Power Query conectores (pré-visualização – descontinuado)
Importante
Power Query suporte do conector foi introduzido como uma pré-visualização pública fechada em Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure, mas foi agora descontinuado. Se tiver uma solução de pesquisa que utilize um conector Power Query, migre para uma solução alternativa.
Migrar até 28 de novembro de 2022
A pré-visualização do conector Power Query foi anunciada em maio de 2021 e não avançará para a disponibilidade geral. A seguinte documentação de orientação de migração está disponível para Snowflake e PostgreSQL. Se estiver a utilizar um conector diferente e precisar de instruções de migração, utilize as informações de contacto de e-mail fornecidas na sua inscrição de pré-visualização para pedir ajuda ou abrir um pedido de suporte com o Suporte do Azure.
Pré-requisitos
- Uma conta do Armazenamento do Azure. Se não tiver uma, crie uma conta de armazenamento.
- Um Azure Data Factory. Se não tiver uma, crie um Data Factory. Veja Preços dos Pipelines do Data Factory antes da implementação para compreender os custos associados. Além disso, veja os preços do Data Factory através de exemplos.
Migrar um pipeline de dados do Snowflake
Esta secção explica como copiar dados de uma base de dados do Snowflake para um índice de Azure Cognitive Search. Não existe nenhum processo de indexação direta do Snowflake para o Azure Cognitive Search, pelo que esta secção inclui uma fase de teste que copia o conteúdo da base de dados para um contentor de blobs do Armazenamento do Azure. Em seguida, irá indexar a partir desse contentor de teste com um pipeline do Data Factory.
Passo 1: Obter informações da base de dados do Snowflake
Aceda a Snowflake e inicie sessão na sua conta do Snowflake. Uma conta do Snowflake parece https://< account_name.snowflakecomputing.com>.
Depois de iniciar sessão, recolha as seguintes informações no painel esquerdo. Irá utilizar estas informações no próximo passo:
- Em Dados, selecione Bases de dados e copie o nome da origem da base de dados.
- Em Administração, selecione Utilizadores & Funções e copie o nome do utilizador. Certifique-se de que o utilizador tem permissões de leitura.
- Em Administração, selecione Contas e copie o valor LOCATOR da conta.
- No URL do Snowflake, semelhante a
https://app.snowflake.com/<region_name>/xy12345/organization). copie o nome da região. Por exemplo, emhttps://app.snowflake.com/south-central-us.azure/xy12345/organization, o nome da região ésouth-central-us.azure. - Em Administração, selecione Armazéns e copie o nome do armazém associado à base de dados que irá utilizar como origem.
Passo 2: Configurar o Serviço Ligado snowflake
Inicie sessão no Azure Data Factory Studio com a sua conta do Azure.
Selecione a fábrica de dados e, em seguida, selecione Continuar.
No menu esquerdo, selecione o ícone Gerir .
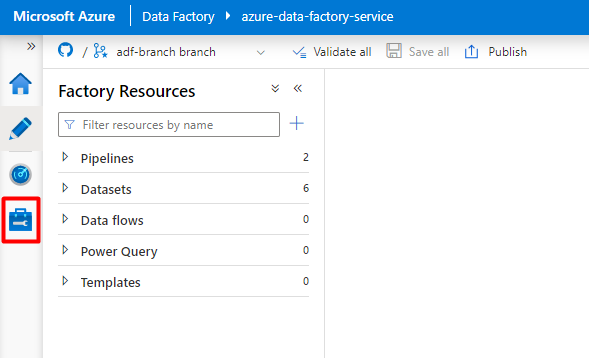
Em Serviços ligados, selecione Novo.
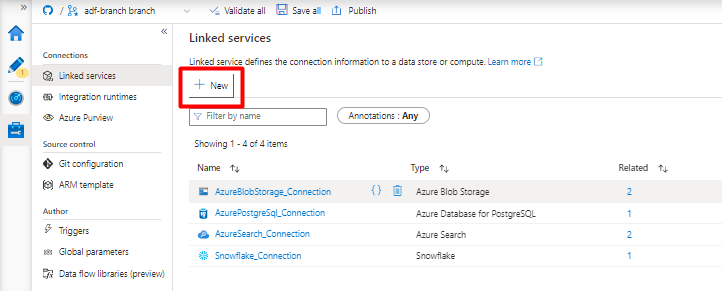
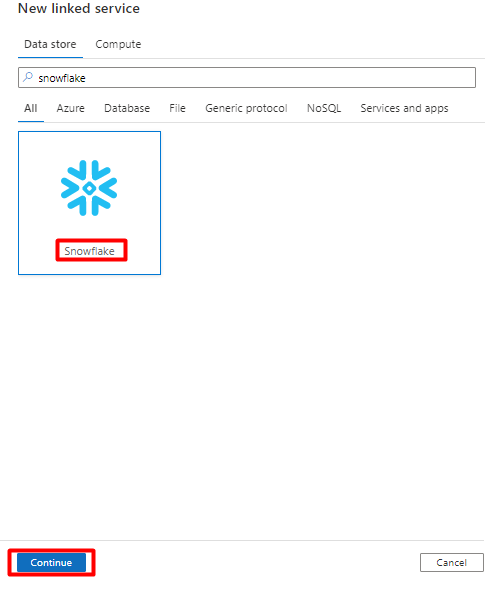
No painel direito, na pesquisa do arquivo de dados, introduza "floco de neve". Selecione o mosaico Floco de Neve e selecione Continuar.
Preencha o formulário Novo serviço ligado com os dados que recolheu no passo anterior. O Nome da conta inclui um valor LOCATOR e a região (por exemplo:
xy56789south-central-us.azure).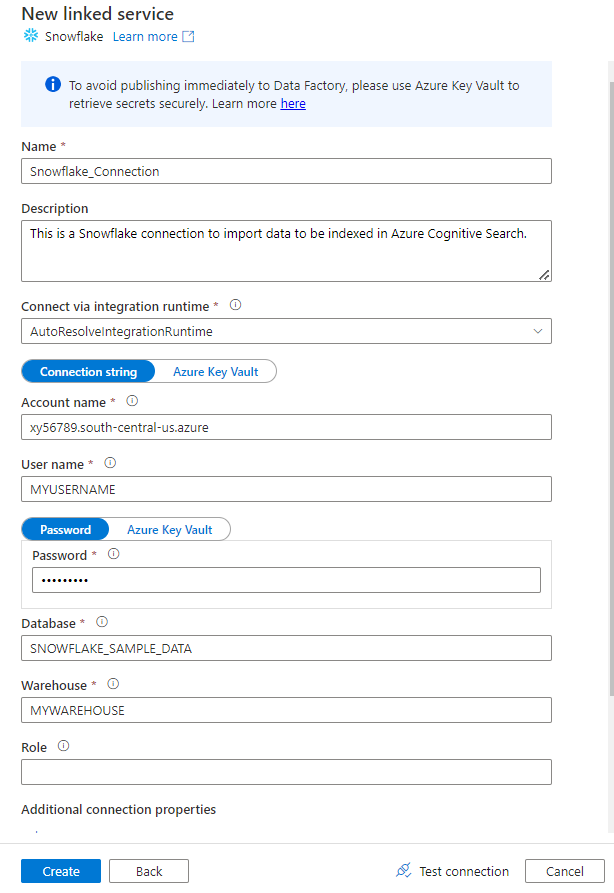
Após a conclusão do formulário, selecione Testar ligação.
Se o teste for bem-sucedido, selecione Criar.
Passo 3: Configurar o Conjunto de Dados do Snowflake
No menu esquerdo, selecione o ícone Autor .
Selecione Conjuntos de dados e, em seguida, selecione o menu de reticências Ações de Conjuntos de Dados (
...).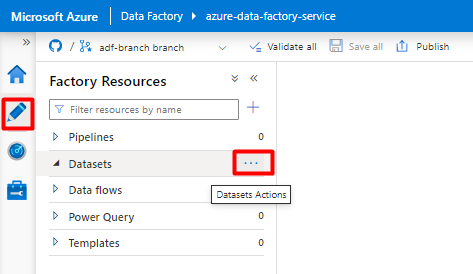
Selecione Novo conjunto de dados.
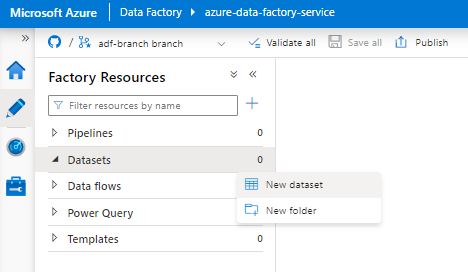
No painel direito, na pesquisa do arquivo de dados, introduza "floco de neve". Selecione o mosaico Floco de Neve e selecione Continuar.
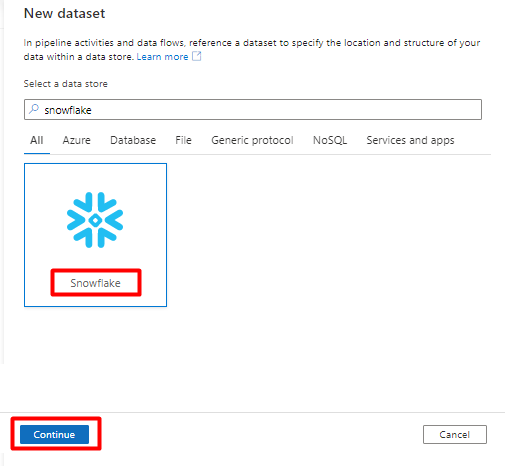
Em Definir Propriedades:
- Selecione o Serviço Ligado que criou no Passo 2.
- Selecione a tabela que pretende importar e, em seguida, selecione OK.
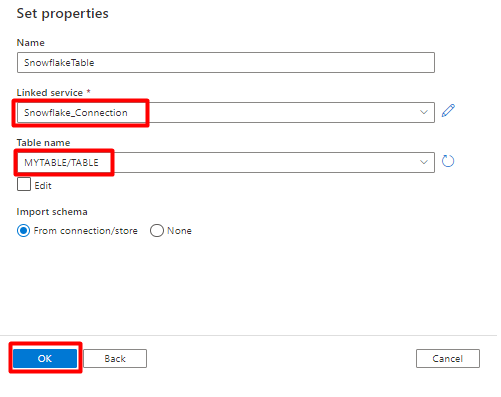
Selecione Guardar.
Passo 4: Criar um novo índice no Azure Cognitive Search
Crie um novo índice no serviço Azure Cognitive Search com o mesmo esquema que configurou atualmente para os seus dados do Snowflake.
Pode reutilizar o índice que está a utilizar atualmente para o Snowflake Power Connector. Na portal do Azure, localize o índice e, em seguida, selecione Definição de Índice (JSON). Selecione a definição e copie-a para o corpo do novo pedido de índice.
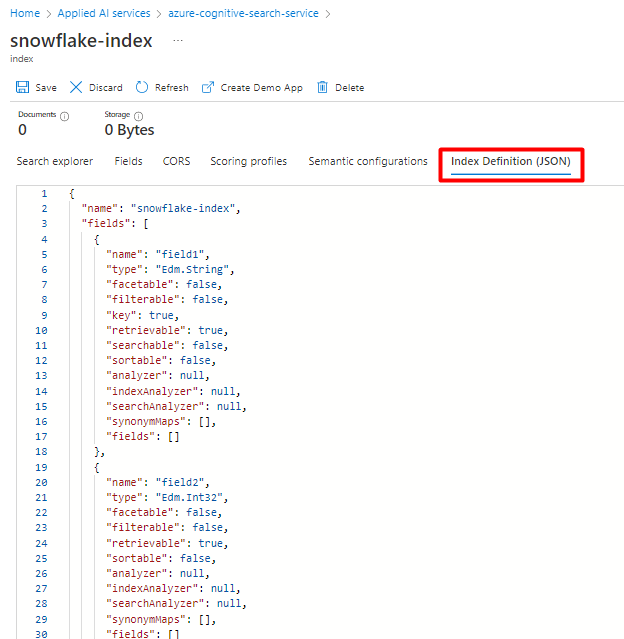
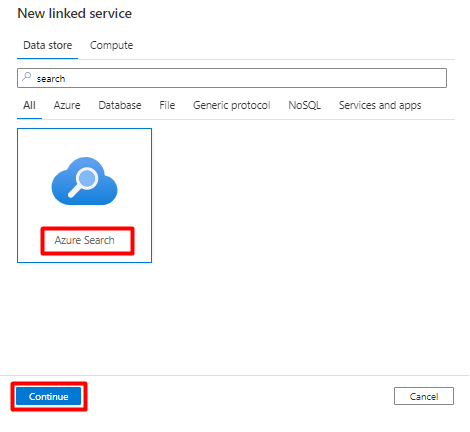
Passo 5: Configurar Azure Cognitive Search Serviço Ligado
No menu esquerdo, selecione Gerir ícone.
