O processo de pipelines de implantação
O processo de implantação permite clonar conteúdo de um estágio no pipeline de implantação para outro, normalmente do desenvolvimento para o teste e do teste para a produção.
Durante a implantação, o Microsoft Fabric copia o conteúdo do estágio de origem para o estágio de destino. As conexões entre os itens copiados são mantidas durante o processo de cópia. O Fabric também aplica as regras de implantação configuradas ao conteúdo atualizado no estágio de destino. A implantação de conteúdo pode demorar um pouco, dependendo do número de itens que estão sendo implantados. Durante esse tempo, você pode navegar para outras páginas no portal, mas não pode usar o conteúdo no estágio de destino.
Você também pode implantar conteúdo programaticamente, usando as APIs REST dos pipelines de implantação. Você pode saber mais sobre esse processo em Automatizar seu pipeline de implantação usando APIs e DevOps.
Nota
A nova interface de utilizador do pipeline de implantação está atualmente em pré-visualização. Para ativar ou usar a nova interface do usuário, consulte Começar a usar a nova interface do usuário.
Há duas partes principais do processo de pipelines de implantação:
Definir a estrutura do pipeline de implantação
Ao criar um pipeline, você define quantos estágios deseja e como eles devem ser chamados. Você também pode tornar público um ou mais palcos. O número de estágios e seus nomes são permanentes e não podem ser alterados após a criação do pipeline. No entanto, você pode alterar o status público de um palco a qualquer momento.
Para definir um pipeline, siga as instruções em Criar um pipeline de implantação.
Adicionar conteúdo aos estágios
Você pode adicionar conteúdo a um estágio de pipeline de duas maneiras:
Atribuir um espaço de trabalho a um palco vazio
Quando você atribui conteúdo a um estágio vazio, um novo espaço de trabalho é criado em uma capacidade para o estágio no qual você implanta. Todos os metadados nos relatórios, painéis e modelos semânticos do espaço de trabalho original são copiados para o novo espaço de trabalho no estágio em que você está implantando.
Após a conclusão da implantação, atualize os modelos semânticos para que você possa usar o conteúdo recém-copiado. A atualização do modelo semântico é necessária porque os dados não são copiados de um estágio para outro. Para entender quais propriedades de item são copiadas durante o processo de implantação e quais propriedades de item não são copiadas, revise a seção de propriedades de item copiadas durante a implantação .
Para obter instruções sobre como atribuir e cancelar a atribuição de espaços de trabalho a estágios de pipeline de implantação, consulte Atribuir um espaço de trabalho a um pipeline de implantação do Microsoft Fabric.
Criar uma área de trabalho
Na primeira vez que você implanta conteúdo, os pipelines de implantação verificam se você tem permissões.
Se você tiver permissões, o conteúdo do espaço de trabalho será copiado para o estágio em que você está implantando e um novo espaço de trabalho para esse estágio será criado na capacidade.
Se você não tiver permissões, o espaço de trabalho será criado, mas o conteúdo não será copiado. Você pode pedir a um administrador de capacidade para adicionar seu espaço de trabalho a uma capacidade ou solicitar permissões de atribuição para a capacidade. Mais tarde, quando o espaço de trabalho for atribuído a uma capacidade, você poderá implantar conteúdo nesse espaço de trabalho.
Se você estiver usando a PPU (Premium por usuário), seu espaço de trabalho será automaticamente associado à sua PPU. Nesses casos, as permissões não são necessárias. No entanto, se você criar um espaço de trabalho com uma PPU, somente outros usuários da PPU poderão acessá-la. Além disso, apenas os usuários de PPU podem consumir conteúdo criado em tais espaços de trabalho.
Espaço de trabalho e propriedade do conteúdo
O usuário de implantação torna-se automaticamente o proprietário dos modelos semânticos clonados e o único administrador do novo espaço de trabalho.
Implantar conteúdo de um estágio para outro
Há várias maneiras de implantar conteúdo de um estágio para outro. Você pode implantar todo o conteúdo ou selecionar quais itens implantar.
Você pode implantar conteúdo em qualquer estágio adjacente, em qualquer direção.
A implantação de conteúdo de um pipeline de produção em funcionamento em um estágio que tenha um espaço de trabalho existente inclui as seguintes etapas:
Implantação de novo conteúdo como uma adição ao conteúdo já existente.
Implantação de conteúdo atualizado para substituir parte do conteúdo já existente.
Processo de implementação
Quando o conteúdo do estágio de origem é copiado para o estágio de destino, o Fabric identifica o conteúdo existente no estágio de destino e o substitui. Para identificar qual item de conteúdo precisa ser substituído, os pipelines de implantação usam a conexão entre o item pai e seus clones. Essa conexão é mantida quando um novo conteúdo é criado. A operação de substituição substitui apenas o conteúdo do item. O ID, a URL e as permissões do item permanecem inalterados.
No estágio de destino, as propriedades do item que não são copiadas permanecem como eram antes da implantação. Novos conteúdos e novos itens são copiados do estágio de origem para o estágio de destino.
Vinculação automática
No Fabric, quando os itens estão conectados, um dos itens depende do outro. Por exemplo, um relatório sempre depende do modelo semântico ao qual está conectado. Um modelo semântico pode depender de outro modelo semântico e também pode ser conectado a vários relatórios que dependem dele. Se houver uma conexão entre dois itens, os pipelines de implantação sempre tentarão manter essa conexão.
Vinculação automática no mesmo espaço de trabalho
Durante a implantação, os pipelines de implantação verificam se há dependências. A implantação é bem-sucedida ou falha, dependendo do local do item que fornece os dados dos quais o item implantado depende.
O item vinculado existe no estágio de destino - Os pipelines de implantação conectam automaticamente (vinculam automaticamente) o item implantado ao item do qual ele depende no estágio implantado. Por exemplo, se você implantar um relatório paginado do desenvolvimento ao teste e o relatório estiver conectado a um modelo semântico que foi implantado anteriormente no estágio de teste, ele se conectará automaticamente ao modelo semântico no estágio de teste.
