Relatórios de faturamento e utilização do Apache Spark no Microsoft Fabric
Aplica-se a:✅ Engenharia de Dados e Ciência de Dados no Microsoft Fabric
Este artigo explica a utilização de computação e os relatórios do ApacheSpark, que alimenta as cargas de trabalho de engenharia e ciência de dados de malha no Microsoft Fabric. A utilização de computação inclui operações lakehouse como visualização de tabela, carga para delta, execuções de notebook a partir da interface, execuções agendadas, execuções acionadas por etapas de notebook nos pipelines e execuções de definição de trabalho do Apache Spark.
Como outras experiências no Microsoft Fabric, a Engenharia de Dados também usa a capacidade associada a um espaço de trabalho para executar esses trabalhos e suas cobranças gerais de capacidade aparecem no portal do Azure em sua assinatura do Microsoft Cost Management . Para saber mais sobre a faturação do Fabric, consulte Compreender a sua fatura do Azure numa capacidade do Fabric.
Capacidade do tecido
Você, como usuário, pode comprar uma capacidade de malha do Azure especificando usando uma assinatura do Azure. O tamanho da capacidade determina a quantidade de poder de computação disponível. Para o Apache Spark for Fabric, cada comprado se traduz em 2 VCores Apache Spark. Por exemplo, se você comprar uma capacidade de malha F128, isso se traduzirá em 256 SparkVCores. Uma capacidade de malha é compartilhada entre todos os espaços de trabalho adicionados a ela e na qual a computação total do Apache Spark permitida é compartilhada entre todos os trabalhos enviados de todos os espaços de trabalho associados a uma capacidade. Para entender sobre os diferentes SKUs, alocação de núcleos e limitação no Spark, consulte Limites de simultaneidade e filas no Apache Spark for Microsoft Fabric.
Configuração de computação do Spark e capacidade adquirida
O Apache Spark compute for Fabric oferece duas opções quando se trata de configuração de computação.
Pools iniciais: esses pools padrão são uma maneira rápida e fácil de usar o Spark na plataforma Microsoft Fabric em segundos. Você pode usar as sessões do Spark imediatamente, em vez de esperar que o Spark configure os nós para você, o que ajuda você a fazer mais com dados e obter insights mais rapidamente. Quando se trata de faturamento e consumo de capacidade, você é cobrado quando começa a executar sua definição de trabalho de notebook ou Spark ou operação lakehouse. Você não será cobrado pelo tempo em que os clusters estiverem ociosos no pool.
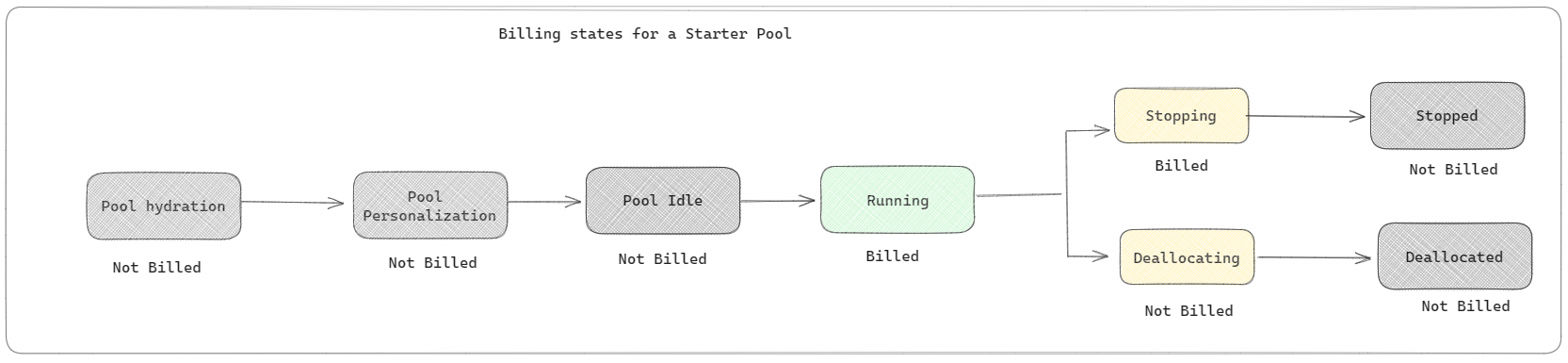
Por exemplo, se você enviar um trabalho de bloco de anotações para um pool inicial, será cobrado apenas pelo período em que a sessão do bloco de anotações estiver ativa. O tempo faturado não inclui o tempo ocioso ou o tempo necessário para personalizar a sessão com o contexto do Spark. Para entender mais sobre como configurar pools iniciais com base na SKU de capacidade de malha comprada, visite Configurando pools iniciais com base na capacidade de malha
Pools de faíscas: são pools personalizados, onde você pode personalizar o tamanho dos recursos necessários para suas tarefas de análise de dados. Você pode dar um nome ao seu pool Spark e escolher quantos e quão grandes são os nós (as máquinas que fazem o trabalho). Você também pode dizer ao Spark como ajustar o número de nós dependendo de quanto trabalho você tem. A criação de uma piscina Spark é gratuita; você só paga quando executa um trabalho do Spark no pool e, em seguida, o Spark configura os nós para você.
