Modelo Train PyTorch
Este artigo descreve como usar o componente Train PyTorch Model no designer do Azure Machine Learning para treinar modelos PyTorch como o DenseNet. O treinamento ocorre depois que você define um modelo e define seus parâmetros, e requer dados rotulados.
Atualmente, o componente Train PyTorch Model suporta treinamento distribuído e de nó único.
Como usar o modelo Train PyTorch
Adicione o componente DenseNet ou ResNet ao seu rascunho de pipeline no designer.
Adicione o componente Train PyTorch Model ao pipeline. Você pode encontrar este componente na categoria Treinamento modelo. Expanda Trem e arraste o componente Train PyTorch Model para o pipeline.
Nota
O componente Train PyTorch Model é melhor executado em computação do tipo GPU para um grande conjunto de dados, caso contrário, seu pipeline falhará. Você pode selecionar computação para componente específico no painel direito do componente definindo Usar outro destino de computação.
Na entrada esquerda, anexe um modelo não treinado. Anexe o conjunto de dados de treinamento e o conjunto de dados de validação à entrada do meio e à direita do Train PyTorch Model.
Para o modelo não treinado, deve ser um modelo PyTorch como o DenseNet; caso contrário, um 'InvalidModelDirectoryError' será lançado.
Para o conjunto de dados, o conjunto de dados de treinamento deve ser um diretório de imagem rotulado. Consulte Converter em diretório de imagens para saber como obter um diretório de imagem rotulado. Se não for rotulado, um 'NotLabeledDatasetError' será lançado.
O conjunto de dados de treinamento e o conjunto de dados de validação têm as mesmas categorias de rótulo, caso contrário, um InvalidDatasetError será lançado.
Para Épocas, especifique quantas épocas você gostaria de treinar. Todo o conjunto de dados será iterado em cada época, por padrão 5.
Para Tamanho do lote, especifique quantas instâncias treinar em um lote, por padrão 16.
Para o número da etapa de aquecimento, especifique quantas épocas você gostaria de aquecer o treinamento, caso a taxa de aprendizado inicial seja um pouco grande demais para começar a convergir, por padrão 0.
Para Taxa de aprendizagem, especifique um valor para a taxa de aprendizagem e o valor padrão é 0,001. A taxa de aprendizagem controla o tamanho da etapa que é usada no otimizador como sgd cada vez que o modelo é testado e corrigido.
Ao definir a taxa menor, você testa o modelo com mais frequência, com o risco de ficar preso em um platô local. Ao definir a taxa maior, você pode convergir mais rapidamente, com o risco de ultrapassar os mínimos verdadeiros.
Nota
Se a perda de trem se tornar nan durante o treinamento, o que pode ser causado por uma taxa de aprendizagem muito grande, a diminuição da taxa de aprendizagem pode ajudar. No treinamento distribuído, para manter a descida de gradiente estável, a taxa de aprendizado real é calculada porque
lr * torch.distributed.get_world_size()o tamanho do lote do grupo de processo é o tamanho mundial vezes maior que o de um único processo. O decaimento da taxa de aprendizagem polinomial é aplicado e pode ajudar a resultar em um modelo de melhor desempenho.Em Random seed, opcionalmente, digite um valor inteiro para usar como semente. O uso de uma semente é recomendado se você quiser garantir a reprodutibilidade do experimento em todos os trabalhos.
Para Paciência, especifique quantas épocas parar precocemente o treinamento se a perda de validação não diminuir consecutivamente. por defeito 3.
Para Frequência de impressão, especifique a frequência de impressão do log de treinamento em iterações em cada época, por padrão 10.
Envie o pipeline. Se o conjunto de dados tiver um tamanho maior, levará algum tempo e a computação da GPU é recomendada.
Preparação distribuída
No treinamento distribuído, a carga de trabalho para treinar um modelo é dividida e compartilhada entre vários miniprocessadores, chamados nós de trabalho. Esses nós de trabalho trabalham em paralelo para acelerar o treinamento do modelo. Atualmente o designer suporta formação distribuída para a componente Train PyTorch Model .
Tempo de preparação
O treinamento distribuído torna possível treinar em um grande conjunto de dados como o ImageNet (1000 aulas, 1,2 milhão de imagens) em apenas algumas horas pelo Train PyTorch Model. A tabela a seguir mostra o tempo de treinamento e o desempenho durante o treinamento de 50 épocas do Resnet50 no ImageNet a partir do zero com base em diferentes dispositivos.
| Dispositivos | Tempo de Formação | Rendimento do treinamento | Precisão de validação Top-1 | Precisão de validação Top-5 |
|---|---|---|---|---|
| 16 GPUs V100 | 6h22min | ~3200 Imagens/seg | 68.83% | 88.84% |
| 8 GPUs V100 | 12h21min | ~1670 Imagens/seg | 68.84% | 88.74% |
Clique na guia 'Métricas' deste componente e veja gráficos de métricas de treinamento, como 'Treinar imagens por segundo' e 'Precisão Top 1'.

Como habilitar o treinamento distribuído
Para habilitar o treinamento distribuído para o componente Train PyTorch Model, você pode definir as configurações de trabalho no painel direito do componente. Somente o cluster de computação AML é suportado para treinamento distribuído.
Nota
Várias GPUs são necessárias para ativar o treinamento distribuído porque o componente de back-end NCCL Train PyTorch Model usa necessidades cuda.
Selecione o componente e abra o painel direito. Expanda a seção Configurações do trabalho .
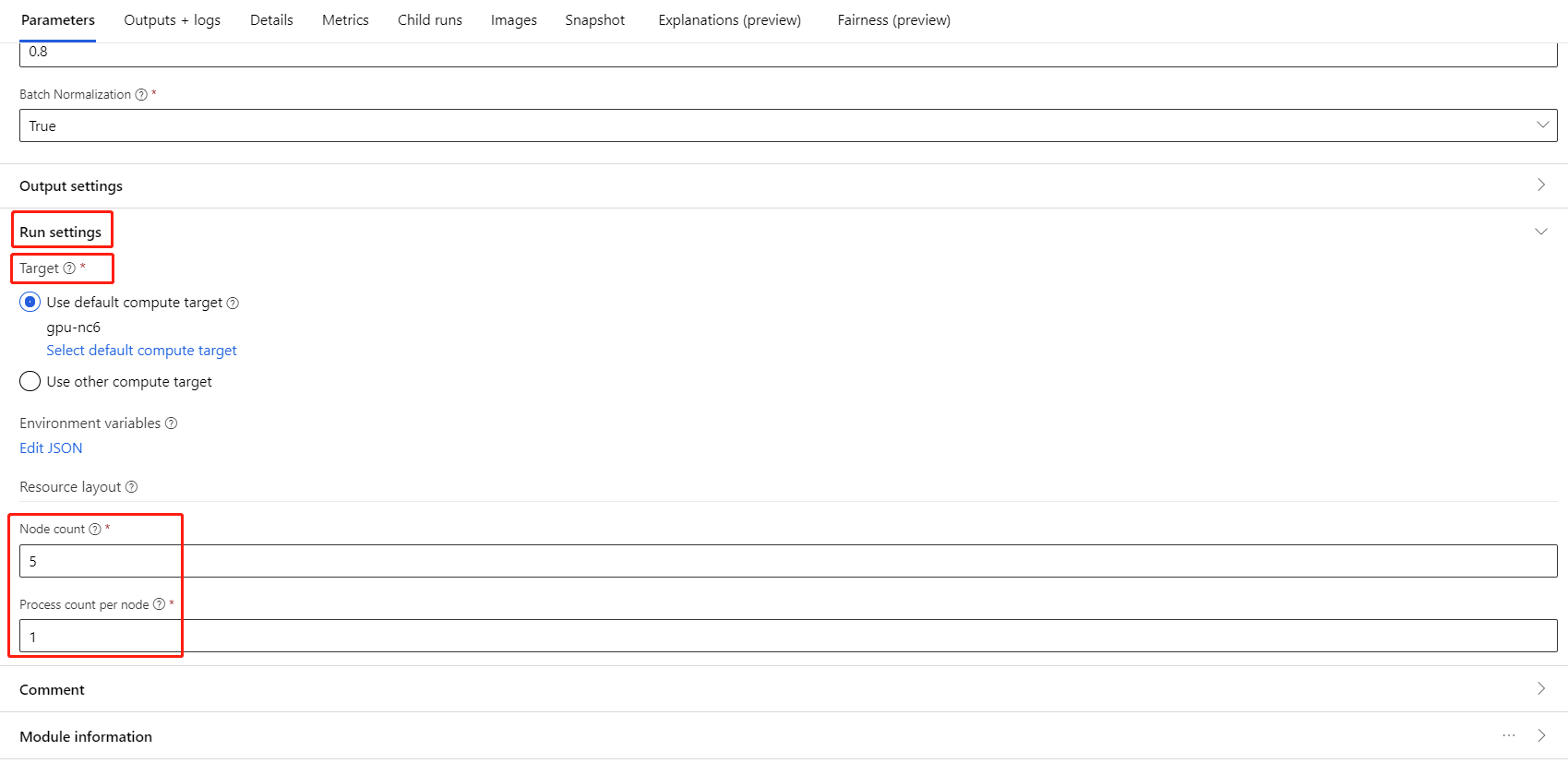
Certifique-se de ter selecionado a computação AML para o destino de computação.
Na seção Layout de recurso, você precisa definir os seguintes valores:
Contagem de nós: Número de nós no destino de computação usado para treinamento. Ele deve ser menor ou igual ao número máximo de nós do cluster de computação. Por padrão, é 1, o que significa trabalho de nó único.
Contagem de processos por nó: número de processos acionados por nó. Deve ser menor ou igual à Unidade de Processamento do seu cálculo. Por padrão, é 1, o que significa trabalho de processo único.
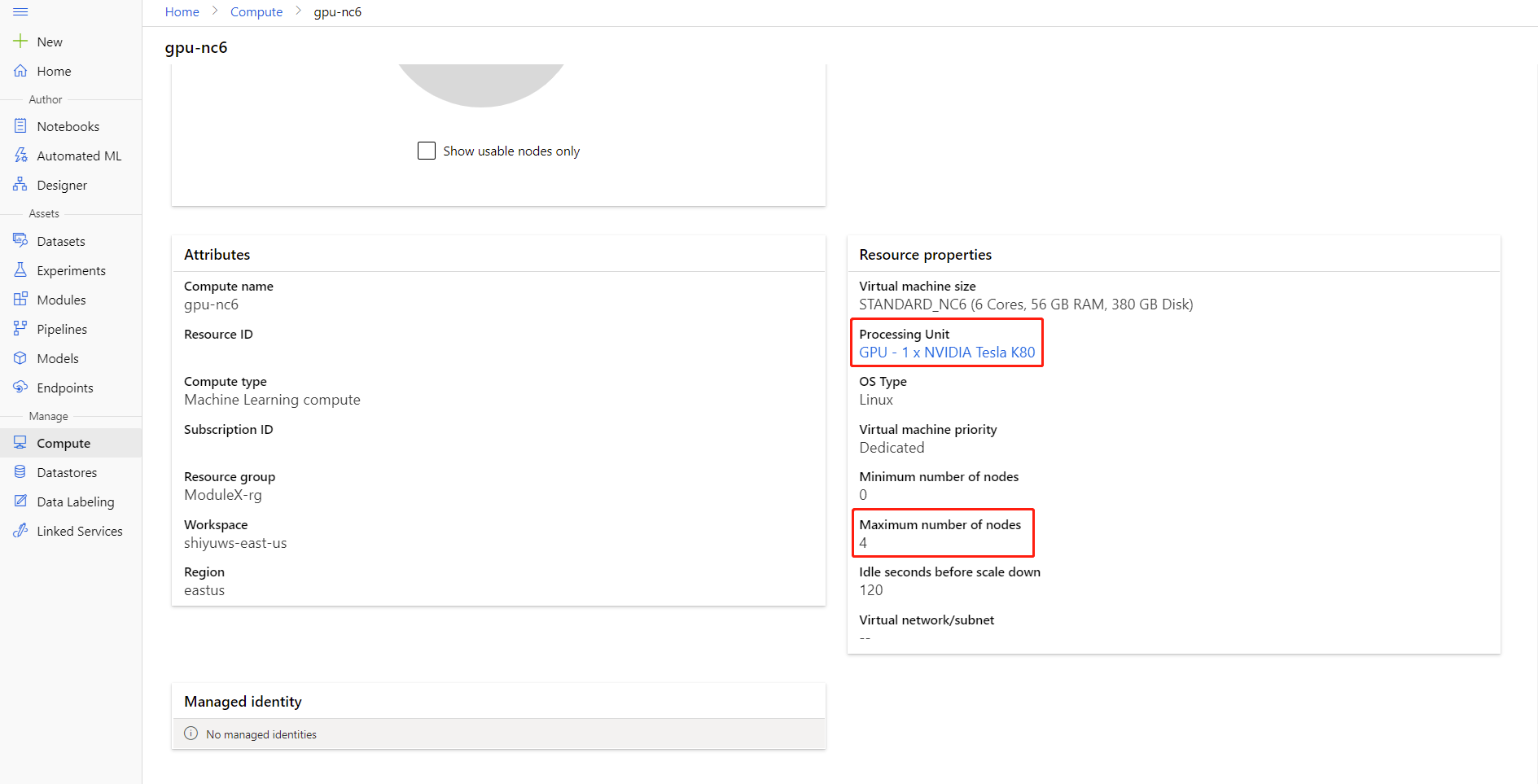
Você pode verificar o número máximo de nós e a unidade de processamento da computação clicando no nome da computação na página de detalhes da computação.


Pode saber mais sobre a formação distribuída no Azure Machine Learning aqui.
Solução de problemas para treinamento distribuído
Se você habilitar o treinamento distribuído para esse componente, haverá logs de driver para cada processo. 70_driver_log_0 é para o processo mestre. Você pode verificar os logs de driver para obter detalhes de erro de cada processo na guia Saídas + logs no painel direito.

Se o componente habilitado para treinamento distribuído falhar sem registros 70_driver , você poderá verificar 70_mpi_log se há detalhes do erro.
O exemplo a seguir mostra um erro comum, que é A contagem de processos por nó é maior do que a Unidade de Processamento da computação.

Você pode consultar este artigo para obter mais detalhes sobre a solução de problemas de componentes.
Resultados
Depois que o trabalho de pipeline for concluído, para usar o modelo para pontuação, conecte o Modelo Train PyTorch ao Modelo de Imagem de Pontuação, para prever valores para novos exemplos de entrada.
Notas técnicas
Insumos esperados
| Nome | Tipo | Description |
|---|---|---|
| Modelo não treinado | UntrainedModelDirectory | Modelo não treinado, requer PyTorch |
| Conjunto de dados de treinamento | Diretório de Imagens | Conjunto de dados de treinamento |
| Conjunto de dados de validação | Diretório de Imagens | Conjunto de dados de validação para avaliação em cada época |
Parâmetros dos componentes
| Nome | Intervalo | Type | Predefinido | Description |
|---|---|---|---|---|
| Épocas | >0 | Número inteiro | 5 | Selecione a coluna que contém o rótulo ou a coluna de resultado |
| Tamanho do lote | >0 | Número inteiro | 16 | Quantas instâncias treinar em um lote |
| Número do passo de aquecimento | >=0 | Número inteiro | 0 | Quantas épocas para aquecer o treino |
| Taxa de aprendizagem | >=o dobro. Epsilon | Float | 0.1 | A taxa de aprendizagem inicial para o otimizador de descida de gradiente estocástico. |
| Random seed | Qualquer | Número inteiro | 1 | A semente para o gerador de números aleatórios usado pelo modelo. |
| Paciência | >0 | Número inteiro | 3 | Quantas épocas para parar cedo o treino |
| Frequência de impressão | >0 | Número inteiro | 10 | Frequência de impressão do log de treinamento ao longo de iterações em cada época |
Saídas
| Nome | Tipo | Description |
|---|---|---|
| Modelo treinado | ModelDirectory | Modelo treinado |
Próximos passos
Consulte o conjunto de componentes disponíveis para o Azure Machine Learning.