O item vinculado não existe no estágio de destino - Os pipelines de implantação falham em uma implantação se um item tiver uma dependência de outro item e o item que fornece os dados não for implantado e não residir no estágio de destino. Por exemplo, se você implantar um relatório do desenvolvimento ao teste e o estágio de teste não contiver seu modelo semântico, a implantação falhará. Para evitar implantações com falha devido a itens dependentes não serem implantados, use o botão Selecionar relacionado . Selecionar relacionado seleciona automaticamente todos os itens relacionados que fornecem dependências para os itens que você está prestes a implantar.
A vinculação automática funciona apenas com itens que são suportados por pipelines de implantação e residem na malha. Para exibir as dependências de um item, no menu Mais opções do item, selecione Exibir linhagem.
Vinculação automática entre espaços de trabalho
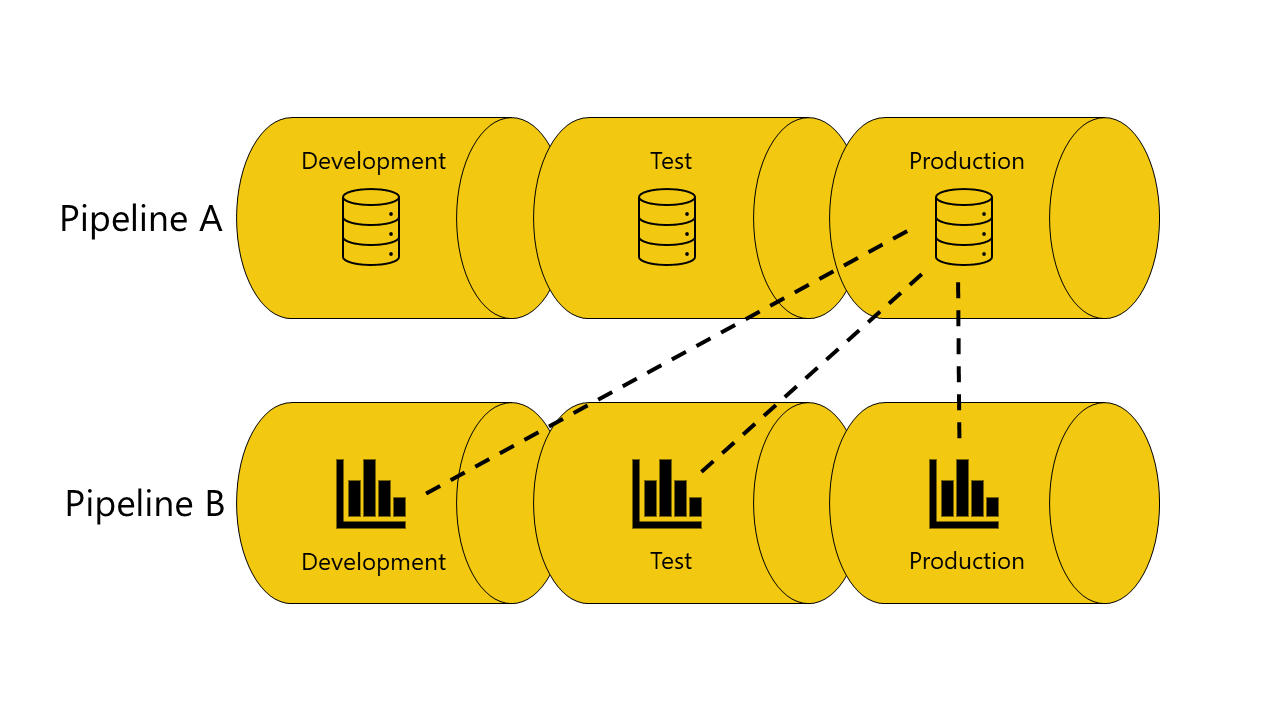
Os pipelines de implantação vinculam automaticamente os itens que estão conectados entre pipelines, se estiverem no mesmo estágio de pipeline. Quando você implanta esses itens, os pipelines de implantação tentam estabelecer uma nova conexão entre o item implantado e o item ao qual ele está conectado no outro pipeline. Por exemplo, se você tiver um relatório no estágio de teste do pipeline A conectado a um modelo semântico no estágio de teste do pipeline B, os pipelines de implantação reconhecerão essa conexão.
