Preparar os conjuntos de dados públicos em conjuntos de dados SDOH - Transformações (pré-visualização)
[Este artigo é uma documentação de pré-lançamento e está sujeito a alterações.]
Os conjuntos de dados públicos SDOH contêm dados agregados de determinantes sociais da saúde (SDOH) publicados por agências governamentais e outras fontes oficiais, como universidades. Estes conjuntos de dados consolidam vários parâmetros SDOH em níveis geográficos, como estado, condado ou código postal. Conjuntos de dados SDOH - Transformações (visualização) permite-lhe ingerir estes conjuntos de dados de nível geográfico no formato CSV (Valores separados por vírgula) ou XLSX (Folha de cálculo Open XML do Excel) e normalizá-los num modelo de dados personalizado.
A versão de pré-visualização fornece os seguintes oito conjuntos de dados SDOH de amostra de vários domínios SDOH para ajudá-lo a executar pipelines de dados e explorar transformações de dados através das camadas do lakehouse de bronze, prata e ouro:
Atlas do Ambiente Alimentar da USDA: Inclui fatores, como proximidade de lojas/restaurantes, preços de alimentos, programas de assistência nutricional e características da comunidade. Estes fatores afetam as escolhas alimentares, a qualidade da dieta e, em última análise, os resultados de saúde.
Atlas Rural da USDA: Oferece estatísticas sobre fatores socioeconómicos, como pessoas, empregos, classificações de condados, rendimentos e veteranos.
Dados SDOH da AHRQ: Fornece detalhes de cinco domínios SDOH principais:
- Contexto social, como idade, raça/etnia, estado de veterano.
- Contexto económico, como o rendimento, a taxa de desemprego.
- Educação
- Infraestrutura física, como habitação, criminalidade, transporte.
- Contexto dos cuidados de saúde, como os seguros de saúde.
Índice de Acessibilidade de Localização: Estima os custos de habitação e transporte do agregado familiar ao nível do bairro.
Índice de Justiça Ambiental: Agrega dados de várias fontes para classificar os impactos cumulativos da injustiça ambiental na saúde para cada setor censitário.
Nível de Escolaridade ACS: Fornece informações sobre a educação em áreas geográficas, derivadas de um grande inquérito demográfico contínuo.
SEIFA Australiana: Combina dados do censo australiano, como rendimentos, educação, emprego e habitação para resumir as características socioeconómicas de uma área.
Índices de Privação do Reino Unido: Uma medida socioeconómica amplamente utilizada no Reino Unido para avaliar a pobreza em pequenas áreas, abrangendo várias dimensões.
Em que:
- USDA: Departamento de Agricultura dos Estados Unidos
- AHRQ: Agência de Investigação e Qualidade em Saúde
- ACS: Inquérito à Comunidade Americana
- SEIFA: Índices Socioeconómicos por Áreas
Importante
Estes conjuntos de dados não são apenas amostras, mas conjuntos de dados completos e reais publicados pelas respetivas organizações. Fornecem uma representação precisa dos perfis SDOH das suas áreas geográficas. Tenha cuidado ao modificá-los, pois são publicações oficiais de agências federais.
Estrutura de pastas
A zona de destino para conjuntos de dados SDOH - Transformações (pré-visualização) inclui três pastas: Ingerir, Processar e Falhas. Para saber mais sobre estas pastas, consulte Estrutura unificada de pastas.
Preparar os conjuntos de dados SDOH antes da ingestão
Antes de ingerir conjuntos de dados públicos SDOH, certifique-se de que estão prontos para uma ingestão bem-sucedida. As seguintes secções apresentam dois cenários:
- Utilize o seu próprio conjunto de dados
- Utilize o conjunto de dados de amostra
Utilize o seu próprio conjunto de dados
Os conjuntos de dados públicos SDOH variam significativamente entre as organizações de publicação em formato, volume e estrutura. Não têm um padrão estabelecido para recolher e trocar as informações obtidas. Portanto, unificá-los numa forma comum é essencial antes de representá-los num modelo de dados.
