Atualização incremental no Dataflow Gen2 (Visualização)
Neste artigo, apresentamos a atualização incremental de dados no Dataflow Gen2 para o Data Factory do Microsoft Fabric. Quando você usa fluxos de dados para ingestão e transformação de dados, há cenários em que você precisa atualizar especificamente apenas dados novos ou atualizados, especialmente à medida que seus dados continuam a crescer. O recurso de atualização incremental atende a essa necessidade, permitindo reduzir os tempos de atualização, aumentar a confiabilidade evitando operações de longa execução e minimizar o uso de recursos.
Pré-requisitos
Para usar a atualização incremental no Dataflow Gen2, você precisa atender aos seguintes pré-requisitos:
- Você deve ter uma capacidade de malha.
- Sua fonte de dados oferece suporte a dobragem (recomendado) e precisa conter uma coluna Data/DataHora que possa ser usada para filtrar os dados.
- Você deve ter um destino de dados que ofereça suporte à atualização incremental. Para obter mais informações, vá para Suporte de destino.
- Antes de começar, certifique-se de revisar as limitações da atualização incremental. Para obter mais informações, vá para Limitações.
Suporte de destino
Os seguintes destinos de dados são suportados para atualização incremental:
- Armazém de Tecidos
- Base de Dados SQL do Azure
- Azure Synapse Analytics
Outros destinos como Lakehouse podem ser usados em combinação com a atualização incremental usando uma segunda consulta que faz referência aos dados em estágios para atualizar o destino dos dados. Dessa forma, você ainda pode usar a atualização incremental para reduzir a quantidade de dados que precisam ser processados e recuperados do sistema de origem. Mas você precisa fazer uma atualização completa dos dados em estágios para o destino dos dados.
Como usar a atualização incremental
Crie um novo Dataflow Gen2 ou abra um Dataflow Gen2 existente.
No editor de fluxo de dados, crie uma nova consulta que recupere os dados que você deseja atualizar incrementalmente.
Verifique a visualização de dados para garantir que a consulta retorne dados que contenham uma coluna DateTime, Date ou DateTimeZone que você pode usar para filtrar os dados.
Certifique-se de que a consulta seja totalmente dobrada, o que significa que a consulta é totalmente enviada para o sistema de origem. Se a consulta não dobrar totalmente, você precisará modificá-la para que ela seja totalmente dobrada. Você pode garantir que a consulta seja totalmente dobrada verificando as etapas de consulta no editor de consultas.
Clique com o botão direito do mouse na consulta e selecione Atualização incremental.
Forneça as configurações necessárias para atualização incremental.
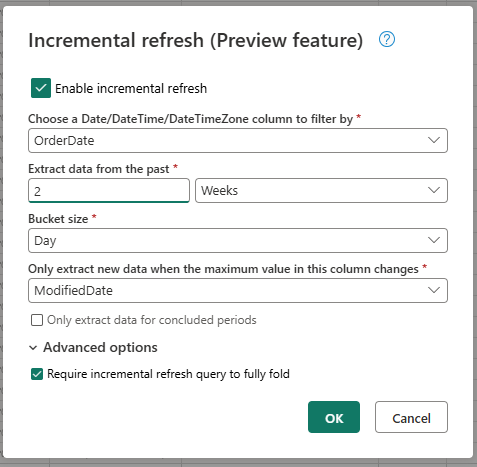
- Escolha uma coluna DateTime pela qual filtrar.
- Extraia dados do passado.
- Tamanho da caçamba.
- Extraia novos dados apenas quando o valor máximo nesta coluna for alterado.
Configure as configurações avançadas, se necessário.
- Exigir consulta de atualização incremental para dobrar totalmente.
Selecione OK para salvar as configurações.
Se desejar, agora você pode configurar um destino de dados para a consulta. Certifique-se de fazer essa configuração antes da primeira atualização incremental, caso contrário, seu destino de dados conterá apenas os dados alterados incrementalmente desde a última atualização.
Publique o Dataflow Gen2.
Depois de configurar a atualização incremental, o fluxo de dados atualiza automaticamente os dados incrementalmente com base nas configurações fornecidas. O fluxo de dados recupera apenas os dados que foram alterados desde a última atualização. Assim, o fluxo de dados é executado mais rápido e consome menos recursos.
Como funciona a atualização incremental nos bastidores
A atualização incremental funciona dividindo os dados em buckets com base na coluna DateTime. Cada bucket contém os dados que foram alterados desde a última atualização. O fluxo de dados sabe o que mudou verificando o valor máximo na coluna que você especificou. Se o valor máximo for alterado para esse bucket, o fluxo de dados recuperará todo o bucket e substituirá os dados no destino. Se o valor máximo não for alterado, o fluxo de dados não recuperará nenhum dado. As seções a seguir contêm uma visão geral de alto nível de como a atualização incremental funciona passo a passo.
