Introdução à monitorização do estado de funcionamento do Service Fabric
O Azure Service Fabric apresenta um modelo de integridade que fornece avaliação e relatórios de integridade avançados, flexíveis e extensíveis. O modelo permite o monitoramento quase em tempo real do estado do cluster e dos serviços em execução nele. Você pode facilmente obter informações de saúde e corrigir possíveis problemas antes que eles caiam em cascata e causem interrupções maciças. No modelo típico, os serviços enviam relatórios com base em suas exibições locais, e essas informações são agregadas para fornecer uma exibição geral no nível do cluster.
Os componentes do Service Fabric usam esse modelo de integridade avançado para relatar seu estado atual. Você pode usar o mesmo mecanismo para relatar a integridade de seus aplicativos. Se você investir em relatórios de integridade de alta qualidade que capturam suas condições personalizadas, poderá detetar e corrigir problemas para seu aplicativo em execução com muito mais facilidade.
Nota
Iniciamos o subsistema de integridade para atender a uma necessidade de atualizações monitoradas. O Service Fabric fornece atualizações monitoradas de aplicativos e clusters que garantem disponibilidade total, sem tempo de inatividade e intervenção mínima ou nenhuma do usuário. Para atingir esses objetivos, a atualização verifica a integridade com base nas políticas de atualização configuradas. Uma atualização só pode prosseguir quando a integridade respeitar os limites desejados. Caso contrário, a atualização será revertida automaticamente ou pausada para dar aos administradores a chance de corrigir os problemas. Para saber mais sobre atualizações de aplicativos, consulte este artigo.
Loja de saúde
O repositório de integridade mantém informações relacionadas à saúde sobre entidades no cluster para fácil recuperação e avaliação. Ele é implementado como um serviço stateful persistente do Service Fabric para garantir alta disponibilidade e escalabilidade. O armazenamento de integridade faz parte do aplicativo malha:/System e está disponível quando o cluster está em execução.
Entidades de saúde e hierarquia
As entidades de saúde estão organizadas numa hierarquia lógica que capta interações e dependências entre diferentes entidades. O repositório de integridade cria automaticamente entidades de integridade e hierarquia com base em relatórios recebidos de componentes do Service Fabric.
As entidades de integridade espelham as entidades do Service Fabric. (Por exemplo, a entidade do aplicativo de integridade corresponde a uma instância de aplicativo implantada no cluster, enquanto a entidade do nó de integridade corresponde a um nó de cluster do Service Fabric.) A hierarquia de saúde capta as interações das entidades do sistema e é a base para a avaliação avançada da saúde. Você pode aprender sobre os principais conceitos do Service Fabric na visão geral técnica do Service Fabric. Para obter mais informações sobre o aplicativo, consulte Modelo de aplicativo do Service Fabric.
