Tutorial Parte 2: Explorar e visualizar dados usando blocos de anotações do Microsoft Fabric
Neste tutorial, você aprenderá como conduzir a análise exploratória de dados (EDA) para examinar e investigar os dados enquanto resume suas principais características por meio do uso de técnicas de visualização de dados.
Você usará seaborn, uma biblioteca de visualização de dados Python que fornece uma interface de alto nível para criar visuais em dataframes e matrizes. Para obter mais informações sobre seaborn, consulte Seaborn: Statistical Data Visualization.
Você também usará o Data Wrangler, uma ferramenta baseada em notebook que oferece uma experiência imersiva para realizar análises e limpezas exploratórias de dados.
As principais etapas neste tutorial são:
- Leia os dados armazenados a partir de uma tabela delta na casa do lago.
- Converta um Spark DataFrame em Pandas DataFrame, que as bibliotecas de visualização python suportam.
- Use o Data Wrangler para executar a limpeza e transformação inicial de dados.
- Execute a análise exploratória de dados usando
seaborn.
Pré-requisitos
Obtenha uma assinatura Microsoft Fabric. Ou inscreva-se para obter uma avaliação gratuita do Microsoft Fabric.
Inicie sessão no Microsoft Fabric.
Use o seletor de experiência no canto inferior esquerdo da página inicial para alternar para o Fabric.
Esta é a parte 2 de 5 da série de tutoriais. Para concluir este tutorial, deve primeiro completar:
Siga com o bloco de notas
2-explore-cleanse-data.ipynb é o bloco de anotações que acompanha este tutorial.
Para abrir o bloco de anotações que acompanha este tutorial, siga as instruções em Prepare o seu sistema para tutoriais de ciência de dados para importar o bloco de anotações para o seu espaço de trabalho.
Se preferir copiar e colar o código desta página, pode criar um novo bloco de notas.
Certifique-se de anexar um lakehouse ao do bloco de anotações antes de começar a executar o código.
Importante
Anexe a mesma casa do lago que você usou na Parte 1.
Leia dados brutos da casa do lago
Leia os dados brutos da secção Arquivos do lakehouse. Você carregou esses dados no bloco de anotações anterior. Certifique-se de ter anexado a mesma casa do lago que você usou na Parte 1 a este bloco de anotações antes de executar este código.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Criar um DataFrame pandas a partir do conjunto de dados
Converta o spark DataFrame em pandas DataFrame para facilitar o processamento e a visualização.
df = df.toPandas()
Exibir dados brutos
Explore os dados brutos com display, faça algumas estatísticas básicas e mostre visualizações de gráficos. Observe que primeiro você precisa importar as bibliotecas necessárias, como Numpy, Pnadas, Seaborne Matplotlib para análise e visualização de dados.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Usar o Data Wrangler para executar a limpeza inicial de dados
Para explorar e transformar quaisquer pandas Dataframes no seu bloco de notas, inicie o Data Wrangler diretamente a partir do bloco de notas.
Observação
O Data Wrangler não pode ser aberto enquanto o kernel do notebook estiver ocupado. A execução da célula deve ser concluída antes de iniciar o Data Wrangler.
- No friso do bloco de notas separador de dados, selecione IniciarData Wrangler . Você verá uma lista de Pandas DataFrames ativados disponíveis para edição.
- Selecione o DataFrame que deseja abrir no Data Wrangler. Como este notebook contém apenas um DataFrame,
df, selecionedf.
O Data Wrangler inicia e gera uma visão geral descritiva dos seus dados. A tabela no meio mostra cada coluna de dados. O painel Resumo ao lado da tabela mostra informações sobre o DataFrame. Quando você seleciona uma coluna na tabela, o resumo é atualizado com informações sobre a coluna selecionada. Em alguns casos, os dados exibidos e resumidos serão uma exibição truncada do seu DataFrame. Quando isso acontecer, você verá a imagem de aviso no painel de resumo. Passe o cursor sobre este aviso para ver o texto que explica a situação.

