Criação de perfil de chamadas à API do Direct3D com precisão (Direct3D 9)
- A criação de perfil do Direct3D com precisão é difícil
- Como criar um perfil preciso de uma sequência de renderização do Direct3D
- Alterações de estado do Direct3D de criação de perfil
- Resumo
- Apêndice
Depois de ter um aplicativo Microsoft Direct3D funcional e quiser melhorar seu desempenho, você geralmente usa uma ferramenta de criação de perfil fora da prateleira ou alguma técnica de medida personalizada para medir o tempo necessário para executar uma ou mais chamadas de API (interface de programação de aplicativo). Se você fez isso, mas está obtendo resultados de tempo que variam de uma sequência de renderização para a próxima, ou você está fazendo hipóteses que não se apegam aos resultados reais do experimento, as informações a seguir podem ajudá-lo a entender o porquê.
As informações fornecidas aqui baseiam-se na suposição de que você tem conhecimento e experiência com o seguinte:
- Programação C/C++
- Programação de API do Direct3D
- Medindo o tempo da API
- O vídeo cartão e seu driver de software
- Possíveis resultados inexplicáveis da experiência de criação de perfil anterior
A criação de perfil do Direct3D com precisão é difícil
Um criador de perfil relata a quantidade de tempo gasto em cada chamada à API. Isso é feito para melhorar o desempenho encontrando e ajustando pontos quentes. Há diferentes tipos de profilers e técnicas de criação de perfil.
- Um criador de perfil de amostragem fica ocioso a maior parte do tempo, despertando em intervalos específicos para amostrar (ou registrar) as funções que estão sendo executadas. Ele retorna o percentual de tempo gasto em cada chamada. Em geral, um criador de perfil de amostragem não é muito invasivo ao aplicativo e tem um impacto mínimo na sobrecarga do aplicativo.
- Um criador de perfil de instrumentação mede o tempo real necessário para que uma chamada seja retornada. Ele requer a compilação de delimitadores de início e parada em um aplicativo. Um criador de perfil de instrumentação é comparativamente mais invasivo a um aplicativo do que um criador de perfil de amostragem.
- Também é possível usar uma técnica de criação de perfil personalizada com um temporizador de alto desempenho. Isso produz resultados muito parecidos com um criador de perfil de instrumentação.
O tipo de criador de perfil ou técnica de criação de perfil usada é apenas parte do desafio de gerar medidas precisas.
A criação de perfil oferece respostas que ajudam você a orçar o desempenho. Por exemplo, suponha que você saiba que uma chamada à API tem uma média de mil ciclos de relógio a serem executados. Você pode afirmar algumas conclusões sobre o desempenho, como o seguinte:
- Uma CPU de 2 GHz (que gasta 50% de seu tempo de renderização) está limitada a chamar essa API 1 milhão de vezes por segundo.
- Para atingir 30 quadros por segundo, você não pode chamar essa API mais de 33.000 vezes por quadro.
- Você só pode renderizar objetos de 3,3 mil por quadro (supondo que 10 dessas chamadas à API para a sequência de renderização de cada objeto).
Em outras palavras, se você tiver tempo suficiente por chamada à API, poderá responder a uma pergunta de orçamento, como o número de primitivos que podem ser renderizados interativamente. Mas os números brutos retornados por um criador de perfil de instrumentação não responderão com precisão às perguntas de orçamento. Isso ocorre porque o pipeline de gráficos tem problemas de design complexos, como o número de componentes que precisam funcionar, o número de processadores que controlam como o trabalho flui entre componentes e estratégias de otimização implementadas no runtime e em um driver projetado para tornar o pipeline mais eficiente.
Cada chamada à API passa por vários componentes
Cada chamada é processada por vários componentes no caminho do aplicativo para o vídeo cartão. Por exemplo, considere a seguinte sequência de renderização que contém duas chamadas para desenhar um único triângulo:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
O diagrama conceitual a seguir mostra os diferentes componentes pelos quais as chamadas devem passar.

O aplicativo invoca o Direct3D, que controla a cena, manipula as interações do usuário e determina como a renderização é feita. Todo esse trabalho é especificado na sequência de renderização, que é enviada para o runtime usando chamadas à API Direct3D. A sequência de renderização é virtualmente independente de hardware (ou seja, as chamadas à API são independentes de hardware, mas um aplicativo tem conhecimento de quais recursos um vídeo cartão dá suporte).
O runtime converte essas chamadas em um formato independente do dispositivo. O runtime manipula toda a comunicação entre o aplicativo e o driver, de modo que um aplicativo seja executado em mais de uma parte compatível do hardware (dependendo dos recursos necessários). Ao medir uma chamada de função, um criador de perfil de instrumentação mede o tempo gasto em uma função, bem como o tempo para a função retornar. Uma limitação de um criador de perfil de instrumentação é que ele pode não incluir o tempo necessário para um driver enviar o trabalho resultante para o vídeo cartão nem o tempo para o vídeo cartão processar o trabalho. Em outras palavras, um criador de perfil de instrumentação fora da prateleira falha ao atribuir todo o trabalho associado a cada chamada de função.
O driver de software usa conhecimento específico de hardware sobre o cartão de vídeo para converter os comandos independentes do dispositivo em uma sequência de comandos de cartão de vídeo. Os drivers também podem otimizar a sequência de comandos enviados para o vídeo cartão, de modo que a renderização no vídeo cartão seja feita com eficiência. Essas otimizações podem causar problemas de criação de perfil porque a quantidade de trabalho feito não é o que parece ser (talvez seja necessário entender as otimizações para contabilizá-las). O driver normalmente retorna o controle para o runtime antes que o cartão de vídeo termine de processar todos os comandos.
O vídeo cartão executa a maior parte da renderização combinando dados dos buffers de vértice e índice, texturas, informações de estado de renderização e os comandos gráficos. Quando o vídeo cartão termina a renderização, o trabalho criado a partir da sequência de renderização é concluído.
Cada chamada à API direct3D deve ser processada por cada componente (o runtime, o driver e o vídeo cartão) para renderizar qualquer coisa.
Há mais de um processador controlando os componentes
A relação entre esses componentes é ainda mais complexa, pois o aplicativo, o runtime e o driver são controlados por um processador e a cartão de vídeo é controlada por um processador separado. O diagrama a seguir mostra dois tipos de processadores: uma CPU (unidade de processamento central) e uma GPU (unidade de processamento gráfico).
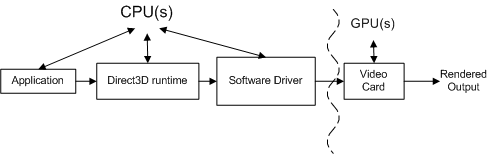
Os sistemas de computador têm pelo menos uma CPU e uma GPU, mas podem ter mais de uma ou ambas. As CPUs estão localizadas na placa-mãe e as GPUs estão localizadas na placa-mãe ou no vídeo cartão. A velocidade da CPU é determinada por um chip de relógio na placa-mãe e a velocidade da GPU é determinada por um chip de relógio separado. O relógio da CPU controla a velocidade do trabalho feito pelo aplicativo, pelo runtime e pelo driver. O aplicativo envia trabalho para a GPU por meio do runtime e do driver.
