Изменение топологии корпоративного поиска для конкретных требований к производительности в SharePoint
ОБЛАСТЬ ПРИМЕНЕНИЯ: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint в Microsoft 365
SharePoint в Microsoft 365
Если в вашей среде поиска применяются определенные требования к производительности, которые не удалось удовлетворить, используя рекомендации, представленные в статье Планирование архитектуры поиска в корпоративной среде в SharePoint Server 2016, то вам необходимо масштабировать топологию архитектуры корпоративного поиска:
Изменение топологии (эта статья)
Реализация измененной топологии (Управление топологией поиска в SharePoint Server)
Знакомы ли вы с компонентами системы поиска в SharePoint Server 2016 и как они взаимодействуют? Прочитав обзор архитектуры поиска в SharePoint Server и архитектуры поиска для SharePoint Server 2016 (или архитектуры поиска для SharePoint Server 2013), прежде чем начать работу, вы познакомитесь с архитектурой поиска, компонентами поиска, базами данных поиска и топологией поиска.
В этой статье мы пошагово опишем, как переработать топологию поиска в соответствии с заданными требованиями к производительности.
Действие 2. Определение компонентов, которые следует масштабировать
Действие 3. Выбор между физическими и виртуальными серверами
Действие 5. Требования к оборудованию, которые необходимо учитывать
После выполнения этих действий вы узнаете:
сколько типов компонентов поиска и баз данных поиска требуется для вашей топологии;
на каких серверах приложений и баз данных следует развернуть каждый компонент поиска;
какие аппаратные ресурсы необходимы каждому серверу приложений и баз данных.
Действие 1. Определение требований к производительности
Убедитесь, что вы понимаете бизнес-требования, на которых основаны требования к производительности. Например, для поиска новостей и финансовой информации необходимы актуальные данные, которые индексируются практически в реальном времени, а для служб поддержки юридических процессов требуется обработка пакетов данных, которые индексируются всего один раз. Используйте один или несколько из следующих способов, чтобы выразить требования к производительности:
Количество индексируемых элементов.
Количество элементов, которое решению поиска необходимо обходить в секунду и с какой задержкой.
Количество запросов, которое решению поиска необходимо обслужить в секунду и с какой задержкой.
Помимо этих требований к производительности, в вашей среде также могут быть требования к релевантности результатов запроса и избыточности топологии поиска. Иногда у вас нет конкретных требований к производительности, но вы определили узкое место в архитектуре поиска, которое может повлиять на производительность. Мы тоже рассмотрим это.
Действие 2. Определение компонентов, которые следует масштабировать
Для увеличения производительности или устранения узкого места можно добавить дополнительные компоненты поиска для выполнения задания или можно увеличить число ресурсов на серверах, на которых размещаются компоненты поиска. Добавление компонентов поиска называют горизонтальным масштабированием, а добавление ресурсов на серверы — вертикальным масштабированием. То, какие компоненты поиска или серверы следует масштабировать, зависит от метрики производительности, которую требуется увеличить, или узкого места, которое необходимо устранить. Вот несколько примеров:
Если для среды требуется высокая частота запросов и узкое место заключается в ресурсах ЦП, добавьте еще одну реплику индекса в каждый раздел индекса. Это позволит службе поиска обрабатывать больше запросов параллельно.
Если узкое место — это ресурсы ЦП для обработки контента, для которого выполняется обход, следует горизонтально масштабировать компоненты обработки контента. Вы также можете вертикально масштабировать эти компоненты, выполняя их на большем числе серверов, с большим числом ЦП или с более быстрыми ЦП. В любом случае масштабирование подразумевает наличие большего объема ресурсов ЦП для обработки контента.
Если компоненты аналитики выполняют свои процессы анализа недостаточно быстро, вертикально масштабируйте ресурсы процессора, число дисковых операций ввода и вывода в секунду или полосу пропускания сети серверов, на которых размещаются компоненты аналитики.
Обратите внимание, что мы не поддерживаем неограниченное масштабирование количества компонентов поиска или баз данных. Найдите максимальные ограничения в разделе Ограничения поиска и оставайтесь в пределах этих ограничений, чтобы обеспечить своевременную и надежную связь между компонентами поиска и базами данных. При необходимости уменьшите емкость архитектуры поиска, уменьшив количество компонентов поиска.
В следующих разделах представлены рекомендации по выбору компонентов или баз данных, которые следует масштабировать для выполнения каждого требования.