Cada operação que você faz pode ser aplicada em questão de cliques, atualizando a exibição de dados em tempo real e gerando código que você pode salvar de volta para o seu notebook como uma função reutilizável.
O restante desta seção orienta você pelas etapas para executar a limpeza de dados com o Data Wrangler.
Remover linhas duplicadas
No painel esquerdo há uma lista de operações (como Localizar e substituir, Formato, Fórmulas, Numérico) que pode executar no conjunto de dados.
Expandir Localizar e substituir e selecionar Eliminar linhas duplicadas.
Um painel é exibido para você selecionar a lista de colunas que deseja comparar para definir uma linha duplicada. Selecione a RowNumber e o CustomerId.
No painel central está uma pré-visualização dos resultados desta operação. Sob a visualização está o código para executar a operação. Neste caso, os dados parecem permanecer inalterados. Mas como você está olhando para uma exibição truncada, é uma boa ideia ainda aplicar a operação.
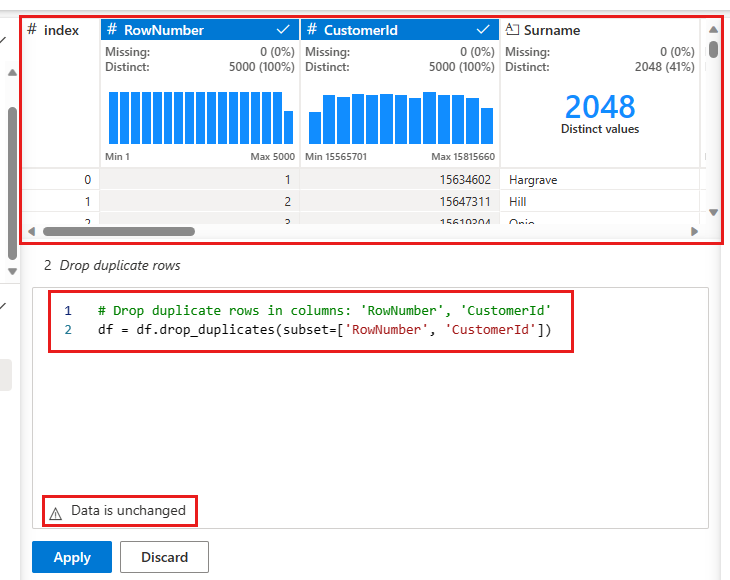
Selecione Aplicar (ao lado ou na parte inferior) para ir para a próxima etapa.

Remover linhas com dados ausentes
Use o Data Wrangler para soltar linhas com dados ausentes em todas as colunas.
Selecione Eliminar valores ausentes de Localizar e substituir.
Escolha Selecionar todos os nas colunas Destino.
Selecione Aplicar para avançar para a próxima etapa.

Soltar colunas
Use o Data Wrangler para eliminar colunas que não são necessárias.
Expanda o Esquema e selecione Eliminar colunas.
Selecione RowNumber, CustomerId, Sobrenome. Essas colunas aparecem em vermelho na visualização, para mostrar que foram alteradas pelo código (neste caso, descartadas).
Selecione Aplicar para avançar para a próxima etapa.

Adicionar código ao bloco de notas
Cada vez que selecionares Aplicar, uma nova etapa é criada no painel Etapas de Limpeza no canto inferior esquerdo. Na parte inferior do painel, selecione código de visualização para todas as etapas para exibir uma combinação de todas as etapas separadas.
Selecione Adicionar código ao bloco de anotações no canto superior esquerdo para fechar o Data Wrangler e adicionar o código automaticamente. O Adicionar código ao bloco de anotações encapsula o código em uma função e, em seguida, chama a função.
