Configurar o Banco de Dados SQL do Azure em uma atividade de cópia
Este artigo descreve como usar a atividade de cópia no pipeline de dados para copiar dados de e para o Banco de Dados SQL do Azure.
Configuração suportada
Para a configuração de cada guia em atividade de cópia, vá para as seções a seguir, respectivamente.
- General (Geral)
- Source
- Destino
- Mapeamento
- Definições
Geral
Consulte as orientações de configurações gerais para configurar a guia Configurações gerais.
Origem
As propriedades a seguir têm suporte para o Banco de Dados SQL do Azure na guia Origem de uma atividade de cópia.

As seguintes propriedades são necessárias:
- Tipo de armazenamento de dados: Selecione Externo.
- Conexão: selecione uma conexão do Banco de Dados SQL do Azure na lista de conexões. Se a conexão não existir, crie uma nova conexão do Banco de Dados SQL do Azure selecionando Novo.
- Tipo de conexão: Selecione Banco de Dados SQL do Azure.
- Tabela: Selecione a tabela em seu banco de dados na lista suspensa. Ou marque Editar para inserir o nome da tabela manualmente.
- Visualizar dados: selecione Visualizar dados para visualizar os dados na tabela.
Em Avançado, você pode especificar os seguintes campos:
Usar consulta: você pode escolher Tabela, Consulta ou Procedimento armazenado. A lista a seguir descreve a configuração de cada configuração:
Tabela: Leia os dados da tabela especificada em Tabela se selecionar este botão.
Consulta: especifique a consulta SQL personalizada para ler dados. Um exemplo é
select * from MyTable. Ou selecione o ícone de lápis para editar no editor de códigos.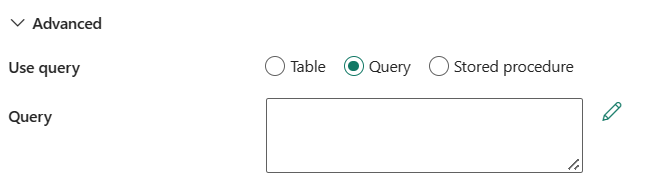
Procedimento armazenado: use o procedimento armazenado que lê dados da tabela de origem. A última instrução SQL deve ser uma instrução SELECT no procedimento armazenado.
Nome do procedimento armazenado: selecione o procedimento armazenado ou especifique o nome do procedimento armazenado manualmente ao marcar a caixa Editar para ler dados da tabela de origem.
Parâmetros de procedimento armazenado: especifique valores para parâmetros de procedimento armazenado. Os valores permitidos são pares de nome ou valor. Os nomes e o invólucro dos parâmetros devem corresponder aos nomes e invólucros dos parâmetros do procedimento armazenado.

Tempo limite da consulta (minutos): especifique o tempo limite para a execução do comando de consulta, o padrão é 120 minutos. Se um parâmetro for definido para essa propriedade, os valores permitidos serão de intervalo de tempo, como "02:00:00" (120 minutos).
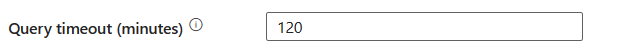
Nível de isolamento: especifica o comportamento de bloqueio de transação para a fonte SQL. Os valores permitidos são: None, ReadCommitted, ReadUncommitted, RepeatableRead, Serializable ou Snapshot. Se não for especificado, Nenhum nível de isolamento será usado. Consulte IsolationLevel Enum para obter mais detalhes.
Opção de partição: especifique as opções de particionamento de dados usadas para carregar dados do Banco de Dados SQL do Azure. Os valores permitidos são: Nenhum (padrão), Partições físicas da tabela e Intervalo dinâmico. Quando uma opção de partição é habilitada (ou seja, não Nenhuma), o grau de paralelismo para carregar simultaneamente dados de um Banco de Dados SQL do Azure é controlado pela configuração de cópia paralela na atividade de cópia.

Nenhum: escolha esta configuração para não usar uma partição.
Partições físicas da tabela: Quando você usa uma partição física, a coluna e o mecanismo da partição são determinados automaticamente com base na sua definição de tabela física.