A CPU e a GPU geralmente são executadas em velocidades diferentes, independentemente umas das outras. A GPU pode responder ao trabalho assim que o trabalho estiver disponível (supondo que a GPU tenha terminado de processar o trabalho anterior). O trabalho de GPU é feito em paralelo com o trabalho da CPU, conforme realçado pela linha curva na figura acima. Um criador de perfil geralmente mede o desempenho da CPU, não da GPU. Isso torna a criação de perfil desafiadora, pois as medidas feitas por um criador de perfil de instrumentação incluem o tempo de CPU, mas podem não incluir o tempo de GPU.
A finalidade da GPU é remover o processamento de carga da CPU para um processador especificamente projetado para o trabalho gráfico. Em placas de vídeo modernas, a GPU substitui grande parte do trabalho de transformação e iluminação no pipeline da CPU para a GPU. Isso reduz muito a carga de trabalho da CPU, deixando mais ciclos de CPU disponíveis para outro processamento. Para ajustar um aplicativo gráfico para o desempenho de pico, você precisa medir o desempenho da CPU e da GPU e equilibrar o trabalho entre os dois tipos de processadores.
Este documento não aborda tópicos relacionados à medição do desempenho da GPU nem ao balanceamento do trabalho entre a CPU e a GPU. Se você quiser entender melhor o desempenho de uma GPU (ou um vídeo específico cartão), visite o site do fornecedor para procurar mais informações sobre o desempenho da GPU. Em vez disso, este documento se concentra no trabalho feito pelo runtime e pelo driver, reduzindo o trabalho de GPU para um valor insignificante. Isso é, em parte, baseado na experiência de que os aplicativos que enfrentam problemas de desempenho geralmente são limitados pela CPU.
Otimizações de runtime e driver podem mascarar medidas de API
O runtime tem uma otimização de desempenho interna que pode sobrecarregar a medida de uma chamada individual. Aqui está um cenário de exemplo que demonstra esse problema. Considere a seguinte sequência de renderização:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Exemplo 1: sequência de renderização simples
Examinando os resultados das duas chamadas na sequência de renderização, um criador de perfil de instrumentação pode retornar resultados semelhantes a estes:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
O criador de perfil retorna o número de ciclos de CPU necessários para processar o trabalho associado a cada chamada (lembre-se de que a GPU não está incluída nesses números porque a GPU ainda não começou a trabalhar nesses comandos). Como IDirect3DDevice9::D rawPrimitive exigiu quase um milhão de ciclos para processar, você pode concluir que ele não é muito eficiente. No entanto, você verá em breve por que essa conclusão está incorreta e como você pode gerar resultados que podem ser usados para orçamento.
Medir alterações de estado requer sequências de renderização cuidadosas
Todas as chamadas diferentes de IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive ou Clear (como SetTexture, SetVertexDeclaration e SetRenderState) produzem uma alteração de estado. Cada alteração de estado define o estado do pipeline que controla como a renderização será feita.
As otimizações no runtime e/ou no driver foram projetadas para acelerar a renderização reduzindo a quantidade de trabalho necessária. Veja a seguir algumas otimizações de alteração de estado que podem poluir as médias de perfil:
- Um driver (ou o runtime) pode salvar uma alteração de estado como um estado local. Como o driver pode operar em um algoritmo "lento" (adiando o trabalho até que seja absolutamente necessário), o trabalho associado a algumas alterações de estado pode ficar atrasado.
- O runtime (ou um driver) pode remover alterações de estado otimizando. Um exemplo disso pode ser remover uma alteração de estado redundante que desabilita a iluminação porque a iluminação foi desabilitada anteriormente.
Não há nenhuma maneira tola de examinar uma sequência de renderização e concluir quais alterações de estado definirão um bit sujo e adiarão o trabalho ou simplesmente serão removidas pela otimização. Mesmo que você possa identificar as alterações de estado otimizadas no runtime ou no driver de hoje, o runtime ou o driver de amanhã provavelmente será atualizado. Você também não sabe prontamente qual era o estado anterior, portanto, é difícil identificar alterações de estado redundantes. A única maneira de verificar o custo de uma alteração de estado é medir a sequência de renderização que inclui as alterações de estado.
Como você pode ver, as complicações causadas por vários processadores, comandos sendo processados por mais de um componente e otimizações incorporadas aos componentes dificultam a previsão da criação de perfil. Na próxima seção, cada um desses desafios de criação de perfil será abordado. Sequências de renderização direct3D de exemplo serão mostradas, com as técnicas de medição que acompanham. Com esse conhecimento, você poderá gerar medidas precisas e repetíveis em chamadas individuais.
Como criar um perfil preciso de uma sequência de renderização do Direct3D
Agora que alguns dos desafios de criação de perfil foram realçados, esta seção mostrará técnicas que ajudarão você a gerar medidas de perfil que podem ser usadas para orçamento. Medidas de criação de perfil precisas e repetíveis são possíveis se você entender a relação entre os componentes controlados pela CPU e como evitar otimizações de desempenho implementadas pelo runtime e pelo driver.
Para começar, você precisa ser capaz de medir com precisão o tempo de execução de uma única chamada à API.
Escolher uma ferramenta de medida precisa como QueryPerformanceCounter
O sistema operacional Microsoft Windows inclui um temporizador de alta resolução que pode ser usado para medir tempos decorridos de alta resolução. O valor atual de um desses temporizadores pode ser retornado usando QueryPerformanceCounter. Depois de invocar QueryPerformanceCounter para retornar valores de início e parada, a diferença entre os dois valores pode ser convertida no tempo decorrido real (em segundos) usando QueryPerformanceCounter.
As vantagens de usar QueryPerformanceCounter são que ele está disponível no Windows e é fácil de usar. Basta cercar as chamadas com uma chamada QueryPerformanceCounter e salvar os valores de inicialização e parada. Portanto, este artigo demonstrará como usar QueryPerformanceCounter para criar um perfil de tempos de execução, semelhante à maneira como um criador de perfil de instrumentação o mediria. Aqui está um exemplo que mostra como inserir QueryPerformanceCounter em seu código-fonte:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Exemplo 2: Implementação de criação de perfil personalizada com QPC
start e stop são dois inteiros grandes que manterão os valores de início e parada retornados pelo temporizador de alto desempenho. Observe que QueryPerformanceCounter(&start) é chamado pouco antes de SetTexture e QueryPerformanceCounter(&stop) ser chamado logo após DrawPrimitive. Depois de obter o valor de parada, QueryPerformanceFrequency é chamado para retornar freq, que é a frequência do temporizador de alta resolução. Neste exemplo hipotético, suponha que você obtenha os seguintes resultados para iniciar, parar e freq:
| Variável Local | Número de tiques |
|---|---|
| iniciar | 1792998845094 |
| parar | 1792998845102 |
| Freq | 3579545 |
Você pode converter esses valores no número de ciclos necessários para executar as chamadas à API desta forma:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
Em outras palavras, são necessários cerca de 4568 ciclos de relógio para processar SetTexture e DrawPrimitive neste computador de 2 GHz. Você pode converter esses valores no tempo real necessário para executar todas as chamadas como esta:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
O uso de QueryPerformanceCounter exige que você adicione medidas de início e parada à sequência de renderização e use QueryPerformanceFrequency para converter a diferença (número de tiques) no número de ciclos de CPU ou em tempo real. Identificar a técnica de medida é um bom começo para desenvolver uma implementação de criação de perfil personalizada. Mas antes de começar a fazer medidas, você precisa saber como lidar com o vídeo cartão.