As entidades de integridade e a hierarquia permitem que o cluster e os aplicativos sejam efetivamente relatados, depurados e monitorados. O modelo de integridade fornece uma representação precisa e granular da integridade das muitas peças móveis no cluster.
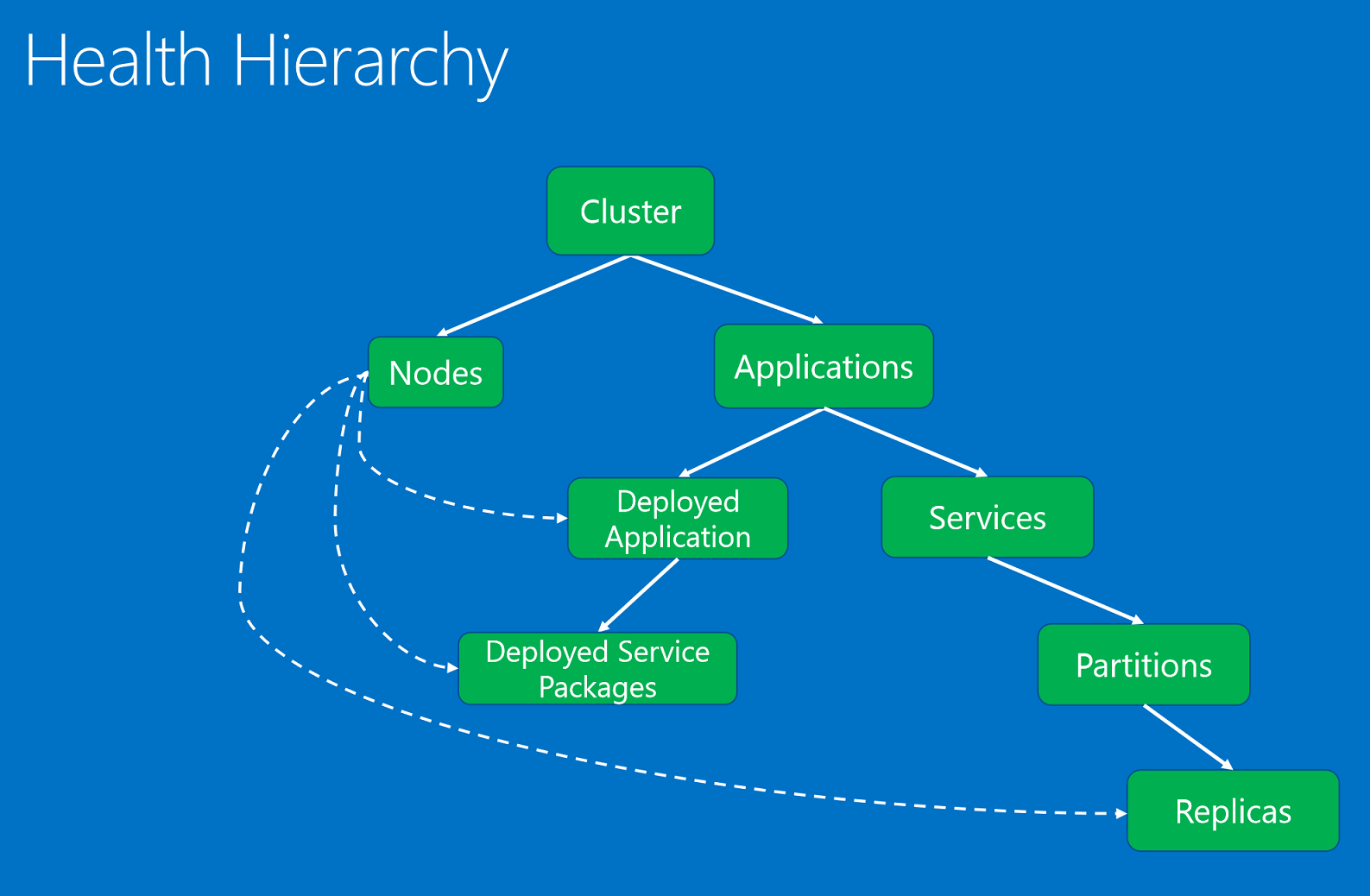 As entidades de saúde, organizadas numa hierarquia baseada nas relações pais-filhos.
As entidades de saúde, organizadas numa hierarquia baseada nas relações pais-filhos.
As entidades de saúde são:
- Aglomeração. Representa a integridade de um cluster do Service Fabric. Os relatórios de integridade do cluster descrevem condições que afetam todo o cluster. Essas condições afetam várias entidades no cluster ou no próprio cluster. Com base na condição, o repórter não pode restringir a questão a uma ou mais crianças insalubres. Exemplos incluem o cérebro da divisão do cluster devido a particionamento de rede ou problemas de comunicação.
- Nó. Representa a integridade de um nó do Service Fabric. Os relatórios de integridade do nó descrevem condições que afetam a funcionalidade do nó. Eles normalmente afetam todas as entidades implantadas em execução nele. Os exemplos incluem nó sem espaço em disco (ou outras propriedades de toda a máquina, como memória, conexões) e quando um nó está inativo. A entidade do nó é identificada pelo nome do nó (string).
- Aplicação. Representa a integridade de uma instância de aplicativo em execução no cluster. Os relatórios de integridade do aplicativo descrevem condições que afetam a integridade geral do aplicativo. Eles não podem ser restritos a filhos individuais (serviços ou aplicativos implantados). Os exemplos incluem a interação de ponta a ponta entre diferentes serviços no aplicativo. A entidade do aplicativo é identificada pelo nome do aplicativo (URI).
- Serviço. Representa a integridade de um serviço em execução no cluster. Os relatórios de integridade do serviço descrevem condições que afetam a integridade geral do serviço. O repórter não pode restringir o problema a uma partição ou réplica não íntegra. Os exemplos incluem uma configuração de serviço (como porta ou compartilhamento de arquivos externo) que está causando problemas para todas as partições. A entidade de serviço é identificada pelo nome do serviço (URI).
- Partição. Representa a integridade de uma partição de serviço. Os relatórios de integridade da partição descrevem as condições que afetam todo o conjunto de réplicas. Os exemplos incluem quando o número de réplicas está abaixo da contagem de destino e quando uma partição está em perda de quórum. A entidade da partição é identificada pelo ID da partição (GUID).
- Réplica. Representa a integridade de uma réplica de serviço com monitoração de estado ou de uma instância de serviço sem monitoração de estado. A réplica é a menor unidade que os vigilantes e os componentes do sistema podem relatar para um aplicativo. Para serviços com monitoração de estado, os exemplos incluem uma réplica primária que não pode replicar operações para secundários e replicação lenta. Além disso, uma instância sem estado pode relatar quando está ficando sem recursos ou tem problemas de conectividade. A entidade da réplica é identificada pelo ID da partição (GUID) e pelo ID da réplica ou instância (longo).