Em Serviços ligados, selecione Novo.
No painel direito, na pesquisa do arquivo de dados, introduza "search". Selecione o mosaico Azure Search e selecione Continuar.
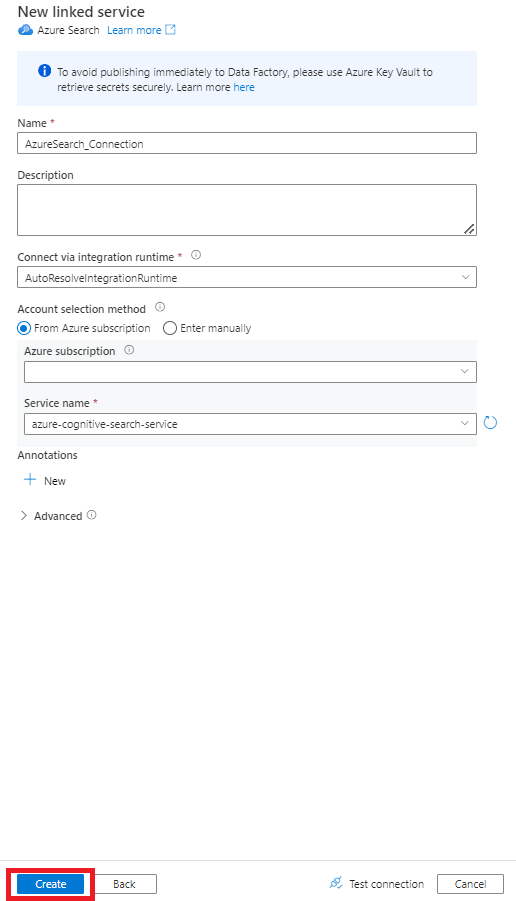
Preencha os novos valores de serviço ligado :
- Escolha a subscrição do Azure onde reside o serviço Azure Cognitive Search.
- Escolha o serviço Azure Cognitive Search que tem o indexador do conector Power Query.
- Selecione Criar.
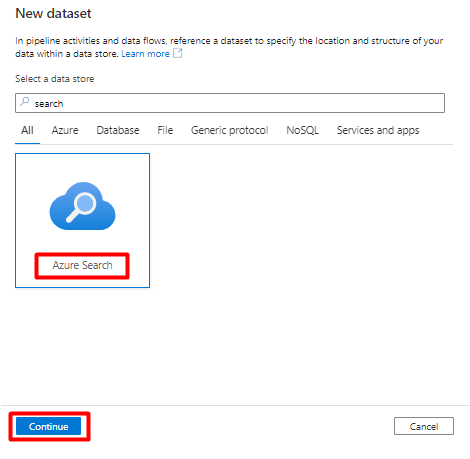
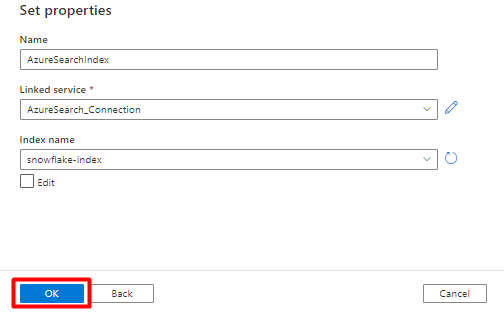
Passo 6: Configurar Azure Cognitive Search Conjunto de Dados
No menu esquerdo, selecione Ícone de autor .
Selecione Conjuntos de dados e, em seguida, selecione o menu de reticências Ações de Conjuntos de Dados (
...).
Selecione Novo conjunto de dados.
No painel direito, na pesquisa do arquivo de dados, introduza "search". Selecione o mosaico Azure Search e selecione Continuar.
Em Definir propriedades:
Selecione Guardar.
Passo 7: Configurar Armazenamento de Blobs do Azure Serviço Ligado
No menu esquerdo, selecione Gerir ícone.
Em Serviços ligados, selecione Novo.
No painel direito, na pesquisa do arquivo de dados, introduza "armazenamento". Selecione o mosaico Armazenamento de Blobs do Azure e selecione Continuar.
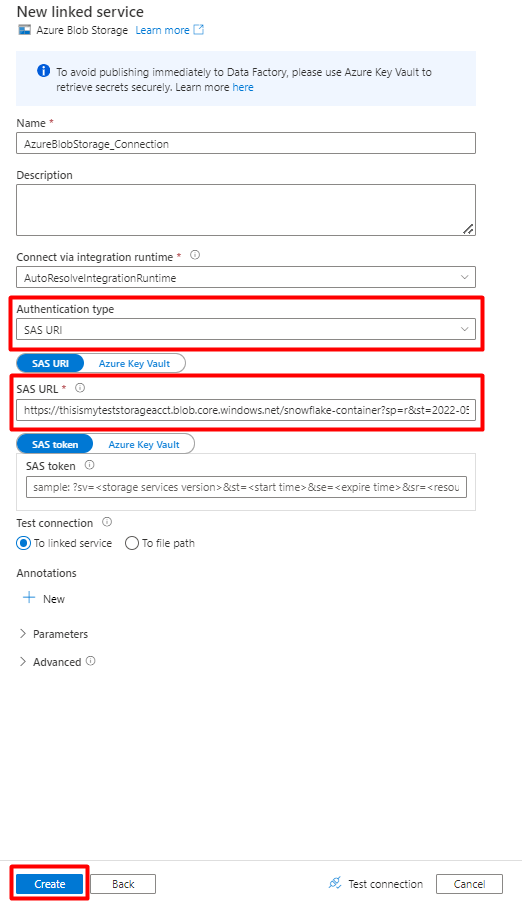
Preencha os novos valores de serviço ligado :
Selecione o Tipo de autenticação: URI de SAS. Apenas este tipo de autenticação pode ser utilizado para importar dados do Snowflake para Armazenamento de Blobs do Azure.
Gere um URL de SAS para a conta de armazenamento que irá utilizar para teste. Cole o URL de SAS do Blob no campo URL de SAS.
Selecione Criar.
Passo 8: Configurar o conjunto de dados de Armazenamento
No menu esquerdo, selecione Ícone de autor .
Selecione Conjuntos de dados e, em seguida, selecione o menu de reticências Ações de Conjuntos de Dados (
...).
Selecione Novo conjunto de dados.
No painel direito, na pesquisa do arquivo de dados, introduza "armazenamento". Selecione o mosaico Armazenamento de Blobs do Azure e selecione Continuar.
Selecione Formato de texto delimitado e selecione Continuar.
Em Definir Propriedades:
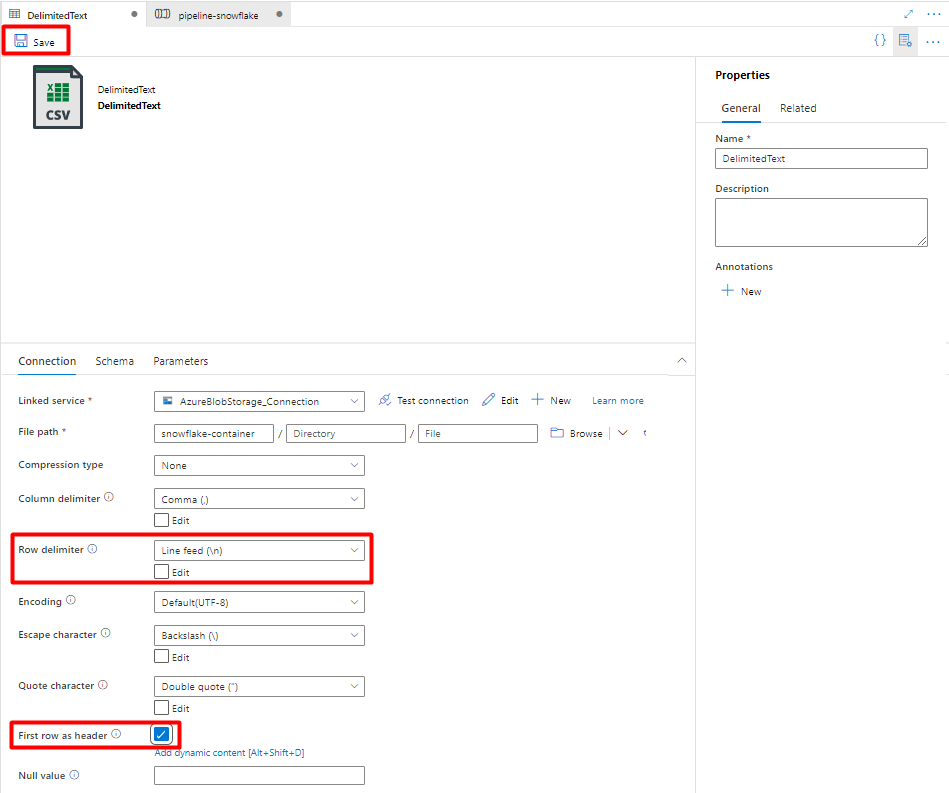
Em Serviço ligado, selecione o serviço ligado criado no Passo 7.
Em Caminho do ficheiro, escolha o contentor que será o sink do processo de teste e selecione OK.
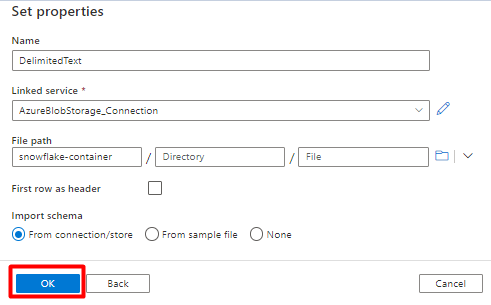
Em Delimitador de linhas, selecione Feed de linhas (\n).
Selecione Primeira linha como uma caixa de cabeçalho .
Selecione Guardar.
Passo 9: Configurar o Pipeline
No menu esquerdo, selecione Ícone de autor .
Selecione Pipelines e, em seguida, selecione o menu de reticências de Ações de Pipelines (
...).
Selecione Novo pipeline.
Crie e configure as atividades do Data Factory que copiam do Snowflake para o contentor de Armazenamento do Azure:
Expanda Mover & secção de transformação e arraste e largue a atividade Copiar Dados para a tela do editor de pipelines em branco.
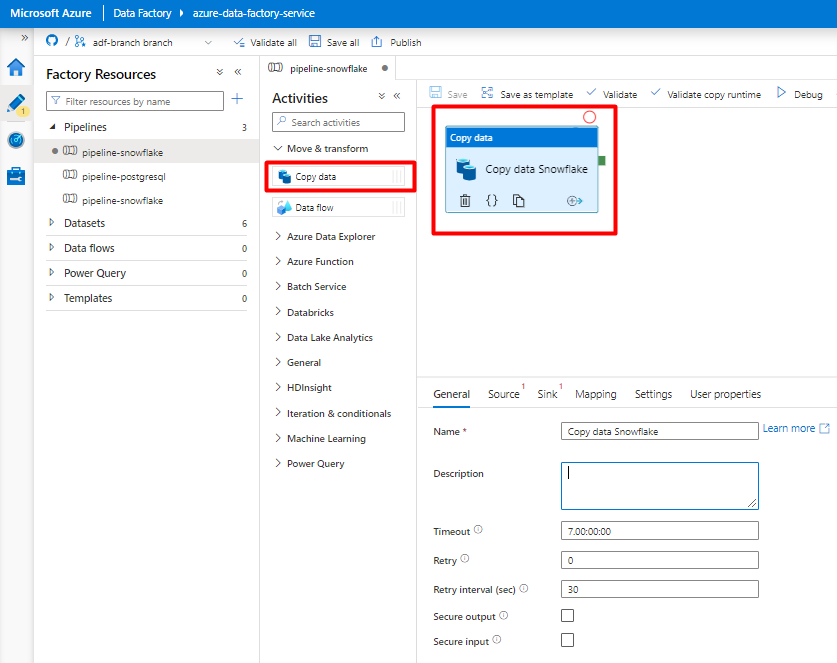
Abra o separador Geral . Aceite os valores predefinidos, a menos que precise de personalizar a execução.
