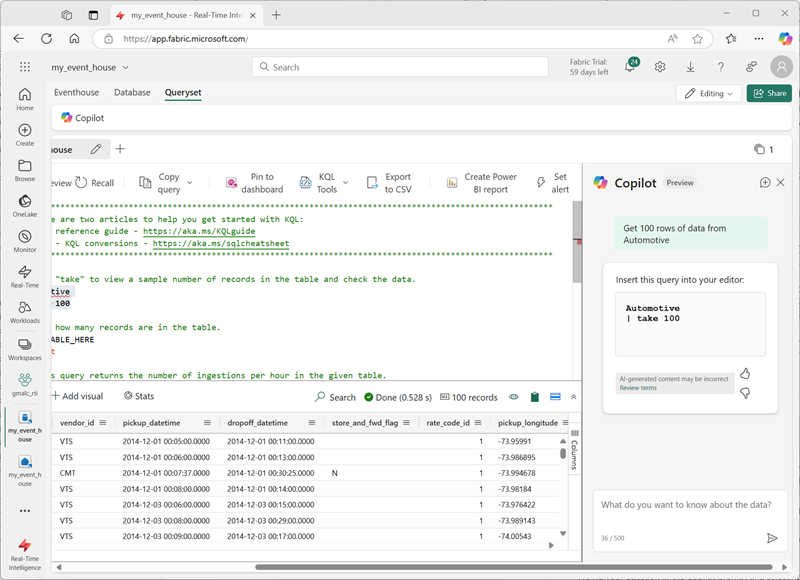
Comece a usar uma casa de eventos
Para criar uma casa de eventos, você deve estar trabalhando em um espaço de trabalho com uma capacidade de malha que ofereça suporte ao recurso de malha de inteligência em tempo real. Em seguida, você pode criar uma ou mais casas de eventos para seus dados.
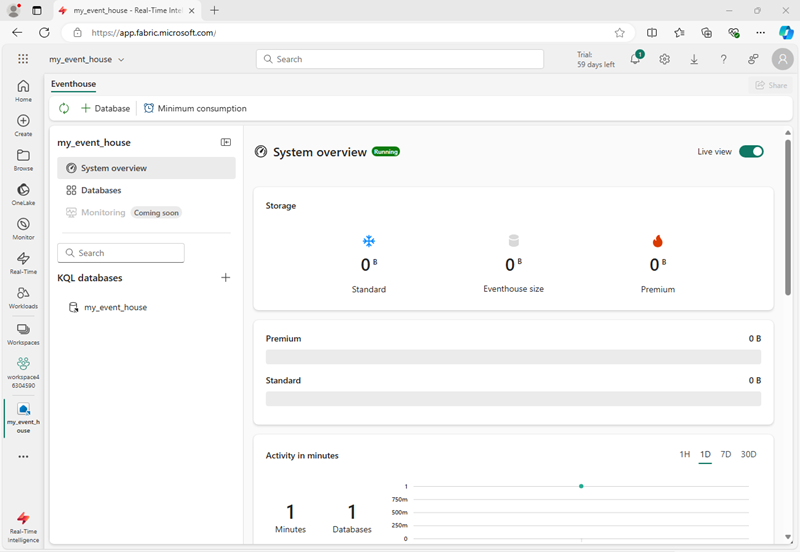
Uma casa de eventos contém um ou mais bancos de dados KQL, nos quais você pode criar tabelas, procedimentos armazenados, exibições materializadas e outros itens para gerenciar seus dados. Depois de criar uma casa de eventos, você pode usar o banco de dados KQL padrão ou criar um novo.
