Bancos de dados de lago do Access usando pool SQL sem servidor
O espaço de trabalho do Azure Synapse Analytics permite criar dois tipos de bancos de dados sobre um data lake do Spark:
- Bancos de dados Lake onde você pode definir tabelas sobre dados de lago usando blocos de anotações Apache Spark, modelos de banco de dados ou Microsoft Dataverse (anteriormente Common Data Service). Essas tabelas podem ser consultadas usando a linguagem T-SQL (Transact-SQL) usando o pool SQL sem servidor.
- Bancos de dados SQL onde você pode definir seus próprios bancos de dados e tabelas diretamente usando o pool SQL sem servidor. Você pode usar T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE para definir os objetos e adicionar exibições SQL, procedimentos e funções de valor de tabela embutido adicionais sobre as tabelas.
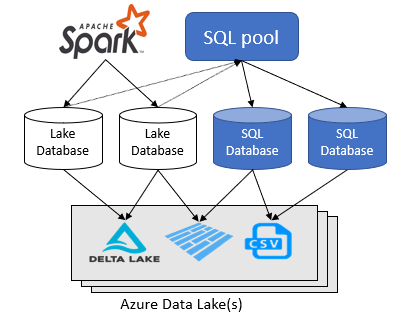
Este artigo se concentra em bancos de dados de lago em um pool SQL sem servidor no Azure Synapse Analytics.
O Azure Synapse Analytics permite criar bancos de dados e tabelas de lago usando o Spark ou o designer de banco de dados e, em seguida, analisar dados nos bancos de dados de lago usando o pool SQL sem servidor. Os bancos de dados lake e as tabelas (parquet ou CSV-backed) que são criadas nos pools Apache Spark, modelos de banco de dados lake ou Dataverse estão automaticamente disponíveis para consulta com o mecanismo de pool SQL sem servidor. Os bancos de dados e tabelas lake que são modificados estão disponíveis no pool SQL sem servidor depois de algum tempo. Há um atraso até que as alterações feitas no Spark ou no designer de banco de dados apareçam no serverless.
Gerenciar banco de dados do lago
Para gerenciar bancos de dados de lago criados pelo Spark, você pode usar pools do Apache Spark ou designer de banco de dados. Por exemplo, crie ou exclua um banco de dados de lago por meio de um trabalho de pool do Spark. Não é possível criar um banco de dados lake ou os objetos nos bancos de dados lake usando o pool SQL sem servidor.
O banco de dados Spark default está disponível no contexto do pool SQL sem servidor como um banco de dados lago chamado default.
Nota
Não é possível criar um lago e um banco de dados SQL no pool SQL sem servidor com o mesmo nome.
As tabelas nos bancos de dados lake não podem ser modificadas a partir de um pool SQL sem servidor. Use o designer de banco de dados ou pools Apache Spark para modificar um banco de dados lake. O pool SQL sem servidor permite que você faça as seguintes alterações em um banco de dados lago usando comandos T-SQL:
- Adicione, altere e solte exibições, procedimentos, funções de valor de tabela embutidas em um banco de dados lake.
- Adicione e remova usuários do Microsoft Entra com escopo de banco de dados.
- Adicione ou remova usuários do banco de dados Microsoft Entra para a função db_datareader . Os usuários do banco de dados Microsoft Entra na função db_datareader têm permissão para ler todas as tabelas no banco de dados lake, mas não podem ler dados de outros bancos de dados.
Modelo de segurança
Os bancos de dados e tabelas do lago são protegidos em dois níveis:
- A camada de armazenamento subjacente atribuindo aos usuários do Microsoft Entra um dos seguintes:
- Controlo de acesso baseado em funções do Azure (RBAC do Azure)
- Função de controle de acesso baseado em atributo do Azure (Azure ABAC)
- Permissões da lista de controle de acesso (ACL)
- A camada SQL onde você pode definir um usuário do Microsoft Entra e conceder permissões SQL para
SELECTdados de tabelas que fazem referência aos dados do lago.
Modelo de segurança do lago
O acesso aos arquivos do banco de dados do lago é controlado usando as permissões do lago na camada de armazenamento. Somente os usuários do Microsoft Entra podem usar tabelas nos bancos de dados do lago e podem acessar os dados no lago usando suas próprias identidades.
Você pode conceder acesso aos dados subjacentes usados para tabelas externas a uma entidade de segurança, como: um usuário, um aplicativo Microsoft Entra com entidade de serviço atribuída ou um grupo de segurança. Para acesso a dados, conceda ambas as seguintes permissões:
- Conceda
read (R)permissão em arquivos (como os arquivos de dados subjacentes da tabela). - Conceda
execute (X)permissão na pasta onde os arquivos estão armazenados e em cada pasta pai até a raiz. Você pode ler mais sobre essas permissões em Listas de controle de acesso (ACLs).
Por exemplo, no https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/, as entidades de segurança precisam:
-
execute (X)permissões em todas as pastas começando no<fs>.myparquettable -
read (R)permissões emyparquettablearquivos dentro dessa pasta, para poder ler uma tabela em um banco de dados (sincronizado ou original).
Se uma entidade de segurança exigir a capacidade de criar objetos ou soltar objetos em um banco de dados, permissões adicionais write (W) serão necessárias nas pastas e arquivos na pasta de depósito . Não é possível modificar objetos em um banco de dados a partir do pool SQL sem servidor, apenas dos pools do Spark ou do designer de banco de dados.
Modelo de segurança SQL
O espaço de trabalho Synapse do Azure fornece um ponto de extremidade T-SQL que permite consultar o banco de dados lake usando o pool SQL sem servidor. Além do acesso aos dados, a interface SQL permite controlar quem pode acessar as tabelas. Você precisa permitir que um usuário acesse os bancos de dados de lago compartilhados usando o pool SQL sem servidor. Existem dois tipos de usuários que podem acessar os bancos de dados do lago:
- Administradores: atribua a função de espaço de trabalho Synapse SQL Administrator ou a função sysadmin no nível de servidor dentro do pool SQL sem servidor. Essa função tem controle total sobre todos os bancos de dados. As funções Synapse Administrator e Synapse SQL Administrator também têm todas as permissões em todos os objetos em um pool SQL sem servidor, por padrão.
- Leitores de espaço de trabalho: conceda as permissões de nível de servidor GRANT CONNECT ANY DATABASE e GRANT SELECT ALL USER SECURABLES no pool SQL sem servidor para um logon que permita que o logon acesse e leia qualquer banco de dados. Essa pode ser uma boa opção para atribuir acesso de leitor/não administrador a um usuário.
- Leitores de banco de dados: crie usuários de banco de dados a partir do ID do Microsoft Entra em seu banco de dados lake e adicione-os a db_datareader função, o que permite que eles leiam dados no banco de dados lake.
Saiba mais sobre como definir o controle de acesso em bancos de dados compartilhados.
Objetos SQL personalizados em bancos de dados de lago
Os bancos de dados Lake permitem a criação de objetos T-SQL personalizados, como esquemas, procedimentos, exibições e as funções de valor de tabela embutidas (iTVFs). Para criar objetos SQL personalizados, você DEVE criar um esquema onde colocará os objetos. Os objetos SQL personalizados não podem ser colocados no dbo esquema porque ele é reservado para as tabelas lake definidas no Spark, no designer de banco de dados ou no Dataverse.
Importante
Você deve criar um esquema SQL personalizado onde colocará seus objetos SQL. Os objetos SQL personalizados não podem ser colocados no dbo esquema. O dbo esquema é reservado para as tabelas de lago que são originalmente criadas no Spark ou no designer de banco de dados.
Exemplos
Criar leitor de banco de dados SQL no banco de dados lake
Neste exemplo, adicionamos um usuário do Microsoft Entra no banco de dados lake que pode ler dados por meio de tabelas compartilhadas. Os usuários são adicionados no banco de dados lake por meio do pool SQL sem servidor. Em seguida, atribua o usuário à função db_datareader para que ele possa ler dados.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Criar leitor de dados no nível do espaço de trabalho
Um logon com GRANT CONNECT ANY DATABASE e GRANT SELECT ALL USER SECURABLES permissões é capaz de ler todas as tabelas usando o pool SQL sem servidor, mas não é capaz de criar bancos de dados SQL ou modificar os objetos neles.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Esse script permite criar usuários sem privilégios de administrador que podem ler qualquer tabela em bancos de dados Lake.
Crie e conecte-se ao banco de dados do Spark com o pool SQL sem servidor
Primeiro, crie um novo banco de dados do Spark chamado mytestlakedb usando um cluster do Spark que você já criou em seu espaço de trabalho. Você pode conseguir isso, por exemplo, usando um Spark C# Notebook com a seguinte instrução .NET for Spark:
spark.sql("CREATE DATABASE mytestlakedb")
Após um pequeno atraso, você pode ver o banco de dados lake do pool SQL sem servidor. Por exemplo, execute a seguinte instrução do pool SQL sem servidor.
SELECT * FROM sys.databases;
Verifique se mytestlakedb está incluído nos resultados.
Criar objetos SQL personalizados no banco de dados lake
O exemplo a seguir mostra como criar um modo de exibição personalizado, procedimento e função de valor de tabela embutida (iTVF) no reports esquema:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Conteúdos relacionados
- Metadados compartilhados do Azure Synapse Analytics
- Tabelas de metadados compartilhadas do Azure Synapse Analytics
- Início rápido: criar uma nova base de dados Lake com modelos de bases de dados
- Tutorial: Usar pool SQL sem servidor com o Power BI Desktop & criar um relatório
- Sincronizar definições de tabela externa do Apache Spark para Azure Synapse no pool SQL sem servidor
- Tutorial: Explore e analise data lakes com pool SQL sem servidor