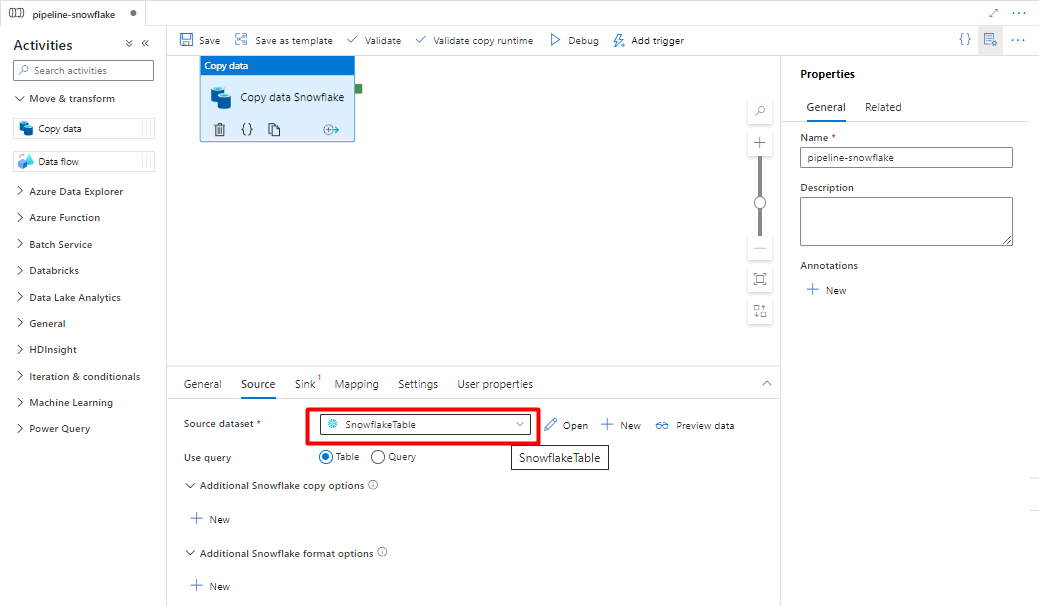
No separador Origem , selecione a sua tabela Snowflake. Deixe as restantes opções com os valores predefinidos.
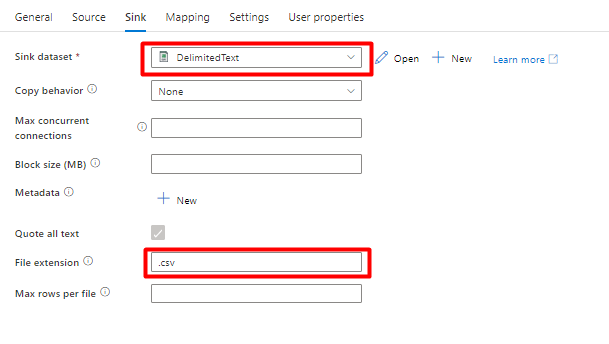
No separador Sink :
Selecione Conjunto de dados Delimitado por Texto de Armazenamento criado no Passo 8.
Em Extensão de Ficheiro, adicione .csv.
Deixe as restantes opções com os valores predefinidos.
Selecione Guardar.
Configure as atividades que copiam do Blob de Armazenamento do Azure para um índice de pesquisa:
Expanda Mover & secção de transformação e arraste e largue a atividade Copiar Dados para a tela do editor de pipelines em branco.
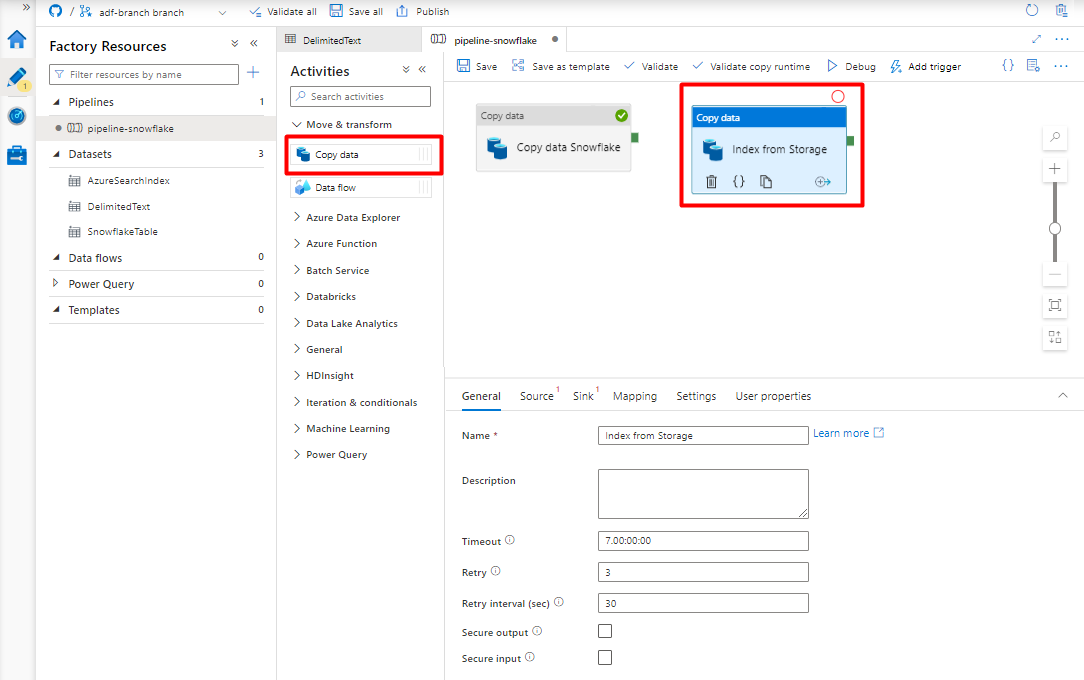
No separador Geral , aceite os valores predefinidos, a menos que precise de personalizar a execução.
No separador Origem :
- Selecione Conjunto de dados Delimitado por Texto de Armazenamento criado no Passo 8.
- No Tipo de caminho de ficheiro , selecione Caminho do ficheiro de caráter universal.
- Deixe todos os campos restantes com valores predefinidos.
No separador Sink, selecione o índice Azure Cognitive Search. Deixe as restantes opções com os valores predefinidos.
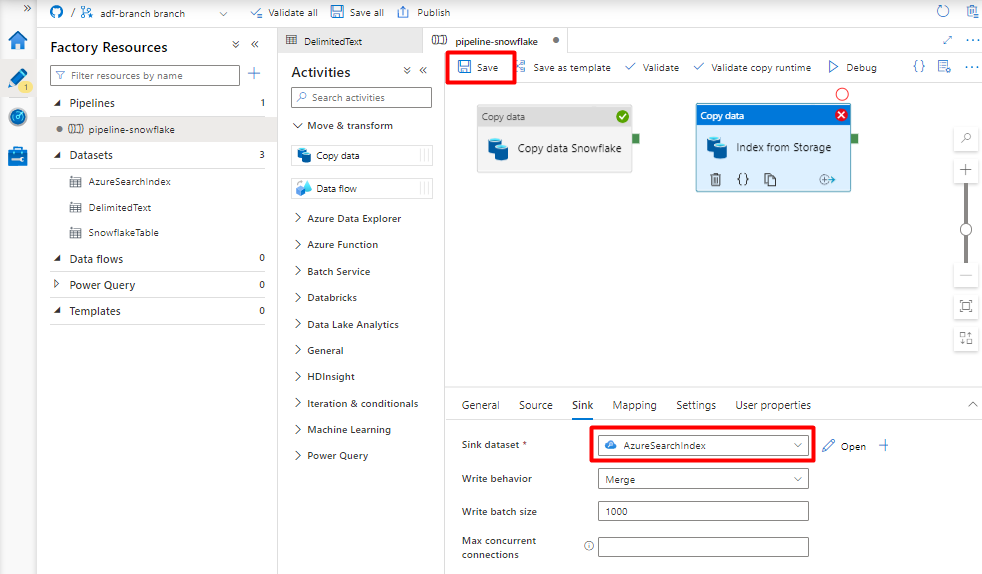
Selecione Guardar.
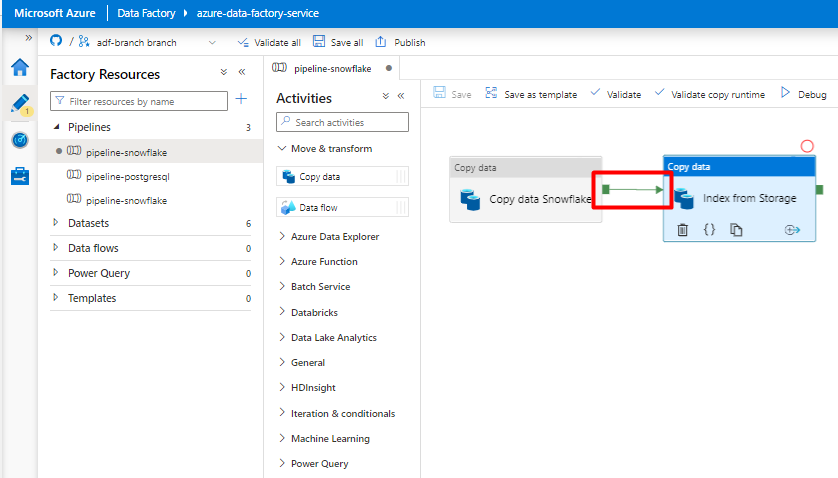
Passo 10: Configurar a Ordem de atividade
No editor de tela pipeline, selecione o pequeno quadrado verde na margem do mosaico de atividade do pipeline. Arraste-a para a atividade "Índices da Conta de Armazenamento para Azure Cognitive Search" para definir a ordem de execução.
Selecione Guardar.
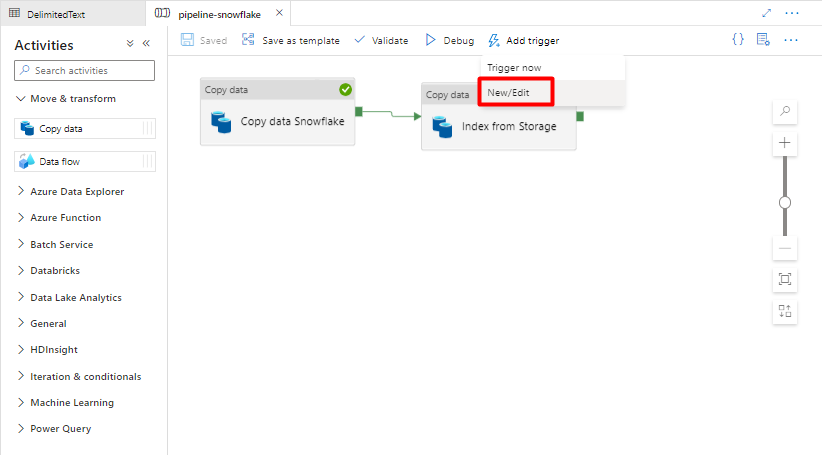
Passo 11: Adicionar um acionador de Pipeline
Selecione Adicionar acionador para agendar a execução do pipeline e selecione Novo/Editar.
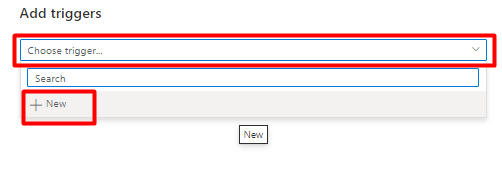
Na lista pendente Escolher acionador , selecione Novo.
Reveja as opções de acionador para executar o pipeline e selecione OK.