Увеличение частоты использования и улучшения актуальности результатов
Сокращение задержки и увеличение пропускной способности запросов
Обработка большего числа элементов в индексе
Если число индексированных элементов увеличивается, а сами элементы меняются с той же частотой, что и раньше, увеличьте емкость топологии поиска за счет горизонтального масштабирования следующих компонентов или баз данных поиска:
| Компонент или база данных поиска | Рекомендация |
|---|---|
| Компонент индекса | Используйте один раздел индекса для каждых 20 млн1 индексированных элементов. Каждый раздел содержит одну или несколько реплик раздела. Все разделы должны содержать одинаковое число реплик. Компонент индекса представляет одну реплику индекса. Таким образом, если требуется две реплики индекса, потребуется в два раза больше компонентов индекса, чем секций индекса. Например, для избыточного индекса с 80 миллионами2 элементов требуется четыре секции. Восемь компонентов индекса представляют четыре раздела при использовании двух реплик для каждого раздела. |
| База данных обхода | Используйте одну базу данных обхода контента для каждых 20 миллионов элементов контента. Например, для индекса со 100 миллионами элементов требуется пять баз данных обхода контента. Если увеличение объема индексируемых элементов подразумевает рост частоты обхода, вам также потребуется больше ресурсов IOPS для обслуживания баз данных обхода контента. Если частота обхода равна 1 документу в секунду, то для базы данных обхода требуется около 10 IOPS. |
| База данных ссылок | Используйте одну базу данных ссылок для каждых 60 миллионов элементов контента. Например, для индекса со 100 миллионами элементов требуется две базы данных ссылок. Если добавление контента подразумевает увеличение частоты обхода, вам может потребоваться больше ресурсов IOPS для обслуживания баз данных ссылок. |
| База данных отчетов аналитики | Необходимое количество баз данных аналитических отчетов зависит от того, как среда поиска использует аналитику и как часто. Как правило, при снижении производительности аналитики добавьте базу данных отчетов аналитики. Например, когда ночное обновление базы данных начинает занимать больше времени. Это может произойти, когда база данных достигает размера 250 ГБ или 20 миллионов строк в общей сложности или когда количество просмотров в день достигает 500 000 уникальных элементов. |
110 миллионов элементов с SharePoint Server 2013 или SharePoint Server 2016, работающих с меньшими ресурсами, чем 500 ГБ хранилища, 32 ГБ ОЗУ и восемью ядрами ЦП.
240 миллионов элементов с SharePoint Server 2013 или с SharePoint Server 2016, работающих с менее 500 ГБ хранилища, 32 ГБ ОЗУ и восемью ядрами ЦП.
Увеличение частоты использования и улучшения актуальности результатов
Существует несколько ситуаций, в которых может потребоваться увеличить частоту использования. Один из примеров — вашей среде требуются актуальные результаты, а объем контента близок к максимально допустимому для вашей архитектуры поиска или контент часто изменяется. Содержимое может часто меняться, если люди архивируют файлы на сайте группы, но теперь они хранят свои файлы в OneDrive во время работы с ними. Служба поиска индексирует все изменения, вносимые в файлы пользователями.
Будет полезно понять, какие факторы влияют на скорость потребления элементов службой поиска.
Скорость обхода элементов службой поиска. Она зависит от:
скорости соединения между компонентами обхода и источниками контента;
типа и среднего размера элементов для обхода;
производительности сервера SQL, на котором размещаются базы данных обхода контента;
объем ресурсов ЦП и памяти, доступных компонентам обхода.
Объем обработки, необходимый каждому элементу перед индексацией.
Число разделов в индексе. Чем разделов больше, тем меньше нагрузка индексации на службу поиска.
Вот, что следует сделать:
Проверьте актуальность результатов в ферме, изучив распределение срока хранения элементов, для которых был выполнен обход. На веб-сайте центра администрирования SharePoint перейдите в раздел Отчеты о работоспособности обхода контента и выберите Пункт Актуальность обхода контента. Распределение по возрасту, приемлемое для вашей фермы, зависит от бизнес-требований. Вот пример: если на странице "Актуальность обхода " показано, что индексация 90 % содержимого занимает четыре часа, но требуется 30 минут, а затем увеличьте скорость приема.
На странице Актуальность обхода контента определите периоды, в которые результаты недостаточно актуальны.
Следуйте рекомендациям для повышения частоты использования в эти периоды времени.
Улучшение актуальности определенного источника контента
Проверьте расписание обхода контента и определите, обход каких источников контента выполняет служба поиска в периоды с недостаточной актуальностью. Если для определенного источника актуальность не соответствует требованиям, рассмотрите следующие возможности.