- DeployedApplication. Representa a integridade de um aplicativo em execução em um nó. Os relatórios de integridade do aplicativo implantado descrevem condições específicas do aplicativo no nó que não podem ser restritas a pacotes de serviço implantados no mesmo nó. Os exemplos incluem erros quando o pacote do aplicativo não pode ser baixado nesse nó e problemas na configuração de entidades de segurança do aplicativo no nó. O aplicativo implantado é identificado pelo nome do aplicativo (URI) e nome do nó (string).
- DeployedServicePackage. Representa a integridade de um pacote de serviço em execução em um nó no cluster. Ele descreve condições específicas de um pacote de serviço que não afetam os outros pacotes de serviço no mesmo nó para o mesmo aplicativo. Os exemplos incluem um pacote de código no pacote de serviço que não pode ser iniciado e um pacote de configuração que não pode ser lido. O pacote de serviço implantado é identificado por nome do aplicativo (URI), nome do nó (string), nome do manifesto do serviço (string) e ID de ativação do pacote de serviço (string).
A granularidade do modelo de integridade facilita a deteção e a correção de problemas. Por exemplo, se um serviço não estiver respondendo, é viável relatar que a instância do aplicativo não está íntegra. No entanto, a geração de relatórios nesse nível não é ideal, porque o problema pode não estar afetando todos os serviços desse aplicativo. O relatório deve ser aplicado ao serviço não íntegro ou a uma partição filho específica, se mais informações apontarem para essa partição. Os dados aparecem automaticamente através da hierarquia e uma partição não íntegra é tornada visível nos níveis de serviço e aplicativo. Essa agregação ajuda a identificar e resolver a causa raiz do problema mais rapidamente.
A hierarquia de saúde é composta por relações pais-filhos. Um cluster é composto por nós e aplicativos. Os aplicativos têm serviços e aplicativos implantados. Os aplicativos implantados implantaram pacotes de serviço. Os serviços têm partições e cada partição tem uma ou mais réplicas. Há uma relação especial entre nós e entidades implantadas. Um nó não íntegro, conforme relatado por seu componente de sistema de autoridade, o serviço Gerenciador de Failover, afeta os aplicativos, pacotes de serviço e réplicas implantados nele.
A hierarquia de integridade representa o estado mais recente do sistema com base nos relatórios de saúde mais recentes, que são informações quase em tempo real. Os vigilantes internos e externos podem relatar as mesmas entidades com base na lógica específica do aplicativo ou em condições monitoradas personalizadas. Os relatórios de usuários coexistem com os relatórios do sistema.
Planeje investir em como relatar e responder à saúde durante o projeto de um grande serviço de nuvem. Esse investimento inicial torna o serviço mais fácil de depurar, monitorar e operar.
Estados de saúde
O Service Fabric usa três estados de integridade para descrever se uma entidade está íntegra ou não: OK, aviso e erro. Qualquer relatório enviado para o repositório de integridade deve especificar um desses estados. O resultado da avaliação de saúde é um desses estados.
Os estados de saúde possíveis são:
- Está bem. A entidade é saudável. Não há problemas conhecidos relatados sobre ele ou seus filhos (quando aplicável).
- Atenção. A entidade tem alguns problemas, mas ainda pode funcionar corretamente. Por exemplo, há atrasos, mas eles ainda não causam problemas funcionais. Em alguns casos, a condição de aviso pode corrigir-se sem intervenção externa. Nestes casos, os relatórios de saúde sensibilizam e dão visibilidade ao que se passa. Em outros casos, a condição de aviso pode degradar-se em um problema grave sem a intervenção do usuário.
- Error. A entidade não é saudável. Devem ser tomadas medidas para corrigir o estado da entidade, porque esta não pode funcionar corretamente.
- Desconhecido. A entidade não existe no armazém de saúde. Esse resultado pode ser obtido a partir das consultas distribuídas que mesclam resultados de vários componentes. Por exemplo, a consulta get node list vai para FailoverManager, ClusterManager e HealthManager; get application list query vai para ClusterManager e HealthManager. Essas consultas mesclam resultados de vários componentes do sistema. Se outro componente do sistema retornar uma entidade que não está presente no armazenamento de integridade, o resultado mesclado terá estado de integridade desconhecido. Uma entidade não está armazenada porque os relatórios de integridade ainda não foram processados ou a entidade foi limpa após a exclusão.
Políticas de saúde
A loja de saúde aplica políticas de saúde para determinar se uma entidade é saudável com base em seus relatórios e seus filhos.
Nota
As políticas de integridade podem ser especificadas no manifesto do cluster (para avaliação da integridade do cluster e do nó) ou no manifesto do aplicativo (para avaliação do aplicativo e qualquer um de seus filhos). As solicitações de avaliação de integridade também podem ser aprovadas em políticas personalizadas de avaliação de integridade, que são usadas apenas para essa avaliação.