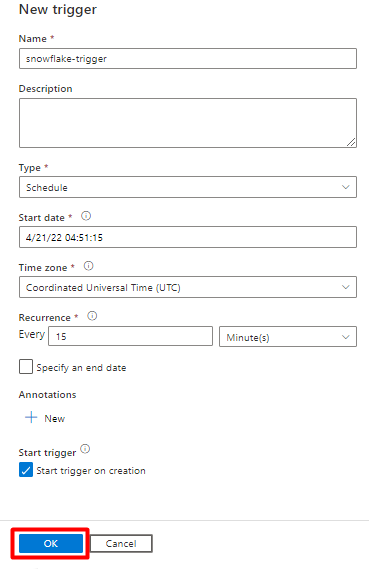
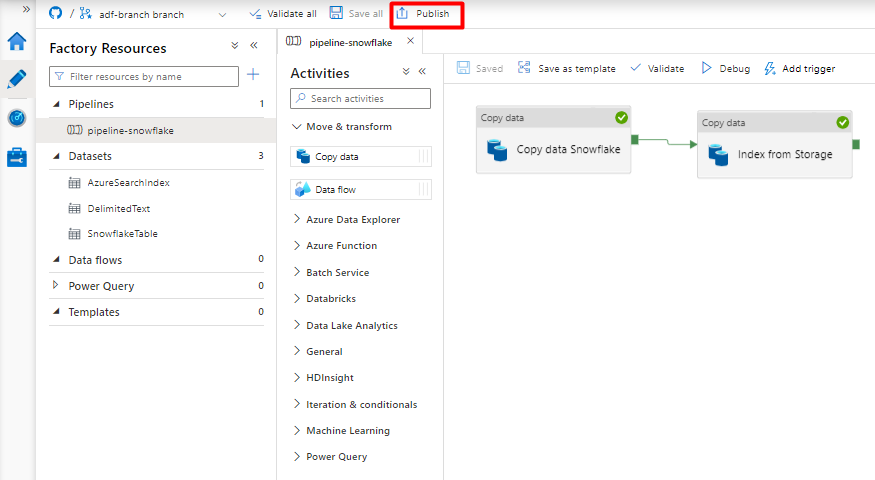
Selecione Guardar.
Selecione Publicar.
Migrar um pipeline de dados do PostgreSQL
Esta secção explica como copiar dados de uma base de dados PostgreSQL para um índice de Azure Cognitive Search. Não existe nenhum processo de indexação direta do PostgreSQL para o Azure Cognitive Search, pelo que esta secção inclui uma fase de teste que copia o conteúdo da base de dados para um contentor de blobs do Armazenamento do Azure. Em seguida, irá indexar a partir desse contentor de teste com um pipeline do Data Factory.
Passo 1: Configurar o Serviço Ligado PostgreSQL
Inicie sessão no Azure Data Factory Studio com a sua conta do Azure.
Selecione o data factory e selecione Continuar.
No menu esquerdo, selecione o ícone Gerir .
Em Serviços ligados, selecione Novo.
No painel direito, na pesquisa do arquivo de dados, introduza "postgresql". Selecione o mosaico PostgreSQL que representa onde está localizada a base de dados PostgreSQL (Azure ou outro) e selecione Continuar. Neste exemplo, a base de dados PostgreSQL está localizada no Azure.

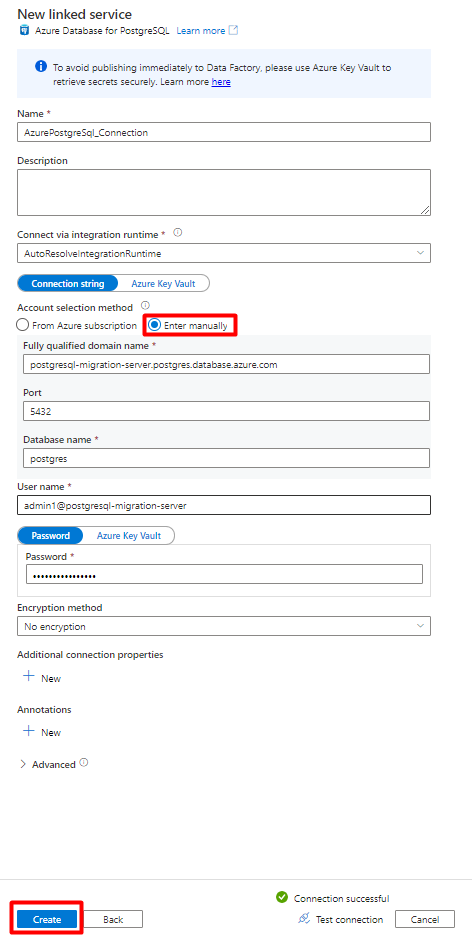
Preencha os novos valores de serviço ligado :
Em Método de seleção de conta, selecione Introduzir manualmente.
Na página Descrição Geral do Base de Dados do Azure para PostgreSQL no portal do Azure, cole os seguintes valores no respetivo campo:
- Adicione o Nome do servidor ao nome de domínio completamente qualificado.
- Adicione Administração nome de utilizador ao Nome de utilizador.
- Adicionar Base de Dados ao Nome da base de dados.
- Introduza o Administração palavra-passe de nome de utilizador para Palavra-passe de nome de utilizador.
- Selecione Criar.
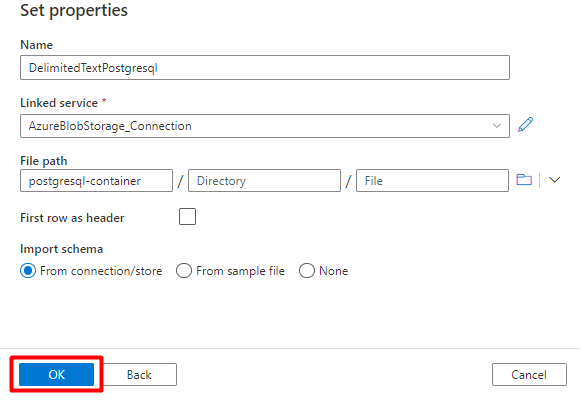
Passo 2: Configurar o Conjunto de Dados postgreSQL
No menu esquerdo, selecione Ícone de autor.
Selecione Conjuntos de dados e, em seguida, selecione o menu Reticências de Ações de Conjuntos de Dados (
...).
Selecione Novo conjunto de dados.
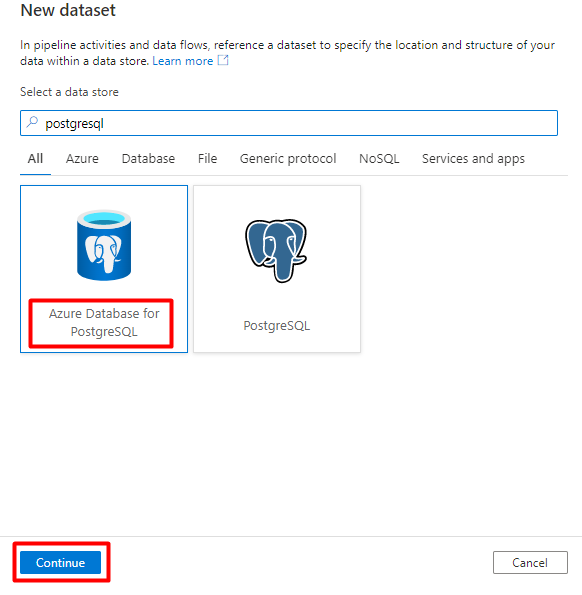
No painel direito, na pesquisa do arquivo de dados, introduza "postgresql". Selecione o mosaico Azure PostgreSQL . Selecione Continuar.
Preencha os valores de propriedades Definir :
Selecione o Serviço Ligado PostgreSQL criado no Passo 1.
Selecione a tabela que pretende importar/indexar.
Selecione OK.
Selecione Guardar.
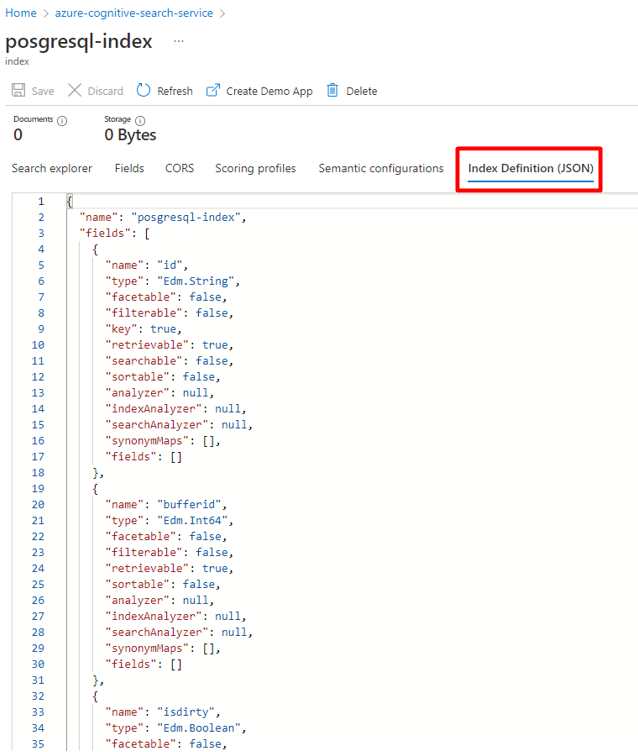
Passo 3: Criar um novo índice no Azure Cognitive Search
Crie um novo índice no serviço Azure Cognitive Search com o mesmo esquema que o utilizado para os seus dados postgreSQL.
Pode reutilizar o índice que está a utilizar atualmente para o Power Connector do PostgreSQL. No portal do Azure, localize o índice e, em seguida, selecione Definição de Índice (JSON). Selecione a definição e copie-a para o corpo do novo pedido de índice.
Passo 4: Configurar Azure Cognitive Search Serviço Ligado
No menu esquerdo, selecione o ícone Gerir .
Em Serviços ligados, selecione Novo.
No painel direito, na pesquisa do arquivo de dados, introduza "search". Selecione mosaico Azure Search e selecione Continuar.
Preencha os novos valores do serviço ligado :
- Selecione a subscrição do Azure onde reside o serviço Azure Cognitive Search.
- Selecione o serviço Azure Cognitive Search que tem o indexador do conector Power Query.
- Selecione Criar.
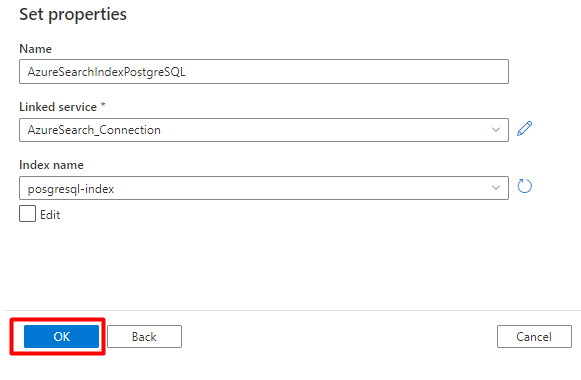
Passo 5: Configurar Azure Cognitive Search Conjunto de Dados
No menu esquerdo, selecione Ícone de autor.
Selecione Conjuntos de dados e, em seguida, selecione o menu Reticências de Ações de Conjuntos de Dados (
...).
Selecione Novo conjunto de dados.
No painel direito, na pesquisa do arquivo de dados, introduza "search". Selecione o mosaico Azure Search e selecione Continuar.
Em Definir propriedades:
Selecione Guardar.
Passo 6: Configurar Armazenamento de Blobs do Azure Serviço Ligado
No menu esquerdo, selecione Gerir ícone.
Em Serviços ligados, selecione Novo.
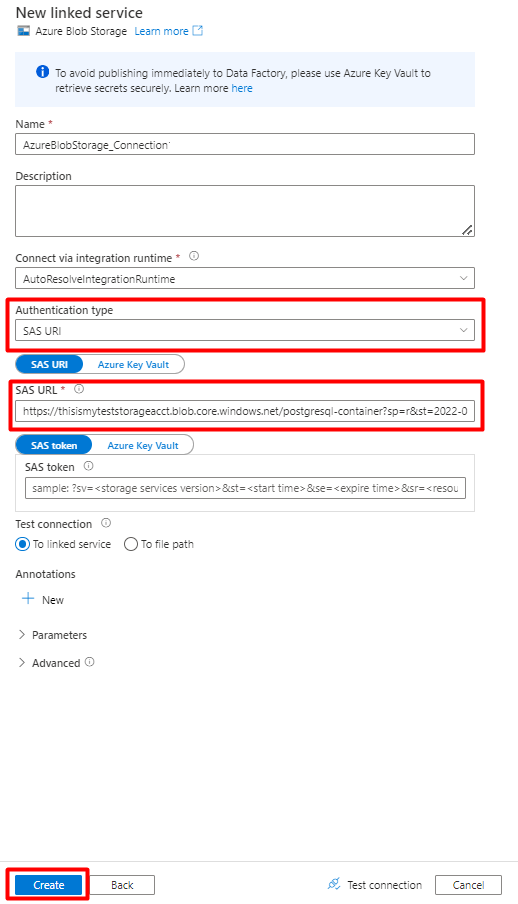
No painel direito, na pesquisa do arquivo de dados, introduza "storage". Selecione o mosaico Armazenamento de Blobs do Azure e selecione Continuar.
