Integrar o OneLake com o Azure Synapse Analytics
O Azure Synapse é um serviço de análise sem limites que reúne o armazenamento de dados empresariais e análise de macrodados. Este tutorial mostra como se conectar ao OneLake usando o Azure Synapse Analytics.
Gravar dados do Synapse usando o Apache Spark
Siga estas etapas para usar o Apache Spark para gravar dados de exemplo no OneLake a partir do Azure Synapse Analytics.
Abra seu espaço de trabalho Synapse e crie um pool Apache Spark com seus parâmetros preferidos.
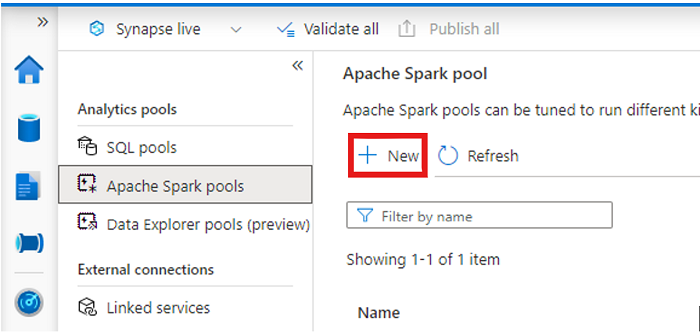
Crie um novo bloco de anotações Apache Spark.
Abra o bloco de anotações, defina o idioma como PySpark (Python) e conecte-o ao pool do Spark recém-criado.
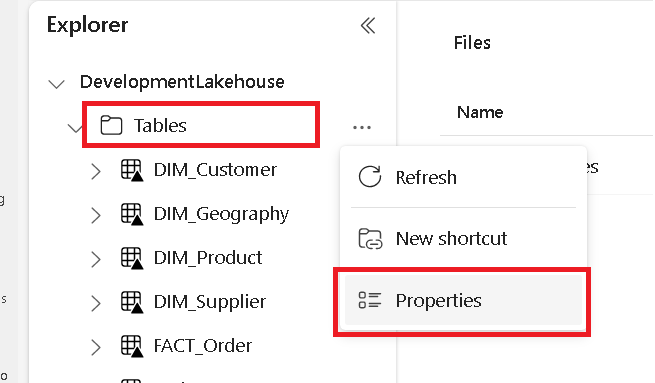
Em uma guia separada, navegue até o lago do Microsoft Fabric e localize a pasta Tabelas de nível superior.
Clique com o botão direito do mouse na pasta Tabelas e selecione Propriedades.
Copie o caminho ABFS do painel de propriedades.
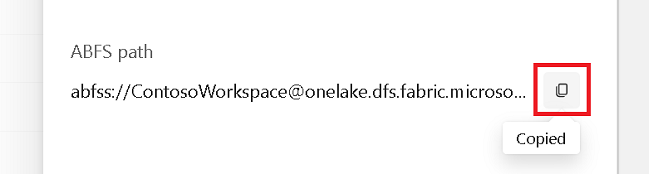
De volta ao bloco de anotações do Azure Synapse, na primeira nova célula de código, forneça o caminho lakehouse. Este lakehouse é onde seus dados são gravados mais tarde. Execute a célula.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Em uma nova célula de código, carregue dados de um conjunto de dados aberto do Azure em um dataframe. Este conjunto de dados é aquele que você carrega em sua casa do lago. Execute a célula.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Em uma nova célula de código, filtre, transforme ou prepare seus dados. Para esse cenário, você pode reduzir seu conjunto de dados para carregamento mais rápido, unir com outros conjuntos de dados ou filtrar para resultados específicos. Execute a célula.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Em uma nova célula de código, usando seu caminho OneLake, escreva seu dataframe filtrado em uma nova tabela Delta-Parquet em sua casa do lago Fabric. Execute a célula.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Finalmente, em uma nova célula de código, teste se seus dados foram gravados com êxito lendo o arquivo recém-carregado do OneLake. Execute a célula.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Parabéns! Agora você pode ler e gravar dados no OneLake usando o Apache Spark no Azure Synapse Analytics.
Ler dados do Synapse usando SQL
Siga estas etapas para usar o SQL serverless para ler dados do OneLake do Azure Synapse Analytics.
Abra uma casa de lago de tecido e identifique uma tabela que você gostaria de consultar da Sinapse.
Clique com o botão direito do mouse na tabela e selecione Propriedades.
Copie o caminho ABFS para a tabela.
Abra o espaço de trabalho Synapse no Synapse Studio.
Crie um novo script SQL.
No editor de consultas SQL, insira a consulta a seguir, substituindo
ABFS_PATH_HEREpelo caminho copiado anteriormente.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Execute a consulta para ver as 10 primeiras linhas da tabela.
Parabéns! Agora você pode ler dados do OneLake usando SQL serverless no Azure Synapse Analytics.