Увеличьте скорость подключения между сервером, на котором размещается компонент обхода, и источником этого контента. Это скорость обхода контента, скачивание элементов из источников контента и передача элементов в компонент обработки содержимого, что повышает потребность в пропускной способности сети для компонента обхода контента.
Если источник контента — SharePoint, ферме может требоваться больше целей обхода. Сведения о целевых объектах обхода контента см. в статье Управление нагрузкой обхода контента (SharePoint 2010).
Повысьте производительность базы данных контента. Узнайте, как это описано в статье Рекомендации по SQL Server в ферме SharePoint Server.
Увеличение объема ресурсов ЦП для обхода
Если компонент обхода часто использует 100 % ресурсов процессора, советуем добавить еще один компонент обхода или ресурсы процессора на серверы, на которых размещаются компоненты обхода. Именно скорость обхода контента, обнаружение ссылок и управление обходом контента определяют потребность в ресурсах процессора. Обычно обход контента выполняется достаточно быстро, если вы используете два компонента обхода в архитектурах поиска, таких как небольшие и средние примеры архитектуры поиска , по оценкам Майкрософт. Для больших и очень больших архитектур поиска потребуется более двух компонентов обхода.
Увеличение объема ресурсов ЦП для базы данных обхода контента
Проверьте, достаточно ли ресурсов на серверах SQL, на которых размещаются базы данных обхода контента. Узнайте, как это сделать в статье Рекомендации по SQL Server в ферме SharePoint Server.
Если все базы данных обхода контента потребляют множество ресурсов процессора, возможно, следует добавить больше ресурсов процессора на сервер SQL, на котором размещаются базы данных, или добавить другой сервер SQL с таким же числом баз данных обхода контента, что и на существующих серверах SQL. Если у вас, например, два сервера SQL, на каждом из которых размещаются три базы данных обхода контента, добавьте другой сервер SQL с тремя базами данных обхода контента.
Если только одна или несколько баз данных обхода контента используют множество ресурсов процессора, нагрузка среди баз данных обхода контента распределена неравномерно. Рассмотрите возможность перераспределения нагрузки по всем базам данных обхода контента. Обратите внимание, что во время этого процесса служба поиска приостанавливает обход, поэтому результаты будут менее актуальными, пока не будут индексированы изменения, произошедшие во время паузы. Чтобы запустить перераспределение, нажмите кнопку Баланс на странице Базы данных. На странице администрирования поиска перейдите в раздел Журнал обхода контента и выберите Базы данных.
Увеличение объема ресурсов ЦП и памяти для обработки контента
Если компонент обработки контента использует почти 100 % ресурсов ЦП, возможно, следует добавить дополнительные компоненты обработки или добавить ресурсы ЦП на серверы, на которых размещается компонент обработки контента.
Если вы заметили, что память часто перезагружается, рассмотрите возможность увеличения объема памяти на серверах с компонентами обработки контента. В качестве ориентира используйте следующее соотношение: 2 ГБ рабочей памяти на одно ядро ЦП.
Увеличение числа разделов индекса
Проверьте активность обработки контента. Для этого откройте страницу администрирования поиска, выберите Отчеты о работоспособности программы-обходчика и щелкните Действия по обработке контента. Если индексация отнимает больше всего времени, можно разделить индекс на большее число разделов. Чем разделов больше, тем меньше нагрузка индексации на службу поиска.
При добавлении дополнительных секций в выполняющуюся установку индекс будет повторно разбит на разделы. Повторное секционирование индекса может занять несколько часов или дней. Сколько времени это займет, зависит от состояния фермы при начале повторного секционирования.
Сокращение задержки и увеличение пропускной способности запросов
Число запросов, которое служба поиска может обслуживать в секунду, называется пропускной способностью запроса. Она зависит от времени, необходимого службе поиска для обработки запроса, и времени, в течение которого запрос ожидает обработки, так как ресурс недоступен. Сумму времени обработки и ожидания называют задержкой запроса. Чем меньше задержка запроса, тем выше пропускная способность запроса. Чтобы сократить задержку запроса, следуйте указанным далее рекомендациям.
| Рекомендация |
|---|
| Уменьшение времени обработки запросов |
| Уменьшение времени ожидания запросов |
Уменьшение времени обработки запросов
Рассмотрите возможность добавления дополнительных разделов для индекса. Чем больше разделов, тем меньше элементов в каждом разделе, т. е. каждый раздел быстрее реагирует на запросы. Но слишком большое число разделов также не оптимально. Так как компоненту обработки запросов требуется объединять ответы от каждого раздела, чтобы сформировать ответ на запрос, при наличии большого количества разделов объединение занимает много времени. Число реплик для всех разделов должно быть одинаковым.