Preencha os novos valores do serviço ligado :
Selecione o Tipo de autenticação: URI de SAS. Apenas este método pode ser utilizado para importar dados do PostgreSQL para Armazenamento de Blobs do Azure.
Gere um URL de SAS para a conta de armazenamento que vai utilizar para teste e copie o URL sas de Blob para o campo DE URL de SAS.
Selecione Criar.
Passo 7: Configurar o conjunto de dados de Armazenamento
No menu esquerdo, selecione Ícone de autor.
Selecione Conjuntos de dados e, em seguida, selecione o menu Reticências de Ações de Conjuntos de Dados (
...).
Selecione Novo conjunto de dados.
No painel direito, na pesquisa do arquivo de dados, introduza "storage". Selecione o mosaico Armazenamento de Blobs do Azure e selecione Continuar.
Selecione Formato DelimitadoTexto e selecione Continuar.
No Delimitador de linhas, selecione Feed de linhas (\n).
Selecione Primeira linha como uma caixa de cabeçalho .
Selecione Guardar.
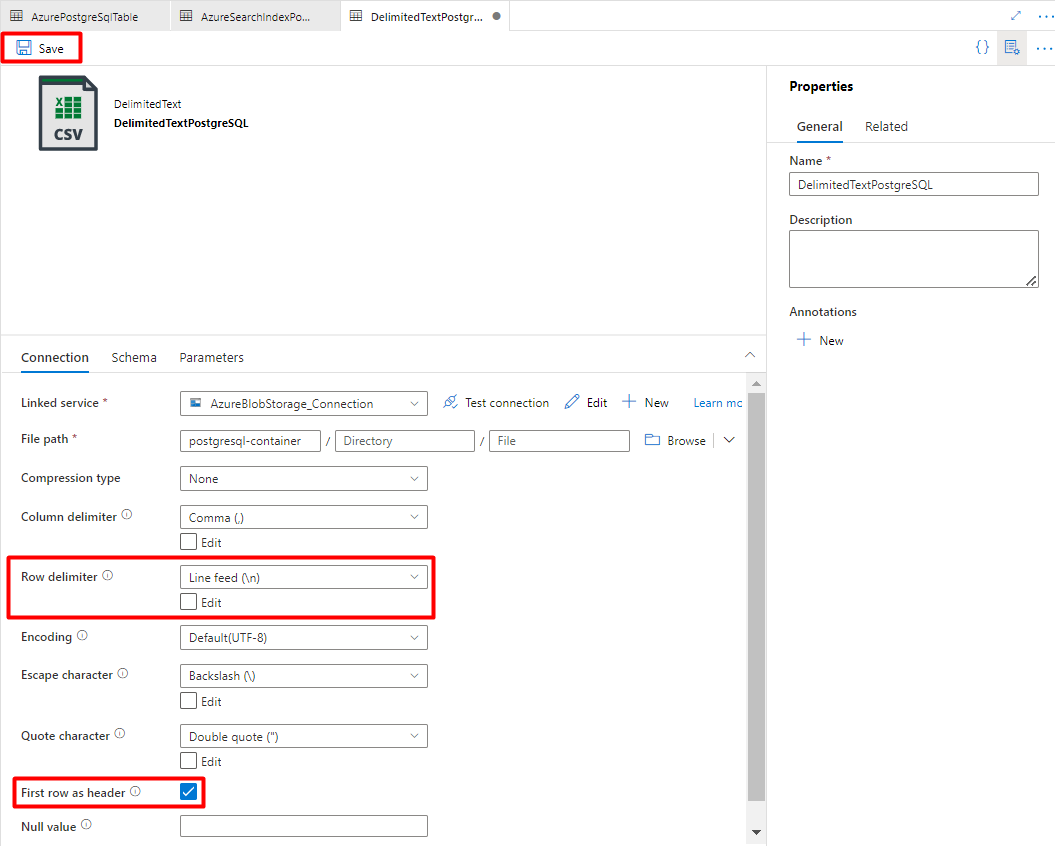
Passo 8: Configurar o Pipeline
No menu esquerdo, selecione Ícone de autor.
Selecione Pipelines e, em seguida, selecione o menu de reticências do Pipelines Actions (
...).
Selecione Novo pipeline.
Crie e configure as atividades do Data Factory que copiam do PostgreSQL para o contentor de Armazenamento do Azure.
Expanda Mover & transformar secção e arraste e largue a atividade Copiar Dados para a tela do editor de pipelines em branco.
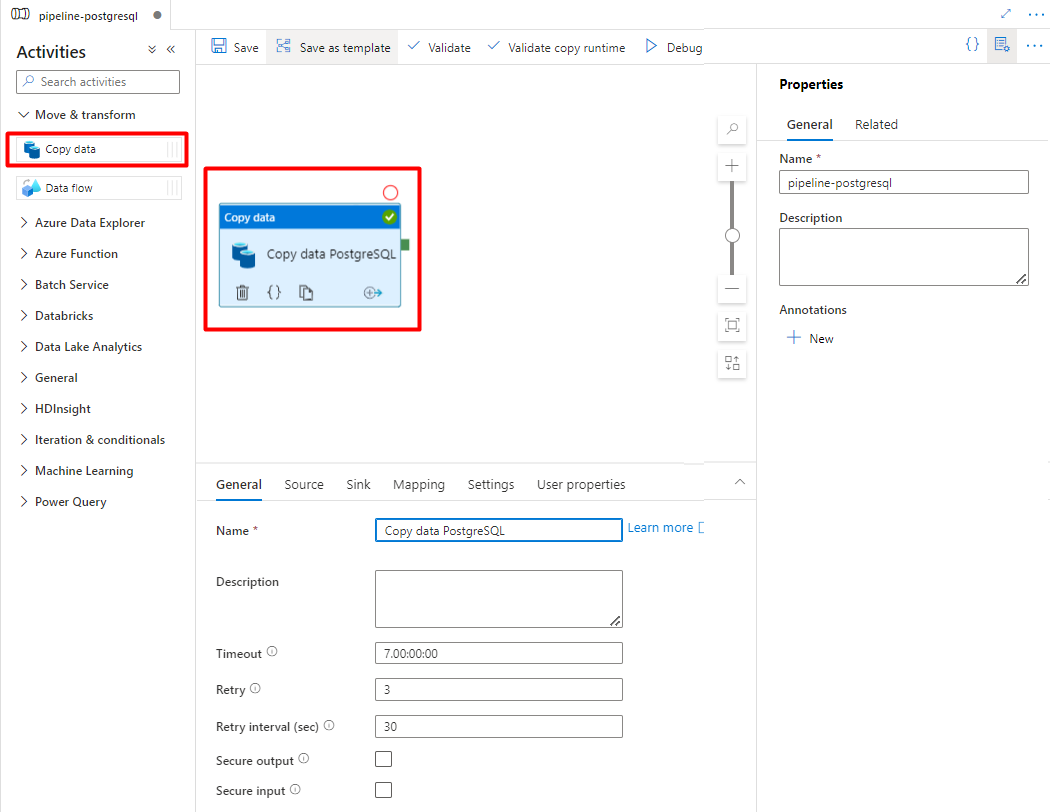
Abra o separador Geral , aceite os valores predefinidos, a menos que precise de personalizar a execução.
No separador Origem , selecione a tabela PostgreSQL. Deixe as restantes opções com os valores predefinidos.
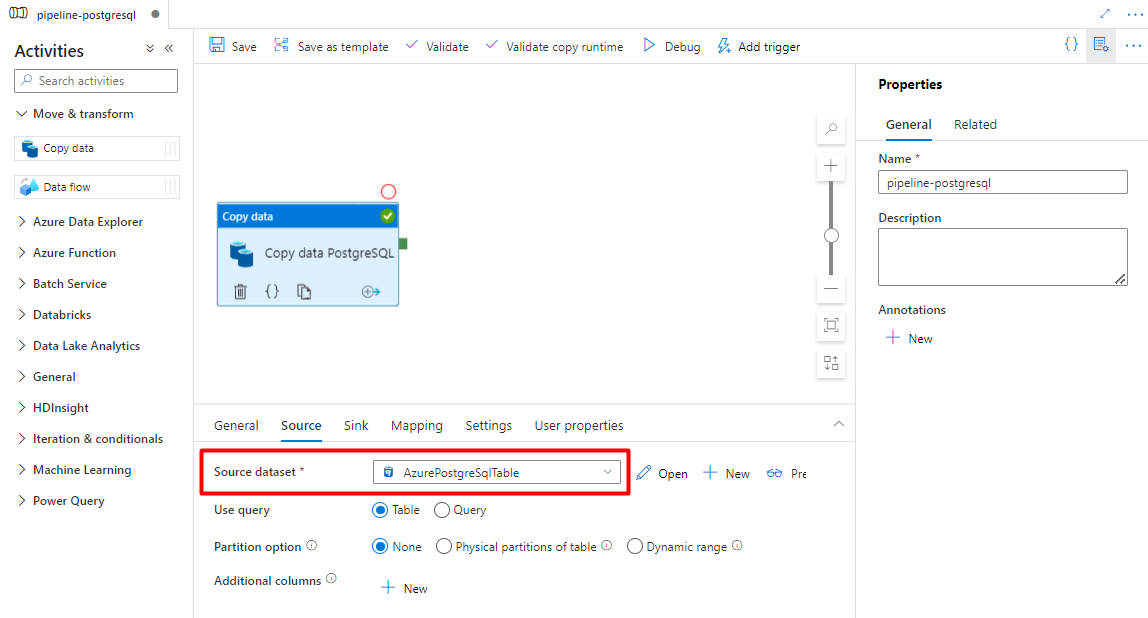
No separador Sink :
Selecione o conjunto de dados Storage DelimitedText PostgreSQL configurado no Passo 7.
Na Extensão de Ficheiro, adicione .csv
Deixe as restantes opções com os valores predefinidos.
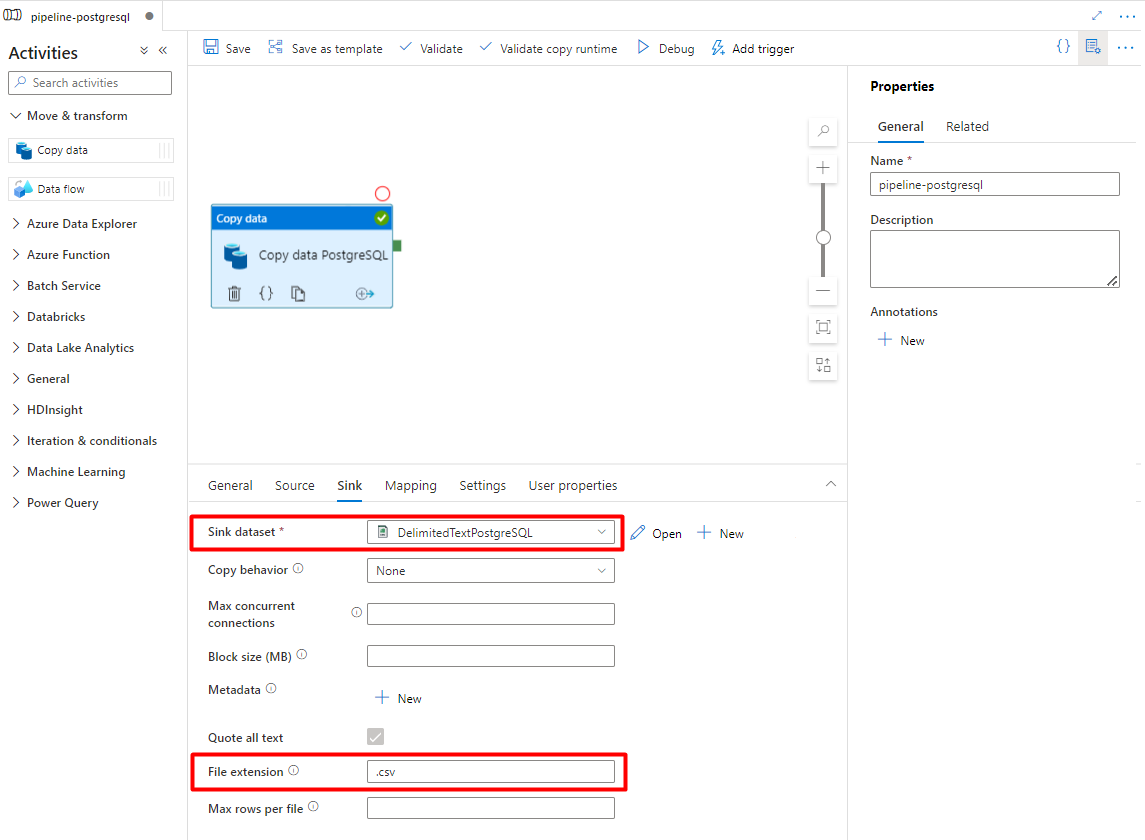
Selecione Guardar.