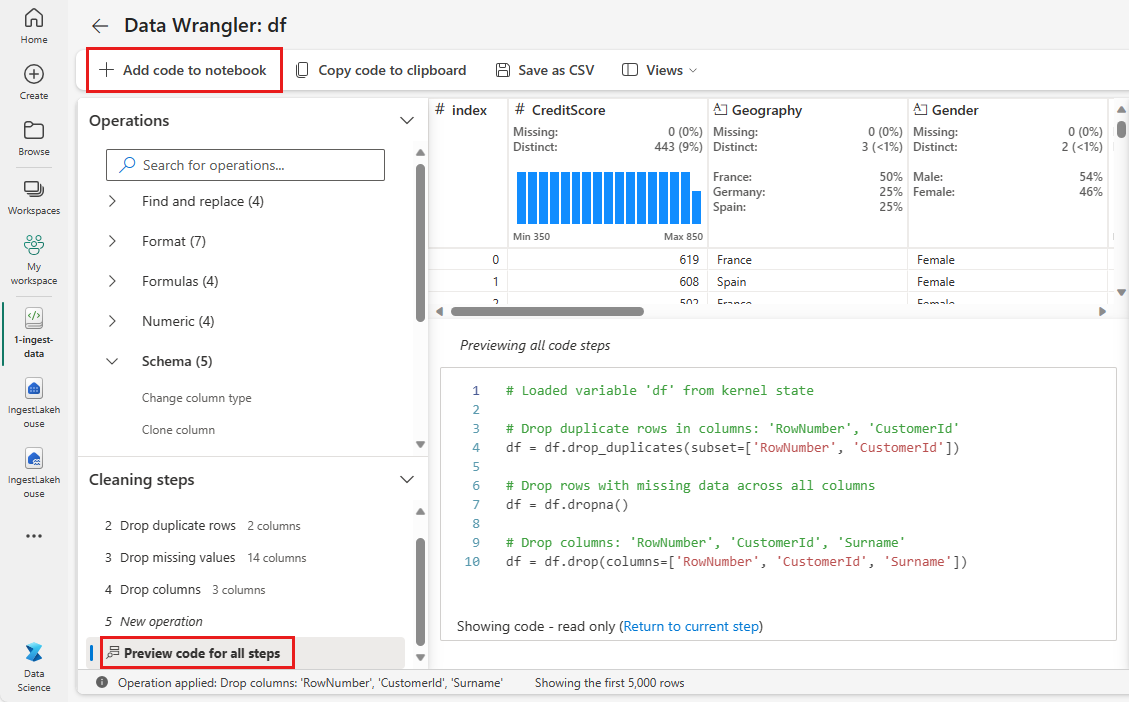
Dica
O código gerado pelo Data Wrangler não será aplicado até que você execute manualmente a nova célula.
Se você não usou o Data Wrangler, pode usar essa próxima célula de código.
Esse código é semelhante ao código produzido pelo Data Wrangler, mas adiciona no argumento inplace=True a cada uma das etapas geradas. Ao definir inplace=True, o Pandas irá sobrescrever o DataFrame original em vez de criar um novo DataFrame como resultado.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Explore os dados
Exiba alguns resumos e visualizações dos dados limpos.
Determinar atributos categóricos, numéricos e de destino
Use esse código para determinar atributos categóricos, numéricos e de destino.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
O resumo estatístico de cinco números
Mostrar o resumo de cinco números (a pontuação mínima, primeiro quartil, mediana, terceiro quartil, a pontuação máxima) para os atributos numéricos, usando gráficos de caixa.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
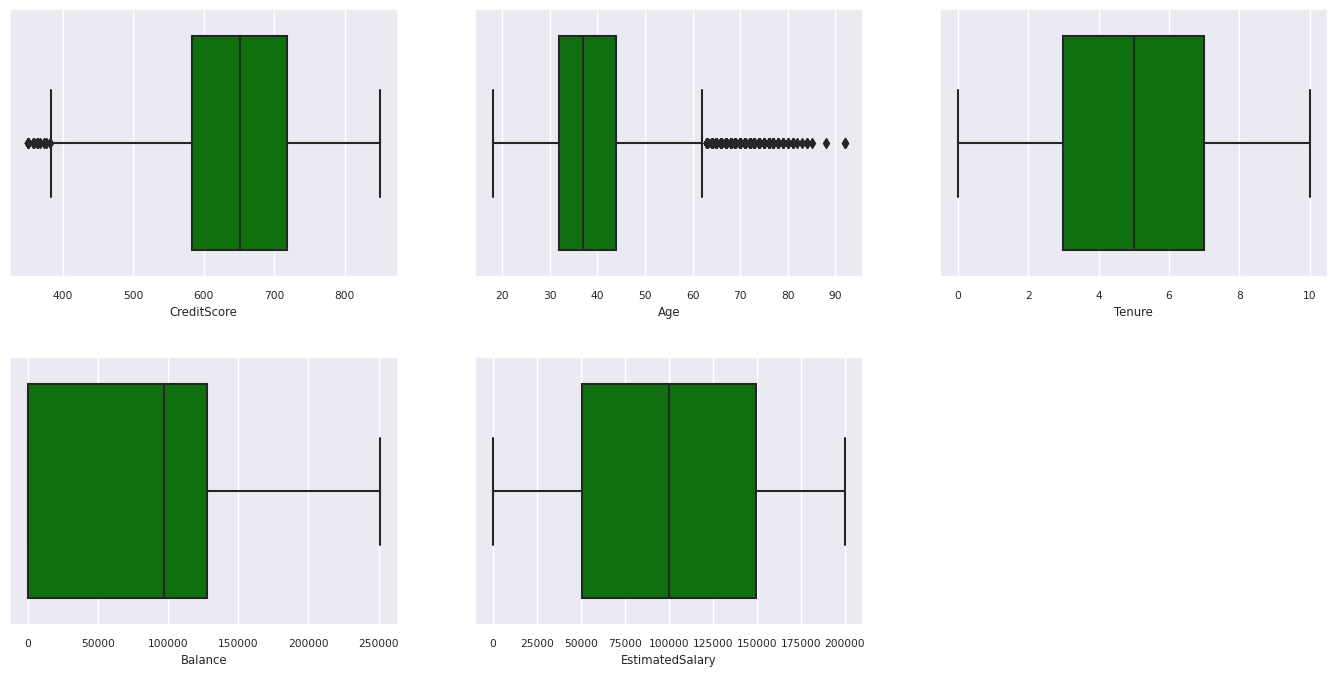
Distribuição de clientes que saíram e os que não saíram.
Mostrar a distribuição de clientes saídos versus clientes não saídos entre os atributos categóricos.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Distribuição dos atributos numéricos
Mostrar a distribuição de frequência dos atributos numéricos usando histograma.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Executar engenharia de características
Execute engenharia de recursos para gerar novos atributos com base nos atributos atuais:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Use o Data Wrangler para executar uma codificação a quente