При добавлении дополнительных секций в выполняющуюся установку индекс выполняется повторно. Повторное секционирование индекса может занять несколько часов или дней. Сколько времени это займет, зависит от состояния фермы при начале повторного секционирования.
Уменьшение времени ожидания запросов
Рассмотрим следующие действия:
Добавьте дополнительные реплики индекса. При добавлении реплик служба поиска распределяет запросы по репликам и обрабатывает их параллельно. Компонент индекса представляет одну реплику индекса. Число реплик у всех разделов должно быть одинаковым, поэтому добавьте один компонент индекса в каждый раздел индекса. При добавлении компонентов индекса в существующие разделы в запущенной установке служба поиска автоматически заполняет новые реплики данными из раздела индекса. Для того чтобы реплики стали работоспособными, может потребоваться несколько часов.
Увеличьте объем памяти на серверах, на которых размещаются компоненты индекса.
Используйте для индекса более быстрое хранилище на серверах с компонентами индекса, например твердотельные накопители (SSD).
Увеличьте объем ресурсов процессора на серверах, на которых размещаются компоненты индекса. Это позволит компонентам обрабатывать больше запросов в секунду. Например, если на сервере используется один ЦП с частотой 2 ГГц, одно ядро может обрабатывать:
5 запросов в секунду, при наличии 1 миллиона элементов в индексе;
2 запроса в секунду, при наличии 5 миллионов элементов в индексе;
1 запрос в секунду, при наличии 10 миллионов элементов в индексе.
Увеличьте объем ресурсов процессора на серверах, на которых размещаются компоненты обработки запросов. Тогда компоненты смогут обрабатывать больше запросов в секунду, особенно если запросы сложные и редкие. Именно скорость запросов и количество преобразований запросов определяет потребность в ресурсах процессора для компонента обработки запросов. Обычно компоненту обработки запросов требуется одно ядро ЦП на 4 запроса в секунду.
Уменьшение времени аналитической обработки
Аналитическая обработка выполняется каждую ночь. Компонент обработки аналитики хранит промежуточные данные на сервере, где размещен компонент, и хранит результаты анализа в базе данных отчетов аналитики. Если из-за сбоя обработки аналитики прерывается, это не повлияет на обход документов или обработку запросов. Но результаты запроса не будут иметь оптимальной релевантности.
Рассмотрим следующие действия:
Если вашей среде необходима оптимальная релевантность результатов запросов, а обработка аналитики недостаточно быстра для этого, добавьте диски (шпиндели) или используйте более быстрые диски.
Если для обработки аналитики требуется больше времени, чем обычно, добавьте базу данных отчетов аналитики. Время обработки может увеличиться, когда размер базы данных достигает 250 ГБ или 20 миллионов строк или когда число просмотров в день достигает 500 000 уникальных элементов.
Если для завершения обработки аналитики требуется больше 24 часов, добавьте дополнительные компоненты обработки аналитики или добавьте ресурсы процессора на серверы, на которых размещаются компоненты обработки аналитики. Именно количество элементов в индексе и действие на сайте определяет потребность в ресурсах процессора.
Если обработка аналитики вообще не завершается или возникают оповещения о работоспособности дисков на серверах, где размещаются компоненты аналитики, увеличьте дисковое пространство на серверах. Чтобы компонент аналитики быстрее обрабатывал большие объемы промежуточных данных, можно добавить дополнительные компоненты обработки аналитики или можно добавить ресурсы процессора на серверы, на которых размещается компонент обработки аналитики.