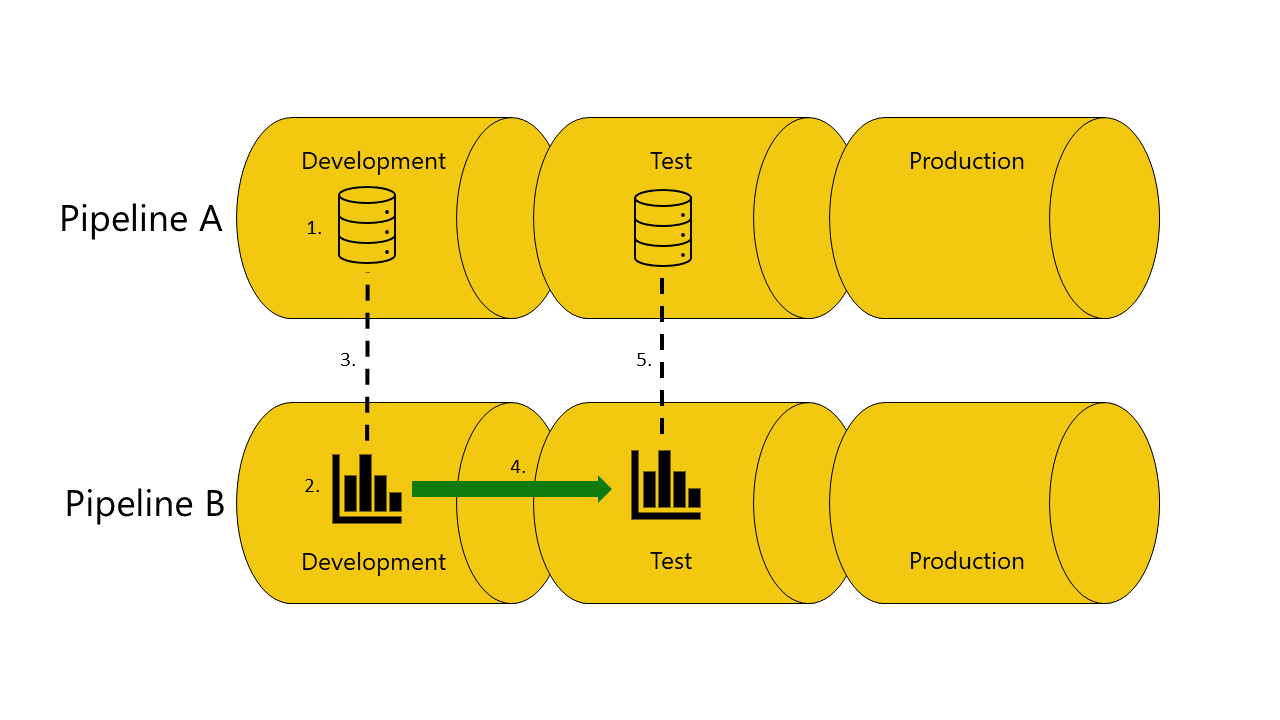
Aqui está um exemplo com ilustrações que ajudam a demonstrar como funciona a vinculação automática entre pipelines:
Você tem um modelo semântico no estágio de desenvolvimento do pipeline A.
Você também tem um relatório no estágio de desenvolvimento do pipeline B.
Seu relatório no pipeline B está conectado ao seu modelo semântico no pipeline A. Seu relatório depende desse modelo semântico.
Você implanta o relatório no pipeline B desde o estágio de desenvolvimento até o estágio de teste.
A implantação é bem-sucedida ou falha, dependendo se você tem ou não uma cópia do modelo semântico do qual ela depende no estágio de teste do pipeline A:
Se você tiver uma cópia do modelo semântico do qual o relatório depende no estágio de teste do pipeline A:
A implantação é bem-sucedida e os pipelines de implantação conectam (vinculam automaticamente) o relatório no estágio de teste do pipeline B ao modelo semântico no estágio de teste do pipeline A.
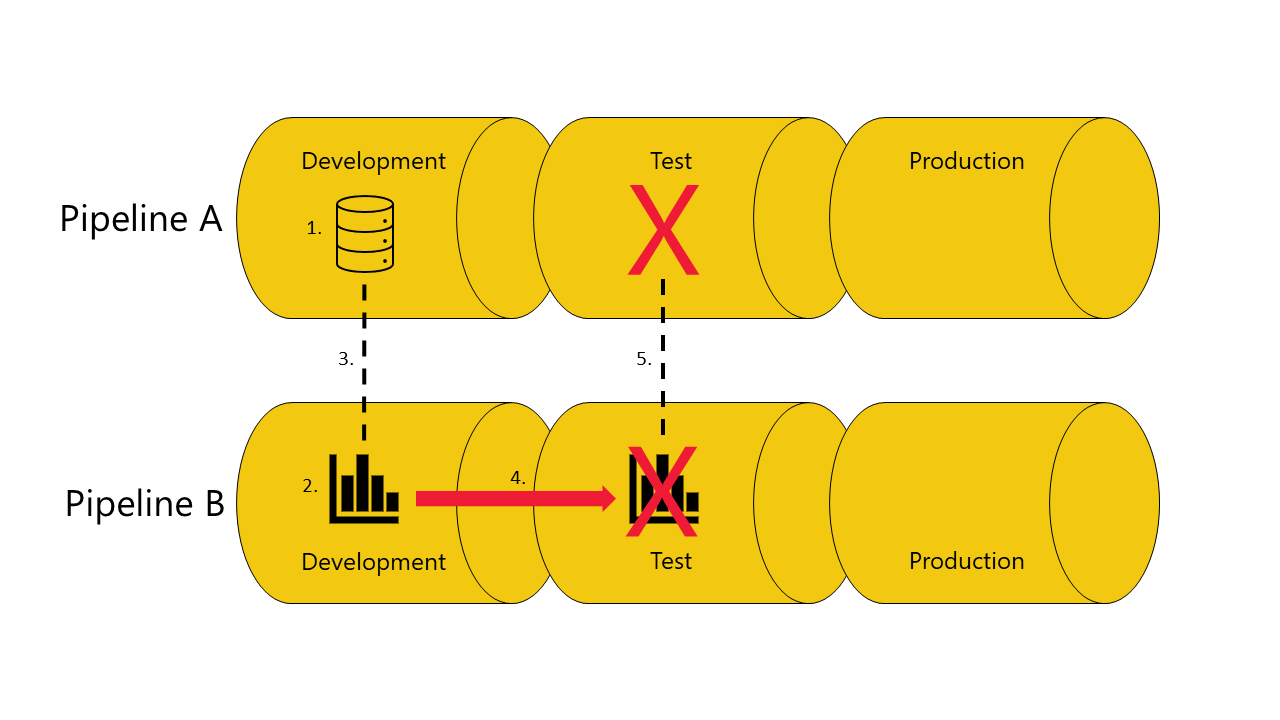
Se você não tiver uma cópia do modelo semântico do qual o relatório depende no estágio de teste do pipeline A:
A implantação falha porque os pipelines de implantação não podem conectar (vincular automaticamente) o relatório no estágio de teste no pipeline B ao modelo semântico do qual ele depende no estágio de teste do pipeline A.
Evite usar a vinculação automática
Em alguns casos, talvez você não queira usar a vinculação automática. Por exemplo, se você tiver um pipeline para desenvolver modelos semânticos organizacionais e outro para criar relatórios. Nesse caso, talvez você queira que todos os relatórios estejam sempre conectados a modelos semânticos no estágio de produção do pipeline ao qual pertencem. Nesse caso, evite usar o recurso de vinculação automática.
Há três métodos que você pode usar para evitar o uso da vinculação automática:
Não conecte o item aos estágios correspondentes. Quando os itens não estão conectados no mesmo estágio, os pipelines de implantação mantêm a conexão original. Por exemplo, se você tiver um relatório no estágio de desenvolvimento do pipeline B conectado a um modelo semântico no estágio de produção do pipeline A. Quando você implanta o relatório no estágio de teste do pipeline B, ele permanece conectado ao modelo semântico no estágio de produção do pipeline A.
Defina uma regra de parâmetro. Esta opção não está disponível para relatórios. Você só pode usá-lo com modelos semânticos e fluxos de dados.
Conecte seus relatórios, painéis e blocos a um modelo semântico de proxy ou fluxo de dados que não esteja conectado a um pipeline.
Autobinding e parâmetros
Os parâmetros podem ser usados para controlar as conexões entre modelos semânticos ou fluxos de dados e os itens dos quais eles dependem. Quando um parâmetro controla a conexão, a vinculação automática após a implantação não ocorre, mesmo quando a conexão inclui um parâmetro que se aplica à ID do modelo semântico ou do fluxo de dados ou à ID do espaço de trabalho. Nesses casos, você precisará revincular os itens após a implantação alterando o valor do parâmetro ou usando regras de parâmetro.
Nota
Se você estiver usando regras de parâmetro para revincular itens, os parâmetros deverão ser do tipo Text.
Atualizando dados
Os dados no item de destino, como um modelo semântico ou fluxo de dados, são mantidos quando possível. Se não houver alterações em um item que contém os dados, os dados serão mantidos como eram antes da implantação.
Em muitos casos, quando você tem uma pequena alteração, como adicionar ou remover uma tabela, o Fabric mantém os dados originais. Para interromper alterações de esquema ou alterações na conexão da fonte de dados, é necessária uma atualização completa.
Requisitos para implantação em um estágio com um espaço de trabalho existente
Qualquer usuário licenciado que seja um contribuidor dos espaços de trabalho de implantação de destino e de origem pode implantar conteúdo que reside em uma capacidade em um estágio com um espaço de trabalho existente. Para obter mais informações, consulte a seção Permissões .
Pastas em pipelines de implantação (visualização)
As pastas permitem que os usuários organizem e gerenciem com eficiência os itens do espaço de trabalho de uma maneira familiar. Quando você implanta conteúdo que contém pastas em um estágio diferente, a hierarquia de pastas dos itens aplicados é aplicada automaticamente.
Representação de pastas
- Nova interface do usuário de representação de pastas
- Interface do usuário de representação de pastas originais
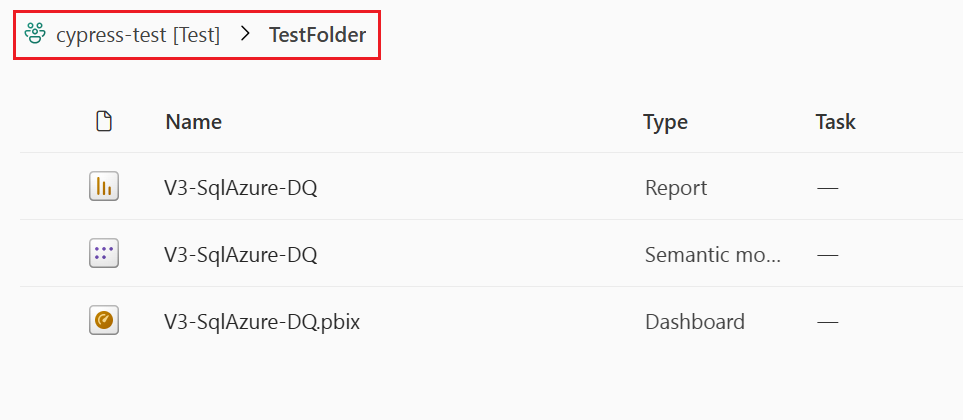
O conteúdo do espaço de trabalho é mostrado à medida que é estruturado no espaço de trabalho. As pastas são listadas e, para ver seus itens, você precisa selecionar a pasta. O caminho completo de um item é mostrado na parte superior da lista de itens. Como uma implantação é apenas de itens, você só pode selecionar uma pasta que contenha itens suportados. Selecionar uma pasta para implantação significa selecionar todos os seus itens e subpastas com seus itens para uma implantação.
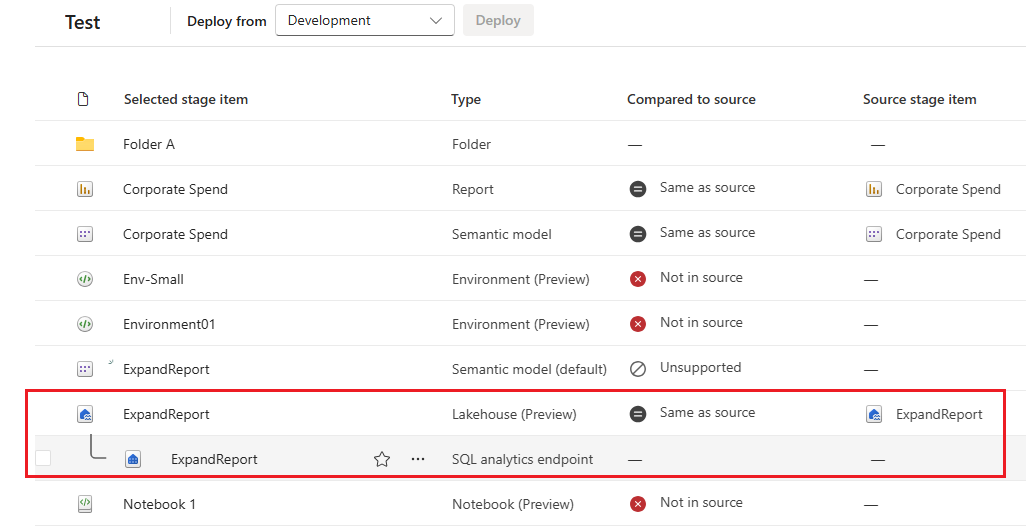
Esta imagem mostra o conteúdo de uma pasta dentro do espaço de trabalho. O nome completo do caminho da pasta é mostrado na parte superior da lista.