Para ingerir e transformar um conjunto de dados público SDOH à sua escolha, adicione as seguintes três informações principais:
Esquema: Devido à ausência de um conjunto padrão de códigos para obter dados SDOH, compreender o significado de cada campo é um desafio. Para resolver esse problema, crie um dicionário de dados para o conjunto de dados adicionando uma nova folha denominada Esquema (se o conjunto de dados estiver no formato XLSX) ou crie um novo ficheiro CSV (se o conjunto de dados estiver no formato CSV) com as colunas apresentadas no exemplo a seguir:
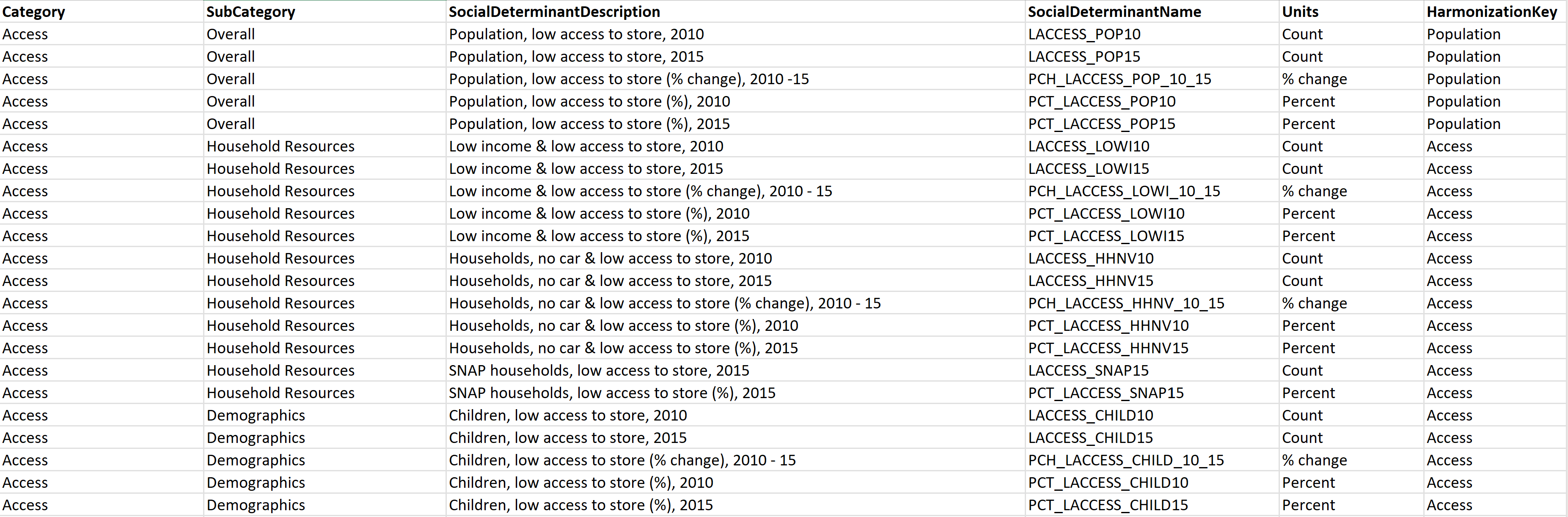
DataSetMetadata: Como os conjuntos de dados SDOH vêm de editores diferentes, registar os principais detalhes sobre o conjunto de dados é crucial. Adicione uma nova folha denominada DataSetMetadata (se o conjunto de dados estiver no formato XLSX) ou crie um novo ficheiro CSV (se o conjunto de dados estiver no formato CSV) com as colunas apresentadas no exemplo a seguir:

LocationConfiguration: Diferentes áreas geográficas definem e organizam dados de localização de várias maneiras. Para ajudar os pipelines SDOH a compreender a estrutura geográfica do conjunto de dados, adicione uma nova folha denominda LocationConfiguration (se o conjunto de dados estiver no formato XLSX) ou crie um novo ficheiro CSV (se o conjunto de dados estiver no formato CSV) com as colunas apresentadas no exemplo a seguir:
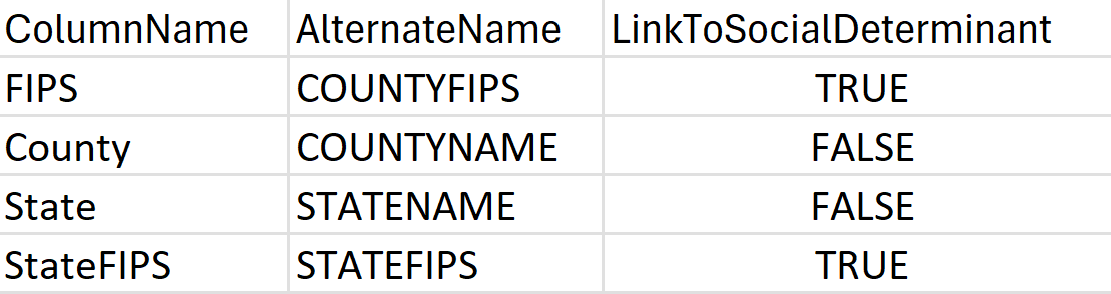



Além disso:
- Pode consultar a estrutura dos conjuntos de dados SDOH de amostra para preencher as informações necessárias, como categoria determinante social, metadados e chave de harmonização.