Foco em medidas de CPU
Conforme indicado anteriormente, a CPU e a GPU funcionam em paralelo para processar o trabalho gerado pelas chamadas à API. Um aplicativo do mundo real requer a criação de perfil de ambos os tipos de processadores para descobrir se seu aplicativo é limitado por CPU ou com GPU limitada. Como o desempenho da GPU é específico do fornecedor, seria muito desafiador produzir resultados neste artigo que abrangem a variedade de placas de vídeo disponíveis.
Em vez disso, este artigo se concentrará apenas na criação de perfil do trabalho executado pela CPU usando uma técnica personalizada para medir o runtime e o trabalho do driver. O trabalho de GPU será reduzido a uma quantidade insignificante, para que os resultados da CPU sejam mais visíveis. Um benefício dessa abordagem é que essa técnica produz resultados no Apêndice que você deve ser capaz de correlacionar com suas medidas. Para reduzir o trabalho exigido pelo vídeo cartão a um nível insignificante, basta reduzir o trabalho de renderização para a menor quantidade possível. Isso pode ser feito limitando as chamadas de desenho para renderizar um único triângulo e pode ser restringido ainda mais para que cada triângulo contenha apenas um pixel.
A unidade de medida usada neste artigo para medir o trabalho da CPU será o número de ciclos de relógio da CPU em vez do tempo real. Os ciclos de relógio da CPU têm a vantagem de que ele é mais portátil (para aplicativos limitados por CPU) do que o tempo decorrido real entre computadores com diferentes velocidades de CPU. Isso pode ser convertido facilmente em tempo real, se desejado.
Este documento não aborda tópicos relacionados ao balanceamento da carga de trabalho entre a CPU e a GPU. Lembre-se de que o objetivo deste artigo não é medir o desempenho geral de um aplicativo, mas mostrar como medir com precisão o tempo de execução e o driver para processar chamadas à API. Com essas medidas precisas, você pode assumir a tarefa de orçar a CPU para entender determinados cenários de desempenho.
Controlando otimizações de runtime e driver
Com uma técnica de medida identificada e uma estratégia para reduzir o trabalho de GPU, a próxima etapa é entender as otimizações de runtime e driver que atrapalham a criação de perfil.
O trabalho da CPU pode ser dividido em três buckets: o trabalho do aplicativo, o trabalho de runtime e o trabalho do driver. Ignore o trabalho do aplicativo, pois isso está sob controle do programador. Do ponto de vista do aplicativo, o runtime e o driver são como caixas pretas, pois o aplicativo não tem controle sobre o que é implementado neles. A chave é entender as técnicas de otimização que podem ser implementadas no runtime e no driver. Se você não entende essas otimizações, é muito fácil chegar à conclusão errada sobre a quantidade de trabalho que a CPU está fazendo com base nas medidas de perfil. Em particular, há dois tópicos relacionados a algo chamado buffer de comando e o que ele pode fazer para ofuscar a criação de perfil. Esses tópicos são:
- Otimização de runtime com o Buffer de Comando. O buffer de comando é uma otimização de runtime que reduz o impacto de uma transição de modo. Para controlar o tempo da transição de modo, consulte Controlando o buffer de comando.
- Negando os efeitos de tempo do Buffer de Comando. O tempo decorrido de uma transição de modo pode ter um grande impacto nas medidas de criação de perfil. A estratégia para isso é tornar a sequência de renderização grande em comparação com a transição de modo.
Controlando o buffer de comando
Quando um aplicativo faz uma chamada à API, o runtime converte a chamada à API em um formato independente do dispositivo (que chamaremos de comando) e a armazena no buffer de comando. O buffer de comando é adicionado ao diagrama a seguir.
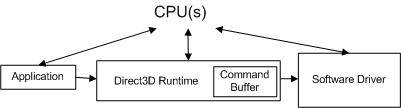
Sempre que o aplicativo faz outra chamada à API, o runtime repete essa sequência e adiciona outro comando ao buffer de comando. Em algum momento, o runtime esvazia o buffer (enviando os comandos para o driver). No Windows XP, esvaziar o buffer de comando causa uma transição de modo à medida que o sistema operacional alterna do runtime (em execução no modo de usuário) para o driver (em execução no modo kernel), conforme mostrado no diagrama a seguir.
- modo de usuário – o modo de processador não privilegiado que executa o código do aplicativo. Os aplicativos no modo de usuário não podem obter acesso aos dados do sistema, exceto por meio de serviços do sistema.
- modo kernel – o modo de processador privilegiado no qual o código executivo baseado no Windows é executado. Um driver ou thread em execução no modo kernel tem acesso a toda a memória do sistema, acesso direto ao hardware e instruções de CPU para executar E/S com o hardware.
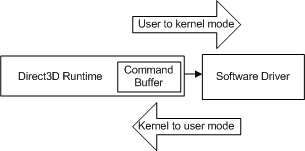
A transição ocorre sempre que a CPU alterna de usuário para modo kernel (e vice-versa) e o número de ciclos necessários é grande em comparação com uma chamada de API individual. Se o runtime enviasse cada chamada à API para o driver quando ela foi invocada, cada chamada à API incorreria no custo de uma transição de modo.
Em vez disso, o buffer de comando é uma otimização de runtime projetada para reduzir o custo efetivo da transição de modo. O buffer de comando enfileira muitos comandos de driver em preparação para uma transição de modo único. Quando o runtime adiciona um comando ao buffer de comando, o controle é retornado ao aplicativo. Um criador de perfil não tem como saber que os comandos do driver provavelmente ainda não foram enviados ao driver. Como resultado, os números retornados por um criador de perfil de instrumentação fora da prateleira são enganosos, pois medem o trabalho de runtime, mas não o trabalho do driver associado.
Resultados do perfil sem uma transição de modo
Usando a sequência de renderização do exemplo 2, aqui estão algumas medidas de tempo típicas que ilustram a magnitude de uma transição de modo. Supondo que as chamadas SetTexture e DrawPrimitive não causem uma transição de modo, um criador de perfil de instrumentação fora da prateleira pode retornar resultados semelhantes a estes:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Cada um desses números é o tempo necessário para que o runtime adicione essas chamadas ao buffer de comando. Como não há transição de modo, o driver ainda não fez nenhum trabalho. Os resultados do criador de perfil são precisos, mas não medem todo o trabalho que a sequência de renderização eventualmente fará com que a CPU execute.
