Descrição geral dos tipos de modelo no Microsoft Syntex
Aplica-se a: ✓ Todos os modelos personalizados | ✓ Todos os modelos pré-criados
Compreender os seus conteúdos no Microsoft Syntex começa com os modelos de processamento de documentos. Os modelos de processamento de documentos permitem-lhe identificar e classificar documentos carregados para bibliotecas de documentos do SharePoint e, em seguida, extrair as informações de que precisa de cada ficheiro.
Quando aplicado a uma biblioteca de documentos do SharePoint, o modelo é associado a um tipo de conteúdo e tem colunas para armazenar as informações que estão a ser extraídas. O tipo de conteúdo que criar é armazenado na galeria de tipos de conteúdo do SharePoint. Também pode optar por utilizar tipos de conteúdo existentes para utilizar o respetivo esquema.
O Syntex utiliza modelos personalizados e modelos pré-criados.
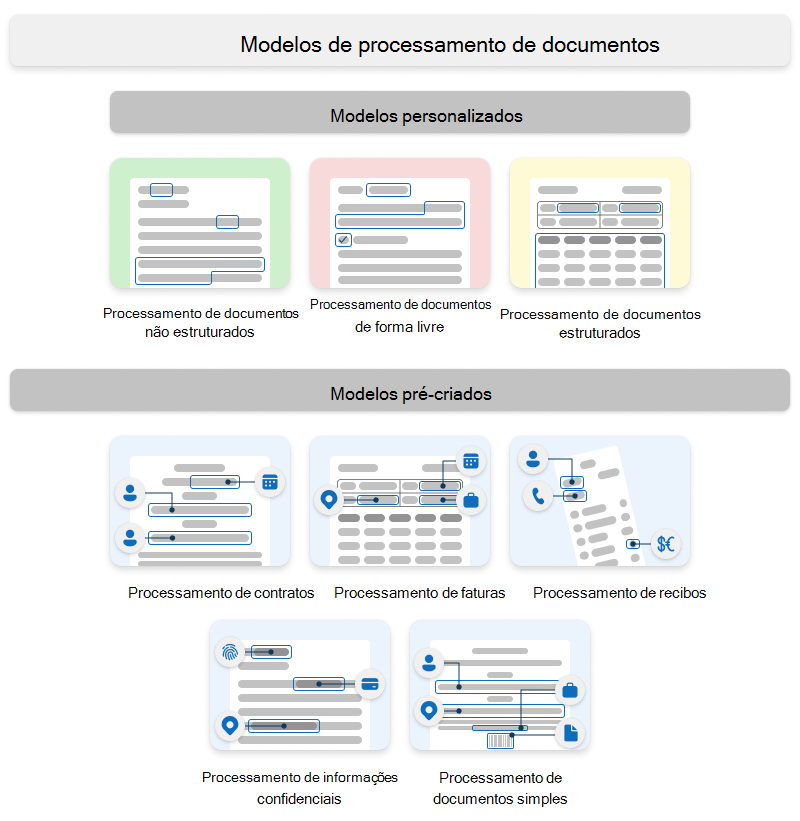
Os modelos podem ser modelos empresariais, criados num centro de conteúdos ou modelos locais, que são criados no seu site do SharePoint local.
Modelos personalizados
O tipo de modelo personalizado que escolher dependerá dos tipos de ficheiros que utiliza, do formato e da estrutura dos ficheiros e do local onde pretende aplicar o modelo.
Os modelos personalizados incluem:
- Processamento de documentos não estruturados
- Processamento de documentos de forma livre
- Processamento de documentos estruturados
Para ver as diferenças lado a lado nos modelos personalizados, veja Comparar modelos personalizados.
Processamento de documentos não estruturados
Utilize o modelo de processamento de documentos não estruturado para classificar automaticamente documentos e extrair informações dos mesmos. Funciona melhor com documentos não estruturados, como cartas ou contratos. Estes documentos têm de ter texto que possa ser identificado com base em expressões ou padrões. O texto identificado designa o tipo de ficheiro que é (a classificação) e o que pretende extrair (os respetivos extratores).
Por exemplo, um documento não estruturado pode ser uma carta de renovação de contrato que pode ser escrita de formas diferentes. No entanto, as informações existem consistentemente no corpo de cada documento de renovação do contrato, como a cadeia de texto "Data de início do serviço de" seguida de uma data real.
Este tipo de modelo suporta a maior variedade de tipos de ficheiro e suporta mais de 40 idiomas.
Quando criar um modelo de processamento de documentos não estruturado, utilize a opção Modelo de classe única .
Para obter mais informações, veja Descrição geral do processamento de documentos não estruturados.
Processamento de documentos de forma livre
Utilize o modelo de processamento de documentos de forma livre para extrair automaticamente informações de documentos não estruturados e de forma livre, como cartas e contratos onde as informações podem aparecer em qualquer parte do documento.
Os modelos de processamento de documentos de forma livre utilizam o Microsoft Power Apps AI Builder para criar e preparar modelos no Syntex.
Nota
O modelo de processamento de documentos de forma livre ainda não está disponível em algumas regiões. Para obter mais informações, veja Disponibilidade de funcionalidades por região.
Uma vez que a sua organização recebe cartas e documentos em grandes quantidades de várias origens, como correio, fax e e-mail, processar estes documentos e introduzi-los manualmente numa base de dados pode demorar bastante tempo. Ao utilizar a IA para extrair o texto e outras informações destes documentos, este modelo automatiza este processo.
Este tipo de modelo é a melhor opção para documentos em ficheiros PDF ou de imagem quando não precisa de uma classificação automática do tipo de documento e suporta mais de 40 idiomas.
Quando criar um modelo de processamento de documentos de forma livre, utilize a opção Modelo de extração de forma livre.
Para obter mais informações, veja Descrição geral do processamento de documentos estruturados e de forma livre.
Processamento de documentos estruturados
Utilize o modelo de processamento de documentos estruturado para identificar automaticamente valores de campos e tabelas. Funciona melhor para documentos estruturados ou semiestruturados, como formulários e faturas.
Os modelos de processamento de documentos estruturados utilizam o processamento de documentos do Microsoft Power Apps AI Builder (anteriormente conhecido como processamento de formulários) para criar e preparar modelos no Syntex.
Este tipo de modelo suporta a maior variedade de idiomas e é preparado para compreender o esquema do formulário a partir de documentos de exemplo e, em seguida, aprende a procurar os dados que precisa de extrair de localizações semelhantes. Forms geralmente têm um esquema mais estruturado onde as entidades estão na mesma localização (por exemplo, um número de segurança social num formulário fiscal).
Quando criar um modelo de processamento de documentos estruturado, utilize a opção Modelo de extração estruturada .
Para obter mais informações, veja Descrição geral do processamento de documentos estruturados e de forma livre.
Modelos pré-construídos
Se não precisar de criar um modelo personalizado, pode utilizar um modelo de processamento de documentos pré-criado que já tenha sido preparado para documentos estruturados específicos.
Os modelos pré-criados incluem:
- Processamento de contratos
- Processamento de faturas
- Processamento de recibos
- Processamento de informações confidenciais
- Processamento de documentos simples
Os modelos pré-criados são preparados previamente para reconhecer documentos e as informações estruturadas nos documentos. Em vez de ter de criar um novo modelo personalizado do zero, pode iterar um modelo pré-preparado existente para adicionar campos específicos que se adequam às necessidades da sua organização.
Processamento de contratos
O modelo de processamento de contratos pré-criado analisa e extrai informações importantes de documentos contratuais. A API analisa contratos em vários formatos e extrai informações do contrato de chave, como o nome do cliente ou da parte, o endereço de faturação, a jurisdição e a data de expiração.
Para obter mais informações sobre modelos de processamento de contratos, veja Utilizar um modelo pré-criado para extrair informações de contratos.
Processamento de faturas
O modelo de processamento de faturas pré-criado analisa e extrai informações importantes das faturas de vendas. A API analisa as faturas em vários formatos e extrai as informações da fatura da chave, como o nome do cliente, o endereço de faturação, a data para conclusão e o montante em dívida.
Para obter mais informações sobre os modelos de processamento de faturas, veja Utilizar um modelo pré-criado para extrair informações de faturas.
Processamento de recibos
O modelo de processamento de recibos pré-criado analisa e extrai informações importantes dos recibos de vendas. A API analisa recibos impressos e manuscritos e extrai informações de recibos de chave, como o nome do comerciante, o número de telefone do comerciante, a data de transação, o imposto e o total da transação.
Para obter mais informações sobre os modelos de processamento de recibos, veja Utilizar um modelo pré-criado para extrair informações de recibos.
Processamento de informações confidenciais
O modelo de processamento de informações confidenciais pré-criado analisa, deteta e extrai informações importantes de documentos. A API analisa contratos em vários formatos e extrai informações confidenciais importantes, tais como números de segurança social, números de contas financeiras, números de identificação de cartas de condução e outras informações pessoais.
Para obter mais informações sobre modelos de processamento de informações confidenciais, veja Utilizar um modelo pré-criado para detetar informações confidenciais de documentos.
Processamento de documentos simples
O modelo de processamento de documentos simples pré-criado oferece uma solução flexível e pré-concebida para extrair pares chave-valor, marcas de seleção e entidades nomeadas de documentos estruturados básicos. Ao contrário de outros modelos pré-criados com esquemas fixos, este modelo pode identificar chaves que outras pessoas podem perder, fornecendo uma alternativa valiosa à etiquetagem e preparação de modelos personalizados. Este modelo também suporta códigos de barras e deteção de idioma.
Para obter mais informações sobre modelos de processamento de documentos simples, veja Utilizar um modelo pré-criado para detetar informações confidenciais de documentos.