Nos pipelines de implantação, as pastas são consideradas parte do nome de um item (um nome de item inclui seu caminho completo). Quando um item é implantado, depois que o seu caminho foi alterado (movido da pasta A para a pasta B, por exemplo), o Deployment pipelines aplica essa alteração ao seu item emparelhado durante a implantação - o item emparelhado também será movido para a pasta B. Se a pasta B não existir no estágio em que estamos a implantar, ela será criada primeiro na sua área de trabalho. As pastas podem ser vistas e gerenciadas somente na página do espaço de trabalho.
Implante itens dentro de uma pasta a partir dessa pasta. Não é possível implantar itens de hierarquias diferentes ao mesmo tempo.
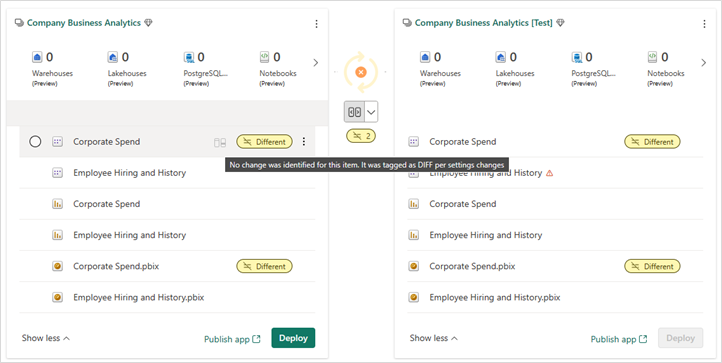
Identificar itens que foram movidos para pastas diferentes
Como as pastas são consideradas parte do nome do item, os itens movidos para uma pasta diferente no espaço de trabalho são identificados na página Pipelines de implantação como Diferentes quando comparados. Este item não aparece na janela de comparação, pois não é uma alteração de esquema, mas as configurações mudam.
- Item de pasta movido na nova interface do usuário
- Item de pasta movido na interface do usuário original

Pastas individuais não podem ser implantadas manualmente em pipelines de implantação. Sua implantação é acionada automaticamente quando pelo menos um de seus itens é implantado.
A hierarquia de pastas de itens emparelhados é atualizada somente durante a implantação. Durante a atribuição, após o processo de emparelhamento, a hierarquia de itens emparelhados ainda não é atualizada.
Como uma pasta é implantada somente se um de seus itens for implantado, uma pasta vazia não pode ser implantada.
A implantação de um item entre vários em uma pasta também atualiza a estrutura dos itens que não são implantados no estágio de destino, mesmo que os próprios itens não estejam sendo implantados.
Representação de item pai-filho
Eles aparecem apenas na nova interface do usuário. Tem a mesma aparência que no espaço de trabalho. A criança não é implantada, mas recriada no estágio de destino
Propriedades do item copiadas durante a implantação
Para obter uma lista de itens suportados, consulte Itens suportados de pipelines de implantação.
Durante a implantação, as seguintes propriedades de item são copiadas e substituem as propriedades do item no estágio de destino:
Fontes de dados (regras de implantação são suportadas)
Parâmetros (regras de implantação são suportadas)
Visuais de relatório
Páginas de relatório
Blocos do painel
Metadados do modelo
Relações de item
Os rótulos de sensibilidade são copiados somente quando uma das seguintes condições é atendida. Se essas condições não forem atendidas, os rótulos de sensibilidade não serão copiados durante a implantação.
Um novo item é implantado ou um item existente é implantado em um estágio vazio.
Nota
Nos casos em que a rotulagem padrão está habilitada no locatário e o rótulo padrão é válido, se o item que está sendo implantado for um modelo semântico ou fluxo de dados, o rótulo será copiado do item de origem só se o rótulo tiver proteção. Se o rótulo não estiver protegido, o rótulo padrão será aplicado ao modelo semântico de destino ou fluxo de dados recém-criado.
O item de origem tem um rótulo com proteção e o item de destino não. Nesse caso, uma janela pop-up pede consentimento para substituir o rótulo de sensibilidade alvo.
Propriedades do item que não são copiadas
As seguintes propriedades de item não são copiadas durante a implantação:
Dados - Os dados não são copiados. Apenas os metadados são copiados
URL
ID
Permissões - Para um espaço de trabalho ou um item específico
Configurações do espaço de trabalho - Cada estágio tem seu próprio espaço de trabalho
Conteúdo e configurações do aplicativo - Para atualizar seus aplicativos, consulte Atualizar conteúdo para aplicativos do Power BI
As seguintes propriedades do modelo semântico também não são copiadas durante a implantação:
Atribuição de função
Agenda de atualização
Credenciais da origem de dados
Configurações de cache de consulta (pode ser herdada da capacidade)
Configurações de endosso
Recursos de modelo semântico suportados
Os pipelines de implantação oferecem suporte a muitos recursos de modelo semântico. Esta seção lista dois recursos de modelo semântico que podem aprimorar sua experiência de pipelines de implantação:
Atualização incremental
Os pipelines de implantação suportam atualização incremental, um recurso que permite grandes modelos semânticos atualizações mais rápidas e confiáveis, com menor consumo.
Com pipelines de implantação, você pode fazer atualizações em um modelo semântico com atualização incremental, mantendo dados e partições. Quando você implanta o modelo semântico, a política é copiada junto.