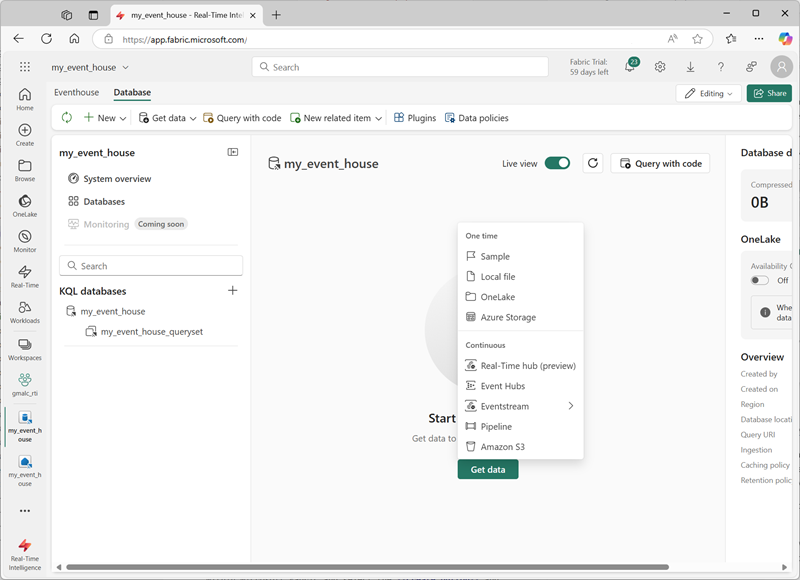
Para colocar seus dados em um banco de dados KQL em uma casa de eventos, normalmente importe-os de um local estático (como um arquivo local, OneLake, armazenamento do Azure ou um conjunto de dados de exemplo) ou de uma fonte em tempo real (como Hubs de Eventos do Azure ou um fluxo de eventos de malha).
Nota
Você pode habilitar a opção OneLake para um banco de dados ou para tabelas individuais que ele contém, disponibilizando os dados dessas tabelas no OneLake.
Consultando tabelas em um banco de dados KQL
Para consultar dados nas tabelas em um banco de dados KQL, você pode escrever código KQL (Kusto Query Language) ou usar um subconjunto restrito de instruções SQL (Structured Query Language).
Para facilitar o desenvolvimento de consultas, as casas de eventos incluem suporte para um ou mais conjuntos de consultas KQL, que simplificam o desenvolvimento de consultas fornecendo exemplos de sintaxe e utilitários de codificação. Um conjunto de consultas padrão é fornecido, e você pode criar mais, se necessário.
A sintaxe KQL é intuitiva e concisa, e inclui uma ampla gama de funções e expressões que facilitam a execução eficiente de análises de dados complexos.
A consulta KQL mais simples consiste simplesmente em um nome de tabela. Por exemplo, para recuperar todos os dados de uma tabela chamada Automotive, você pode executar a seguinte consulta:
Automotive
Esta consulta KQL é o equivalente à expressão SELECT * FROM AutomotiveSQL.
Dado o tamanho potencialmente enorme das tabelas baseadas em fluxos ilimitados de dados em tempo real, usar uma simples consulta de nome de tabela é incomum. Se quiser recuperar uma amostra de dados da tabela, você pode usar a palavra-chave take , conforme mostrado aqui:
Automotive
| take 100
Esta consulta retorna 100 linhas da tabela Automotive (de forma semelhante ao SQL SELECT TOP 100 * FROM Automotive). Observe o | uso do caractere em cada nova linha para separar as cláusulas da consulta.