Por padrão, o Service Fabric aplica regras rígidas (tudo deve estar íntegro) para a relação hierárquica pai-filho. Se mesmo uma das crianças tiver um evento insalubre, o pai é considerado insalubre.
Política de integridade do cluster
A diretiva de integridade do cluster é usada para avaliar o estado de integridade do cluster e os estados de integridade do nó. A política pode ser definida no manifesto do cluster. Se ela não estiver presente, a política padrão (zero falhas toleradas) será usada.
A política de integridade do cluster contém:
ConsiderWarningAsError. Especifica se os relatórios de integridade de aviso devem ser tratados como erros durante a avaliação de integridade. Predefinição: false.
MaxPercentUnhealthyApplications. Especifica a porcentagem máxima tolerada de aplicativos que podem não estar íntegros antes que o cluster seja considerado em erro.
MaxPercentUnhealthyNodes. Especifica a porcentagem máxima tolerada de nós que podem não estar íntegros antes que o cluster seja considerado em erro. Em clusters grandes, alguns nós estão sempre inativos ou fora para reparos, então essa porcentagem deve ser configurada para tolerar isso.
ApplicationTypeHealthPolicyMap. O mapa da política de integridade do tipo de aplicativo pode ser usado durante a avaliação da integridade do cluster para descrever tipos de aplicativos especiais. Por padrão, todos os aplicativos são colocados em um pool e avaliados com MaxPercentUnhealthyApplications. Se alguns tipos de aplicação devem ser tratados de forma diferente, eles podem ser retirados do pool global. Em vez disso, eles são avaliados em relação às porcentagens associadas ao nome do tipo de aplicativo no mapa. Por exemplo, em um cluster há milhares de aplicativos de diferentes tipos e algumas instâncias de aplicativo de controle de um tipo de aplicativo especial. Os aplicativos de controle nunca devem estar em erro. Você pode especificar global MaxPercentUnhealthyApplications para 20% para tolerar algumas falhas, mas para o tipo de aplicativo "ControlApplicationType" defina MaxPercentUnhealthyApplications como 0. Dessa forma, se alguns dos muitos aplicativos não estiverem íntegros, mas abaixo do percentual global de insalubridade, o cluster será avaliado como Aviso. Um estado de integridade de aviso não afeta a atualização do cluster ou outro monitoramento acionado pelo estado de integridade do erro. Mas mesmo um aplicativo de controle em erro tornaria o cluster não íntegro, o que aciona a reversão ou pausa a atualização do cluster, dependendo da configuração de atualização. Para os tipos de aplicativo definidos no mapa, todas as instâncias de aplicativo são retiradas do pool global de aplicativos. Eles são avaliados com base no número total de aplicativos do tipo de aplicativo, usando o MaxPercentUnhealthyApplications específico do mapa. Todos os demais aplicativos permanecem no pool global e são avaliados com MaxPercentUnhealthyApplications.
O exemplo a seguir é um trecho de um manifesto de cluster. Para definir entradas no mapa de tipo de aplicativo, prefixe o nome do parâmetro com "ApplicationTypeMaxPercentUnhealthyApplications-", seguido pelo nome do tipo de aplicativo.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. O mapa da política de integridade do tipo de nó pode ser usado durante a avaliação da integridade do cluster para descrever tipos de nó especiais. Os tipos de nó são avaliados em relação às porcentagens associadas ao nome do tipo de nó no mapa. A definição desse valor não tem efeito sobre o pool global de nós usado paraMaxPercentUnhealthyNodes. Por exemplo, um cluster tem centenas de nós de diferentes tipos e alguns tipos de nós que hospedam trabalhos importantes. Nenhum nó nesse tipo deve estar inativo. Você pode especificar globalMaxPercentUnhealthyNodespara 20% para tolerar algumas falhas para todos os nós, mas para o tipoSpecialNodeTypede nó , defina comoMaxPercentUnhealthyNodes0. Dessa forma, se alguns dos muitos nós não estiverem íntegros, mas abaixo da porcentagem global não íntegra, o cluster será avaliado como estando no estado de integridade de Aviso. Um estado de integridade de Aviso não afeta a atualização do cluster ou outro monitoramento acionado por um estado de integridade de Erro. Mas mesmo um nó do tipoSpecialNodeTypeem um estado de integridade de erro tornaria o cluster não íntegro e acionaria a reversão ou pausaria a atualização do cluster, dependendo da configuração de atualização. Por outro lado, definir o globalMaxPercentUnhealthyNodescomo 0 e definir aSpecialNodeTypeporcentagem máxima de nós não íntegros como 100 com um nó do tipoSpecialNodeTypeem um estado de erro ainda colocaria o cluster em um estado de erro porque a restrição global é mais rigorosa nesse caso.O exemplo a seguir é um trecho de um manifesto de cluster. Para definir entradas no mapa de tipo de nó, prefixe o nome do parâmetro com "NodeTypeMaxPercentUnhealthyNodes-", seguido pelo nome do tipo de nó.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Política de integridade do aplicativo
A política de integridade do aplicativo descreve como a avaliação de eventos e agregação de estados filhos é feita para aplicativos e seus filhos. Ele pode ser definido no manifesto do aplicativo, ApplicationManifest.xml, no pacote do aplicativo. Se nenhuma política for especificada, o Service Fabric assumirá que a entidade não está íntegra se tiver um relatório de integridade ou um filho no estado de integridade de aviso ou erro. As políticas configuráveis são:
- ConsiderWarningAsError. Especifica se os relatórios de integridade de aviso devem ser tratados como erros durante a avaliação de integridade. Predefinição: false.
- MaxPercentUnhealthyDeployedApplications. Especifica a porcentagem máxima tolerada de aplicativos implantados que podem não estar íntegros antes que o aplicativo seja considerado erro. Essa porcentagem é calculada dividindo o número de aplicativos implantados não íntegros pelo número de nós nos quais os aplicativos estão atualmente implantados no cluster. O cálculo arredonda para cima para tolerar uma falha em pequenos números de nós. Percentagem por defeito: zero.
- DefaultServiceTypeHealthPolicy. Especifica a diretiva de integridade do tipo de serviço padrão, que substitui a diretiva de integridade padrão para todos os tipos de serviço no aplicativo.
- ServiceTypeHealthPolicyMap. Fornece um mapa de políticas de integridade de serviço por tipo de serviço. Essas políticas substituem as políticas de integridade do tipo de serviço padrão para cada tipo de serviço especificado. Por exemplo, se um aplicativo tiver um tipo de serviço de gateway sem estado e um tipo de serviço de mecanismo com monitoração de estado, você poderá configurar as políticas de integridade para sua avaliação de forma diferente. Ao especificar a política por tipo de serviço, você pode obter um controle mais granular da integridade do serviço.
Política de integridade do tipo de serviço
A política de integridade do tipo de serviço especifica como avaliar e agregar os serviços e os filhos dos serviços. A política contém:
- MaxPercentUnhealthyPartitionsPerService. Especifica a porcentagem máxima tolerada de partições não íntegras antes que um serviço seja considerado não íntegro. Percentagem por defeito: zero.
- MaxPercentUnhealthyReplicasPerPartition. Especifica a porcentagem máxima tolerada de réplicas não íntegras antes que uma partição seja considerada não íntegra. Percentagem por defeito: zero.
- MaxPercentUnhealthyServices. Especifica a porcentagem máxima tolerada de serviços não íntegros antes que o aplicativo seja considerado não íntegro. Percentagem por defeito: zero.
O exemplo a seguir é um trecho de um manifesto de aplicativo:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Avaliação da saúde
Os usuários e os serviços automatizados podem avaliar a integridade de qualquer entidade a qualquer momento. Para avaliar a saúde de uma entidade, a loja de saúde agrega todos os relatórios de saúde da entidade e avalia todas as suas crianças (quando aplicável). O algoritmo de agregação de integridade usa políticas de integridade que especificam como avaliar relatórios de saúde e como agregar estados de saúde infantil (quando aplicável).
Agregação de relatórios de saúde
Uma entidade pode ter vários relatórios de saúde enviados por diferentes repórteres (componentes do sistema ou cães de guarda) em diferentes propriedades. A agregação usa as diretivas de integridade associadas, em particular o membro ConsiderWarningAsError da diretiva de integridade do aplicativo ou cluster. ConsiderWarningAsError especifica como avaliar avisos.
O estado de saúde agregado é desencadeado pelos piores relatórios de saúde da entidade. Se houver pelo menos um relatório de integridade de erro, o estado de integridade agregado será um erro.
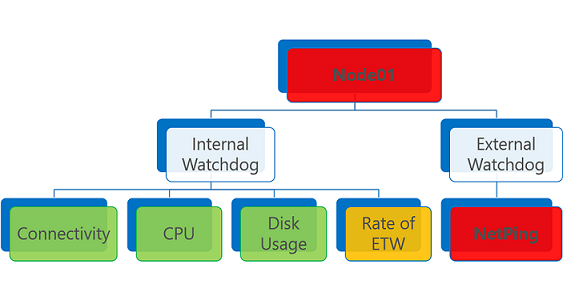
Uma entidade de integridade que tenha um ou mais relatórios de integridade de erro é avaliada como Erro. O mesmo se aplica a um relatório de saúde expirado, independentemente do seu estado de saúde.
Se não houver relatórios de erros e um ou mais avisos, o estado de integridade agregado será aviso ou erro, dependendo do sinalizador de política ConsiderWarningAsError.
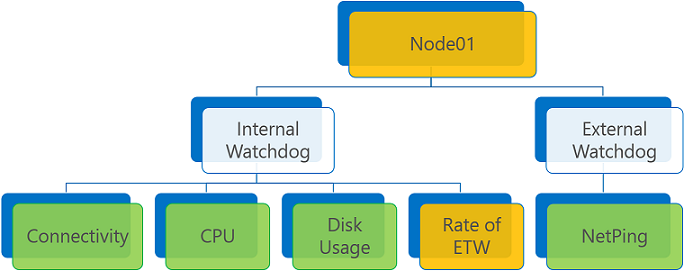
Agregação de relatório de integridade com relatório de aviso e ConsiderWarningAsError definido como false (padrão).
Agregação da saúde infantil
O estado de saúde agregado de uma entidade reflete os estados de saúde da criança (quando aplicável). O algoritmo para agregar estados de saúde infantil usa as políticas de integridade aplicáveis com base no tipo de entidade.
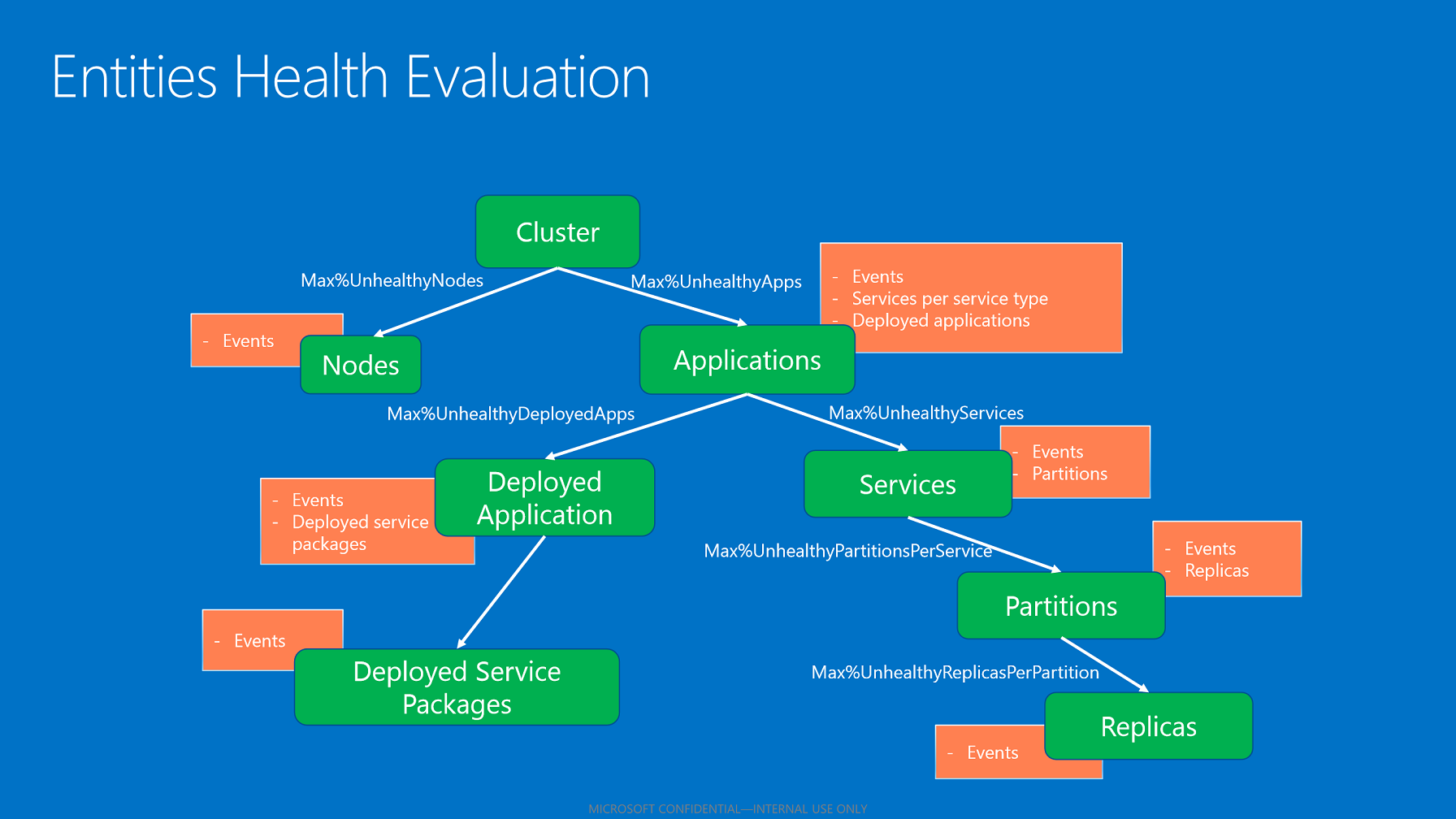
Agregação infantil com base em políticas de saúde.
Depois de avaliar todas as crianças, a unidade de saúde agrega os seus estados de saúde com base na percentagem máxima configurada de crianças não saudáveis. Essa porcentagem é retirada da política com base na entidade e no tipo filho.
- Se todas as crianças tiverem estados OK, o estado de saúde agregado da criança será OK.
- Se as crianças tiverem os estados OK e de aviso, o estado de saúde agregado da criança será de aviso.
- Se houver crianças com estados de erro que não respeitem a percentagem máxima permitida de crianças não saudáveis, o estado de saúde agregado dos pais é um erro.
- Se as crianças com estados de erro respeitarem a percentagem máxima permitida de crianças não saudáveis, o estado de saúde agregado dos pais é de aviso.
Relatórios de saúde
Os componentes do sistema, os aplicativos do System Fabric e os vigilantes internos/externos podem gerar relatórios em relação às entidades do Service Fabric. Os repórteres fazem determinações locais da saúde das entidades monitoradas, com base nas condições que estão monitorando. Eles não precisam olhar para nenhum estado global ou dados agregados. O comportamento desejado é ter repórteres simples, e não organismos complexos que precisam olhar para muitas coisas para inferir quais informações enviar.
Para enviar dados de integridade para o repositório de integridade, um repórter precisa identificar a entidade afetada e criar um relatório de integridade. Para enviar o relatório, use a API FabricClient.HealthClient.ReportHealth , APIs de integridade de relatório expostas nos Partition objetos ou CodePackageActivationContext , cmdlets do PowerShell ou REST.
Relatórios de saúde
Os relatórios de integridade para cada uma das entidades no cluster contêm as seguintes informações:
FonteId. Uma cadeia de caracteres que identifica exclusivamente o repórter do evento de integridade.
Identificador de entidade. Identifica a entidade onde o relatório é aplicado. Difere com base no tipo de entidade:
- Aglomeração. Nenhum.
- Nó. Nome do nó (string).
- Aplicação. Nome do aplicativo (URI). Representa o nome da instância do aplicativo implantada no cluster.
- Serviço. Nome do serviço (URI). Representa o nome da instância de serviço implantada no cluster.
- Partição. ID da partição (GUID). Representa o identificador exclusivo da partição.
- Réplica. O ID da réplica de serviço com monitoração de estado ou o ID da instância de serviço sem estado (INT64).
- DeployedApplication. Nome do aplicativo (URI) e nome do nó (string).
- DeployedServicePackage. Nome do aplicativo (URI), nome do nó (cadeia de caracteres) e nome do manifesto do serviço (cadeia de caracteres).
Imóvel. Uma cadeia de caracteres (não uma enumeração fixa) que permite ao relator categorizar o evento de integridade para uma propriedade específica da entidade. Por exemplo, o repórter A pode relatar a integridade da propriedade "Armazenamento" do Node01 e o repórter B pode relatar a integridade da propriedade "Conectividade" do Node01. No repositório de integridade, esses relatórios são tratados como eventos de integridade separados para a entidade Node01.
Descrição. Uma cadeia de caracteres que permite que um repórter forneça informações detalhadas sobre o evento de integridade. SourceId, Property e HealthState devem descrever completamente o relatório. A descrição adiciona informações legíveis por humanos sobre o relatório. O texto facilita a compreensão do relatório de integridade por administradores e usuários.
Estado de Saúde. Uma enumeração que descreve o estado de integridade do relatório. Os valores aceitos são OK, Aviso e Erro.
TimeToLive. Um período de tempo que indica por quanto tempo o relatório de integridade é válido. Juntamente com RemoveWhenExpired, ele permite que o armazenamento de integridade saiba como avaliar eventos expirados. Por padrão, o valor é infinito e o relatório é válido para sempre.
RemoveWhenExpired. Um booleano. Se definido como true, o relatório de integridade expirado é removido automaticamente do repositório de integridade e o relatório não afeta a avaliação de integridade da entidade. Usado quando o relatório é válido apenas por um período de tempo especificado e o relator não precisa limpá-lo explicitamente. Ele também é usado para excluir relatórios do repositório de integridade (por exemplo, um cão de guarda é alterado e para de enviar relatórios com origem e propriedade anteriores). Ele pode enviar um relatório com um breve TimeToLive junto com RemoveWhenExpired para limpar qualquer estado anterior do armazenamento de integridade. Se o valor for definido como false, o relatório expirado será tratado como um erro na avaliação de integridade. O valor falso sinaliza para o armazenamento de saúde que a fonte deve relatar periodicamente sobre essa propriedade. Se isso não acontecer, então deve haver algo errado com o cão de guarda. A saúde do cão de guarda é capturada considerando o evento como um erro.
