Utilize modelos baseados em Azure Machine Learning
Os dados unificados em Dynamics 365 Customer Insights - Data são uma origem para a construção de modelos de aprendizagem automática que podem gerar conhecimentos empresariais adicionais. O Customer Insights - Data integra-se com o Azure Machine Learning para utilizar os seus próprios modelos personalizados.
Pré-requisitos
- Acesso ao Customer Insights - Data
- Subscrição do Azure Enterprise ativa
- Perfis de cliente unificados
- Exportação de tabela para armazenamento de Blobs do Azure configurado
Configurar a área de trabalho do Azure Machine Learning
Consulte criar uma área de Trabalho do Azure Machine Learning para opções diferentes para criar a área de trabalho. Para melhor desempenho, crie a área de trabalho numa região do Azure que esteja geograficamente mais próxima do ambiente de Customer Insights.
Aceda à sua área de trabalho através do Azure Machine Learning Studio. Existem várias formas de interagir com a sua área de trabalho.
Trabalhar com o designer do Azure Machine Learning
O estruturador do Azure Machine Learning fornece uma tela visual onde poderá arrastar e largar conjuntos de dados e módulos. Um pipeline de lote criado a partir do designer pode ser integrado no Customer Insights - Data se estiverem configurados em conformidade.
Trabalhar com o SDK do Azure Machine Learning
Cientistas de dados e programadores de IA usam o SDK do Azure Machine Learning para construir fluxos de trabalho de aprendizagem automática. Atualmente, os modelos treinados utilizando o SDK não podem ser integrados diretamente. É necessário um pipeline de inferência de lote que esse modelo consome para a integração com o Customer Insights - Data.
Requisitos de pipeline de lote para integrar com o Customer Insights - Data
Configuração do conjunto de dados
Crie conjuntos de dados para utilizar os dados da tabela do Customer Insights para o seu pipeline de inferência de lote. Registe estes conjuntos de dados na área de trabalho. Atualmente, apenas suportamos conjuntos de dados tabulares no formato .csv. Parametrize os conjuntos de dados que correspondem aos dados da tabela como um parâmetro de pipeline.
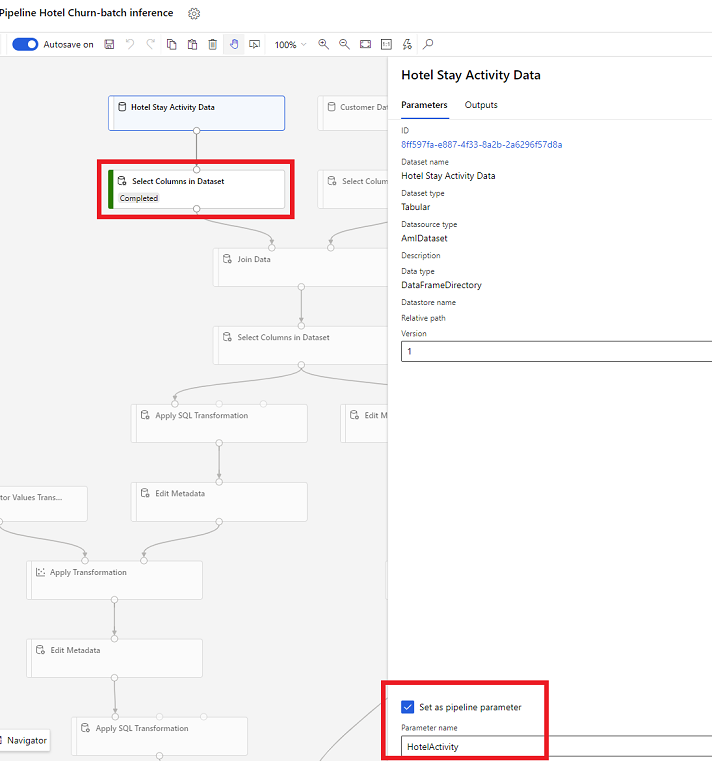
Parâmetros do conjunto de dados no Designer
No designer, abra Selecionar colunas no conjunto de dados e selecione Definir como parâmetro de pipeline onde fornece um nome para o parâmetro.
Parâmetro do conjunto de dados no SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Pipeline de inferência de lote
No estruturador, utilize um pipeline de preparação para criar ou atualizar um pipeline de inferência. Atualmente, apenas são suportados os pipelines de inferência de lote.
Utilizando o SDK, publique o pipeline para um ponto final. Atualmente, o Customer Insights - Data integra-se com o pipeline padrão num ponto final do pipeline de lote na área de trabalho de aprendizagem automática.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Importar dados do pipeline
O designer fornece o módulo de Dados de Exportação que permite a saída de um pipeline para exportação para o armazenamento do Azure. Atualmente, o módulo deve utilizar o tipo de datastore Armazenamento de Blobs do Azure e parametrizar a Datastore e o Caminho relativo. O sistema substitui estes dois parâmetros durante a execução do pipeline com uma datastore e um caminho acessível à aplicação.
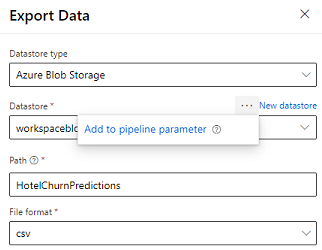
Ao escrever a saída de inferência utilizando código, envie a saída para um caminho dentro de um arquivo de dados registado na área de trabalho. Se o caminho e a datastore forem parametrizados no pipeline, o Customer Insights pode ler e importar a saída de inferência. Atualmente, só é suportada uma única saída tabular em formato CSV. O caminho deve incluir o diretório e o nome de ficheiro.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name