Configure as atividades que copiam do Armazenamento do Azure para um índice de pesquisa:
Expanda Mover & transformar secção e arraste e largue a atividade Copiar Dados para a tela do editor de pipelines em branco.
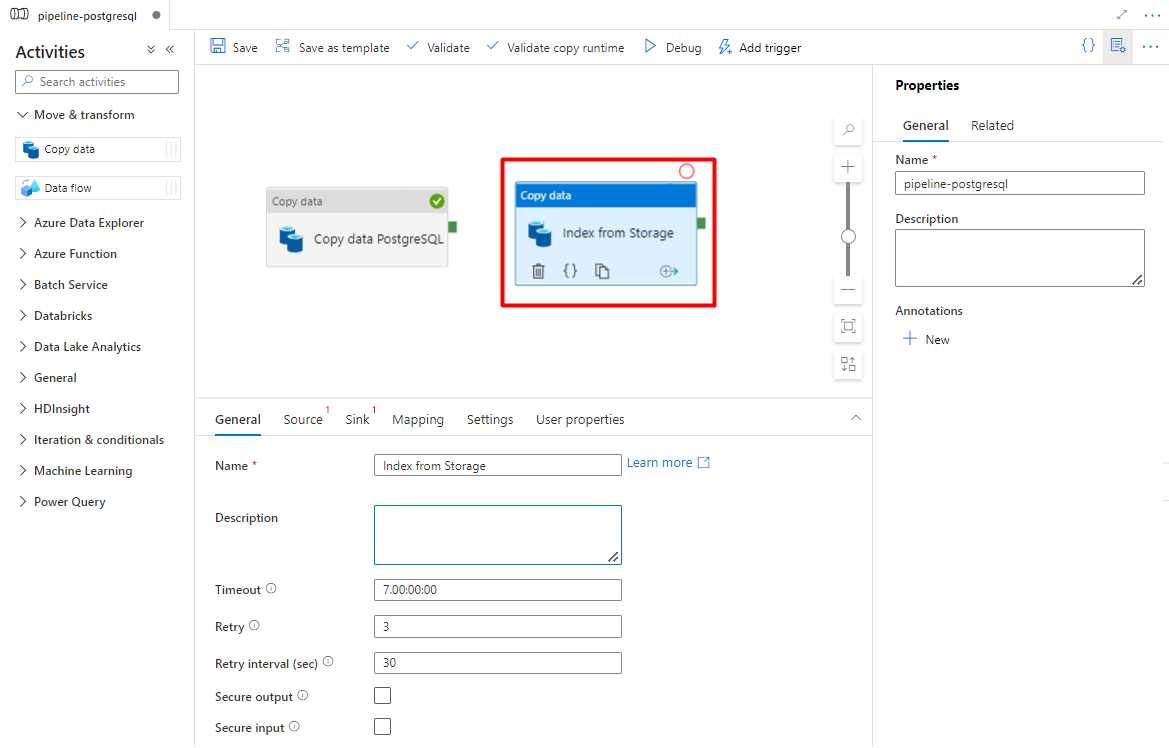
No separador Geral , deixe os valores predefinidos, a menos que precise de personalizar a execução.
No separador Origem :
- Selecione o conjunto de dados Origem de armazenamento configurado no Passo 7.
- No campo Tipo de caminho de ficheiro , selecione Caminho do ficheiro de caráter universal.
- Deixe todos os campos restantes com valores predefinidos.
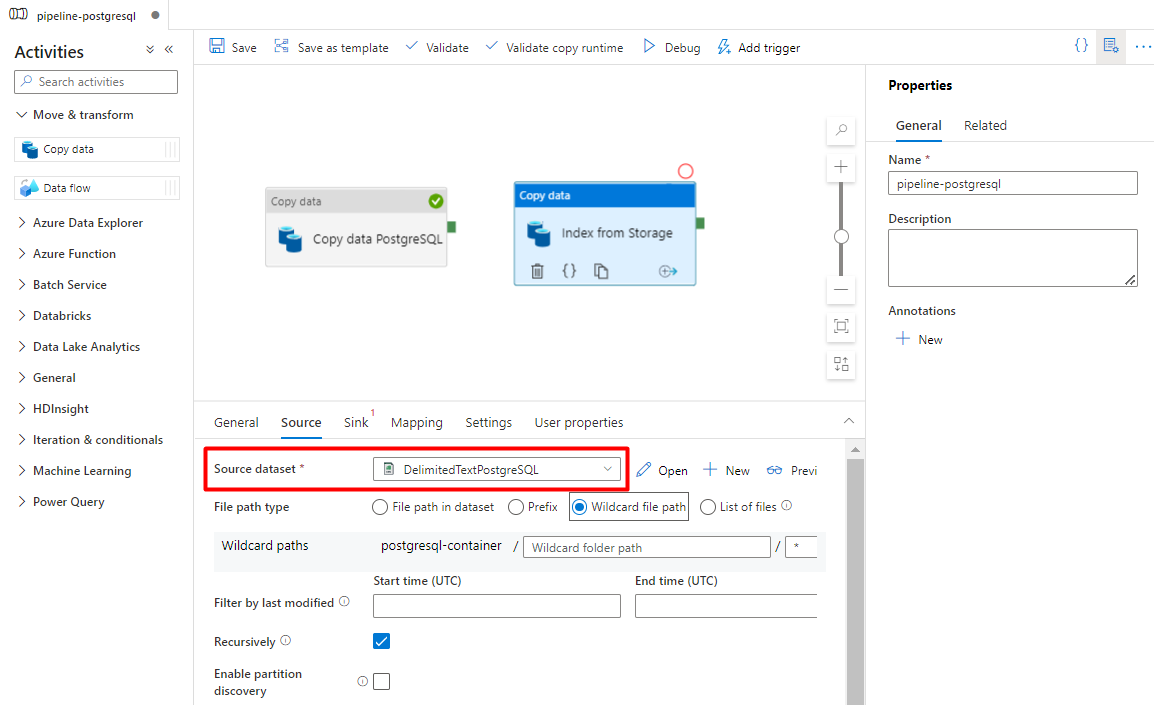
No separador Sink, selecione o índice Azure Cognitive Search. Deixe as restantes opções com os valores predefinidos.
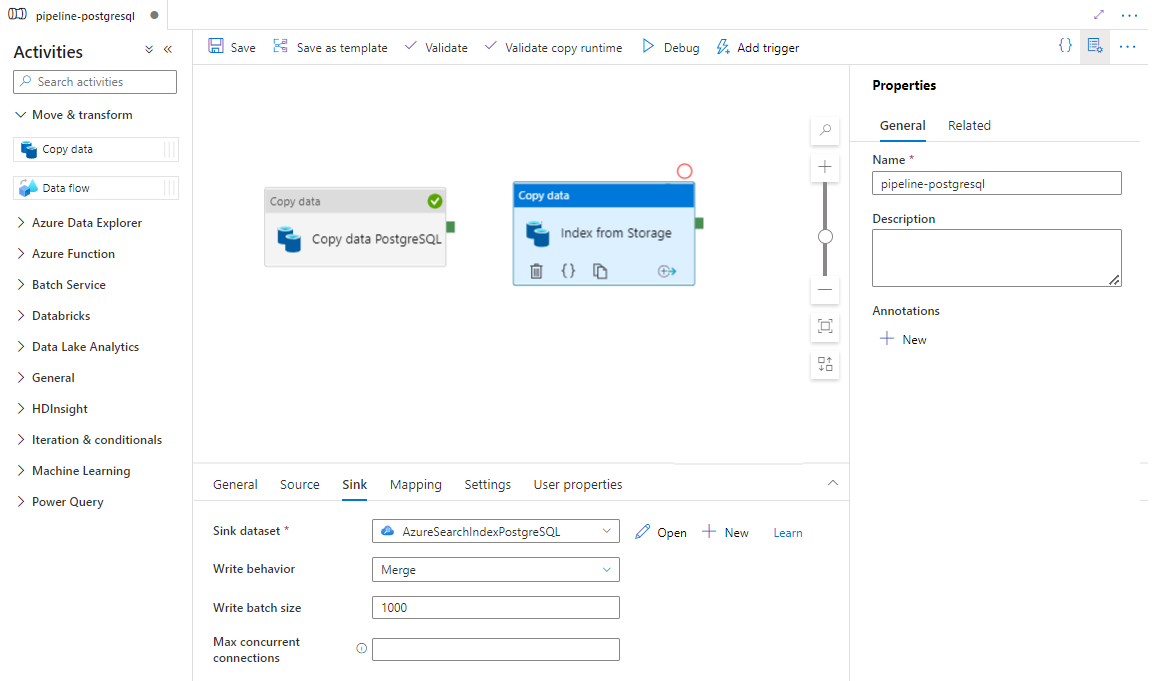
Selecione Guardar.
Passo 9: Configurar a Ordem de atividade
No editor de tela pipeline, selecione o pequeno quadrado verde na margem da atividade do pipeline. Arraste-a para a atividade "Índices da Conta de Armazenamento para Azure Cognitive Search" para definir a ordem de execução.
Selecione Guardar.
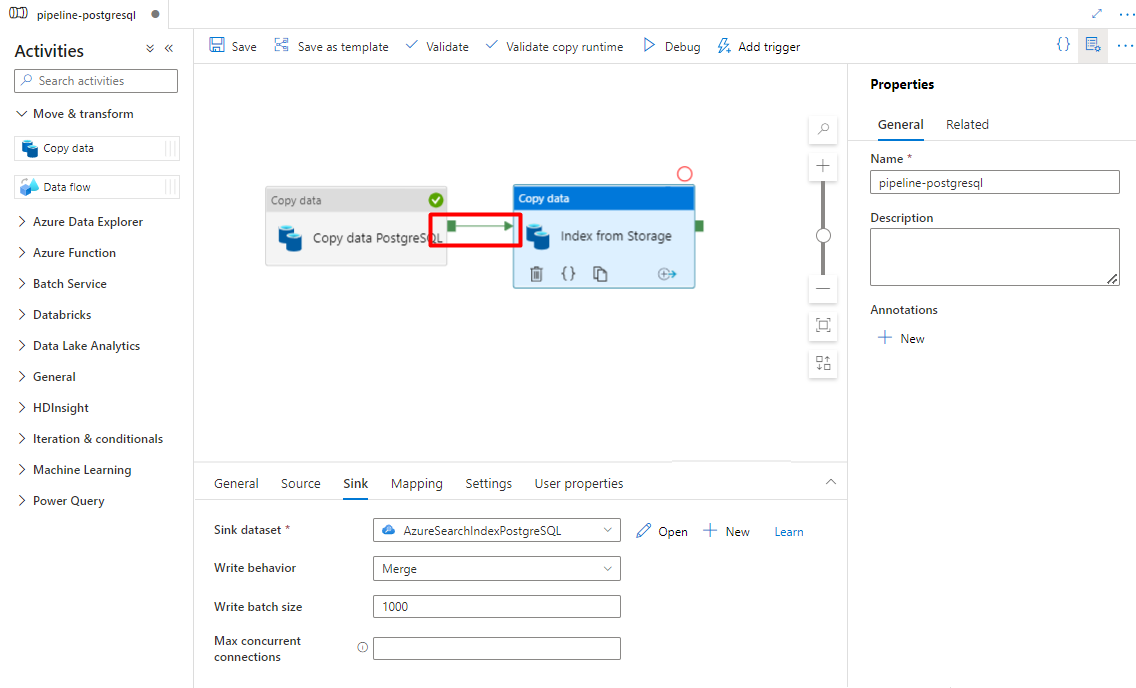
Passo 10: Adicionar um acionador de Pipeline
Selecione Adicionar acionador para agendar a execução do pipeline e selecione Novo/Editar.