SequenceNumber. Um número inteiro positivo que precisa ser cada vez maior, representa a ordem dos relatórios. Ele é usado pelo armazenamento de saúde para detetar relatórios obsoletos que são recebidos com atraso devido a atrasos na rede ou outros problemas. Um relatório será rejeitado se o número de sequência for menor ou igual ao número aplicado mais recentemente para a mesma entidade, fonte e propriedade. Se não for especificado, o número de sequência é gerado automaticamente. É necessário colocar o número sequencial apenas ao relatar transições de estado. Nessa situação, a fonte precisa lembrar quais relatórios enviou e manter as informações para recuperação no failover.
Essas quatro informações - SourceId, entity identifier, Property e HealthState - são necessárias para cada relatório de integridade. A cadeia de caracteres SourceId não tem permissão para iniciar com o prefixo "System.", que é reservado para relatórios do sistema. Para a mesma entidade, há apenas um relatório para a mesma origem e propriedade. Vários relatórios para a mesma origem e propriedade substituem-se uns aos outros, seja no lado do cliente de saúde (se forem em lote) ou no lado do armazenamento de integridade. A substituição baseia-se em números sequenciais; Os relatórios mais recentes (com números de sequência mais elevados) substituem os relatórios mais antigos.
Eventos no domínio da saúde
Internamente, o armazenamento de integridade mantém eventos de integridade, que contêm todas as informações dos relatórios, e metadados adicionais. Os metadados incluem a hora em que o relatório foi fornecido ao cliente de integridade e a hora em que foi modificado no servidor. Os eventos de saúde são retornados por consultas de saúde.
Os metadados adicionados contêm:
- SourceUtcTimestamp. O tempo em que o relatório foi entregue ao cliente de saúde (Tempo Universal Coordenado).
- LastModifiedUtcTimestamp. A hora em que o relatório foi modificado pela última vez no lado do servidor (Tempo Universal Coordenado).
- IsExpired. Um sinalizador para indicar se o relatório expirou quando a consulta foi executada pelo repositório de integridade. Um evento só pode expirar se RemoveWhenExpired for false. Caso contrário, o evento não será retornado por consulta e será removido do armazenamento.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. A última vez para transições OK/aviso/erro. Esses campos dão o histórico das transições de estado de saúde para o evento.
Os campos de transição de estado podem ser usados para alertas mais inteligentes ou informações de eventos de integridade "históricos". Eles permitem cenários como:
- Alerta quando uma propriedade está em aviso/erro há mais de X minutos. Verificar a condição por um período de tempo evita alertas sobre condições temporárias. Por exemplo, um alerta se o estado de integridade estiver alertando por mais de cinco minutos pode ser traduzido em (HealthState == Warning and Now - LastWarningTransitionTime > 5 minutes).
- Alertar apenas sobre as condições que mudaram nos últimos X minutos. Se um relatório já estava em erro antes da hora especificada, ele pode ser ignorado porque já foi sinalizado anteriormente.
- Se uma propriedade estiver alternando entre aviso e erro, determine por quanto tempo ela não está íntegra (ou seja, não está OK). Por exemplo, um alerta se a propriedade não estiver íntegra por mais de cinco minutos pode ser traduzido em (HealthState != Ok e Now - LastOkTransitionTime > 5 minutos).
Exemplo: Relatar e avaliar a integridade do aplicativo
O exemplo a seguir envia um relatório de integridade por meio do PowerShell na malha do aplicativo :/WordCount da origem MyWatchdog. O relatório de integridade contém informações sobre a "disponibilidade" da propriedade de integridade em um estado de integridade de erro, com TimeToLive infinito. Em seguida, ele consulta a integridade do aplicativo, que retorna erros de estado de integridade agregados e os eventos de integridade relatados na lista de eventos de integridade.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Utilização do modelo de saúde
O modelo de integridade permite que os serviços de nuvem e a plataforma subjacente do Service Fabric sejam dimensionados, porque o monitoramento e as determinações de integridade são distribuídos entre os diferentes monitores dentro do cluster. Outros sistemas têm um serviço único e centralizado no nível do cluster que analisa todas as informações potencialmente úteis emitidas pelos serviços. Esta abordagem dificulta a sua escalabilidade. Ele também não permite que eles coletem informações específicas para ajudar a identificar problemas e possíveis problemas o mais próximo possível da causa raiz.
O modelo de integridade é muito usado para monitoramento e diagnóstico, para avaliar a integridade do cluster e do aplicativo e para atualizações monitoradas. Outros serviços usam dados de integridade para executar reparos automáticos, criar histórico de integridade do cluster e emitir alertas sobre determinadas condições.
Próximos passos
Exibir relatórios de integridade do Service Fabric
Usar relatórios de integridade do sistema para solução de problemas
Como relatar e verificar a integridade do serviço
Adicionar relatórios de integridade personalizados do Service Fabric