Resultados do perfil com uma transição de modo
Agora, veja o que acontece para o mesmo exemplo quando ocorre uma transição de modo. Desta vez, suponha que SetTexture e DrawPrimitive causem uma transição de modo. Mais uma vez, um criador de perfil de instrumentação fora da prateleira pode retornar resultados semelhantes a estes:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
O tempo medido para SetTexture é quase o mesmo, no entanto, o aumento dramático na quantidade de tempo gasto em DrawPrimitive é devido à transição de modo. Veja o que está acontecendo:
- Suponha que o buffer de comando tenha espaço para um comando antes do início da sequência de renderização.
- SetTexture é convertido em um formato independente de dispositivo e adicionado ao buffer de comando. Nesse cenário, essa chamada preenche o buffer de comando.
- O runtime tenta adicionar DrawPrimitive ao buffer de comando, mas não pode, pois está cheio. Em vez disso, o runtime esvazia o buffer de comando. Isso causa a transição do modo kernel. Suponha que a transição leve cerca de 5.000 ciclos. Esse tempo contribui para o tempo gasto em DrawPrimitive.
- Em seguida, o driver processa o trabalho associado a todos os comandos que foram esvaziados do buffer de comando. Suponha que o tempo de driver para processar os comandos que quase preencheram o buffer de comando é de cerca de 935.000 ciclos. Suponha que o trabalho do driver associado a SetTexture seja de cerca de 2750 ciclos. Esse tempo contribui para o tempo gasto em DrawPrimitive.
- Quando o driver conclui seu trabalho, a transição do modo de usuário retorna o controle para o runtime. O buffer de comando agora está vazio. Suponha que a transição leve cerca de 5.000 ciclos.
- A sequência de renderização termina convertendo DrawPrimitive e adicionando-a ao buffer de comando. Suponha que isso leve cerca de 900 ciclos. Esse tempo contribui para o tempo gasto em DrawPrimitive.
Resumindo os resultados, você verá:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Assim como a medida de DrawPrimitive sem a transição de modo (900 ciclos), a medida de DrawPrimitive com a transição de modo (947.950 ciclos) é precisa, mas inútil em termos de trabalho de CPU de orçamento. O resultado contém o trabalho de runtime correto, o trabalho do driver para SetTexture, o driver funciona para quaisquer comandos que precederam SetTexture e duas transições de modo. No entanto, a medida não tem o trabalho do driver DrawPrimitive .
Uma transição de modo pode ocorrer em resposta a qualquer chamada. Depende do que estava anteriormente no buffer de comando. Você precisa controlar a transição de modo para entender quanto trabalho de CPU (runtime e driver) está associado a cada chamada. Para fazer isso, você precisa de um mecanismo para controlar o buffer de comando e o tempo da transição de modo.
O mecanismo de consulta
O mecanismo de consulta no Microsoft Direct3D 9 foi projetado para permitir que o runtime consulte a GPU para progresso e retorne determinados dados da GPU. Durante a criação de perfil, se o trabalho de GPU for minimizado para que ele tenha um impacto insignificante no desempenho, você poderá retornar status da GPU para ajudar a medir o trabalho do driver. Afinal, o trabalho do driver é concluído quando a GPU vê os comandos do driver. Além disso, o mecanismo de consulta pode ser persuadido a controlar duas características de buffer de comando que são importantes para a criação de perfil: quando o buffer de comando esvazia e quanto trabalho está no buffer.
Esta é a mesma sequência de renderização usando o mecanismo de consulta:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Exemplo 3: usando uma consulta para controlar o buffer de comando
Aqui está uma explicação mais detalhada de cada uma dessas linhas de código:
- Crie uma consulta de evento criando um objeto de consulta com D3DQUERYTYPE_EVENT.
- Adicione um marcador de evento de consulta ao buffer de comando chamando Issue(D3DISSUE_END). Esse marcador instrui o driver a acompanhar quando a GPU terminar de executar quaisquer comandos anteriores ao marcador.
- A primeira chamada esvazia o buffer de comando porque chamar GetData com D3DGETDATA_FLUSH força o buffer de comando a ser esvaziado. Cada chamada subsequente está verificando a GPU para ver quando ela termina de processar todo o trabalho de buffer de comando. Esse loop não retorna S_OK até que a GPU esteja ociosa.
- Exemplo da hora de início.
- Invoque as chamadas à API que estão sendo perfiladas.
- Adicione um segundo marcador de evento de consulta ao buffer de comando. Esse marcador será usado para acompanhar a conclusão das chamadas.
- A primeira chamada esvazia o buffer de comando porque chamar GetData com D3DGETDATA_FLUSH força o buffer de comando a ser esvaziado. Quando a GPU termina de processar todo o trabalho de buffer de comando, GetData retorna S_OK e o loop é encerrado porque a GPU está ociosa.
- Exemplo do tempo de parada.
Aqui estão os resultados medidos com QueryPerformanceCounter e QueryPerformanceFrequency:
| Variável Local | Número de tiques |
|---|---|
| iniciar | 1792998845060 |
| parar | 1792998845090 |
| Freq | 3579545 |
Convertendo tiques em ciclos mais uma vez (em um computador de 2 GHz):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Aqui está o detalhamento do número de ciclos por chamada:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
O mecanismo de consulta nos permitiu controlar o runtime e o trabalho do driver que está sendo medido. Para entender cada um desses números, veja o que está acontecendo em resposta a cada uma das chamadas à API, juntamente com os intervalos estimados:
A primeira chamada esvazia o buffer de comando chamando GetData com D3DGETDATA_FLUSH. Quando a GPU termina de processar todo o trabalho de buffer de comando, GetData retorna S_OK e o loop é encerrado porque a GPU está ociosa.
A sequência de renderização começa convertendo SetTexture em um formato independente do dispositivo e adicionando-a ao buffer de comando. Suponha que isso leve cerca de 100 ciclos.
DrawPrimitive é convertido e adicionado ao buffer de comando. Suponha que isso leve cerca de 900 ciclos.
O problema adiciona um marcador de consulta ao buffer de comando. Suponha que isso leve cerca de 200 ciclos.
GetData faz com que o buffer de comando seja esvaziado, o que força a transição do modo kernel. Suponha que isso leve cerca de 5.000 ciclos.
Em seguida, o driver processa o trabalho associado a todas as quatro chamadas. Suponha que o tempo de driver para processar SetTexture é de cerca de 2964 ciclos, DrawPrimitive é de cerca de 3600 ciclos, Problema é de cerca de 200 ciclos. Portanto, o tempo total do driver para todos os quatro comandos é de cerca de 6450 ciclos.
Observação
O driver também leva um pouco de tempo para ver qual é o status da GPU. Como o trabalho de GPU é trivial, a GPU já deve ser feita. GetData retornará S_OK com base na probabilidade de a GPU ter sido concluída.
Quando o driver conclui seu trabalho, a transição do modo de usuário retorna o controle para o runtime. O buffer de comando agora está vazio. Suponha que isso leve cerca de 5.000 ciclos.
Os números de GetData incluem:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
O mecanismo de consulta usado em combinação com QueryPerformanceCounter mede todo o trabalho da CPU. Isso é feito com uma combinação de marcadores de consulta e comparações de status de consulta. Os marcadores de consulta iniciais e interrompidos adicionados ao buffer de comando são usados para controlar a quantidade de trabalho no buffer. Ao aguardar até que o código de retorno correto seja retornado, a medida de início é feita pouco antes de uma sequência de renderização limpo ser iniciada e a medida de parada é feita logo após o driver concluir o trabalho associado ao conteúdo do buffer de comando. Isso captura efetivamente o trabalho de CPU feito pelo runtime, bem como pelo driver.
Agora que você sabe sobre o buffer de comando e o efeito que ele pode ter na criação de perfil, você deve saber que há algumas outras condições que podem fazer com que o runtime esvazie o buffer de comando. Você precisa watch para eles em suas sequências de renderização. Algumas dessas condições são em resposta a chamadas à API, outras são em resposta a alterações de recursos no runtime. Qualquer uma das seguintes condições causará uma transição de modo:
- Quando um dos métodos de bloqueio (Lock) é chamado em um buffer de vértice, buffer de índice ou textura (em determinadas condições com determinados sinalizadores).
- Quando um dispositivo ou buffer de vértice, buffer de índice ou textura é criado.
- Quando um dispositivo ou buffer de vértice, buffer de índice ou textura é destruído pela última versão.
- Quando ValidateDevice é chamado.
- Quando Presente é chamado.
- Quando o buffer de comando é preenchido.
- Quando GetData é chamado com D3DGETDATA_FLUSH.
Tenha cuidado para watch para essas condições em suas sequências de renderização. Sempre que uma transição de modo for adicionada, 10.000 ciclos de trabalho do driver serão adicionados às medidas de criação de perfil. Além disso, o buffer de comando não é dimensionado estaticamente. O runtime pode alterar o tamanho do buffer em resposta à quantidade de trabalho que está sendo gerada pelo aplicativo. Essa é mais uma otimização que depende de uma sequência de renderização.
Portanto, tenha cuidado para controlar as transições de modo durante a criação de perfil. O mecanismo de consulta oferece um método robusto para esvaziar o buffer de comando para que você possa controlar o tempo da transição de modo, bem como a quantidade de trabalho que o buffer contém. No entanto, mesmo essa técnica pode ser aprimorada reduzindo o tempo de transição do modo para torná-la insignificante em relação ao resultado medido.
Tornar a sequência de renderização grande em comparação com a transição de modo
No exemplo anterior, a opção de modo kernel e o comutador de modo de usuário consomem cerca de 10.000 ciclos que não têm nada a ver com o runtime e o trabalho do driver. Como a transição de modo é incorporada ao sistema operacional, ela não pode ser reduzida a zero. Para tornar a transição de modo insignificante, a sequência de renderização precisa ser ajustada para que o driver e o trabalho de runtime sejam uma ordem de magnitude maior do que as opções de modo. Você pode tentar fazer uma subtração para remover as transições, mas amortizar o custo em um custo de sequência de renderização muito maior é mais confiável.
A estratégia para reduzir a transição de modo até que ela se torne insignificante é adicionar um loop à sequência de renderização. Por exemplo, vamos examinar os resultados da criação de perfil se um loop for adicionado que repetirá a sequência de renderização 1500 vezes:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Exemplo 4: Adicionar um loop à sequência de renderização
Aqui estão os resultados medidos com QueryPerformanceCounter e QueryPerformanceFrequency:
| Variável Local | Número de Tics |
|---|---|
| iniciar | 1792998845000 |
| parar | 1792998847084 |
| Freq | 3579545 |
O uso de QueryPerformanceCounter mede 2.840 tiques agora. Converter tiques em ciclos é o mesmo que já mostramos:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
Em outras palavras, são necessários cerca de 6,9 milhões de ciclos neste computador de 2 GHz para processar as 1500 chamadas no loop de renderização. Dos 6,9 milhões de ciclos, a quantidade de tempo nas transições de modo é de aproximadamente 10 mil, portanto, agora os resultados do perfil estão quase inteiramente medindo o trabalho associado a SetTexture e DrawPrimitive.
Observe que o exemplo de código requer uma matriz de duas texturas. Para evitar uma otimização de runtime que removeria SetTexture se ele define o mesmo ponteiro de textura sempre que for chamado, basta usar uma matriz de duas texturas. Dessa forma, cada vez por meio do loop, o ponteiro de textura é alterado e o trabalho completo associado a SetTexture é executado. Certifique-se de que ambas as texturas sejam do mesmo tamanho e formato, para que nenhum outro estado seja alterado quando a textura mudar.
E agora você tem uma técnica para criação de perfil do Direct3D. Ele depende do contador de alto desempenho (QueryPerformanceCounter) para registrar o número de tiques que leva a CPU para processar o trabalho. O trabalho é cuidadosamente controlado para ser o runtime e o trabalho do driver associado a chamadas à API usando o mecanismo de consulta. Uma consulta fornece dois meios de controle: primeiro para esvaziar o buffer de comando antes do início da sequência de renderização e, em segundo lugar, para retornar quando o trabalho de GPU for concluído.
Até agora, este artigo mostrou como criar o perfil de uma sequência de renderização. Cada sequência de renderização tem sido bastante simples, contendo uma única chamada DrawPrimitive e uma chamada SetTexture . Isso foi feito para se concentrar no buffer de comando e no uso do mecanismo de consulta para controlá-lo. Aqui está um breve resumo de como criar o perfil de uma sequência de renderização arbitrária:
- Use um contador de alto desempenho como QueryPerformanceCounter para medir o tempo necessário para processar cada chamada à API. Use QueryPerformanceFrequency e a taxa de relógio da CPU para convertê-lo no número de ciclos de CPU por chamada à API.
- Minimize a quantidade de trabalho de GPU renderizando listas de triângulos, em que cada triângulo contém um pixel.
- Use o mecanismo de consulta para esvaziar o buffer de comando antes da sequência de renderização. Isso garante que a criação de perfil capturará a quantidade correta de trabalho de runtime e driver associado à sequência de renderização.
- Controle a quantidade de trabalho adicionada ao buffer de comandos com marcadores de evento de consulta. Essa mesma consulta detecta quando a GPU conclui seu trabalho. Como o trabalho de GPU é trivial, isso é praticamente equivalente a medir quando o trabalho do driver é concluído.
Todas essas técnicas são usadas para criar o perfil de alterações de estado. Supondo que você leu e entendeu como controlar o buffer de comando e concluiu com êxito as medições de linha de base em DrawPrimitive, você está pronto para adicionar alterações de estado às suas sequências de renderização. Há alguns desafios adicionais de criação de perfil ao adicionar alterações de estado a uma sequência de renderização. Se você pretende adicionar alterações de estado às sequências de renderização, continue na próxima seção.