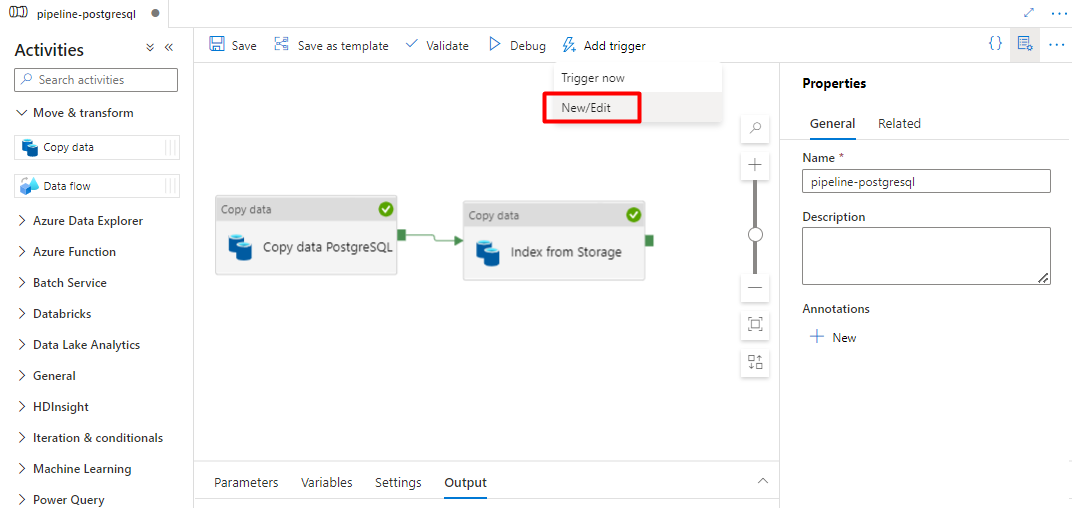
Na lista pendente Escolher acionador , selecione Novo.
Reveja as opções de acionador para executar o pipeline e selecione OK.
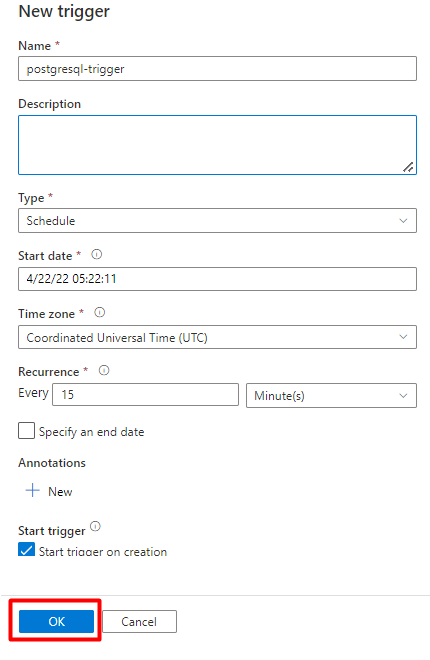
Selecione Guardar.
Selecione Publicar.
Conteúdo legado para pré-visualização do conector Power Query
É utilizado um conector de Power Query com um indexador de pesquisa para automatizar a ingestão de dados de várias origens de dados, incluindo as de outros fornecedores de cloud. Utiliza Power Query para obter os dados.
As origens de dados suportadas na pré-visualização incluem:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Objetos do Salesforce
- Relatórios do Salesforce
- Smartsheet
- Snowflake
Funcionalidade suportada
Power Query conectores são utilizados em indexadores. Um indexador no Azure Cognitive Search é um crawler que extrai dados e metadados pesquisáveis de uma origem de dados externa e preenche um índice com base em mapeamentos campo a campo entre o índice e a origem de dados. Por vezes, esta abordagem é referida como um "modelo de solicitação" porque o serviço extrai dados sem ter de escrever qualquer código que adicione dados a um índice. Os indexadores fornecem uma forma conveniente de os utilizadores indexarem conteúdo a partir da respetiva origem de dados sem terem de escrever o seu próprio crawler ou modelo push.
Os indexadores que referenciam Power Query origens de dados têm o mesmo nível de suporte para conjuntos de competências, agendas, lógica de deteção de alteração de marca de água elevada e a maioria dos parâmetros suportados por outros indexadores.
Pré-requisitos
Embora já não possa utilizar esta funcionalidade, esta tinha os seguintes requisitos durante a pré-visualização:
Azure Cognitive Search serviço numa região suportada.
Pré-visualizar registo. Esta funcionalidade tem de estar ativada no back-end.
Armazenamento de Blobs do Azure conta, utilizada como intermediário para os seus dados. Os dados irão fluir da origem de dados e, em seguida, para o Armazenamento de Blobs e, em seguida, para o índice. Este requisito só existe com a pré-visualização fechada inicial.
Disponibilidade regional
A pré-visualização só estava disponível nos serviços de pesquisa nas seguintes regiões:
- E.U.A. Central
- E.U.A. Leste
- E.U.A. Leste 2
- E.U.A. Centro-Norte
- Europa do Norte
- E.U.A. Centro-Sul
- E.U.A. Centro-Oeste
- Europa Ocidental
- E.U.A. Oeste
- E.U.A. Oeste 2
Limitações da pré-visualização
Esta secção descreve as limitações específicas da versão atual da pré-visualização.
A solicitação de dados binários da origem de dados não é suportada.
A sessão de depuração não é suportada.
Introdução à utilização do portal do Azure
O portal do Azure fornece suporte para os conectores Power Query. Ao amostrar dados e ler metadados no contentor, o assistente importar dados no Azure Cognitive Search pode criar um índice predefinido, mapear campos de origem para campos de índice de destino e carregar o índice numa única operação. Consoante o tamanho e a complexidade dos dados de origem, pode ter um índice de pesquisa de texto completo operacional em minutos.
O vídeo seguinte mostra como configurar um conector de Power Query no Azure Cognitive Search.
Passo 1 – Preparar os dados de origem
Certifique-se de que a origem de dados contém dados. O assistente de Importação de dados lê metadados e efetua a amostragem de dados para inferir um esquema de índice, mas também carrega dados da sua origem de dados. Se os dados estiverem em falta, o assistente irá parar e devolver e efetuar o erro.
Passo 2 – Iniciar o assistente para Importar dados
Depois de ser aprovado para a pré-visualização, a equipa do Azure Cognitive Search irá fornecer-lhe uma ligação de portal do Azure que utiliza um sinalizador de funcionalidade para que possa aceder aos conectores Power Query. Abra esta página e inicie o assistente a partir da barra de comandos na página Azure Cognitive Search serviço ao selecionar Importar dados.
Passo 3 – Selecionar a origem de dados
Existem algumas origens de dados que pode extrair dados desta pré-visualização. Todas as origens de dados que utilizam Power Query incluirão um "Powered By Power Query" no mosaico. Selecione a sua origem de dados.
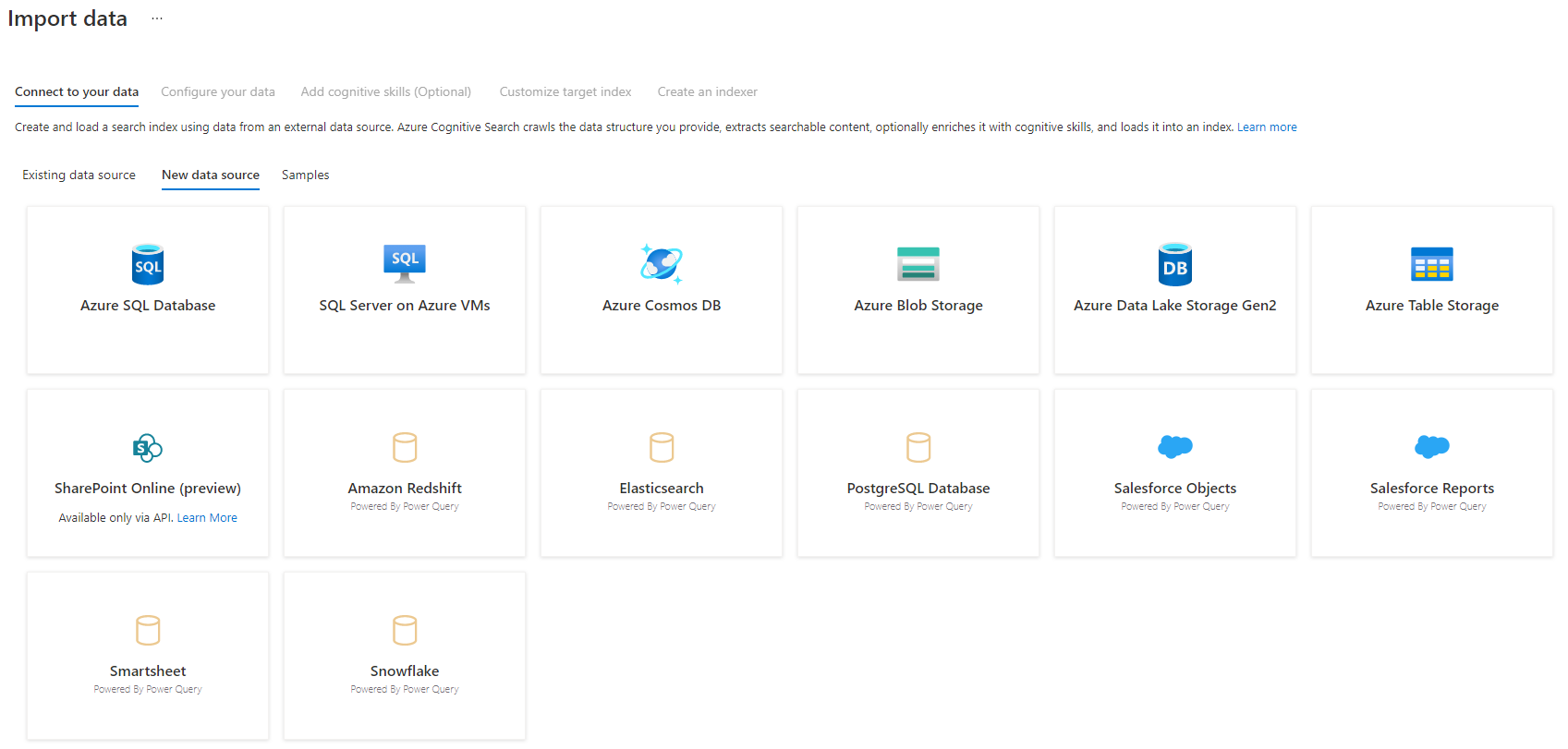
Depois de selecionar a origem de dados, selecione Seguinte: Configurar os dados para avançar para a secção seguinte.
Passo 4 – Configurar os seus dados
Neste passo, irá configurar a ligação. Cada origem de dados exigirá informações diferentes. Para algumas origens de dados, a documentação do Power Query fornece mais detalhes sobre como ligar aos seus dados.
Depois de fornecer as credenciais de ligação, selecione Seguinte.
Passo 5 – Selecionar os seus dados
O assistente de importação irá pré-visualizar várias tabelas que estão disponíveis na sua origem de dados. Neste passo, irá verificar uma tabela que contém os dados que pretende importar para o seu índice.