Para entender como a atualização incremental se comporta com fluxos de dados, consulte por que vejo duas fontes de dados conectadas ao meu fluxo de dados depois de usar regras de fluxo de dados?
Nota
As configurações de atualização incremental não são copiadas na Gen 1.
Ativando a atualização incremental em um pipeline
Para habilitar a atualização incremental, configure-a no Power BI Desktop e publique seu modelo semântico. Depois de publicar, a política de atualização incremental é semelhante em todo o pipeline e só pode ser criada no Power BI Desktop.
Depois que o pipeline estiver configurado com atualização incremental, recomendamos que você use o seguinte fluxo:
Faça alterações no arquivo .pbix no Power BI Desktop. Para evitar longos tempos de espera, você pode fazer alterações usando uma amostra de seus dados.
Carregue seu arquivo .pbix para o primeiro estágio (geralmente de desenvolvimento).
Implante seu conteúdo para a próxima etapa. Após a implantação, as alterações feitas serão aplicadas a todo o modelo semântico que você está usando.
Revise as alterações feitas em cada estágio e, depois de verificá-las, implante no próximo estágio até chegar ao estágio final.
Exemplos de utilização
A seguir estão alguns exemplos de como você pode integrar a atualização incremental com pipelines de implantação.
Crie um novo pipeline e conecte-o a um espaço de trabalho com um modelo semântico que tenha a atualização incremental habilitada.
Habilite a atualização incremental em um modelo semântico que já esteja em um espaço de trabalho de desenvolvimento .
Crie um pipeline a partir de um espaço de trabalho de produção que tenha um modelo semântico que use atualização incremental. Por exemplo, atribua o espaço de trabalho ao estágio de produção de um novo pipeline e use a implantação retroativa para implantar no estágio de teste e, em seguida, no estágio de desenvolvimento.
Publique um modelo semântico que usa atualização incremental em um espaço de trabalho que faz parte de um pipeline existente.
Limitações de atualização incremental
Para atualização incremental, os pipelines de implantação oferecem suporte apenas a modelos semânticos que usam metadados de modelo semântico aprimorados. Todos os modelos semânticos criados ou modificados com o Power BI Desktop implementam automaticamente metadados de modelo semântico avançados.
Ao republicar um modelo semântico em um pipeline ativo com a atualização incremental habilitada, as seguintes alterações resultam em falha de implantação devido ao potencial de perda de dados:
Republicar um modelo semântico que não usa atualização incremental, para substituir um modelo semântico que tenha a atualização incremental habilitada.
Renomear uma tabela que tenha a atualização incremental habilitada.
Renomeando colunas não calculadas em uma tabela com a atualização incremental habilitada.
Outras alterações, como adicionar uma coluna, remover uma coluna e renomear uma coluna calculada, são permitidas. No entanto, se as alterações afetarem a exibição, você precisará atualizar antes que a alteração seja visível.
Modelos compósitos
Usando modelos compostos, você pode configurar um relatório com várias conexões de dados.
Você pode usar a funcionalidade de modelos compostos para conectar um modelo semântico de malha a um modelo semântico externo, como o Azure Analysis Services. Para obter mais informações, consulte Usando o DirectQuery para modelos semânticos de malha e Azure Analysis Services.
Em um pipeline de implantação, você pode usar modelos compostos para conectar um modelo semântico a outro modelo semântico de malha externo ao pipeline.
Agregações automáticas
As agregações automáticas são criadas com base em agregações definidas pelo usuário e usam aprendizado de máquina para otimizar continuamente os modelos semânticos do DirectQuery para obter o máximo desempenho de consulta de relatório.
Cada modelo semântico mantém suas agregações automáticas após a implantação. Os pipelines de implantação não alteram a agregação automática de um modelo semântico. Isso significa que, se você implantar um modelo semântico com uma agregação automática, a agregação automática no estágio de destino permanecerá como está e não será substituída pela agregação automática implantada a partir do estágio de origem.
Para habilitar agregações automáticas, siga as instruções em configurar a agregação automática.
Tabelas híbridas
As tabelas híbridas são tabelas com atualização incremental que podem ter partições de importação e consulta direta. Durante uma implantação limpa, a política de atualização e as partições de tabela híbrida são copiadas. Quando você está implantando em um estágio de pipeline que já tem partições de tabela híbridas, somente a política de atualização é copiada. Para atualizar as partições, atualize a tabela.
Atualizar conteúdo para aplicativos do Power BI
Os aplicativos do Power BI são a maneira recomendada de distribuir conteúdo para consumidores de malha gratuitos. Você pode atualizar o conteúdo de seus aplicativos do Power BI usando um pipeline de implantação, oferecendo mais controle e flexibilidade quando se trata do ciclo de vida do seu aplicativo.
Crie um aplicativo para cada estágio do pipeline de implantação, para que você possa testar cada atualização do ponto de vista de um usuário final. Use o botão publicar ou exibir no cartão de espaço de trabalho para publicar ou exibir o aplicativo em um estágio de pipeline específico.
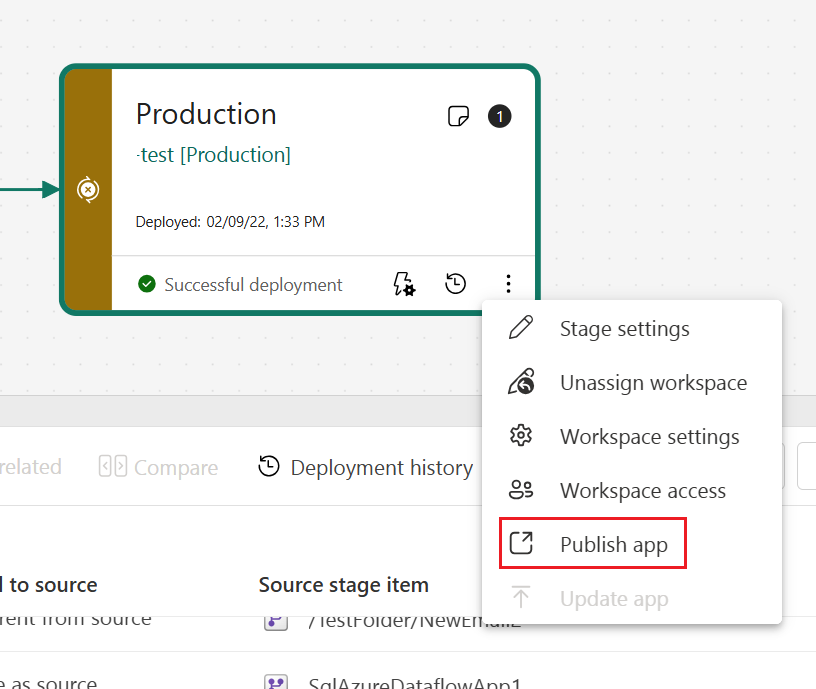

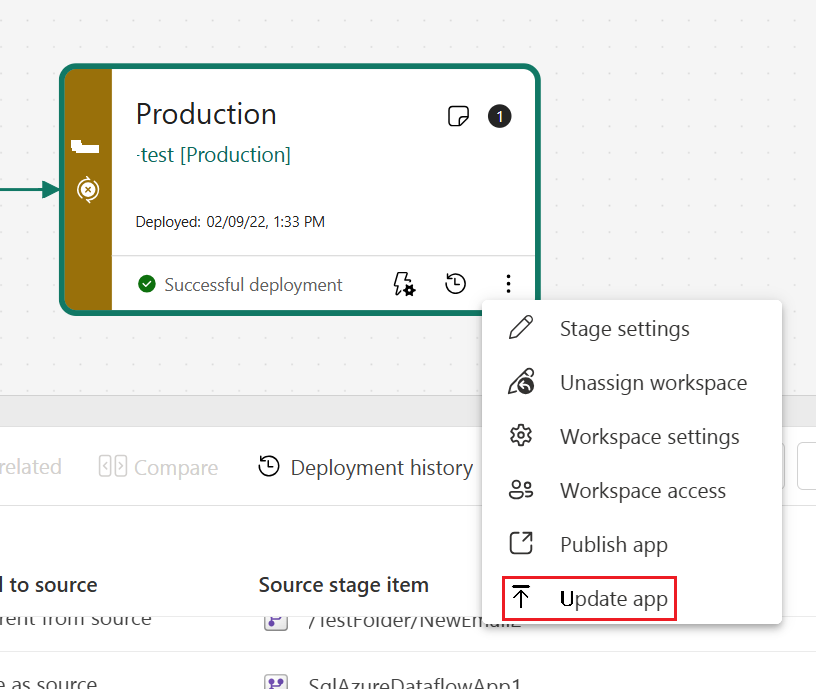
Na etapa de produção, você também pode atualizar a página do aplicativo no Fabric, para que todas as atualizações de conteúdo fiquem disponíveis para os usuários do aplicativo.
- Atualizar aplicativo - nova interface do usuário
- Atualizar aplicativo - interface do usuário original

Importante
O processo de implantação não inclui a atualização do conteúdo ou das configurações do aplicativo. Para aplicar alterações ao conteúdo ou às configurações, você precisa atualizar manualmente o aplicativo no estágio de pipeline necessário.
Permissões
As permissões são necessárias para o pipeline e para os espaços de trabalho atribuídos a ele. As permissões de pipeline e de espaço de trabalho são concedidas e gerenciadas separadamente.
Os pipelines têm apenas uma permissão, Admin, que é necessária para compartilhar, editar e excluir um pipeline.
Os espaços de trabalho têm permissões diferentes, também chamadas de funções. As funções de espaço de trabalho determinam o nível de acesso a um espaço de trabalho em um pipeline.
Os pipelines de implantação não oferecem suporte a grupos do Microsoft 365 como administradores de pipeline.
Para implantar de um estágio para outro no pipeline, você deve ser um administrador de pipeline e um colaborador, membro ou administrador dos espaços de trabalho atribuídos aos estágios envolvidos. Por exemplo, um administrador de pipeline ao qual não é atribuída uma função de espaço de trabalho pode exibir o pipeline e compartilhá-lo com outras pessoas. No entanto, esse usuário não pode exibir o conteúdo do espaço de trabalho no pipeline ou no serviço e não pode executar implantações.
Tabela de permissões
Esta seção descreve as permissões do pipeline de implantação. As permissões listadas nesta seção podem ter aplicativos diferentes em outros recursos do Fabric.
A permissão de pipeline de implantação mais baixa é administrador de pipeline e é necessária para todas as operações de pipeline de implantação.
| User | Permissões de pipeline | Comentários |
|---|---|---|
| Administrador de pipeline |
|
O acesso ao pipeline não concede permissões para exibir ou executar ações no conteúdo do espaço de trabalho. |
|
Visualizador de espaço de trabalho (e administrador de pipeline) |
|
Os membros do espaço de trabalho atribuídos à função Visualizador sem permissões de compilação , não podem acessar o modelo semântico ou editar o conteúdo do espaço de trabalho. |
|
Colaborador do espaço de trabalho (e administrador de pipeline) |
|
|
|
Membro do espaço de trabalho (e administrador de pipeline) |
|
Se a configuração bloquear republicar e desabilitar atualização de pacote localizada na seção de segurança do modelo semântico do locatário estiver habilitada, somente os proprietários de modelos semânticos poderão atualizar os modelos semânticos. |
|
Administrador de área de trabalho (e administrador de pipeline) |
|
Permissões concedidas
Quando você está implantando itens do Power BI, a propriedade do item implantado pode mudar. Analise a tabela a seguir para entender quem pode implantar cada item e como a implantação afeta a propriedade do item.
| Item de tecido | Permissão necessária para implantar um item existente | Propriedade do item após uma primeira implantação | Propriedade do item após a implantação em um estágio com o item |
|---|---|---|---|
| Modelo semântico | Membro do espaço de trabalho | O usuário que fez a implantação torna-se o proprietário | Inalterado |
| Fluxo de dados | Proprietário do fluxo de dados | O usuário que fez a implantação torna-se o proprietário | Inalterado |
| Datamart | Proprietário do Datamart | O usuário que fez a implantação torna-se o proprietário | Inalterado |
| Relatório paginado | Membro do espaço de trabalho | O usuário que fez a implantação torna-se o proprietário | O usuário que fez a implantação torna-se o proprietário |
Permissões necessárias para ações populares
A tabela a seguir lista as permissões necessárias para ações populares de pipeline de implantação. A menos que especificado de outra forma, para cada ação você precisa de todas as permissões listadas.
| Ação | Permissões obrigatórias |
|---|---|
| Exibir a lista de pipelines em sua organização | Nenhuma licença necessária (usuário livre) |
| Criar um pipeline | Um usuário com uma das seguintes licenças:
|
| Excluir um pipeline | Administrador de pipeline |
| Adicionar ou remover um usuário de pipeline | Administrador de pipeline |
| Atribuir um espaço de trabalho a um palco |
|
| Cancelar a atribuição de um espaço de trabalho a um palco | Uma das seguintes funções:
|
| Desdobrar num ambiente vazio (ver nota) |
|
| Implantar itens para o próximo estágio (consulte a nota) |
|
| Ver ou definir uma regra |
|
| Gerenciar configurações de pipeline | Administrador de pipeline |
| Exibir um estágio de pipeline |
|
| Exibir a lista de itens em um estágio | Administrador de pipeline |
| Comparar dois estágios |
|
| Ver o histórico de implementações | Administrador de pipeline |
Nota
Para implantar conteúdo no ambiente GCC, você precisa ser pelo menos um membro do espaço de trabalho de origem e de destino. A implantação como colaborador ainda não é suportada.
Considerações e limitações
Esta seção lista a maioria das limitações nos pipelines de implantação.
- O espaço de trabalho deve residir em uma capacidade de malha.
- O número máximo de itens que podem ser implantados em uma única implantação é 300.
- Não há suporte para o download de um arquivo .pbix após a implantação.
- Os grupos do Microsoft 365 não são suportados como administradores de pipeline.
- Quando você implanta um item do Power BI pela primeira vez, se outro item no estágio de destino tiver o mesmo nome e tipo (por exemplo, se ambos os arquivos forem relatórios), a implantação falhará.
- Para obter uma lista de limitações do espaço de trabalho, consulte as limitações de atribuição do espaço de trabalho.
- Para obter uma lista de itens suportados, consulte itens suportados. Qualquer item que não esteja na lista não é suportado.
- A implantação falhará se algum dos itens tiver dependências circulares ou próprias (por exemplo, o item A faz referência ao item B e o item B faz referência ao item A).
- Somente itens do Power BI podem ser implantados em um espaço de trabalho em uma região de capacidade diferente. Outros itens de malha não podem ser implantados em um espaço de trabalho em uma região de capacidade diferente.
- Não há suporte para relatórios PBIR.
Limitações do modelo semântico
Os conjuntos de dados que usam conectividade de dados em tempo real não podem ser implantados.
Não há suporte para um modelo semântico com o modo de conectividade DirectQuery ou Composite que usa variação ou tabelas automáticas de data/hora . Para obter mais informações, consulte O que posso fazer se tiver um conjunto de dados com DirectQuery ou modo de conectividade Composto, que usa tabelas de variação ou calendário?.
Durante a implantação, se o modelo semântico de destino estiver usando uma conexão ao vivo, o modelo semântico de origem também deverá usar esse modo de conexão.
Após a implantação, o download de um modelo semântico (do estágio em que foi implantado) não é suportado.
Para obter uma lista de limitações de regras de implantação, consulte Limitações de regras de implantação.
Se a vinculação automática estiver ativada, então:
- Não há suporte para consulta nativa e DirectQuery juntos. Isso inclui conjuntos de dados de proxy.
- A conexão da fonte de dados deve ser a primeira etapa na expressão de mashup.
Quando um modelo semântico Direct Lake é implantado, ele não se liga automaticamente aos itens no estágio de destino. Por exemplo, se um LakeHouse for uma fonte para um modelo semântico do DirectLake e ambos forem implantados no próximo estágio, o modelo semântico do DirectLake no estágio de destino ainda estará vinculado ao LakeHouse no estágio de origem. Use regras de fonte de dados para associá-lo a um item no estágio de destino. Outros tipos de modelos semânticos são automaticamente vinculados ao item emparelhado no estágio de destino.
Limitações do fluxo de dados
As configurações de atualização incremental não são copiadas na Gen 1.
Quando você está implantando um fluxo de dados em um estágio vazio, os pipelines de implantação criam um novo espaço de trabalho e definem o armazenamento de fluxo de dados como um armazenamento de blob de malha. O armazenamento de Blob é usado mesmo se o espaço de trabalho de origem estiver configurado para usar o armazenamento de data lake do Azure Gen2 (ADLS Gen2).
A entidade de serviço não é suportada para fluxos de dados.
Não há suporte para a implantação do modelo de dados comum (CDM).
Para limitações de regras de pipeline de implantação que afetam fluxos de dados, consulte Limitações de regras de implantação.
Se um fluxo de dados estiver sendo atualizado durante a implantação, a implantação falhará.
Se você comparar estágios durante uma atualização de fluxo de dados, os resultados serão imprevisíveis.
Limitações do Datamart
Não é possível implantar um datamart com rótulos de sensibilidade.
Você precisa ser o proprietário do datamart para implantar um datamart.
Conteúdos relacionados
Introdução aos pipelines de implantação.