Aqui estão algumas consultas comuns e seus equivalentes SQL:
Recuperar colunas específicas
Automotive
| project trip_id, pickup_datetime, fare_amount
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
Filtrar linhas
Automotive
| where fare_amount > 20
| project trip_id, pickup_datetime, fare_amount
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
WHERE fare_amount > 20
Ordenar os resultados
Automotive
| where fare_amount > 20
| project trip_id, pickup_datetime, fare_amount
| sort by pickup_datetime desc
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
WHERE fare_amount > 20
ORDER BY pickup_datetime DESC
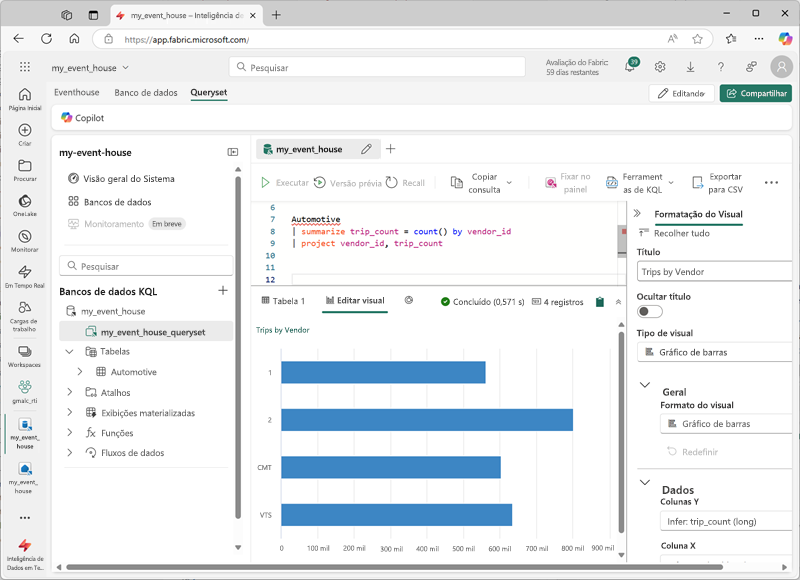
Grupo e agregado
Automotive
| summarize trip_count = count() by vendor_id
| project vendor_id, trip_count
SELECT vendor_id, COUNT(*) AS trip_count
FROM Automotive
GROUP BY vendor_id
Nota
Em todos os exemplos acima, você pode usar a consulta KQL ou a consulta SQL equivalente para recuperar dados de uma tabela em um banco de dados KQL. Existem vantagens para cada língua e, no caso de uma base de dados KQL, a KQL é a língua preferida pelas seguintes razões:
- Simplicidade: KQL é uma linguagem mais simples do que SQL, tornando-a mais fácil de aprender e usar.
- Desempenho: O KQL é otimizado para desempenho e pode lidar com grandes quantidades de dados de forma mais eficiente do que o SQL.
- Flexibilidade: O KQL é mais flexível do que o SQL, permitindo que os usuários executem consultas complexas com facilidade.
- Integração: o KQL é integrado com outros produtos da Microsoft, como o Azure Monitor e o Azure Sentinel.
Uma grande desvantagem de usar SQL sobre KQL é que não é a linguagem nativa do motor e tem que passar por um transformador. Essa diferença de idioma impede que ele seja publicado no Power BI diretamente do Queryset.
No entanto, em alguns casos, o SQL pode ser uma boa escolha pelos seguintes motivos:
- Compatibilidade: SQL é uma linguagem amplamente utilizada e é compatível com muitos sistemas de banco de dados diferentes.
- Funcionalidade: O SQL tem uma gama mais ampla de funções e recursos do que o KQL.
- Programação de procedimentos: SQL suporta programação de procedimentos, o que permite que os desenvolvedores escrevam scripts complexos e procedimentos armazenados.
Visualizar resultados de consulta em um conjunto de consultas
Embora, em última análise, você possa querer criar painéis em tempo real ou relatórios do Power BI com base em suas consultas, isso pode ser útil ao explorar os dados em um conjunto de consultas para criar visualizações de dados rápidas. Em comum com muitos ambientes comuns de desenvolvimento de notebooks , os conjuntos de consultas KQL incluem a capacidade de renderizar os resultados de uma consulta como um gráfico.
Usando o Copilot para ajudar com consultas
Para assistência baseada em IA com consultas KQL, você pode usar o Copilot para Inteligência em Tempo Real.
Quando o administrador tiver ativado o Copilot, você verá a opção na barra de menus do conjunto de consultas. O Copilot é aberto como um painel ao lado da interface de consulta principal. Quando você faz uma pergunta sobre seus dados, o Copilot gera o código KQL para responder à sua pergunta.