Criação de perfil de alterações de estado do Direct3D
O Direct3D usa muitos estados de renderização para controlar quase todos os aspectos do pipeline. As APIs que causam alterações de estado incluem qualquer função ou método diferente das chamadas Draw*Primitive.
As alterações de estado são complicadas porque talvez você não consiga ver o custo de uma alteração de estado sem renderização. Isso é resultado do algoritmo lento que o driver e a GPU usam para adiar o trabalho até que ele tenha absolutamente que ser feito. Em geral, você deve seguir estas etapas para medir uma única alteração de estado:
- Perfil DrawPrimitive primeiro.
- Adicione uma alteração de estado à sequência de renderização e crie o perfil da nova sequência.
- Subtraia a diferença entre as duas sequências para obter o custo da alteração de estado.
Naturalmente, tudo o que você aprendeu sobre como usar o mecanismo de consulta e colocar a sequência de renderização em um loop para negar o custo da transição de modo ainda se aplica.
Criação de perfil de uma alteração de estado simples
Começando com uma sequência de renderização que contém DrawPrimitive, aqui está a sequência de código para medir o custo da adição de SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Exemplo 5: medindo uma chamada à API de alteração de estado
Observe que o loop contém duas chamadas, SetTexture e DrawPrimitive. A sequência de renderização faz um loop 1500 vezes e gera resultados semelhantes a estes:
| Variável Local | Número de Tics |
|---|---|
| iniciar | 1792998860000 |
| parar | 1792998870260 |
| Freq | 3579545 |
A conversão de tiques em ciclos mais uma vez gera:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Dividir pelo número de iterações no loop gera:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Cada iteração do loop contém uma alteração de estado e uma chamada de desenho. Subtraindo o resultado das folhas da sequência de renderização DrawPrimitive :
3850 - 1100 = 2750 cycles for SetTexture
Esse é o número médio de ciclos para adicionar SetTexture a essa sequência de renderização. Essa mesma técnica pode ser aplicada a outras alterações de estado.
Por que SetTexture é chamado de alteração de estado simples? Como o estado que está sendo definido é restrito para que o pipeline faça a mesma quantidade de trabalho sempre que o estado é alterado. Restringir ambas as texturas para o mesmo tamanho e formato garante a mesma quantidade de trabalho para cada chamada SetTexture .
Criação de perfil de uma alteração de estado que precisa ser alternada
Há outras alterações de estado que fazem com que a quantidade de trabalho executada pelo pipeline gráfico seja alterada para cada iteração do loop de renderização. Por exemplo, se o teste z estiver habilitado, cada cor de pixel atualizará um destino de renderização somente depois que o valor z do novo pixel for testado em relação ao valor z do pixel existente. Se o teste z estiver desabilitado, esse teste por pixel não será feito e a saída será gravada muito mais rapidamente. Habilitar ou desabilitar o estado do teste z altera drasticamente a quantidade de trabalho feito (pela CPU, bem como pela GPU) durante a renderização.
SetRenderState requer um estado de renderização específico e um valor de estado para habilitar ou desabilitar o teste z. O valor de estado específico é avaliado em runtime para determinar quanto trabalho é necessário. É difícil medir essa alteração de estado em um loop de renderização e ainda pré-condicionar o estado do pipeline para que ele mude. A única solução é alternar a alteração de estado durante a sequência de renderização.
Por exemplo, a técnica de criação de perfil precisa ser repetida duas vezes da seguinte maneira:
- Comece criando o perfil da sequência de renderização DrawPrimitive . Chame isso de linha de base.
- Crie o perfil de uma segunda sequência de renderização que alterne a alteração de estado. O loop de sequência de renderização contém:
- Uma alteração de estado para definir o estado em uma condição "false".
- DrawPrimitive , assim como a sequência original.
- Uma alteração de estado para definir o estado em uma condição "true".
- Um segundo DrawPrimitive para forçar a segunda alteração de estado a ser realizada.
- Localize a diferença entre as duas sequências de renderização. Isso é feito:
- Multiplique a sequência DrawPrimitive da linha de base por 2 porque há duas chamadas DrawPrimitive na nova sequência.
- Subtraia o resultado da nova sequência da sequência original.
- Divida o resultado por 2 para obter o custo médio da alteração do estado "false" e "true".
Com a técnica de loop usada na sequência de renderização, o custo da alteração do estado do pipeline precisa ser medido alternando o estado de "true" para uma condição "false" e vice-versa, para cada iteração na sequência de renderização. O significado de "verdadeiro" e "falso" aqui não são literais, isso simplesmente significa que o Estado precisa ser definido em condições opostas. Isso faz com que ambas as alterações de estado sejam medidas durante a criação de perfil. É claro que tudo o que você aprendeu sobre como usar o mecanismo de consulta e colocar a sequência de renderização em um loop para negar o custo da transição de modo ainda se aplica.
Por exemplo, aqui está a sequência de código para medir o custo de ativar ou desativar o teste z:
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Exemplo 5: Medindo uma alteração de estado de alternição
O loop alterna o estado executando duas chamadas SetRenderState . A primeira chamada SetRenderState desabilita o teste z e o segundo SetRenderState habilita o teste z. Cada SetRenderState é seguido por DrawPrimitive para que o trabalho associado à alteração de estado seja processado pelo driver em vez de definir apenas um sujo bit no driver.
Esses números são razoáveis para esta sequência de renderização:
| Variável Local | Número de tiques |
|---|---|
| iniciar | 1792998845000 |
| parar | 1792998861740 |
| Freq | 3579545 |
A conversão de tiques em ciclos mais uma vez gera:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Dividir pelo número de iterações no loop gera:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Cada iteração do loop contém duas alterações de estado e duas chamadas de desenho. Subtraindo as chamadas de desenho (supondo que 1100 ciclos) sai:
6200 - 1100 - 1100 = 4000 cycles for both state changes
Esse é o número médio de ciclos para ambas as alterações de estado, portanto, o tempo médio para cada alteração de estado é:
4000 / 2 = 2000 cycles for each state change
Portanto, o número médio de ciclos para habilitar ou desabilitar o teste z é de 2000 ciclos. Vale a pena observar que QueryPerformanceCounter está medindo z-enable metade do tempo e z-disable metade do tempo. Na verdade, essa técnica mede a média de ambas as alterações de estado. Em outras palavras, você está medindo o tempo para alternar um estado. Usando essa técnica, você não tem como saber se os tempos de habilitação e desabilitação são equivalentes, pois mediu a média de ambos. No entanto, esse é um número razoável a ser usado ao orçar um estado de alternagem como um aplicativo que causa essa alteração de estado só pode fazer isso alternando esse estado.
Agora você pode aplicar essas técnicas e analisar todas as alterações de estado desejadas, certo? Não exatamente. Você ainda precisa ter cuidado com otimizações projetadas para reduzir a quantidade de trabalho que precisa ser feita. Há dois tipos de otimizações que você deve estar ciente ao projetar suas sequências de renderização.
Cuidado com otimizações de alteração de estado
A seção anterior mostra como criar o perfil de ambos os tipos de alterações de estado: uma alteração de estado simples que é restrita para gerar a mesma quantidade de trabalho para cada iteração e uma alteração de estado de alternagem que altera drasticamente a quantidade de trabalho feito. O que acontece se você pegar a sequência de renderização anterior e adicionar outra alteração de estado a ela? Por exemplo, este exemplo usa a sequência de renderização z-enable> e adiciona uma comparação z-func a ela:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
O estado z-func define o nível de comparação ao gravar no buffer z (entre o valor z de um pixel atual com o valor z de um pixel no buffer de profundidade). D3DCMP_NEVER desativa a comparação de teste z enquanto D3DCMP_ALWAYS define a comparação a ser feita sempre que o teste z é feito.
A criação de perfil de qualquer uma dessas alterações de estado em uma sequência de renderização com DrawPrimitive gera resultados semelhantes a estes:
| Alteração de estado único | Número médio de ciclos |
|---|---|
| somente D3DRS_ZENABLE | 2000 |
ou
| Alteração de estado único | Número médio de ciclos |
|---|---|
| somente D3DRS_ZFUNC | 600 |
Mas, se você criar o perfil D3DRS_ZENABLE e D3DRS_ZFUNC na mesma sequência de renderização, poderá ver resultados como estes:
| Ambas as alterações de estado | Número médio de ciclos |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
Você pode esperar que o resultado seja a soma de ciclos de 2000 e 600 (ou 2600) porque o driver está fazendo todo o trabalho associado à configuração de ambos os estados de renderização. Em vez disso, a média é de 2000 ciclos.
Esse resultado reflete uma otimização de alteração de estado implementada no runtime, no driver ou na GPU. Nesse caso, o driver poderia ver o primeiro SetRenderState e definir um estado sujo que adiaria o trabalho até mais tarde. Quando o driver vê o segundo SetRenderState, o mesmo estado de sujo poderia ser definido com redundância e o mesmo trabalho seria adiado mais uma vez. Quando DrawPrimitive é chamado, o trabalho associado ao estado sujo é finalmente processado. O driver executa o trabalho uma vez, o que significa que as duas primeiras alterações de estado são efetivamente consolidadas pelo driver. Da mesma forma, as alterações de terceiro e quarto estado são efetivamente consolidadas pelo driver em uma única alteração de estado quando o segundo DrawPrimitive é chamado. O resultado líquido é que o driver e a GPU processam uma única alteração de estado para cada chamada de desenho.
Este é um bom exemplo de uma otimização de driver dependente de sequência. O driver adiou o trabalho duas vezes definindo um estado de sujo e, em seguida, executou o trabalho uma vez para limpar o estado sujo. Este é um bom exemplo do tipo de melhoria de eficiência que pode ocorrer quando o trabalho é adiado até que seja absolutamente necessário.
Como você sabe quais alterações de estado definem um estado de sujo internamente e, portanto, adiam o trabalho até mais tarde? Somente testando sequências de renderização (ou conversando com gravadores de driver). Os drivers são atualizados e aprimorados periodicamente para que a lista de otimizações não seja estática. Há apenas uma maneira de saber absolutamente o que uma alteração de estado custa em uma determinada sequência de renderização, em um determinado conjunto de hardware; e isso é para medi-lo.
Cuidado com otimizações DrawPrimitive
Além das otimizações de alteração de estado, o runtime tentará otimizar o número de chamadas de desenho que o driver precisa processar. Por exemplo, considere-as de volta para chamadas de desenho de volta para trás:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Exemplo 5a: duas chamadas de desenho
Essa sequência contém duas chamadas de desenho, que o runtime consolidará em uma única chamada equivalente a:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Exemplo 5b: uma única chamada de desenho concatenada
O runtime concatenará essas duas chamadas de desenho específicas em uma única chamada, o que reduz o trabalho do driver em 50%, pois o driver agora só precisará processar uma chamada de desenho.
Em geral, o runtime concatenará duas ou mais chamadas DrawPrimitive consecutivas quando:
- O tipo primitivo é uma lista de triângulos (D3DPT_TRIANGLELIST).
- Cada chamada de DrawPrimitive sucessiva deve referenciar vértices consecutivos dentro do buffer de vértice.
Da mesma forma, as condições certas para concatenar duas ou mais chamadas DrawIndexedPrimitive são:
- O tipo primitivo é uma lista de triângulos (D3DPT_TRIANGLELIST).
- Cada chamada de DrawIndexedPrimitive sucessiva deve fazer referência sequencial a índices consecutivos dentro do buffer de índice.
- Cada chamada de DrawIndexedPrimitive sucessiva deve usar o mesmo valor para BaseVertexIndex.
Para evitar a concatenação durante a criação de perfil, modifique a sequência de renderização para que o tipo primitivo não seja uma lista de triângulos ou modifique a sequência de renderização para que não haja chamadas de desenho back-to-back que usem vértices (ou índices) consecutivos. Mais especificamente, o runtime também concatenará chamadas de desenho que atendam às duas seguintes condições:
- Quando a chamada anterior for DrawPrimitive, se a próxima chamada de desenho:
- usa uma lista de triângulos, AND
- especifica o StartVertex = StartVertex anterior + PrimitiveCount anterior * 3
- Ao usar DrawIndexedPrimitive, se a próxima chamada de desenho:
- usa uma lista de triângulos, AND
- especifica o StartIndex = StartIndex anterior + PrimitiveCount anterior * 3, AND
- especifica o BaseVertexIndex = BaseVertexIndex anterior
Aqui está um exemplo mais sutil de concatenação de chamada de desenho que é fácil de ignorar quando você está criando perfil. Suponha que a sequência de renderização tenha esta aparência:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Exemplo 5c: uma alteração de estado e uma chamada de desenho
O loop itera em 1500 triângulos, definindo uma textura e desenhando cada triângulo. Esse loop de renderização usa aproximadamente 2.750 ciclos para SetTexture e 1100 ciclos para DrawPrimitive , conforme mostrado nas seções anteriores. Você pode intuitivamente esperar que mover SetTexture para fora do loop de renderização reduza a quantidade de trabalho feito pelo driver em 1500 * 2750 ciclos, que é a quantidade de trabalho associada à chamada de SetTexture 1500 vezes. O snippet de código teria esta aparência:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Exemplo 5d: Exemplo 5c com a alteração de estado fora do loop
Mover SetTexture para fora do loop de renderização reduz a quantidade de trabalho associada a SetTexture , pois ele é chamado uma vez em vez de 1500 vezes. Um efeito secundário menos óbvio é que o trabalho para DrawPrimitive também é reduzido de 1500 chamadas para 1 chamada porque todas as condições para concatenar chamadas de desenho são atendidas. Quando a sequência de renderização for processada, o runtime processará 1500 chamadas em uma única chamada de driver. Ao mover essa linha de código, a quantidade de trabalho do driver foi reduzida drasticamente:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Esses resultados estão totalmente corretos, mas são muito enganosos no contexto da pergunta original. A otimização de chamada de desenho fez com que a quantidade de trabalho do driver fosse drasticamente reduzida. Esse é um problema comum ao fazer a criação de perfil personalizada. Ao eliminar chamadas de uma sequência de renderização, tenha cuidado para evitar a concatenação de chamadas de desenho. Na verdade, esse cenário é um exemplo poderoso da quantidade de melhoria no desempenho do driver possível por essa otimização de runtime.