Intervalo dinâmico: Quando você usa uma consulta com paralelo habilitado, o parâmetro de partição de intervalo (
?DfDynamicRangePartitionCondition) é necessário. Exemplo de consulta:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.- Nome da coluna da partição: especifique o nome da coluna de origem no tipo inteiro ou data/data/hora (
int,smallint,bigint,date,datetime2smalldatetimedatetime, , oudatetimeoffset) que é usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, o índice ou a chave primária da tabela será detetado automaticamente e usado como a coluna de partição. - Limite superior da partição: especifique o valor máximo da coluna de partição para a divisão do intervalo de partições. Esse valor é usado para decidir a passada da partição, não para filtrar as linhas na tabela. Todas as linhas na tabela ou no resultado da consulta são particionadas e copiadas.
- Limite inferior da partição: especifique o valor mínimo da coluna de partição para a divisão do intervalo de partições. Esse valor é usado para decidir a passada da partição, não para filtrar as linhas na tabela. Todas as linhas na tabela ou no resultado da consulta são particionadas e copiadas.
- Nome da coluna da partição: especifique o nome da coluna de origem no tipo inteiro ou data/data/hora (
Colunas adicionais: adicione mais colunas de dados para armazenar o caminho relativo ou o valor estático dos arquivos de origem. A expressão é suportada para este último. Para obter mais informações, vá para Adicionar colunas adicionais durante a cópia.


Destino
As propriedades a seguir têm suporte para o Banco de Dados SQL do Azure na guia Destino de uma atividade de cópia.

As seguintes propriedades são necessárias:
- Tipo de armazenamento de dados: Selecione Externo.
- Conexão: selecione uma conexão do Banco de Dados SQL do Azure na lista de conexões. Se a conexão não existir, crie uma nova conexão do Banco de Dados SQL do Azure selecionando Novo.
- Tipo de conexão: Selecione Banco de Dados SQL do Azure.
- Tabela: Selecione a tabela em seu banco de dados na lista suspensa. Ou marque Editar para inserir o nome da tabela manualmente.
- Visualizar dados: selecione Visualizar dados para visualizar os dados na tabela.
Em Avançado, você pode especificar os seguintes campos:
Comportamento de gravação: define o comportamento de gravação quando a origem são arquivos de um armazenamento de dados baseado em arquivo. Você pode escolher Inserir, Upsert ou Procedimento armazenado.

Inserir: escolha esta opção se os dados de origem tiverem inserções.
Upsert: Escolha esta opção se os dados de origem tiverem inserções e atualizações.
Use TempDB: especifique se deseja usar uma tabela temporária global ou uma tabela física como a tabela provisória para upsert. Por padrão, o serviço usa a tabela temporária global como a tabela provisória e essa caixa de seleção está marcada.
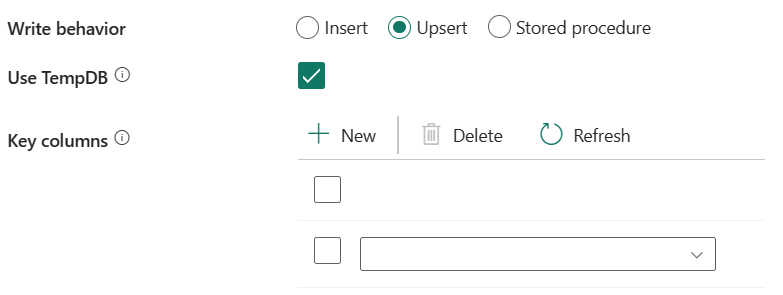
Selecionar esquema de banco de dados do usuário: Quando a caixa de seleção Usar TempDB não estiver marcada, especifique o esquema provisório para criar uma tabela provisória se uma tabela física for usada.
Nota
Você deve ter permissão para criar e excluir tabelas. Por padrão, uma tabela provisória compartilhará o mesmo esquema que uma tabela de destino.