Реализация избыточности компонентов и баз данных поиска
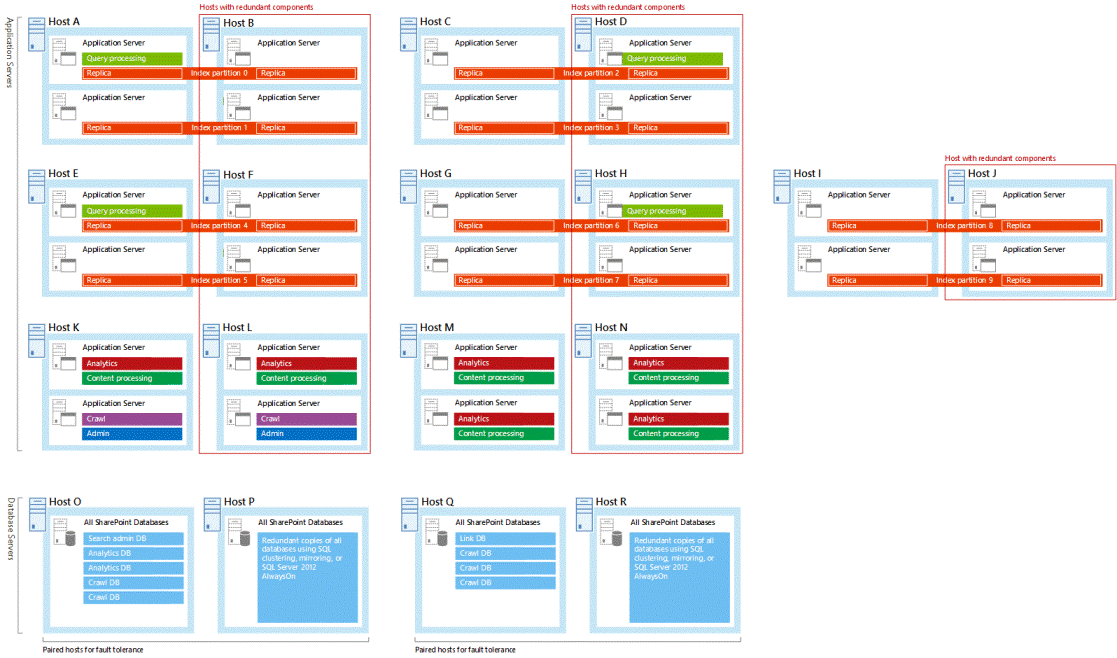
Архитектура поиска будет поддерживать высокую доступность, если разместить избыточные компоненты и базы данных поиска на отдельных доменах сбоя. Рекомендуется разработать топологию поиска с избыточными базами данных и компонентами поиска. Все примеры архитектуры поиска, протестированные корпорацией Майкрософт, имеют избыточные компоненты поиска и базы данных. Эти примеры могут оказаться полезными при работе с собственной топологией (см. статью Архитектура корпоративного поиска для SharePoint 2016).
Следуйте указанным далее рекомендациям.
Реализация избыточности индекса
Индекс является избыточным, если он содержит две или более реплик индекса на каждую секцию индекса. Если сервер, на котором размещена реплика индекса, происходит сбой, это может снизить производительность, но поиск по-прежнему может обслуживать запросы и элементы индекса. Но если среда всегда требует одинаковой производительности, поиску требуется больше избыточных компонентов индекса. Например, вы разработали топологию поиска с двумя репликами на секцию, чтобы сократить время ожидания запросов, а в вашей среде требуется короткое время ожидания запросов. Увеличьте количество реплик индекса на секцию.
Все разделы должны содержать одинаковое число реплик. Компонент индекса представляет одну реплику индекса. Таким образом, если требуется две реплики индекса, потребуется в два раза больше компонентов индекса, чем секций индекса. Например, для избыточного индекса SharePoint Server 2016a с 80 миллионами элементов требуется четыре секции. Восемь компонентов индекса представляют четырех разделы при использовании двух реплик для каждого раздела.
При добавлении компонентов индекса в существующие разделы в запущенной установке служба поиска автоматически заполняет новые реплики данными из раздела индекса. Для того чтобы реплики стали работоспособными, может потребоваться несколько часов.
Реализация избыточности компонентов обхода и обработки контента, обработки запросов, обработки аналитики и администрирования поиска
В качестве примера рассмотрим компонент обхода контента. Если вам нужно отключить один из серверов, на котором размещен компонент обхода контента для обслуживания, это может снизить актуальность результатов, но поиск по-прежнему может сканировать все содержимое. Но если среда постоянно требует одинаковой свежести результатов, поиску требуются более избыточные компоненты обхода контента. Например: вы разработали топологию поиска с тремя компонентами обхода контента, и вам нужна та же актуальность результатов, даже если два сервера компонентов обхода контента завершаются сбоем. Добавьте еще два компонента обхода контента.
Компонент администрирования поиска — исключение из этого принципа. Одного компонента администрирования достаточно для топологии поиска любого размера. Таким образом двух компонентов администрирования поиска достаточно для обеспечения избыточности.
Компоненты обработки контента распределяют нагрузку между собой, поэтому избыточные компоненты обработки контента увеличивают емкость для обработки элементов.
Реализация избыточности баз данных поиска
Чтобы сделать базы данных поиска избыточными, используйте функции обеспечения высокой доступности SQL Server (см. статью Создание архитектуры и стратегии обеспечения высокой доступности для SharePoint Server).