Agora você sabe como medir as alterações de estado. Comece criando perfil de DrawPrimitive. Em seguida, adicione cada alteração de estado adicional à sequência (em alguns casos, adicionando uma chamada e, em outros casos, adicionando duas chamadas) e meça a diferença entre as duas sequências. Você pode converter os resultados em tiques, ciclos ou tempo. Assim como medir sequências de renderização com QueryPerformanceCounter, medir alterações de estado individuais depende do mecanismo de consulta para controlar o buffer de comando e colocar as alterações de estado em um loop para minimizar o impacto das transições de modo. Essa técnica mede o custo de alternar um estado, pois o criador de perfil retorna a média de habilitar e desabilitar o estado.
Com essa funcionalidade, você pode começar a gerar sequências de renderização arbitrárias e medir com precisão o runtime e o trabalho do driver associados. Em seguida, os números podem ser usados para responder a perguntas de orçamento, como "quantas mais dessas chamadas" podem ser feitas na sequência de renderização, mantendo uma taxa de quadros razoável, assumindo cenários limitados por CPU.
Resumo
Este documento demonstra como controlar o buffer de comando para que chamadas individuais possam ser criadas com precisão. Os números de criação de perfil podem ser gerados em tiques, ciclos ou tempo absoluto. Eles representam a quantidade de runtime e trabalho de driver associado a cada chamada à API.
Comece criando o perfil de uma chamada Draw*Primitive em uma sequência de renderização. Lembre-se de:
- Use QueryPerformanceCounter para medir o número de tiques por chamada à API. Use QueryPerformanceFrequency para converter os resultados em ciclos ou hora, se desejar.
- Use o mecanismo de consulta para esvaziar o buffer de comando antes de iniciar.
- Inclua a sequência de renderização em um loop para minimizar o impacto da transição de modo.
- Use o mecanismo de consulta para medir quando a GPU tiver concluído seu trabalho.
- Cuidado com a concatenação de runtime que terá um grande impacto na quantidade de trabalho feito.
Isso oferece um desempenho de linha de base para DrawPrimitive que pode ser usado para compilar. Para criar o perfil de uma alteração de estado, siga estas dicas adicionais:
- Adicione a alteração de estado a um perfil de sequência de renderização conhecido da nova sequência. Como o teste é feito em um loop, isso requer a configuração do estado duas vezes em valores opostos (como habilitar e desabilitar, por exemplo).
- Compare a diferença em tempos de ciclo entre as duas sequências.
- Para alterações de estado que alteram significativamente o pipeline (como SetTexture), subtraia a diferença entre as duas sequências para obter o tempo de alteração de estado.
- Para alterações de estado que alteram significativamente o pipeline (e, portanto, exigem estados de alternância como SetRenderState), subtraia a diferença entre as sequências de renderização e divida por 2. Isso gerará o número médio de ciclos para cada alteração de estado.
Mas tenha cuidado com otimizações que causam resultados inesperados durante a criação de perfil. As otimizações de alteração de estado podem definir sujo estados que fazem com que o trabalho seja adiado. Isso pode causar resultados de perfil que não são tão intuitivos quanto o esperado. As chamadas de desenho concatenadas reduzirão drasticamente o trabalho do driver, o que pode levar a conclusões enganosas. Sequências de renderização cuidadosamente planejadas são usadas para impedir a alteração de estado e desenhar concatenações de chamada. O truque é impedir que as otimizações ocorram durante a criação de perfil para que os números gerados sejam números de orçamento razoáveis.
Observação
Duplicar essa estratégia de criação de perfil em um aplicativo sem o mecanismo de consulta é mais difícil. Antes do Direct3D 9, a única maneira previsível de esvaziar o buffer de comando é bloquear uma superfície ativa (como um destino de renderização) para aguardar até que a GPU esteja ociosa. Isso ocorre porque o bloqueio de uma superfície força o runtime a esvaziar o buffer de comando caso haja comandos de renderização no buffer que devem atualizar a superfície antes que ela seja bloqueada, além de aguardar a conclusão da GPU. Essa técnica é funcional, embora seja mais obtrusiva que o uso do mecanismo de consulta introduzido no Direct3D 9.
Apêndice
Os números nesta tabela são um intervalo de aproximações para a quantidade de runtime e trabalho de driver associado a cada uma dessas alterações de estado. As aproximações são baseadas em medidas reais feitas em drivers usando as técnicas mostradas no artigo. Esses números foram gerados usando o runtime do Direct3D 9 e dependem do driver.
As técnicas neste artigo foram projetadas para medir o runtime e o trabalho do driver. Em geral, é impraticável fornecer resultados que correspondam ao desempenho da CPU e da GPU em cada aplicativo, pois isso exigiria uma matriz exaustiva de sequências de renderização. Além disso, é particularmente difícil comparar o desempenho da GPU porque ela é altamente dependente da configuração de estado no pipeline antes da sequência de renderização. Por exemplo, habilitar a mesclagem alfa pouco afeta a quantidade de trabalho de CPU necessário, mas pode ter um grande impacto na quantidade de trabalho feito pela GPU. Portanto, as técnicas neste artigo restringem o trabalho de GPU à quantidade mínima possível limitando a quantidade de dados que precisam ser renderizados. Isso significa que os números na tabela corresponderão mais de perto aos resultados obtidos de aplicativos limitados pela CPU (em vez de um aplicativo limitado pela GPU).
Você é incentivado a usar as técnicas apresentadas para abranger os cenários e as configurações mais importantes para você. Os valores na tabela podem ser usados para comparar com os números gerados. Como cada driver varia, a única maneira de gerar os números reais que você verá é gerar resultados de criação de perfil usando seus cenários.
| Chamada à API | Número médio de ciclos |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| Setrendertarget | 6000 - 6250 |
| SetPixelShaderConstant (1 constante) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| Setstreamsource | 3700 - 5800 |
| ILUMINAÇÃO | 1700 - 7500 |
| DIFFUSEMATERIALSOURCE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| Setlight | 2200 - 5100 |
| Settransform | 3200 - 3750 |
| Setindices | 900 - 5600 |
| AMBIENTE | 1150 - 4800 |
| Settexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 constante) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| RECORTE | 500 - 2550 |
| Drawindexedprimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| Drawprimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Tópicos relacionados