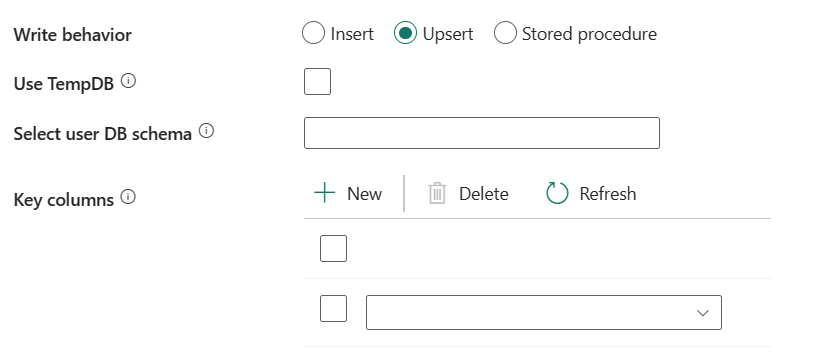
Colunas de chave: especifique os nomes das colunas para identificação de linha exclusiva. Uma única chave ou uma série de chaves podem ser usadas. Se não for especificado, a chave primária será usada.
Procedimento armazenado: use o procedimento armazenado que define como aplicar dados de origem em uma tabela de destino. Este procedimento armazenado é invocado por lote.
Nome do procedimento armazenado: selecione o procedimento armazenado ou especifique o nome do procedimento armazenado manualmente ao marcar a caixa Editar para ler dados da tabela de origem.
Parâmetros de procedimento armazenado: especifique valores para parâmetros de procedimento armazenado. Os valores permitidos são pares de nome ou valor. Os nomes e o invólucro dos parâmetros devem corresponder aos nomes e invólucros dos parâmetros do procedimento armazenado.
Bloqueio de tabela de inserção em massa: escolha Sim ou Não. Use essa configuração para melhorar o desempenho da cópia durante uma operação de inserção em massa em uma tabela sem índice de vários clientes. Para obter mais informações, vá para BULK INSERT (Transact-SQL)
Opção Tabela: Especifica se a tabela de destino deve ser criada automaticamente se a tabela não existir com base no esquema de origem. Escolha Nenhum ou Criar tabela automaticamente. A criação automática de tabelas não é suportada quando o destino especifica um procedimento armazenado.
Script de pré-cópia: especifique um script para a Atividade de Cópia ser executada antes de gravar dados em uma tabela de destino em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados.
Tempo limite de gravação do lote: especifique o tempo de espera para que a operação de inserção do lote seja concluída antes que ela atinja o tempo limite. O valor permitido é timepan. O valor padrão é "00:30:00" (30 minutos).
Tamanho do lote de gravação: especifique o número de linhas a serem inseridas na tabela SQL por lote. O valor permitido é inteiro (número de linhas). Por padrão, o serviço determina dinamicamente o tamanho de lote apropriado com base no tamanho da linha.
Máximo de conexões simultâneas: especifique o limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas.
Desativar análise de métricas de desempenho: essa configuração é usada para coletar métricas, como DTU, DWU, RU e assim por diante, para copiar recomendações e otimização de desempenho. Se você estiver preocupado com esse comportamento, marque esta caixa de seleção.
Mapeamento
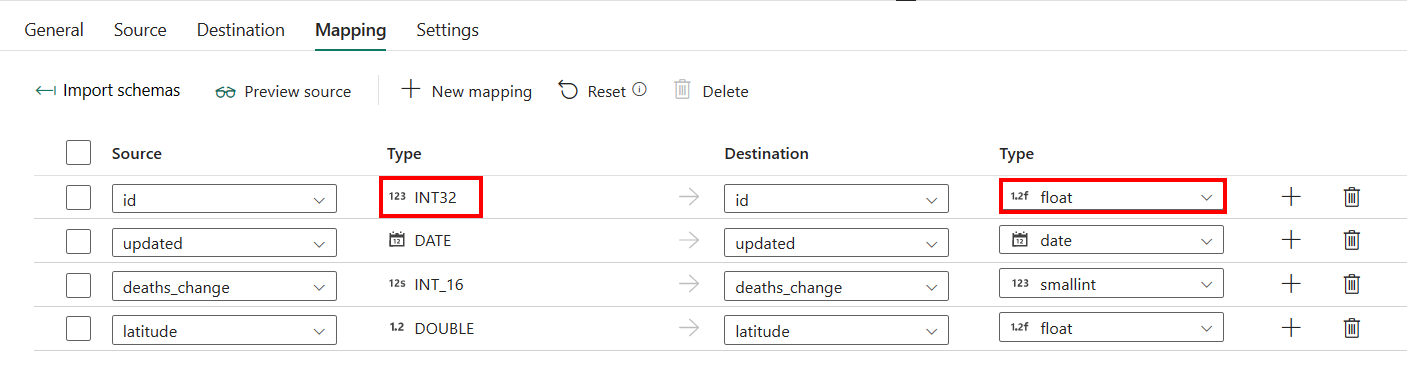
Para a configuração da guia Mapeamento, se você não aplicar o Banco de Dados SQL do Azure com a criação automática de tabela como destino, vá para Mapeamento.
Se você aplicar o Banco de Dados SQL do Azure com a tabela de criação automática como destino, exceto a configuração em Mapeamento, poderá editar o tipo para suas colunas de destino. Depois de selecionar Importar esquemas, você pode especificar o tipo de coluna no seu destino.
Por exemplo, o tipo da coluna ID na origem é int, e você pode alterá-lo para o tipo float ao mapear para a coluna de destino.
Definições
Para Configuração da guia Configurações , vá para Configurar suas outras configurações na guia Configurações.
Cópia paralela do Banco de Dados SQL do Azure
O conector do Banco de Dados SQL do Azure na atividade de cópia fornece particionamento de dados interno para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.
Quando você habilita a cópia particionada, a atividade de cópia executa consultas paralelas na fonte do Banco de Dados SQL do Azure para carregar dados por partições. O grau paralelo é controlado pelo Grau de paralelismo de cópia na guia Configurações de atividade de cópia. Por exemplo, se você definir Grau de paralelismo de cópia como quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas, e cada consulta recuperará uma parte dos dados do Banco de Dados SQL do Azure.
Sugere-se que habilite a cópia paralela com particionamento de dados, especialmente quando carrega uma grande quantidade de dados do Banco de Dados SQL do Azure. A seguir estão sugeridas configurações para diferentes cenários. Ao copiar dados para o armazenamento de dados baseado em arquivo, é recomendável gravar em uma pasta como vários arquivos (especifique apenas o nome da pasta), caso em que o desempenho é melhor do que gravar em um único arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carga completa a partir de uma mesa grande, com divisórias físicas. | Opção de partição: Partições físicas da tabela. Durante a execução, o serviço deteta automaticamente as partições físicas e copia os dados por partições. Para verificar se a sua tabela tem partição física ou não, pode consultar esta consulta. |
| Carga completa a partir de uma tabela grande, sem partições físicas, enquanto com uma coluna inteira ou datetime para particionamento de dados. | Opções de partição: Partição de intervalo dinâmico. Coluna de partição (opcional): especifique a coluna usada para particionar dados. Se não for especificado, o índice ou a coluna de chave primária será usado. Limite superior da partição e limite inferior da partição (opcional): Especifique se deseja determinar o passo da partição. Isso não é para filtrar as linhas na tabela, todas as linhas na tabela serão particionadas e copiadas. Se não for especificado, as atividades de cópia detetarão automaticamente os valores. Por exemplo, se a coluna de partição "ID" tiver valores que variam de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com cópia paralela como 4, o serviço recuperará dados por 4 partições - IDs no intervalo <=20, [21, 50], [51, 80] e >=81, respectivamente. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, enquanto com uma coluna inteira ou data/data/hora para particionamento de dados. | Opções de partição: Partição de intervalo dinâmico. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Limite superior da partição e limite inferior da partição (opcional): Especifique se deseja determinar o passo da partição. Isso não é para filtrar as linhas na tabela, todas as linhas no resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detetará automaticamente o valor. Por exemplo, se a coluna de partição "ID" tiver valores que variam de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com cópia paralela como 4, o serviço recuperará dados por 4 partições - IDs no intervalo <=20, [21, 50], [51, 80] e >=81, respectivamente. Aqui estão mais consultas de exemplo para diferentes cenários: • Consulte toda a tabela: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Consulta a partir de uma tabela com seleção de colunas e filtros adicionais de cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Consulta com subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Consulta com partição em subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Práticas recomendadas para carregar dados com a opção de partição:
- Escolha uma coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar distorção de dados.
- Se a tabela tiver partição interna, use a opção de partição Partições físicas da tabela para obter um melhor desempenho.
Exemplo de consulta para verificar a partição física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se a tabela tiver partição física, você verá "HasPartition" como "sim" como a seguir.

Resumo da tabela
As tabelas a seguir contêm mais informações sobre a atividade de cópia no Banco de Dados SQL do Azure.
Origem
| Nome | Descrição | valor | Necessário | Propriedade de script JSON |
|---|---|---|---|---|
| Tipo de armazenamento de dados | Seu tipo de armazenamento de dados. | Externa | Sim | / |
| Ligação | Sua conexão com o armazenamento de dados de origem. | <A sua ligação> | Sim | ligação |
| Tipo de ligação | O seu tipo de ligação. Selecione Banco de Dados SQL do Azure. | Base de Dados SQL do Azure | Sim | / |
| Tabela | Sua tabela de dados de origem. | <Nome da tabela de destino> | Sim | Esquema tabela |
| Utilizar consulta | A consulta SQL personalizada para ler dados. | • Nenhum • Consulta • Procedimento armazenado |
Não | • sqlReaderQuery • sqlReaderStoredProcedureName, storedProcedureParameters |
| Tempo limite da consulta | O tempo limite para a execução do comando de consulta, padrão, é de 120 minutos. | timespan | Não | queryTimeout |
| Nível de isolamento | Especifica o comportamento de bloqueio de transação para a fonte SQL. | • Nenhum • ReadCommitted • ReadUncommitted • Leitura repetível • Serializável • Instantâneo |
Não | Nível de isolamento |
| Opção de partição | As opções de particionamento de dados usadas para carregar dados do Banco de Dados SQL do Azure. | • Nenhum • Divisórias físicas de mesa • Alcance dinâmico |
Não | partitionOption: • PhysicalPartitionsOfTable • Gama dinâmica |
| Colunas adicionais | Adicione mais colunas de dados para armazenar o caminho relativo ou o valor estático dos arquivos de origem. A expressão é suportada para este último. | • Nome • Valor |
Não | adicionaisColunas: • nome • valor |
Destino
| Nome | Descrição | valor | Necessário | Propriedade de script JSON |
|---|---|---|---|---|
| Tipo de armazenamento de dados | Seu tipo de armazenamento de dados. | Externa | Sim | / |
| Ligação | Sua conexão com o armazenamento de dados de destino. | <A sua ligação > | Sim | ligação |
| Tipo de ligação | O seu tipo de ligação. Selecione Banco de Dados SQL do Azure. | Base de Dados SQL do Azure | Sim | / |
| Tabela | Sua tabela de dados de destino. | <Nome da tabela de destino> | Sim | Esquema tabela |
| Comportamento de escrita | Define o comportamento de gravação quando a origem são arquivos de um armazenamento de dados baseado em arquivo. | • Inserir • Upsert • Procedimento armazenado |
Não | writeBehavior: • inserir • Upsert • sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureParameters |
| Bloqueio de tabela de inserção em massa | Use essa configuração para melhorar o desempenho da cópia durante uma operação de inserção em massa em uma tabela sem índice de vários clientes. | Yes ou No. | Não | sqlWriterUseTableLock: verdadeiro ou falso |
| Opção de tabela | Especifica se a tabela de destino deve ser criada automaticamente se ela não existir com base no esquema de origem. | • Nenhum • Criação automática de tabelas |
Não | tableOption: • Criação automática |
| Script de pré-cópia | Um script para a Atividade de Cópia ser executada antes de gravar dados em uma tabela de destino em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados. | <script de pré-cópia> (string) |
Não | pré-CopyScript |
| Tempo limite de gravação em lote | O tempo de espera para que a operação de inserção de lote termine antes que ela atinja o tempo limite. O valor permitido é timepan. O valor padrão é "00:30:00" (30 minutos). | timespan | Não | writeBatchTimeout |
| Tamanho do lote de gravação | O número de linhas a serem inseridas na tabela SQL por lote. Por padrão, o serviço determina dinamicamente o tamanho de lote apropriado com base no tamanho da linha. | <número de linhas> (inteiro) |
Não | writeBatchSize |
| Máximo de conexões simultâneas | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | <limite superior de conexões simultâneas> (inteiro) |
Não | maxConcurrentConnections |
| Desative a análise de métricas de desempenho | Essa configuração é usada para coletar métricas, como DTU, DWU, RU e assim por diante, para otimização e recomendações de desempenho de cópia. Se você estiver preocupado com esse comportamento, marque esta caixa de seleção. | Selecionar ou desmarcar | Não | disableMetricsCollection: verdadeiro ou falso |