Действие 3. Выбор между физическими и виртуальными серверами
Когда вы изначально планировали архитектуру поиска, вы решили использовать физические серверы, виртуальные машины или их комбинацию. Подумайте, по-прежнему ли верно это решение. Если компонентов поиска стало намного больше, можно воспользоваться виртуальными машинами, чтобы упростить управление архитектурой. Например, проще заменить неисправную виртуальную машину, чем физическую. Обратите внимание, что хотя виртуальной средой и проще управлять, уровень ее производительности иногда может быть меньше, чем у физической среды. На физическом сервере могут размещаться больше компонентов поиска, чем на виртуальном. Полезные рекомендации см. в статье Обзор виртуализации ферм и архитектур для SharePoint 2013.
Действие 4. Определение серверов, на которых следует разместить тот или иной компонент или базу данных
После изменения топологии поиска следует назначить компоненты и базы данных поиска физическим или виртуальным серверам. Существует не один оптимальный способ назначения компонентов поиска физическим серверам или виртуальным машинам, но у нас есть рекомендации для вас:
Один тип компонента поиска на каждом сервере
На каждом физическом сервере или виртуальной машине может размещаться только один компонент поиска каждого типа. Компонент индекса служит исключением. Физические серверы или виртуальные машины могут содержать до четырех компонентов индекса. Сведения об этих ограничениях см. в разделе Ограничения поиска.
Разделите компоненты массовой обработки и обработки в реальном времени
Старайтесь не размещать компоненты массовой обработки и обработки в реальном времени на одном физическом сервере или виртуальной машине. Массовой обработкой занимаются компоненты обхода контента, обработки контента и компоненты обработки аналитики. Компоненты индекса и обработки запросов выполняют обработку в реальном времени.
Не смешивайте конкурирующие компоненты поиска
Старайтесь не размещать компоненты поиска на одном физическом сервере или виртуальной машине, если они конкурируют друг с другом за одни ресурсы. Ниже приведена таблица, показывающая относительный объем ресурсов, необходимых каждому компоненту.
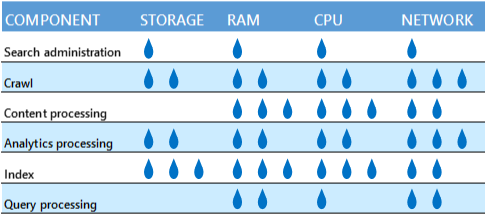
Например, будет плохой идеей разместить компоненты обхода контента и обработки аналитики на одном сервере, так как они интенсивно используют полосу пропускания сети. Но если у физического сервера или виртуальной машины достаточно сетевой емкости, компоненты не будут конкурировать.
Еще один пример — очень большая архитектура поиска, проверенная Майкрософт. В ней компоненты обхода и администрирования поиска мы разместили на отдельных виртуальных машинах. В противном случае они могли конкурировать за ресурсы процессора, снижая скорость обхода контента.
Используйте отказоустойчивые домены
Назначьте избыточные компоненты поиска узлам в отдельных отказоустойчивых доменах.
Действие 5. Требования к оборудованию, которые необходимо учитывать
Следующий шаг состоит в планировании необходимого оборудования.
Выбор аппаратных ресурсов для серверов узлов
Каждому компоненту и каждой базе данных поиска требуется минимальный объем аппаратных ресурсов хост-сервера для нормальной работы. Но чем больше аппаратных ресурсов у вас есть, тем выше будет производительность вашей архитектуры поиска. Поэтому рекомендуется использовать объем ресурсов больше минимального. Необходимые каждому компоненту поиска ресурсы зависят от рабочей нагрузки, которая в основном определяется скоростью обхода, скоростью запросов и числом индексируемых элементов.
Например, при размещении виртуальных машин в Windows Server 2008 R2 с пакетом обновления 1 (SP1) число ядер ЦП на каждую из них не должно превышать четырех. Если у вас есть Windows Server 2012 или более новой версии, вы можете использовать восемь или больше ядер ЦП для каждой виртуальной машины. Так вы сможете прибегнуть к горизонтальному масштабированию, добавив число ядер для каждой виртуальной машины, а не к вертикальному (увеличение числа виртуальных машин). Настраивайте серверы или виртуальные машины, на которых размещаются одинаковые компоненты поиска, и используйте одинаковые аппаратные ресурсы. В качестве примера можно использовать компонент индекса. Если разделы индекса размещаются на виртуальных машинах, производительность всей архитектуры поиска определяется производительностью самой медленной виртуальной машины.
Общее хранилище
Убедитесь, что на каждом сервере узла достаточно места на диске для базовой установки операционной системы Windows Server и для программных файлов SharePoint Server 2016. Серверу узла также требуется свободное дисковое пространство для диагностических целей, например для ведения журнала, отладки и создания дампов памяти по выполняемым ежедневно операциям, а также для файла подкачки. Как правило, 80 ГБ дискового пространства достаточно для операционной системы Windows Server и программных файлов SharePoint Server 2016.
Увеличьте объем хранилища для пространства журналов SQL каждого сервера базы данных. Если не настроить сервер базы данных для частого резервного копирования баз данных, пространство журнала SQL использует много хранилища. Дополнительные сведения о планировании баз данных SQL см. в статье Storage and SQL Server capacity planning and configuration (SharePoint Server).
Минимальный объем хранилища, необходимый для базы данных отчетов аналитики, может быть разным. Это связано с тем, что объем хранилища зависит от того, как пользователи взаимодействуют с SharePoint Server 2016. Если взаимодействие происходит часто, обычно требуется хранить больше событий. Узнайте, какой объем хранилища текущая архитектура поиска использует для базы данных аналитики, и назначьте по крайней мере этот объем переработанной топологии.
Минимальные ресурсы для компонента индекса
Далее представлены минимальные ресурсы, необходимые серверу или виртуальной машине для размещения одного компонента индекса или размещения одного компонента индекса и одного компонента обработки запросов:
| Хранилище | Память | Процессор | Пропускная способность сети |
| 500 ГБ для индекса1 | 32 GB1 | 64-разрядный, не менее 8 ядер1, 2. | 2 Гбит/с |
1В SharePoint Server 2013 минимальный объем ресурсов составляет 500 ГБ хранилища, 16 ГБ ОЗУ и четыре ядра ЦП.
2Вы можете использовать 16 ГБ оперативной памяти и четыре ядра ЦП с SharePoint Server 2016, но тогда каждый компонент индексирования сможет содержать не более 10 млн элементов (а не 20 млн).
Минимальные ресурсы для компонента обработки аналитики
Далее представлены минимальные ресурсы, необходимые серверу или виртуальной машине для размещения одного компонента обработки аналитики:
| Хранилище | Память | Процессор | Пропускная способность сети |
| 300 ГБ для локальной обработки аналитики | 8 ГБ | 64-разрядная версия, минимум четырехъядерный процессор, но рекомендуется восьмиядерный. | 2 Гбит/с |
Если на сервере размещается один компонент обработки аналитики и один или несколько компонентов массовой обработки, увеличьте объем памяти до 16 ГБ.
Минимальные ресурсы для компонентов обхода контента, обработки контента, обработки запросов и администрирования поиска
Далее представлены минимальные ресурсы, необходимые серверу или виртуальной машине для размещения одного из следующих компонентов:
| Хранилище | Память | Процессор | Пропускная способность сети |
| Не требуется | 8 ГБ | 64-разрядная версия, минимум четырехъядерный процессор, но рекомендуется восьмиядерный. | 2 Гбит/с |
Если на сервере размещаются два или более из этих компонентов, увеличьте объем памяти до 16 ГБ.
Компоненту обработки запроса требуется хорошая пропускная способность сети. Это количество секций индекса, размер запросов и результатов, которые управляют этой потребностью в пропускной способности сети. Например, 20 запросов в секунду на компонент обработки запросов (20 QPS/QPC) и индекс с 20 разделами формируют входящий трафик 200 Мбит/с и исходящий трафик 100 Мбит/с для сервера или виртуальной машины, на которых размещается компонент обработки запросов.
Минимальные ресурсы для баз данных поиска
Ниже представлены минимальные ресурсы, необходимые для размещения одной или нескольких баз данных поиска на сервере или виртуальной машине.
| Хранилище | Память | Процессор | Пропускная способность сети |
| Хранилище, необходимое базе данных отчетов аналитики, зависит от того, каким образом и как часто среда поиска использует аналитику. Используйте текущий объем базы данных в качестве ориентира. | 8 ГБ для сред малого размера. 16 ГБ для сред среднего размера. |
64-разрядный, 4 ядра. | 2 Гбит/с |
Планирование производительности хранилища
Скорость работы хранилища влияет на производительность поиска. Убедитесь, что имеющееся у вас хранилище работает достаточно быстро и способно обрабатывать трафик от компонентов и баз данных поиска. Скорость работы дисков измеряется количеством операций ввода-вывода в секунду (IOPS).