- Se preferir não ingerir determinados campos do conjunto de dados original, remova-os da folha de dados ou deixe os detalhes em branco na folha de esquema. Em ambos os casos, não são incluídos no modelo de dados de prata.
- Os conjuntos de dados com o mesmo nome, data de publicação e editor são tratados como duplicados.
Utilize o conjunto de dados de amostra
Os conjuntos de dados SDOH de amostra fornecidos com as soluções de dados de cuidados de saúde vêm pré-preenchidos com todas as informações de pré-requisito e estão disponíveis no seu OneLake. Pode extraí-los localmente.
Carregar conjuntos de dados para a área de trabalho do Fabric
Quando os conjuntos de dados estiverem prontos, escolha uma das duas opções a seguir para carregá-los. Pode usar a Opção 2 apenas se estiver a usar o conjunto de dados de amostra fornecido com os conjuntos de dados SDOH - Transformações (pré-visualização).
- Opção 1: Carregar manualmente os conjuntos de dados.
- Opção 2: Usar um script para carregar os conjuntos de dados.
Carregar manualmente os conjuntos de dados
No seu ambiente de soluções de dados de cuidados de saúde, selecione o lakehouse healthcare#_msft_bronze.
Abra a pasta Ingerir. Para mais informações, consulte Descrições das pastas.
Selecione as reticências (...) ao lado do nome da pasta e selecione Carregar pasta.
Carregue os conjuntos de dados do seu sistema local. Use o Explorador de ficheiros do OneLake para localizar os conjuntos de dados no seguinte caminho:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset.Atualize a pasta Ingerir. Agora deve conseguir ver os ficheiros de conjunto de dados dentro da subpasta SDOH.
Usar um script para carregar os conjuntos de dados
Importante
Utilize esta opção apenas se estiver a utilizar o conjunto de dados de amostra fornecido.
Aceda à área de trabalho do Fabric das soluções de dados de cuidados de saúde.
Selecione + Novo item.
No painel Novo item, pesquise e selecione Bloco de notas.
Copie o seguinte fragmento de código para o bloco de notas:
workspace_id = '<workspace_id>' # Workspace ID. Retrieve the value from the healthcare#_msft_config_notebook. one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint. Retrieve the value from the healthcare#_msft_config_notebook. solution_id = "<solution_id>" # Solution ID. Retrieve the value from the healthcare#_msft_config_notebook. bronze_lakehouse_id = "<bronze_lakehouse_id>" # To locate the bronze lakehouse ID, open the bronze lakehouse and check the URL in the browser's address bar: https://{baseurl}/lakehouse/{GUID}/details). The {GUID} value in the URL is the bronze lakehouse ID. def copy_source_files_and_folders(source_path, destination_path): # List the contents of the source directory source_contents = mssparkutils.fs.ls(source_path) # List the contents of the destination directory try: destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} except Exception as e: print(f"Destination path {destination_path} does not exist or is empty. Creating the path.") destination_files = {} mssparkutils.fs.mkdirs(destination_path) # Copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" if item.isDir: # Recursively copy the contents of the directory copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # Define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_id}@{one_lake_endpoint}/{solution_id}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/XLSX" # Copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Execute o bloco de notas. Os conjuntos de dados SDOH de amostra agora são movidos para a localização designada na pasta Ingerir.
Os conjuntos de dados SDOH estão agora prontos para ingestão.