведения о дисках ввода-вывода для рабочих узлов кластера.

Мониторинг управляемой службы для Prometheus и Управляемой Grafana Azure
С помощью предварительно созданной панели мониторинга "Экспортер узлов и узлов" можно визуализировать и анализировать метрики, связанные с диском ввода-вывода, из рабочих узлов. Для этого необходимо настроить кластер AKS для сбора метрик Prometheus в управляемой службе Monitor для Prometheus и подключения рабочей области Monitor к рабочей области Azure Managed Grafana.

Операции ввода-вывода в секунду и диски Azure
Физические устройства хранилища имеют ограничения с точки зрения пропускной способности и максимальное количество операций с файлами, которые они могут обрабатывать. Диски Azure используются для хранения операционной системы, работающей на узлах AKS. Диски подвергаются тем же ограничениям физического хранилища, что и операционная система.
Рассмотрим концепцию пропускной способности. Средний размер операций ввода-вывода можно умножить на число операций ввода-вывода в секунду, чтобы определить пропускную способность в мегабайтах в секунду (МБ секунды). Более крупные размеры операций ввода-вывода преобразуются в более низкий объем операций ввода-вывода из-за фиксированной пропускной способности диска.
Если рабочая нагрузка превышает максимальные ограничения службы ввода-вывода, назначенные дискам Azure, кластер может перестать отвечать и ввести состояние ожидания ввода-вывода. В системах под управлением Linux многие компоненты рассматриваются как файлы, такие как сетевые сокеты, CNI, Docker и другие службы, зависящие от сетевых операций ввода-вывода. Следовательно, если диск не может быть прочитан, сбой распространяется на все эти файлы.
Несколько событий и сценариев могут активировать регулирование операций ввода-вывода в секунду, в том числе:
Значительное количество контейнеров, работающих на узлах, так как docker I/O предоставляет общий доступ к диску операционной системы.
Пользовательские или сторонние средства, используемые для обеспечения безопасности, мониторинга и ведения журнала, которые могут создавать дополнительные операции ввода-вывода на диске операционной системы.
События отработки отказа узла и периодические задания, которые активизировали рабочую нагрузку или масштабируйте количество модулей pod. Это увеличение нагрузки повышает вероятность регулирования вхождений, что потенциально приводит ко всем узлам переход в не готовое состояние до завершения операций ввода-вывода.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Основные авторы:
- Паоло Сальватори | Главный инженер клиента
- Фрэнсис Сими Назарет | Старший технический специалист
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.