Способ доставки данных от компонентов поиска и операционной системы в рамках хранилища влияет на производительность поиска. Для получения хороших результатов можно сделать следующее.
Разделить файлы операционной системы Windows Server, файлы программ SharePoint Server 2016 и журналы диагностики между тремя отдельными томами или разделами хранилища с нормальной производительностью.
Храните данные компонентов поиска в отдельном томе или разделе хранилища. Кроме того, компоненты индекса необходимо хранить на томах с высокой производительностью.
Примечание.
Настраиваемое расположение для данных компонента поиска можно задать при установке SharePoint Server 2016 на узле. Любой компонент поиска на узле, которому требуется хранить данные, будет хранить их в указанном расположении. Чтобы изменить это расположение позже, необходимо переустановить SharePoint Server 2016.
Выбор типа хранилища
Общие сведения об архитектуре хранилища и типах дисков см. в статье Планирование и настройка емкости хранилища и SQL Server (SharePoint Server 2016). Для серверов, на которых размещены базы данных поиска или компоненты индекса, обработки данных аналитики либо администрирования поиска, необходимы хранилища, обеспечивающие малые задержки и достаточное количество операций ввода-вывода в секунду. В следующих таблицах показано, какое количество операций ввода-вывода в секунду необходимо для работы этих компонентов и баз данных поиска.
При развертывании общего хранилища, например SAN или NAS пиковая нагрузка на диски для одного компонента поиска обычно совпадает с пиковой нагрузкой на диски для другого компонента поиска. Чтобы определить количество операций ввода-вывода в секунду общего хранилища, необходимое для работы поиска, следует вычислить сумму количества операций ввода-вывода в секунду, необходимого для каждого из этих компонентов.
Требования к количеству операций ввода-вывода в секунду для компонента поиска
| Имя компонента | Сведения о компоненте | Требуемое количество операций ввода-вывода в секунду | Использование отдельного тома или раздела хранилища |
|---|---|---|---|
| Компонент индекса | Использует хранилище при объединении индекса и при обработке запросов и ответах на них. | 300 операций ввода-вывода в секунду для чтения блоков размером 64 КБ в случайном порядке. 100 операций ввода-вывода в секунду для записи блоков размером 256 КБ в случайном порядке. 200 МБ/с для последовательного чтения. 200 МБ/с последовательной записи. |
Да |
| Компонент аналитики | Выполняет локальный анализ данных путем массовой обработки. | Нет | Да |
| Компонент обхода | Выполняет локальное хранение загруженного контента перед отправкой его на компонент обработки контента. Хранилище ограничено пропускной способностью сети. | Нет | Да |
Требования к количеству операций ввода-вывода в секунду для базы данных поиска
| Имя базы данных | Требуемое количество операций ввода-вывода в секунду | Типичная нагрузка на подсистему ввода-вывода. |
|---|---|---|
| База данных обхода | Количество операций ввода-вывода в секунду варьируется от среднего до большого | Скорость обхода контента составляет 10 операций ввода-вывода на 1 документ в секунду. |
| База данных ссылок | Среднее количество операций ввода-вывода в секунду | 10 операций ввода-вывода в секунду на 1 млн элементов в индексе поиска. |
| База данных администрирования поиска | Малое количество операций ввода-вывода в секунду | Неприменимо. |
| База данных отчетов аналитики | Среднее количество операций ввода-вывода в секунду | Неприменимо. |
Выбор способа поддержки высокой доступности архитектурой поиска
Если вы не знакомы со стратегиями обеспечения высокого уровня доступности, ознакомьтесь со статьей, которая поможет вам приступить к работе: Создание архитектуры и стратегии высокого уровня доступности для SharePoint Server. Если вы размещаете избыточные компоненты поиска и базы данных в отдельных доменах сбоя, сбой в одной части фермы не приводит к отключению полной службы. Но производительность поиска снизится, так как компоненты поиска больше не смогут совместно использовать нагрузку. Чтобы снизить вероятность потери одного сервера, рекомендуется улучшить локальную избыточность. Для каждого хост-сервера в архитектуре поиска выполните следующие действия.
Используйте хранилище RAID на каждом сервере.
Установите несколько избыточных сетевых подключений на каждом сервере.
Установите несколько избыточных источников питания с независимой разводкой или источники бесперебойного питания для каждого сервера.
Все примеры архитектур поиска размещают избыточные компоненты поиска на независимых серверах. В этих примерах самый правый узел в каждой паре является резервным. Вот архитектура большого поиска с выделенными избыточными узлами: