Ingerir dados no OneLake e analisar com o Azure Databricks
Neste guia, você irá:
Crie um pipeline em um espaço de trabalho e ingira dados em seu OneLake no formato Delta.
Leia e modifique uma tabela Delta no OneLake com o Azure Databricks.
Pré-requisitos
Antes de começar, você deve ter:
Um espaço de trabalho com um item Lakehouse.
Um espaço de trabalho premium do Azure Databricks. Apenas os espaços de trabalho premium do Azure Databricks suportam a passagem de credenciais do Microsoft Entra. Ao criar seu cluster, habilite a passagem de credenciais do Armazenamento do Azure Data Lake nas Opções Avançadas.
Um conjunto de dados de exemplo.
Ingerir dados e modificar a tabela Delta
Navegue até a sua casa do lago no serviço do Power BI e selecione Obter dados e, em seguida, selecione Novo pipeline de dados.
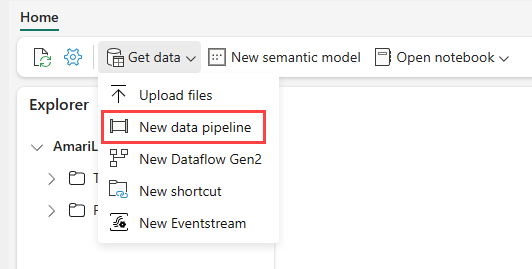
No prompt Novo Pipeline, insira um nome para o novo pipeline e selecione Criar.
Para este exercício, selecione os dados de exemplo NYC Taxi - Green como a fonte de dados e, em seguida, selecione Avançar.
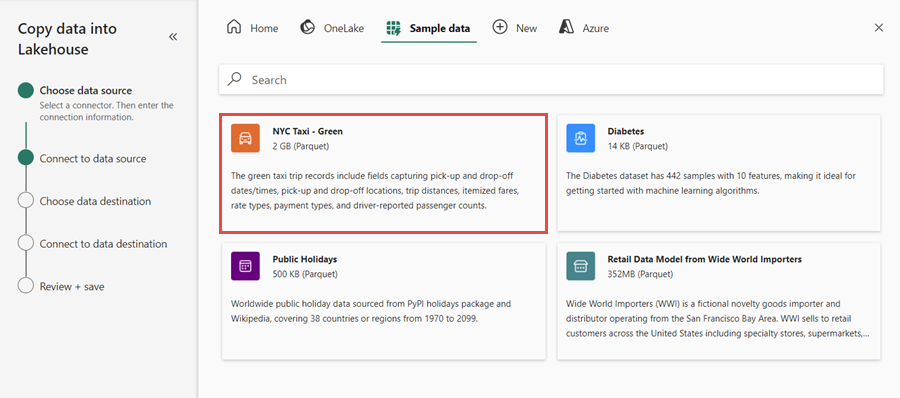
No ecrã de pré-visualização, selecione Seguinte.
Para o destino dos dados, selecione o nome da casa do lago que você deseja usar para armazenar os dados da tabela OneLake Delta. Você pode escolher uma casa de lago existente ou criar uma nova.
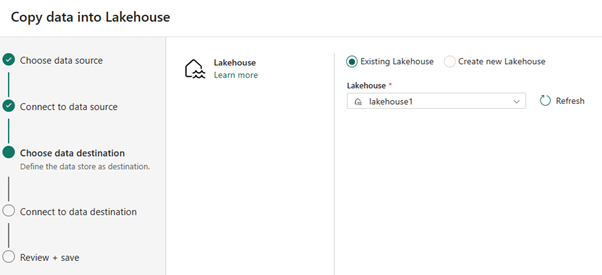
Selecione onde deseja armazenar a saída. Escolha Tabelas como a pasta raiz e digite "nycsample" como o nome da tabela.
No ecrã Rever + Guardar, selecione Iniciar transferência de dados imediatamente e, em seguida, selecione Guardar + Executar.
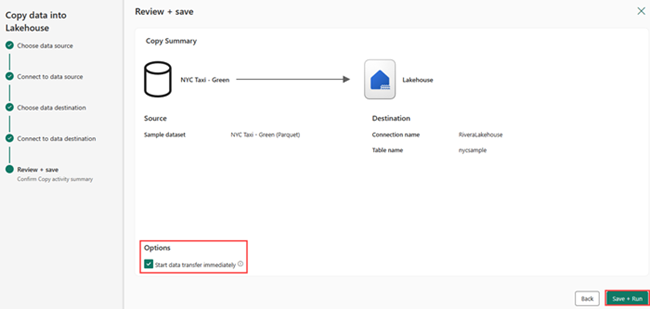
Quando o trabalho estiver concluído, navegue até a casa do lago e visualize a tabela delta listada na pasta /Tables.
Clique com o botão direito do mouse no nome da tabela criada, selecione Propriedades e copie o caminho do Sistema de Arquivos de Blob do Azure (ABFS).
Abra seu bloco de anotações do Azure Databricks. Leia a tabela Delta no OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Atualize os dados da tabela Delta alterando um valor de campo.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;