Resolver problemas de soluções de dados de cuidados de saúde no Microsoft Fabric
Este artigo fornece informações sobre alguns problemas ou erros que poderá ver ao utilizar soluções de dados de cuidados de saúde no Microsoft Fabric e como resolvê-los. O artigo também inclui algumas orientações de monitorização de aplicações.
Se o problema persistir depois de seguir as orientações deste artigo, crie um pedido de suporte para a equipa de suporte.
Resolução de problemas de implementação
Às vezes, pode encontrar problemas intermitentes ao implementar soluções de dados de cuidados de saúde na área de trabalho do Fabric. Aqui estão alguns problemas comummente observados e soluções alternativas para corrigi-los:
A criação de soluções falha ou demora demasiado tempo.
Erro: A criação da solução de cuidados de saúde está em curso durante mais de 5 minutos e/ou falha.
Causa: este erro ocorre se existir outra solução de cuidados de saúde que partilhe o mesmo nome ou se tiver sido eliminada recentemente.
Resolução: se eliminou recentemente uma solução, aguarde durante 30 a 60 minutos antes de tentar outra implementação.
Falha na implementação da capacidade
Erro: as capacidades das soluções de dados de cuidados de saúde não são implementadas.
Resolução: verifique se a capacidade está listada na secção Gerir recursos implementados.
- Se a capacidade não estiver listada na tabela, tente implementá-la novamente. Selecione o mosaico de capacidade e, em seguida, selecione o botão Implementar na área de trabalho.
- Se o recurso estiver listado na tabela com o valor de estado Falha na implementação volte a implementar a capacidade. Como alternativa, pode criar um novo ambiente de soluções de dados de cuidados de saúde e voltar a implementar o recurso aí.
Resolver problemas de tabelas não identificadas
Quando as tabelas delta são criadas no lakehouse pela primeira vez, podem aparecer temporariamente como "não identificadas" ou vazias na visualização do Explorador Lakehouse. No entanto, devem aparecer corretamente na pasta tabelas após alguns minutos.

Voltar a executar pipeline de dados
Para voltar a executar dados de amostra de ponto a ponto, siga estes passos:
Execute uma instrução Spark SQL de um bloco de notas para eliminar todas as tabelas de um lakehouse. Eis um exemplo:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Use o Explorador de Ficheiros do OneLake para se ligar ao OneLake no Explorador de Ficheiros do Windows.
Navegue até a pasta da área de trabalho no Explorador de Ficheiros do Windows. Em
<solution_name>.HealthDataManager\DMHCheckpoint, elimine todas as pastas correspondentes em<lakehouse_id>/<table_name>. Como alternativa, também pode usar Microsoft Spark Utilities (MSSparkUtils) for Fabric para eliminar a pasta.Execute novamente os pipelines de dados, começando com a ingestão de dados clínicos no lakehouse bronze.
Monitorizar aplicações Apache Spark com o Azure Log Analytics
Os registos de aplicações do Apache Spark são enviados para uma instância da área de trabalho do Azure Log Analytics que pode consultar. Use esta consulta Kusto de exemplo para filtrar os registos específicos para soluções de dados de cuidados de saúde:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Os registos da consola do bloco de notas também registam o RunId de cada execução. Pode usar esse valor para recuperar registos para uma execução específica, conforme mostrado na seguinte consulta de exemplo:
AppTraces
| where Properties['RunId'] == "<RunId>"
Para obter informações gerais de monitorização, consulte Usar o hub de Monitorização do Fabric.
Utilizar o explorador de ficheiros do OneLake
A aplicação explorador de ficheiros do OneLake integra-se totalmente com o explorador de ficheiros do Windows. Pode usar o explorador de ficheiros do OneLake para ver qualquer pasta ou ficheiro implementado na sua área de trabalho do Fabric. Também pode ver os dados de exemplo, os ficheiro e pastas do OneLake e os ficheiros do ponto de verificação.
Utilize Explorador de Armazenamento do Azure
Também pode usar o Explorador de Armazenamento do Azure para:
- Aceda aos ficheiros do OneLake nos seus lakehouses do Fabric
- Ligue-se ao caminho do ficheiro URL do OneLake
Reponha a versão do runtime do Spark na área de trabalho do Fabric
Por predefinição, todas as novas áreas de trabalho do Fabric usam a versão de runtime mais recente do Fabric, que é atualmente Runtime 1.3. No entanto, as soluções de dados de cuidados de saúde suportam apenas o Runtime 1.2.
Portanto, depois de implementar soluções de dados de cuidados de saúde na sua área de trabalho, verifique se a versão runtime do Fabric predefinida está definida como Runtime 1.2 (Apache Spark 3.4 e Delta Lake 2.4). Caso contrário, o pipeline de dados e as execuções do bloco de notas podem falhar. Para obter mais informações, consulte Suporte a vários tempos de execução no Fabric.
Siga estes passos para rever/atualizar a versão de runtime do Fabric:
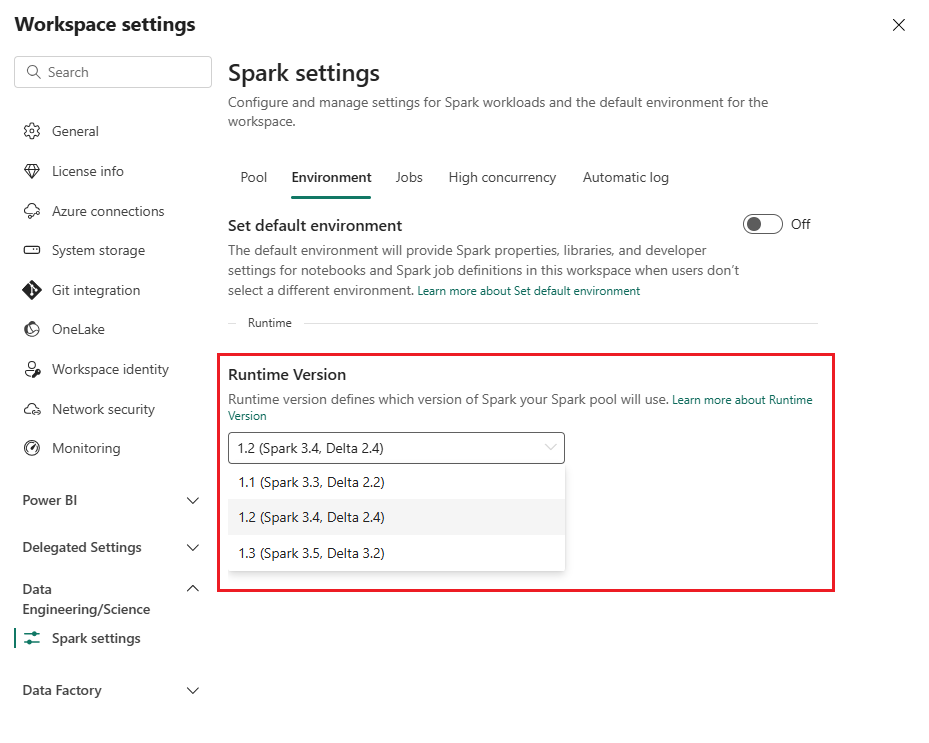
Aceda à área de trabalho das soluções de dados de cuidados de saúde e selecione Definições da área de trabalho.
Na página de definições da área de trabalho, expanda a caixa suspensa Engenharia de Dados/Ciência e selecione Definições do Spark.
No separador Ambiente, atualize o valor de Versão do runtime para 1.2 (Spark 3.4, Delta 2.4) e guarde as alterações.

Atualizar a interface do utilizador do Fabric e o explorador de ficheiros do OneLake
Às vezes, pode notar que a interface do utilizador do Fabric ou o o explorador de ficheiros do OneLake nem sempre atualiza o conteúdo após cada execução do bloco de notas. Se não vir o resultado esperado na interface do utilizador depois de executar qualquer passo de execução (como criar uma nova pasta ou lakehouse ou ingerir novos dados numa tabela), tente atualizar o artefacto (tabela, lakehouse, pasta). Muitas vezes, essa atualização pode resolver discrepâncias antes de explorar outras opções ou investigar mais.