O Data Wrangler também pode ser usado para executar uma codificação one-hot. Para isso, reabra o Data Wrangler. Desta vez, selecione os dados df_clean.
- Expanda Fórmulas e selecione Codificação a quente.
- Um painel é exibido para si selecionar a lista de colunas nas quais deseja executar uma codificação one-hot. Selecione Geography e Gender.
Você pode copiar o código gerado, fechar o Data Wrangler para retornar ao bloco de anotações e colar em uma nova célula. Ou, selecione Adicionar código ao bloco de notas no canto superior esquerdo para fechar o Data Wrangler e adicionar o código automaticamente.
Se você não usou o Data Wrangler, pode usar esta próxima célula de código:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Resumo das observações da análise exploratória dos dados
- A maioria dos clientes são da França, em comparação com a Espanha e a Alemanha, enquanto a Espanha tem a menor taxa de churn em comparação com a França e a Alemanha.
- A maioria dos clientes tem cartões de crédito.
- Há clientes cuja idade e pontuação de crédito estão acima de 60 e abaixo de 400, respectivamente, mas não podem ser considerados como outliers.
- Pouquíssimos clientes têm mais de dois produtos do banco.
- Os clientes que não estão ativos têm uma taxa de churn mais alta.
- O género e os anos de posse não parecem ter impacto na decisão do cliente de encerrar a conta bancária.
Criar uma tabela delta para os dados limpos
Você usará esses dados no próximo bloco de anotações desta série.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Próximo passo
Treine e registre modelos de aprendizado de máquina com estes dados: