Guia de início rápido: criar um pool do Apache Spark sem servidor usando o Synapse Studio
O Azure Synapse Analytics oferece vários mecanismos de análise para ajudá-lo a ingerir, transformar, modelar, analisar e fornecer seus dados. O pool Apache Spark oferece recursos de computação de big data de código aberto. Depois de criar um pool do Apache Spark em seu espaço de trabalho Synapse, os dados podem ser carregados, modelados, processados e servidos para obter insights.
Este guia de início rápido descreve as etapas para criar um pool do Apache Spark em um espaço de trabalho Synapse usando o Synapse Studio.
Importante
O faturamento de instâncias do Spark é rateado por minuto, independentemente de você usá-las ou não. Certifique-se de desligar sua instância do Spark depois de terminar de usá-la ou definir um curto tempo limite. Para obter mais informações, consulte a secção Limpar recursos deste artigo.
Nota
O Synapse Studio continuará a suportar arquivos de configuração baseados em terraform ou bíceps.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Precisará de uma subscrição do Azure. Se necessário, crie uma conta gratuita do Azure
- Você usará o espaço de trabalho Sinapse.
Inicie sessão no portal do Azure
Inicie sessão no portal do Azure
Navegue até o espaço de trabalho Sinapse
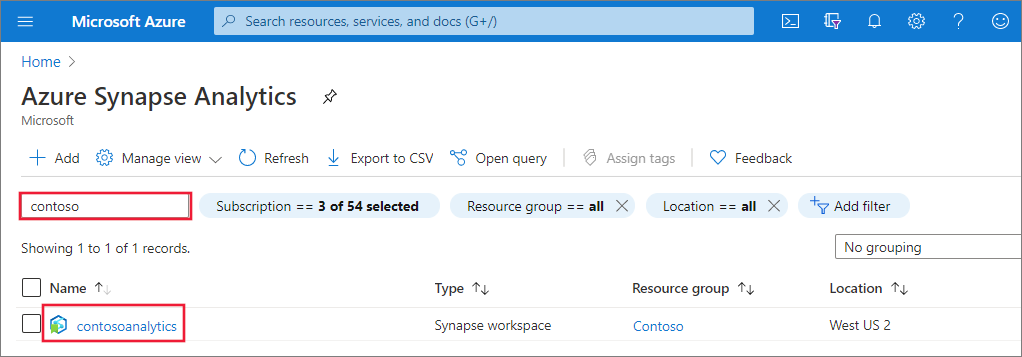
Navegue até o espaço de trabalho Synapse onde o pool do Apache Spark será criado digitando o nome do serviço (ou nome do recurso diretamente) na barra de pesquisa.

Na lista de espaços de trabalho, digite o nome (ou parte do nome) do espaço de trabalho a ser aberto. Neste exemplo, usamos um espaço de trabalho chamado contosoanalytics.


Iniciar o Synapse Studio
Na visão geral do espaço de trabalho, selecione a URL da Web do espaço de trabalho para abrir o Synapse Studio.

Criar o pool do Apache Spark no Synapse Studio
Importante
O Azure Synapse Runtime for Apache Spark 2.4 foi preterido e oficialmente não tem suporte desde setembro de 2023. Como o Spark 3.1 e o Spark 3.2 também estão anunciados como o fim do suporte, recomendamos que os clientes migrem para o Spark 3.3.
Na página inicial do Synapse Studio, navegue até o Hub de Gerenciamento na navegação à esquerda, selecionando o ícone Gerenciar .
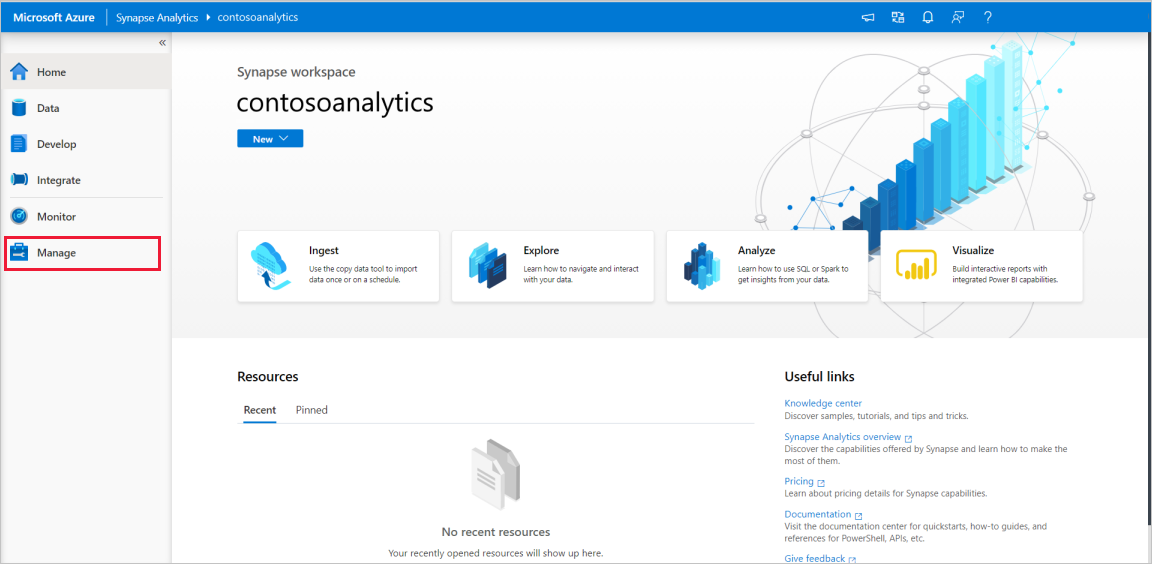
Uma vez no Hub de Gerenciamento, navegue até a seção Pools do Apache Spark para ver a lista atual de pools do Apache Spark disponíveis no espaço de trabalho.
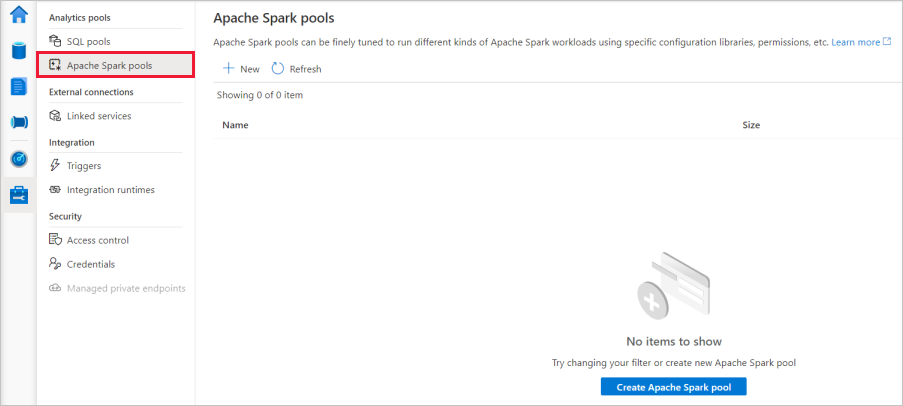
Selecione + Novo e o novo assistente de criação do pool do Apache Spark aparecerá.
Insira os seguintes detalhes na guia Noções básicas :
Definição Valor sugerido Descrição Nome do pool do Apache Spark Um nome de pool válido, como contososparkEste é o nome que o pool do Apache Spark terá. Tamanho do nó Pequeno (4 vCPU / 32 GB) Defina isso para o menor tamanho para reduzir os custos deste início rápido Dimensionamento Automático Desativado Não precisaremos de dimensionamento automático neste início rápido Número de nós 8 Use um tamanho pequeno para limitar os custos neste guia de início rápido Alocar executores dinamicamente Desativado Essa configuração é mapeada para a propriedade de alocação dinâmica na configuração do Spark para alocação de executores do Spark Application. Não precisaremos de dimensionamento automático neste início rápido. 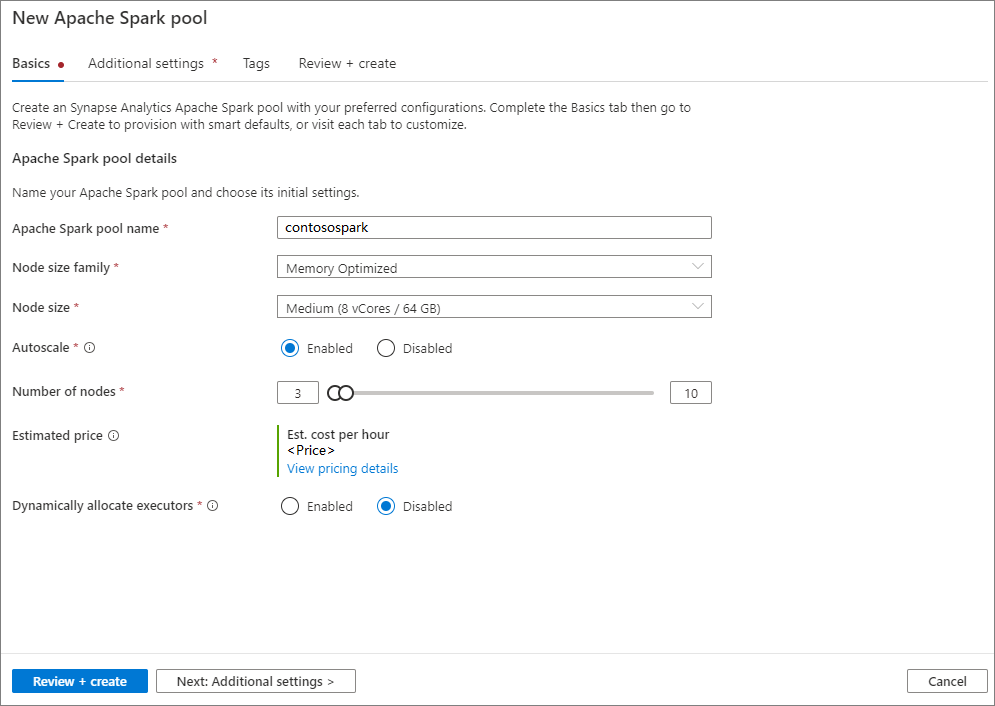
Importante
Há limitações específicas para os nomes que os pools do Apache Spark podem usar. Os nomes devem conter apenas letras ou números, devem ter 15 ou menos caracteres, devem começar com uma letra, não conter palavras reservadas e ser exclusivos no espaço de trabalho.
Na guia seguinte, Configurações adicionais, deixe todas as configurações como padrão.
Selecione Etiquetas. Considere usar marcas do Azure. Por exemplo, a tag "Owner" ou "CreatedBy" para identificar quem criou o recurso e a tag "Environment" para identificar se esse recurso está em Produção, Desenvolvimento, etc. Para obter mais informações, consulte Desenvolver sua estratégia de nomenclatura e marcação para recursos do Azure. Quando estiver pronto, selecione Rever + criar.
No separador Rever + criar, certifique-se de que os detalhes estão corretos com base no que foi introduzido anteriormente e prima Criar.
