Transforme dados com o Apache Spark e consulte com SQL
Neste guia, você irá:
Carregue dados para o OneLake com o explorador de arquivos do OneLake.
Use um bloco de anotações de malha para ler dados no OneLake e gravar novamente como uma tabela Delta.
Analise e transforme dados com o Spark usando um bloco de anotações Fabric.
Consulte uma cópia dos dados no OneLake com SQL.
Pré-requisitos
Antes de começar, deve:
Transfira e instale o explorador de ficheiros OneLake.
Crie um espaço de trabalho com um item Lakehouse.
Faça o download do conjunto de dados WideWorldImportersDW. Você pode usar o Gerenciador de Armazenamento do Azure para se conectar e
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_citybaixar o conjunto de arquivos csv. Ou você pode usar seus próprios dados csv e atualizar os detalhes conforme necessário.
Nota
Sempre crie, carregue ou crie um atalho para dados do Delta-Parquet diretamente na seção Tabelas da casa do lago. Não aninhar suas tabelas em subpastas na seção Tabelas, pois a casa do lago não a reconhecerá como uma tabela e a rotulará como Não identificada.
Carregar, ler, analisar e consultar dados
No explorador de arquivos do OneLake, navegue até sua casa do lago e, sob o
/Filesdiretório, crie um subdiretório chamadodimension_city.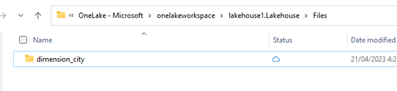
Copie seus arquivos csv de exemplo para o diretório OneLake usando o explorador
/Files/dimension_cityde arquivos OneLake.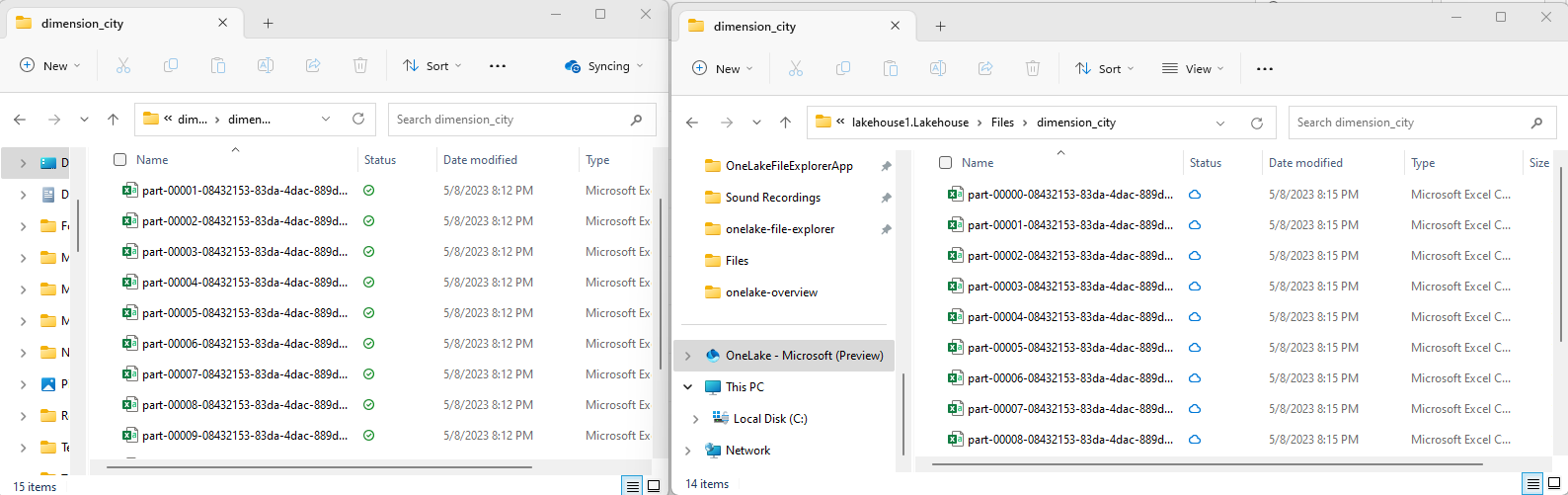
Navegue até a sua casa do lago no serviço do Power BI e exiba seus arquivos.
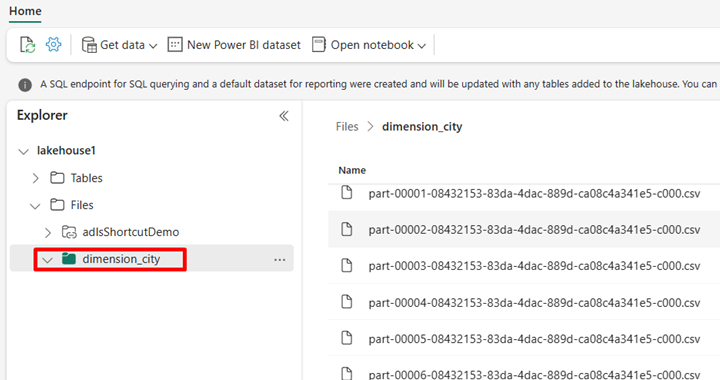
Selecione Abrir bloco de notas e, em seguida , Novo bloco de notas para criar um bloco de notas.
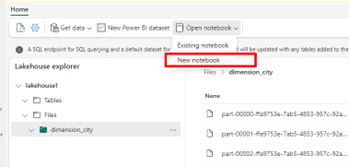
Usando o bloco de anotações de malha, converta os arquivos CSV para o formato Delta. O trecho de código a seguir lê dados do diretório
/Files/dimension_citycriado pelo usuário e os converte em uma tabeladim_cityDelta.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Para ver a nova tabela, atualize a exibição do
/Tablesdiretório.
Consulte sua tabela com o SparkSQL no mesmo bloco de anotações de malha.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Modifique a tabela Delta adicionando uma nova coluna chamada newColumn com número inteiro do tipo de dados. Defina o valor de 9 para todos os registros desta coluna recém-adicionada.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;Você também pode acessar qualquer tabela Delta no OneLake por meio de um ponto de extremidade de análise SQL. Um ponto de extremidade de análise SQL faz referência à mesma cópia física da tabela Delta no OneLake e oferece a experiência T-SQL. Selecione o ponto de extremidade de análise SQL para lakehouse1 e, em seguida, selecione Nova Consulta SQL para consultar a tabela usando T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