Primeiro passo: Avaliar as alterações
Quando o fluxo de dados é executado, ele primeiro avalia as alterações na fonte de dados. Ele faz essa avaliação comparando o valor máximo na coluna DateTime com o valor máximo na atualização anterior. Se o valor máximo for alterado ou se for a primeira atualização, o fluxo de dados marcará o bucket como alterado e o listará para processamento. Se o valor máximo não for alterado, o fluxo de dados ignorará o bucket e não o processará.
Segunda etapa: Recuperar os dados
Agora, o fluxo de dados está pronto para recuperar os dados. Ele recupera os dados de cada bucket que foi alterado. O fluxo de dados faz essa recuperação em paralelo para melhorar o desempenho. O fluxo de dados recupera os dados do sistema de origem e os carrega na área de preparação. O fluxo de dados recupera apenas os dados que estão dentro do intervalo de bucket. Em outras palavras, o fluxo de dados recupera apenas os dados que foram alterados desde a última atualização.
Última etapa: substituir os dados no destino dos dados
O fluxo de dados substitui os dados no destino pelos novos dados. O fluxo de dados usa o replace método para substituir os dados no destino. Ou seja, o fluxo de dados primeiro exclui os dados no destino desse bucket e, em seguida, insere os novos dados. O fluxo de dados não afeta os dados que estão fora do intervalo de bucket. Portanto, se você tiver dados no destino mais antigos do que o primeiro bucket, a atualização incremental não afetará esses dados de forma alguma.
Explicação das configurações de atualização incremental
Para configurar a atualização incremental, você precisa especificar as seguintes configurações.
Definições gerais
As configurações gerais são necessárias e especificam a configuração básica para atualização incremental.
Escolha uma coluna DateTime para filtrar
Essa configuração é necessária e especifica a coluna que os fluxos de dados usam para filtrar os dados. Esta coluna deve ser uma coluna DateTime, Date ou DateTimeZone. O fluxo de dados usa essa coluna para filtrar os dados e recupera apenas os dados que foram alterados desde a última atualização.
Extrair dados do passado
Essa configuração é necessária e especifica até onde o fluxo de dados deve extrair dados. Essa configuração é usada para recuperar a carga de dados inicial. O fluxo de dados recupera todos os dados do sistema de origem que estão dentro do intervalo de tempo especificado. Os valores possíveis são:
- x dias
- x semanas
- x meses
- x quartos
- x anos
Por exemplo, se você especificar 1 mês, o fluxo de dados recuperará todos os novos dados do sistema de origem que está no último mês.
Tamanho da caçamba
Essa configuração é necessária e especifica o tamanho dos buckets que o fluxo de dados usa para filtrar os dados. O fluxo de dados divide os dados em buckets com base na coluna DateTime. Cada bucket contém os dados que foram alterados desde a última atualização. O tamanho do bucket determina a quantidade de dados processados em cada iteração. Um tamanho de bucket menor significa que o fluxo de dados processa menos dados em cada iteração, mas também significa que mais iterações são necessárias para processar todos os dados. Um tamanho de bucket maior significa que o fluxo de dados processa mais dados em cada iteração, mas também significa que menos iterações são necessárias para processar todos os dados.
Extrair novos dados apenas quando o valor máximo nesta coluna for alterado
Essa configuração é necessária e especifica a coluna que o fluxo de dados usa para determinar se os dados foram alterados. O fluxo de dados compara o valor máximo nesta coluna com o valor máximo na atualização anterior. Se o valor máximo for alterado, o fluxo de dados recuperará os dados que foram alterados desde a última atualização. Se o valor máximo não for alterado, o fluxo de dados não recuperará nenhum dado.
Extrair apenas dados de períodos concluídos
Essa configuração é opcional e especifica se o fluxo de dados só deve extrair dados para períodos concluídos. Se essa configuração estiver habilitada, o fluxo de dados extrairá apenas dados para períodos concluídos. Assim, o fluxo de dados só extrai dados para períodos que estão completos e não contêm dados futuros. Se essa configuração estiver desabilitada, o fluxo de dados extrai dados para todos os períodos, incluindo períodos que não estão completos e contêm dados futuros.
Por exemplo, se você tiver uma coluna DateTime que contenha a data da transação e quiser atualizar apenas os meses completos, poderá habilitar essa configuração em combinações com o tamanho do bucket de month. Portanto, o fluxo de dados extrai apenas dados para meses completos e não extrai dados para meses incompletos.
Definições avançadas
Algumas configurações são consideradas avançadas e não são necessárias para a maioria dos cenários.