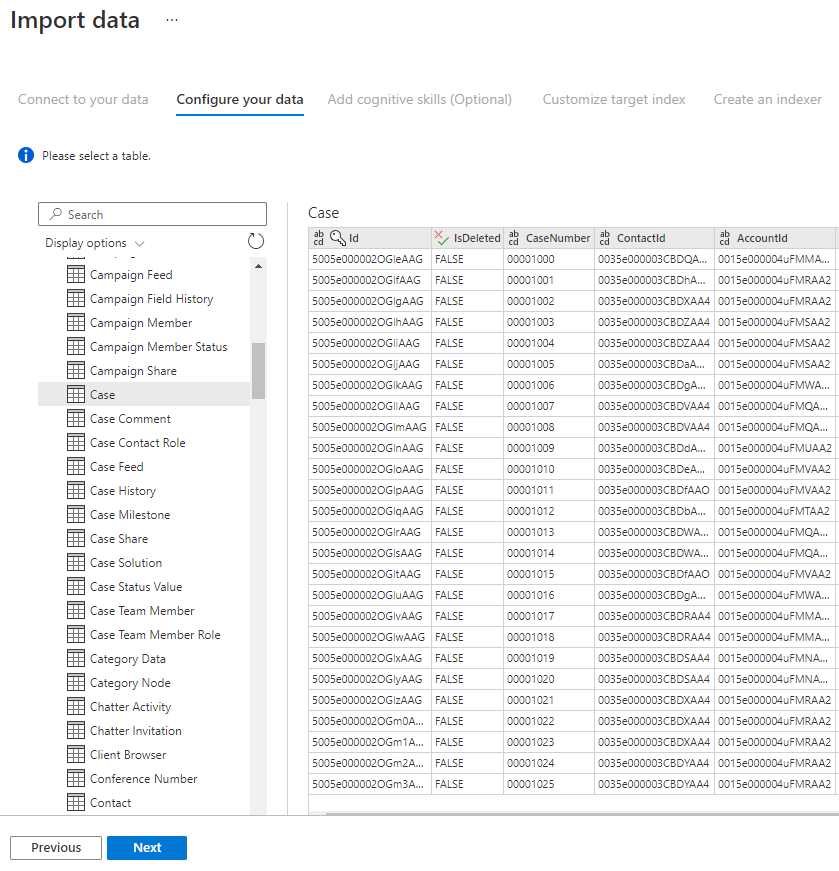
Depois de selecionar a tabela, selecione Seguinte.
Passo 6 – Transformar os seus dados (Opcional)
Power Query conectores fornecem-lhe uma experiência de IU avançada que lhe permite manipular os seus dados para que possa enviar os dados certos para o índice. Pode remover colunas, filtrar linhas e muito mais.
Não é necessário que transforme os seus dados antes de os importar para Azure Cognitive Search.
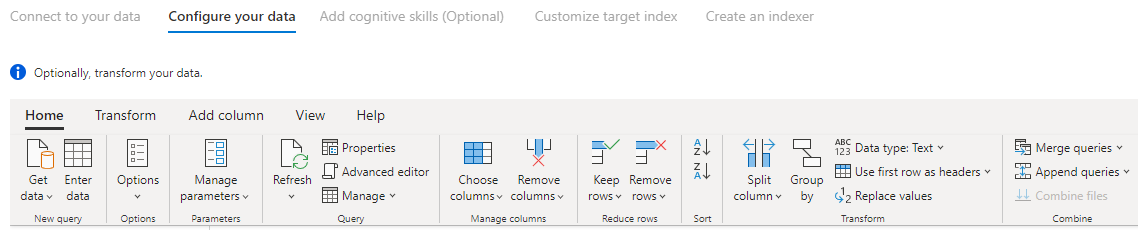
Para obter mais informações sobre como transformar dados com Power Query, veja Utilizar Power Query no Power BI Desktop.
Após a transformação dos dados, selecione Seguinte.
Passo 7 – Adicionar armazenamento de Blobs do Azure
A pré-visualização do conector Power Query requer atualmente que forneça uma conta de armazenamento de blobs. Este passo só existe com a pré-visualização fechada inicial. Esta conta de armazenamento de blobs servirá como armazenamento temporário para dados que se movem da origem de dados para um índice de Azure Cognitive Search.
Recomendamos que forneça uma conta de armazenamento de acesso completo cadeia de ligação:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Pode obter o cadeia de ligação do portal do Azure ao navegar para o painel > da conta de armazenamento Chaves de Definições > (para contas de armazenamento clássicas) ou chaves de Acesso de Definições > (para contas de armazenamento do Azure Resource Manager).
Depois de fornecer um nome de origem de dados e cadeia de ligação, selecione "Seguinte: Adicionar competências cognitivas (Opcional)".
Passo 8 – Adicionar competências cognitivas (Opcional)
O melhoramento de IA é uma extensão de indexadores que pode ser utilizada para tornar os seus conteúdos mais pesquisáveis.
Pode adicionar todos os melhoramentos que adicionam benefícios ao seu cenário. Quando terminar, selecione Seguinte: Personalizar índice de destino.
Passo 9 – Personalizar o índice de destino
Na página Índice, deverá ver uma lista de campos com um tipo de dados e uma série de caixas de verificação para definir atributos de índice. O assistente pode gerar uma lista de campos com base em metadados e ao amostrar os dados de origem.
Pode selecionar atributos em massa ao selecionar a caixa de verificação na parte superior de uma coluna de atributos. Selecione Recuperável e Pesquisável para todos os campos que devem ser devolvidos a uma aplicação cliente e sujeitos ao processamento de pesquisa de texto completo. Irá reparar que os números inteiros não são de texto completo ou pesquisáveis difusos (os números são avaliados literalmente e muitas vezes são úteis em filtros).
Veja a descrição dos atributos de índice e dos analisadores de idiomas para obter mais informações.
Dedique algum tempo a rever as suas seleções. Depois de executar o assistente, as estruturas de dados físicos são criadas e não poderá editar a maioria das propriedades destes campos sem remover e recriar todos os objetos.
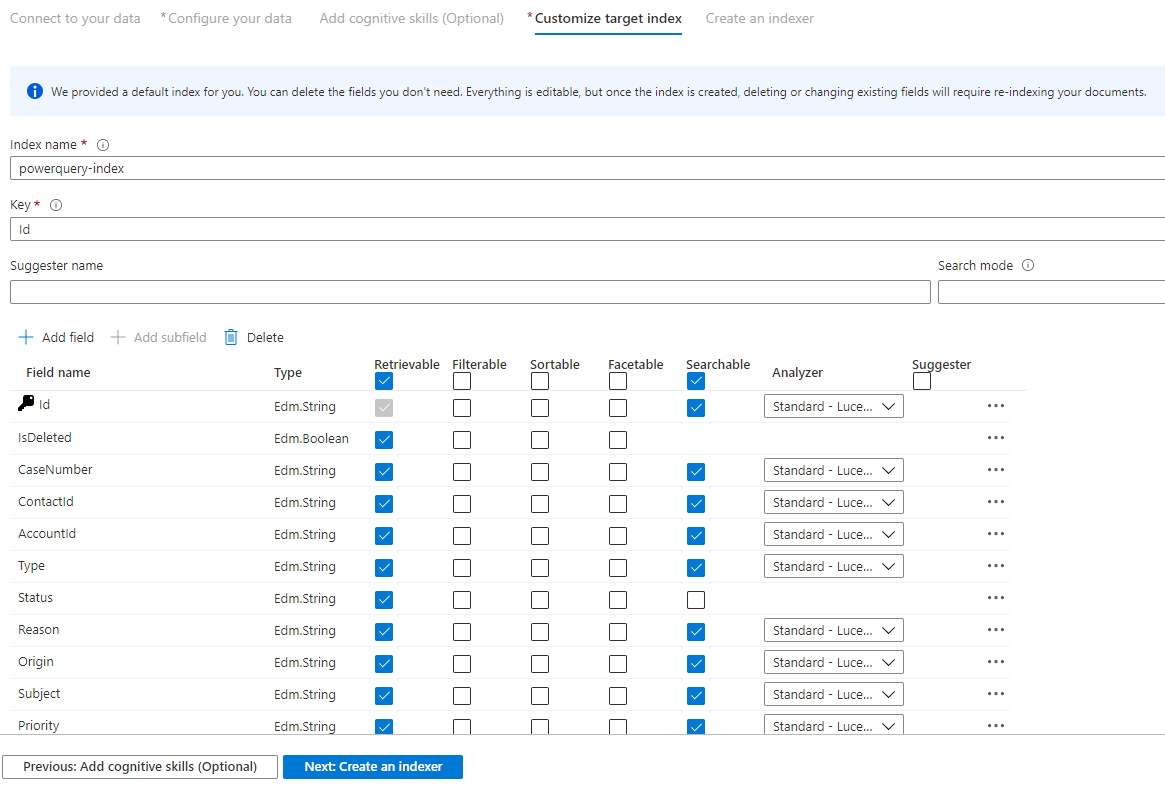
Quando terminar, selecione Seguinte: Criar um Indexador.
Passo 10 – Criar um indexador
O último passo cria o indexador. Atribuir um nome ao indexador permite-lhe existir como um recurso autónomo, que pode agendar e gerir independentemente do objeto de origem de dados e índice, criado na mesma sequência de assistente.
O resultado do assistente Importar dados é um indexador que pesquisa a sua origem de dados e importa os dados que selecionou para um índice no Azure Cognitive Search.
Ao criar o indexador, opcionalmente, pode optar por executar o indexador numa agenda e adicionar a deteção de alterações. Para adicionar a deteção de alterações, designe uma coluna "marca de água elevada".
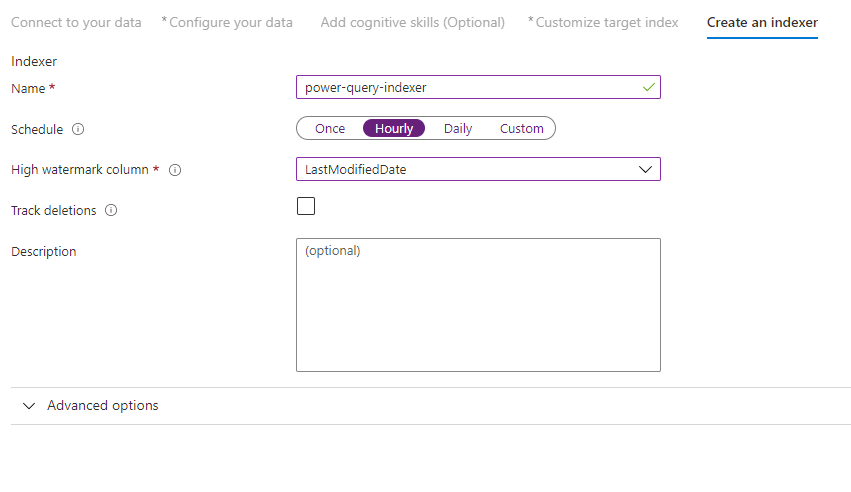
Depois de concluir o preenchimento desta página, selecione Submeter.
Política de Deteção de Alterações de Marca de Água Elevada
Esta política de deteção de alterações baseia-se numa coluna de "marca de água elevada" que captura a versão ou hora em que uma linha foi atualizada pela última vez.
Requisitos
- Todas as inserções especificam um valor para a coluna.
- Todas as atualizações para um item também alteram o valor da coluna.
- O valor desta coluna aumenta com cada inserção ou atualização.
Nomes de colunas não suportados
Os nomes dos campos num índice de Azure Cognitive Search têm de cumprir determinados requisitos. Um destes requisitos é que alguns carateres como "/" não são permitidos. Se um nome de coluna na base de dados não cumprir estes requisitos, a deteção do esquema de índice não reconhecerá a coluna como um nome de campo válido e não verá essa coluna listada como um campo sugerido para o índice. Normalmente, a utilização de mapeamentos de campos resolveria este problema, mas os mapeamentos de campos não são suportados no portal.
Para indexar conteúdos de uma coluna na tabela que tenha um nome de campo não suportado, mude o nome da coluna durante a fase "Transformar os seus dados" do processo de importação de dados. Por exemplo, pode mudar o nome de uma coluna com o nome "Código de faturação/código postal" para "código postal". Ao mudar o nome da coluna, a deteção do esquema de índice irá reconhecê-la como um nome de campo válido e adicioná-la como uma sugestão à definição do índice.
Passos seguintes
Este artigo explica como extrair dados com os conectores Power Query. Uma vez que esta funcionalidade de pré-visualização foi descontinuada, também explica como migrar soluções existentes para um cenário suportado.
Para saber mais sobre indexadores, veja Indexadores no Azure Cognitive Search.