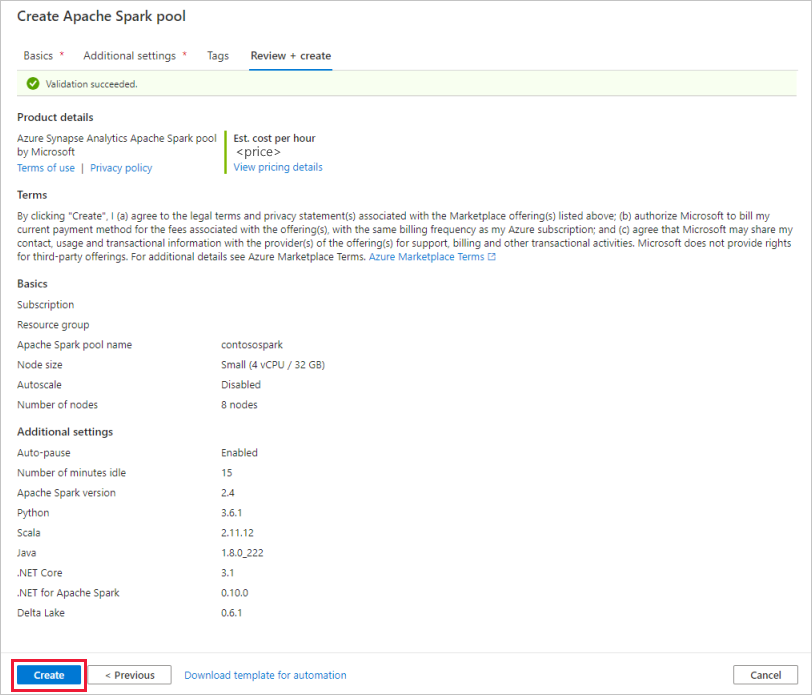
O pool do Apache Spark iniciará o processo de provisionamento.
Quando o provisionamento estiver concluído, o novo pool do Apache Spark aparecerá na lista.
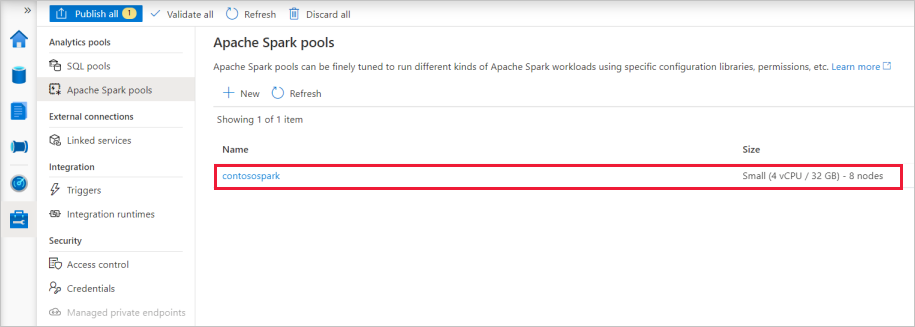





Limpe os recursos do pool do Apache Spark usando o Synapse Studio
As etapas a seguir excluem o pool do Apache Spark do espaço de trabalho usando o Synapse Studio.
Aviso
A exclusão de um pool do Spark removerá o mecanismo de análise do espaço de trabalho. Não será mais possível se conectar ao pool e todas as consultas, pipelines e notebooks que usam esse pool do Spark não funcionarão mais.
Se você quiser excluir o pool do Apache Spark, execute as seguintes etapas:
Navegue até os pools do Apache Spark no Hub de Gerenciamento no Synapse Studio.
Selecione as reticências ao lado do pool Apache a ser excluído (neste caso, contosospark) para mostrar os comandos para o pool do Apache Spark.
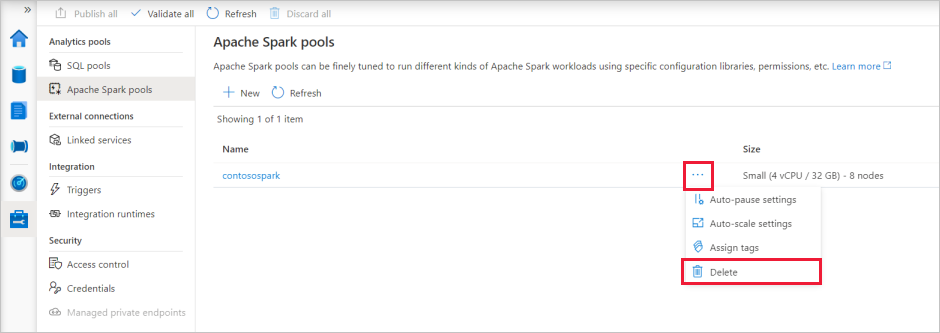
Selecione Eliminar.
Confirme a exclusão e pressione o botão Delete .
Quando o processo for concluído com êxito, o pool do Apache Spark não será mais listado nos recursos do espaço de trabalho.