Exigir consulta de atualização incremental para dobrar totalmente
Essa configuração é opcional e especifica se a consulta usada para atualização incremental deve ser totalmente dobrada. Se essa configuração estiver habilitada, a consulta usada para atualização incremental deverá ser totalmente dobrada. Em outras palavras, a consulta deve ser totalmente empurrada para o sistema de origem. Se essa configuração estiver desabilitada, a consulta usada para atualização incremental não precisará ser totalmente dobrada. Nesse caso, a consulta pode ser parcialmente empurrada para o sistema de origem. É altamente recomendável habilitar essa configuração para melhorar o desempenho e evitar a recuperação de dados desnecessários e não filtrados.
Limitações
Somente destinos de dados baseados em SQL são suportados
Atualmente, apenas destinos de dados baseados em SQL são suportados para atualização incremental. Portanto, você só pode usar o Fabric Warehouse, o Banco de Dados SQL do Azure ou o Azure Synapse Analytics como um destino de dados para atualização incremental. A razão para essa limitação é que esses destinos de dados oferecem suporte às operações baseadas em SQL que são necessárias para atualização incremental. Usamos as operações Excluir e Inserir para substituir os dados no destino dos dados, o que não pode ser feito em paralelo em outros destinos de dados.
O destino dos dados deve ser definido como um esquema fixo
O destino dos dados deve ser definido como um esquema fixo, o que significa que o esquema da tabela no destino dos dados deve ser fixo e não pode ser alterado. Se o esquema da tabela no destino de dados estiver definido como esquema dinâmico, você precisará alterá-lo para esquema fixo antes de configurar a atualização incremental.
O único método de atualização suportado no destino dos dados é replace
O único método de atualização com suporte no destino de dados é replace, o que significa que o fluxo de dados substitui os dados de cada bucket no destino de dados pelos novos dados. No entanto, os dados que estão fora do intervalo de bucket não são afetados. Portanto, se você tiver dados no destino de dados mais antigos do que o primeiro bucket, a atualização incremental não afetará esses dados de forma alguma.
O número máximo de buckets é 50 para uma única consulta e 150 para todo o fluxo de dados
O número máximo de buckets por consulta que o fluxo de dados suporta é 50. Se você tiver mais de 50 caçambas, precisará aumentar o tamanho da caçamba ou reduzir o intervalo da caçamba para diminuir o número de caçambas. Para todo o fluxo de dados, o número máximo de buckets é 150. Se você tiver mais de 150 buckets no fluxo de dados, precisará reduzir o número de consultas de atualização incremental ou aumentar o tamanho do bucket para reduzir o número de buckets.
Diferenças entre a atualização incremental no Dataflow Gen1 e no Dataflow Gen2
Entre Dataflow Gen1 e Dataflow Gen2, há algumas diferenças em como a atualização incremental funciona. A lista a seguir explica as principais diferenças entre a atualização incremental no Dataflow Gen1 e no Dataflow Gen2.
- A atualização incremental agora é um recurso de primeira classe no Dataflow Gen2. No Dataflow Gen1, você tinha que configurar a atualização incremental depois de publicar o fluxo de dados. No Dataflow Gen2, a atualização incremental agora é um recurso de primeira classe que você pode configurar diretamente no editor de fluxo de dados. Esse recurso facilita a configuração da atualização incremental e reduz o risco de erros.
- No Dataflow Gen1, você precisava especificar o intervalo de dados históricos ao configurar a atualização incremental. No Dataflow Gen2, não é necessário especificar o intervalo de dados históricos. O fluxo de dados não remove nenhum dado do destino que está fora do intervalo de bucket. Portanto, se você tiver dados no destino mais antigos do que o primeiro bucket, a atualização incremental não afetará esses dados de forma alguma.
- No Dataflow Gen1, você tinha que especificar os parâmetros para a atualização incremental quando configurava a atualização incremental. No Dataflow Gen2, não é necessário especificar os parâmetros para a atualização incremental. O fluxo de dados adiciona automaticamente os filtros e parâmetros como a última etapa da consulta. Portanto, não é necessário especificar os parâmetros para a atualização incremental manualmente.
FAQ
Recebi um aviso de que usava a mesma coluna para detetar alterações e filtrar. Qual é o significado disto?
Se você receber um aviso de que usou a mesma coluna para detetar alterações e filtrar, isso significa que a coluna especificada para detetar alterações também é usada para filtrar os dados. Não recomendamos esse uso, pois pode levar a resultados inesperados. Em vez disso, recomendamos que você use uma coluna diferente para detetar alterações e filtrar os dados. Se os dados forem deslocados entre buckets, o fluxo de dados pode não ser capaz de detetar as alterações corretamente e pode criar dados duplicados no seu destino. Você pode resolver esse aviso usando uma coluna diferente para detetar alterações e filtrar os dados. Ou você pode ignorar o aviso se tiver certeza de que os dados não mudam entre as atualizações da coluna especificada.
Quero usar a atualização incremental com um destino de dados que não é suportado. O que posso fazer?
Se você quiser usar a atualização incremental com um destino de dados sem suporte, poderá habilitar a atualização incremental em sua consulta e usar uma segunda consulta que faça referência aos dados em estágios para atualizar o destino de dados. Dessa forma, você ainda pode usar a atualização incremental para reduzir a quantidade de dados que precisam ser processados e recuperados do sistema de origem, mas precisa fazer uma atualização completa dos dados em estágios para o destino dos dados. Certifique-se de configurar a janela e o tamanho do bucket corretamente, pois não garantimos que os dados no preparo sejam retidos fora do intervalo do bucket.
Como posso saber se a minha consulta tem a atualização incremental ativada?
Você pode ver se sua consulta tem a atualização incremental habilitada marcando o ícone ao lado da consulta no editor de fluxo de dados. Se o ícone contiver um triângulo azul, a atualização incremental será ativada. Se o ícone não contiver um triângulo azul, a atualização incremental não estará ativada.
Minha fonte recebe muitas solicitações quando uso a atualização incremental. O que posso fazer?
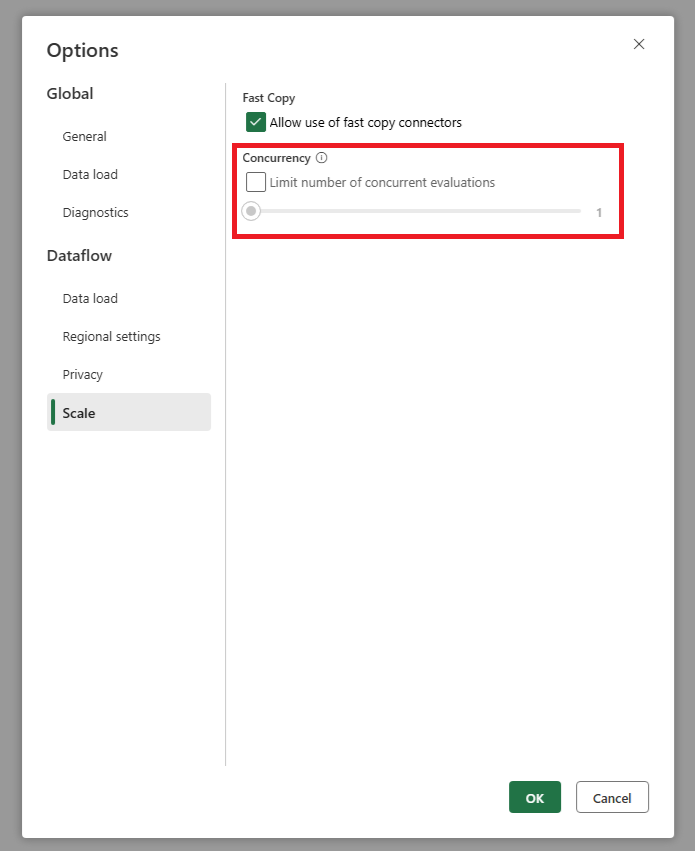
Adicionamos uma configuração que permite definir o número máximo de avaliações de consultas paralelas. Essa configuração pode ser encontrada nas configurações globais do fluxo de dados. Definindo esse valor para um número menor, você pode reduzir o número de solicitações enviadas ao sistema de origem. Essa configuração pode ajudar a reduzir o número de solicitações simultâneas e melhorar o desempenho do sistema de origem. Para definir o número máximo de execuções de consulta paralela, vá para as configurações globais do fluxo de dados, navegue até a guia Escala e defina o número máximo de avaliações de consulta paralela. Recomendamos que você não habilite esse limite, a menos que tenha problemas com o sistema de origem.
Quero usar a atualização incremental, mas vejo que, após a habilitação, o fluxo de dados leva mais tempo para ser atualizado. O que posso fazer?
A atualização incremental, conforme descrito neste artigo, foi projetada para reduzir a quantidade de dados que precisam ser processados e recuperados do sistema de origem. No entanto, se o fluxo de dados demorar mais para ser atualizado depois de habilitar a atualização incremental, pode ser porque a sobrecarga adicional de verificar se os dados foram alterados e processar os buckets é maior do que o tempo economizado pelo processamento de menos dados. Nesse caso, recomendamos que você revise as configurações para atualização incremental e as ajuste para melhor se adequar ao seu cenário. Por exemplo, podes aumentar o tamanho do balde para reduzir o número de baldes e a sobrecarga de processá-los. Ou pode reduzir o número de baldes aumentando o tamanho do balde. Se você ainda tiver baixo desempenho depois de ajustar as configurações, poderá desabilitar a atualização incremental e usar uma atualização completa, pois isso pode ser mais eficiente em seu cenário.