- O tamanho e o número de nós que você pode ter em seu pool personalizado do Spark dependem da capacidade do Microsoft Fabric. Você pode usar esses Spark VCores para criar nós de tamanhos diferentes para seu pool Spark personalizado, desde que o número total de Spark VCores não exceda 128.
- As piscinas de faísca são cobradas como piscinas iniciais; você não paga pelos pools personalizados do Spark que criou, a menos que tenha uma sessão ativa do Spark criada para executar um bloco de anotações ou uma definição de trabalho do Spark. Você só é cobrado pela duração das execuções de trabalho. Você não será cobrado por estágios como a criação e a desalocação do cluster após a conclusão do trabalho.

Por exemplo, se você enviar um trabalho de bloco de anotações para um pool personalizado do Spark, será cobrado apenas pelo período de tempo em que a sessão estiver ativa. A cobrança dessa sessão do bloco de anotações é interrompida quando a sessão do Spark é interrompida ou expirada. Você não é cobrado pelo tempo necessário para adquirir instâncias de cluster da nuvem ou pelo tempo necessário para inicializar o contexto do Spark. Para entender mais sobre como configurar pools Spark com base na SKU de capacidade de malha comprada, visite Configurando pools com base na capacidade de malha


Nota
O período de tempo de expiração da sessão padrão para os Starter Pools e Spark Pools que você cria é definido como 20 minutos. Se você não usar sua piscina Spark por 2 minutos após a sessão expirar, sua piscina Spark será deslocalizada. Para interromper a sessão e a cobrança depois de concluir a execução do bloco de anotações antes do período de expiração da sessão, clique no botão Interromper sessão no menu Início dos blocos de anotações ou vá para a página do hub de monitoramento e interrompa a sessão.
Relatório de uso de computação do Spark
O aplicativo Microsoft Fabric Capacity Metrics fornece visibilidade sobre o uso da capacidade para todas as cargas de trabalho do Fabric em um só lugar. Ele é usado por administradores de capacidade para monitorar o desempenho de cargas de trabalho e seu uso, em comparação com a capacidade comprada.
Depois de instalar o aplicativo, selecione o tipo de item Notebook,Lakehouse,Spark Job Definition na lista suspensa Select item type:. O gráfico de gráfico de faixa de opções multimétrica agora pode ser ajustado para um período de tempo desejado para entender o uso de todos esses itens selecionados.
Todas as operações relacionadas ao Spark são classificadas como operações em segundo plano. O consumo de capacidade do Spark é exibido em um bloco de anotações, uma definição de trabalho do Spark ou uma casa de lago, e é agregado por nome da operação e item. Por exemplo: Se você executar um trabalho de bloco de anotações, poderá ver a execução do bloco de anotações, as CUs usadas pelo bloco de anotações (Total Spark VCores/2 como 1 dá 2 Spark VCores), duração que o trabalho tomou no relatório.
 Para entender mais sobre os relatórios de uso de capacidade do Spark, consulte Monitorar o consumo de capacidade do Apache Spark
Para entender mais sobre os relatórios de uso de capacidade do Spark, consulte Monitorar o consumo de capacidade do Apache Spark
Exemplo de faturação
Considere o seguinte cenário:
Há um Capacity C1 que hospeda um Fabric Workspace W1 e este Workspace contém Lakehouse LH1 e Notebook NB1.
- Qualquer operação Spark que o notebook (NB1) ou lakehouse (LH1) executa é relatada em relação à capacidade C1.
Estendendo este exemplo para um cenário onde há outro Capacity C2 que hospeda um Fabric Workspace W2 e vamos dizer que esse Workspace contém uma definição de trabalho Spark (SJD1) e Lakehouse (LH2).
- Se a definição de trabalho do Spark (SDJ2) do espaço de trabalho (W2) ler dados do lakehouse (LH1), o uso será relatado em relação à capacidade C2 associada ao espaço de trabalho (W2) que hospeda o item.
- Se o Notebook (NB1) executar uma operação de leitura do Lakehouse(LH2), o consumo de capacidade será relatado em relação à Capacidade C1 que está alimentando o espaço de trabalho W1 que hospeda o item do notebook.