Federação de vários sites e várias regiões
Muitas soluções sofisticadas exigem que os mesmos fluxos de eventos sejam disponibilizados para consumo em vários locais ou exigem que os fluxos de eventos sejam coletados em vários locais e, em seguida, consolidados em um local específico para consumo. Muitas vezes, também há a necessidade de enriquecer ou reduzir fluxos de eventos ou fazer conversões de formato de evento, também para dentro de uma única região e solução.
Na prática, isso significa que sua solução manterá vários Hubs de Eventos, geralmente em regiões diferentes e namespaces de Hubs de Eventos, e replicará eventos entre eles. Você também pode trocar eventos com fontes e destinos como o Barramento de Serviço do Azure, o Hub IoT do Azure ou o Apache Kafka.
A manutenção de vários Hubs de Eventos ativos em diferentes regiões também permite que os clientes escolham e alternem entre eles se seus conteúdos estiverem sendo mesclados, o que torna o sistema geral mais resiliente contra problemas de disponibilidade regional.
Este capítulo "Federação" explica os padrões de federação e como realizá-los usando o Azure Stream Analytics sem servidor ou os tempos de execução do Azure Functions, com a opção de ter seu próprio código de transformação ou enriquecimento diretamente no caminho do fluxo de eventos.
Padrões de federação
Há muitas motivações potenciais para que você queira mover eventos entre diferentes Hubs de Eventos ou outras fontes e destinos, e enumeramos os padrões mais importantes nesta seção e também vinculamos a orientações mais detalhadas para o respetivo padrão.
- Resiliência contra eventos de disponibilidade regional
- Otimização da latência
- Validação, redução e enriquecimento
- Integração com serviços de análise
- Consolidação e normalização de fluxos de eventos
- Divisão e roteamento de fluxos de eventos
- Projeções de log
Resiliência contra eventos de disponibilidade regional
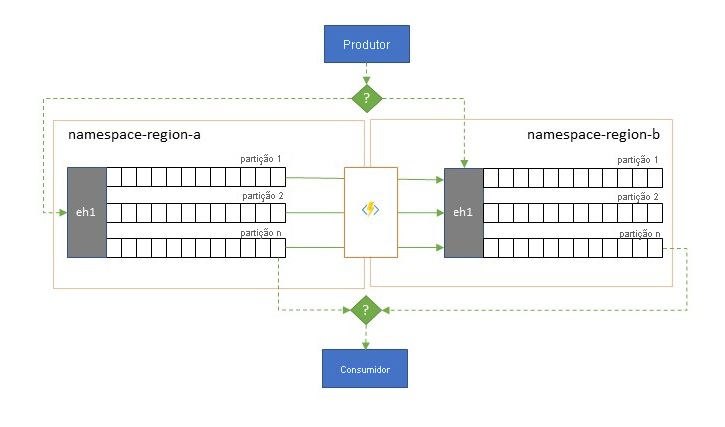
Embora a máxima disponibilidade e confiabilidade sejam as principais prioridades operacionais para Hubs de Eventos, há, no entanto, muitas maneiras pelas quais um produtor ou consumidor pode ser impedido de falar com seus Hubs de Eventos "primários" atribuídos devido a problemas de rede ou resolução de nomes, ou onde um Hubs de Eventos pode, de fato, não responder temporariamente ou retornar erros.
Essas condições não são "desastrosas", de modo que você queira abandonar completamente a implantação regional, como faria em uma situação de recuperação de desastre, mas o cenário de negócios de alguns aplicativos já pode ser afetado por eventos de disponibilidade que não duram mais do que alguns minutos ou até segundos.
Há dois padrões fundamentais para lidar com esses cenários:
- O padrão de replicação consiste em replicar o conteúdo de Hubs de Eventos primários para Hubs de Eventos secundários, em que os Hubs de Eventos primários geralmente são usados pelo aplicativo para produzir e consumir eventos e o secundário serve como uma opção de fallback caso os Hubs de Eventos primários estejam ficando indisponíveis. Como a replicação é unidirecional, do primário para o secundário, uma transição de produtores e consumidores de um primário indisponível para o secundário fará com que o primário antigo não receba mais novos eventos e, portanto, não será mais atual. Portanto, a replicação pura só é adequada para cenários de failover unidirecional. Depois que o failover for executado, o primário antigo será abandonado e um novo Hubs de Eventos secundário precisará ser criado em uma região de destino diferente.
- O padrão de mesclagem estende o padrão de replicação executando uma mesclagem contínua do conteúdo de dois ou mais Hubs de Eventos. Cada evento originalmente produzido em um dos Hubs de Eventos incluídos no esquema é replicado para os outros Hubs de Eventos. À medida que os eventos são replicados, eles são anotados de forma que são subsequentemente ignorados pelo processo de replicação do destino de replicação. Os resultados do uso do padrão de mesclagem são dois ou mais Hubs de Eventos que conterão o mesmo conjunto de eventos de forma eventualmente consistente.
Em ambos os casos, o conteúdo dos Hubs de Eventos não será idêntico. Os eventos de qualquer produtor e agrupados pela mesma chave de partição aparecerão na mesma ordem relativa que o enviado originalmente, mas a ordem absoluta dos eventos pode diferir. Isso é especialmente verdadeiro para cenários em que a contagem de partições dos Hubs de Eventos de origem e de destino diferem, o que é desejável para vários dos padrões estendidos descritos aqui. Um divisor ou roteador pode obter uma fatia de Hubs de Eventos muito maiores com centenas de partições e funil em Hubs de Eventos menores com apenas um punhado de partições, mais adequado para lidar com o subconjunto com recursos de processamento limitados. Por outro lado, uma consolidação pode canalizar dados de vários Hubs de Eventos menores em um único e maior Hubs de Eventos com mais partições para lidar com a taxa de transferência consolidada e as necessidades de processamento.
O critério para manter os eventos juntos é a chave de partição e não o ID da partição original. Outras considerações sobre a ordem relativa e como executar um failover de um Hubs de Eventos para o próximo sem depender do mesmo escopo de deslocamentos de fluxo são discutidas na descrição do padrão de replicação .
Orientação:
Otimização da latência
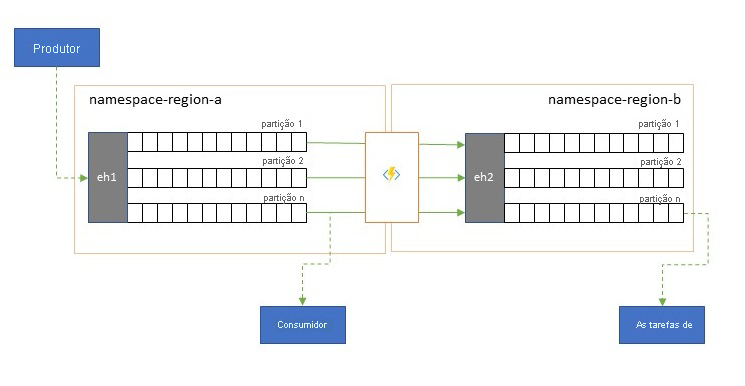
Os fluxos de eventos são escritos uma vez pelos produtores, mas podem ser lidos várias vezes pelos consumidores do evento. Para cenários em que um fluxo de eventos em uma região é compartilhado por vários consumidores e precisa ser acessado repetidamente durante o processamento de análise residente em uma região diferente, ou com demandas que excluiriam consumidores simultâneos, pode ser benéfico colocar uma cópia do fluxo de eventos perto do processador de análise para reduzir a latência de ida e volta.
Bons exemplos de quando a replicação deve ser preferida em vez de consumir eventos remotamente de várias regiões são especialmente aquelas em que as regiões estão extremamente distantes, por exemplo, Europa e Austrália sendo quase antípodas, geograficamente e latências de rede podem facilmente exceder 250 ms para qualquer viagem de ida e volta. Você não pode acelerar a velocidade da luz, mas pode reduzir o número de viagens de ida e volta de alta latência para interagir com os dados.
Orientação:
Validação, redução e enriquecimento
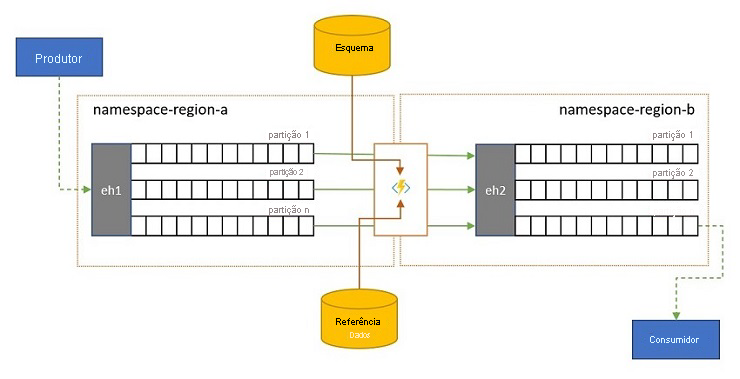
Os fluxos de eventos podem ser enviados para Hubs de Eventos por clientes externos à sua própria solução. Esses fluxos de eventos podem exigir que eventos enviados externamente sejam verificados quanto à conformidade com um determinado esquema e que eventos não compatíveis sejam descartados.
Em cenários em que os clientes são extremamente limitados em largura de banda, como é o caso em muitos cenários de "Internet das Coisas" com largura de banda limitada, ou onde os eventos são originalmente enviados por redes não-IP com tamanhos de pacotes restritos, os eventos podem ter que ser enriquecidos com dados de referência para adicionar mais contexto para serem utilizáveis por processadores de eventos downstream.
Em outros casos, especialmente quando os fluxos estão sendo consolidados, os dados do evento podem ter que ser reduzidos em complexidade ou tamanho absoluto omitindo alguns detalhes.
Qualquer uma dessas operações pode ocorrer como parte de fluxos de replicação, consolidação ou mesclagem.
Orientação:
Integração com serviços de análise
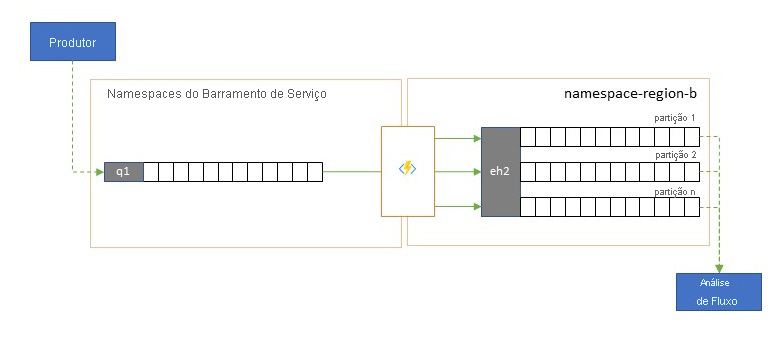
Vários dos serviços de análise nativos da nuvem do Azure, como o Azure Stream Analytics ou o Azure Synapse, funcionam melhor com dados transmitidos ou pré-agrupados fornecidos pelos Hubs de Eventos do Azure, e os Hubs de Eventos do Azure também permitem a integração com vários pacotes de análise de código aberto, como Apache Samza, Apache Flink, Apache Spark e Apache Storm.
Se sua solução usa principalmente o Service Bus ou a Grade de Eventos, você pode tornar esses eventos facilmente acessíveis a esses sistemas de análise e também para arquivamento com o Event Hubs Capture se você canalizá-los para Hubs de Eventos. A Grade de Eventos pode fazer isso nativamente com sua integração de Hubs de Eventos, para o Service Bus você segue as diretrizes de replicação do Service Bus.
O Azure Stream Analytics integra-se diretamente com os Hubs de Eventos.
Orientação:
Consolidação e normalização de fluxos de eventos
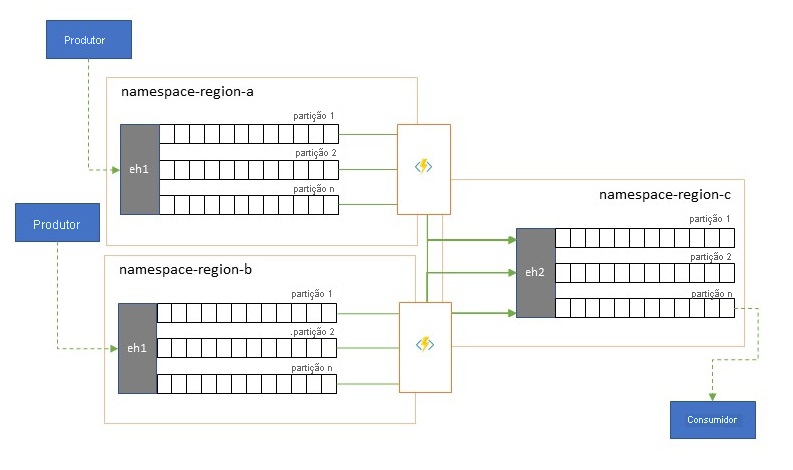
As soluções globais são muitas vezes compostas por pegadas regionais que são amplamente independentes, incluindo ter suas próprias capacidades de análise, mas as perspetivas de análise suprarregionais e globais exigirão uma perspetiva integrada e é por isso que uma consolidação central dos mesmos fluxos de eventos que são avaliados nas respetivas pegadas regionais para a perspetiva local.
A normalização é um sabor do cenário de consolidação, em que dois ou mais fluxos de eventos de entrada carregam o mesmo tipo de eventos, mas com estruturas diferentes ou codificações diferentes, e os eventos mais são transcodificados ou transformados antes de poderem ser consumidos.
A normalização também pode incluir trabalho criptográfico, como descriptografar cargas criptografadas de ponta a ponta e criptografá-las novamente com chaves e algoritmos diferentes para o público consumidor a jusante.
Orientação:
Divisão e roteamento de fluxos de eventos
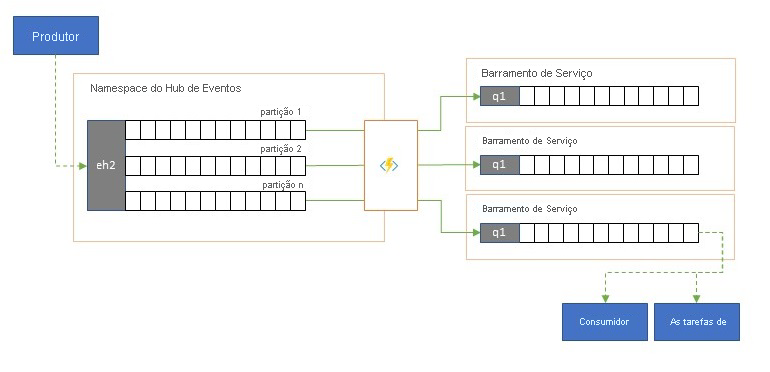
Os Hubs de Eventos do Azure são ocasionalmente usados em cenários no estilo "publicar-assinar" em que um torrent de eventos ingeridos de entrada excede em muito a capacidade do Barramento de Serviço do Azure ou da Grade de Eventos do Azure, ambos com recursos nativos de filtragem e distribuição de publicação-assinatura e são preferidos para esse padrão.
Enquanto um verdadeiro recurso "publicar-assinar" deixa para os assinantes escolherem os eventos que desejam, o padrão de divisão faz com que o produtor mapeie eventos para partições por um modelo de distribuição predeterminado e os consumidores designados então extraiam exclusivamente da "sua" partição. Com os Hubs de Eventos armazenando em buffer o tráfego geral, o conteúdo de uma partição específica, representando uma fração do volume de taxa de transferência original, pode ser replicado em uma fila para consumo de consumidor confiável, transacional e concorrente.
Muitos cenários em que os Hubs de Eventos são usados principalmente para mover eventos dentro de um aplicativo dentro de uma região têm alguns casos em que eventos selecionados, talvez apenas de uma única partição, também precisam ser disponibilizados em outro lugar. Esse cenário é semelhante ao cenário de divisão, mas pode usar um roteador escalável que considera todas as mensagens que chegam em um Hubs de Eventos e seleciona apenas algumas para roteamento posterior e pode diferenciar destinos de roteamento por metadados de evento ou conteúdo.
Orientação:
Projeções de log
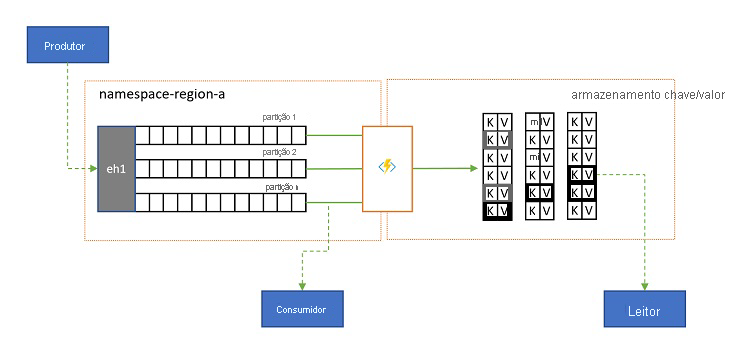
Em alguns cenários, você desejará ter acesso ao valor mais recente enviado para qualquer subfluxo de um evento e normalmente distinguido pela chave de partição. No Apache Kafka, isso geralmente é conseguido ativando a "compactação de log" em um tópico, que descarta todos, exceto o evento mais recente rotulado com qualquer chave exclusiva. A abordagem de compactação de log tem três desvantagens compostas:
- A compactação requer uma reorganização contínua do log, que é uma operação excessivamente cara para um broker otimizado para cargas de trabalho somente de apêndice.
- A compactação é destrutiva e não permite uma perspetiva compactada e não compactada do mesmo fluxo.
- Um fluxo compactado ainda tem um modelo de acesso sequencial, o que significa que encontrar o valor desejado no log requer a leitura de todo o log na pior das hipóteses, o que normalmente leva a otimizações que implementam o padrão exato apresentado aqui: projetar o conteúdo do log em um banco de dados ou cache.
Em última análise, um log compactado é um armazenamento de chave-valor e, como tal, é a pior opção de implementação possível para tal armazenamento. É muito mais eficiente para pesquisas e consultas criar e usar uma projeção permanente do log em um armazenamento de chave-valor adequado ou em algum outro banco de dados.
Como os eventos são imutáveis e a ordem é sempre preservada em um log, qualquer projeção de um log em um armazenamento de chave-valor sempre será idêntica para o mesmo intervalo de eventos, o que significa que uma projeção que você mantém atualizada sempre fornece uma exibição autoritativa e nunca há uma boa razão para reconstruí-la a partir do conteúdo do log uma vez construída.
Orientação:
Tecnologias de aplicativos de replicação
A implementação dos padrões acima requer um ambiente de execução escalável e confiável para as tarefas de replicação que você deseja configurar e executar. No Azure, os ambientes de tempo de execução mais adequados para essas tarefas são tarefas sem monitoração de estado são o Azure Stream Analytics para tarefas de replicação de fluxo com monitoração de estado e o Azure Functions para tarefas de replicação sem monitoração de estado.
Aplicativos de replicação com monitoração de estado no Azure Stream Analytics
Para aplicativos de replicação com monitoração de estado que precisam considerar relações entre eventos, criar eventos compostos, enriquecer eventos ou reduzir eventos, criar agregações de dados e transformar cargas úteis de eventos, o Azure Stream Analytics é a melhor opção de implementação.
No Azure Stream Analytics, você cria trabalhos que integram entradas e saídas e integram os dados das entradas por meio de consultas que produzem um resultado que é disponibilizado nas saídas.
As consultas são baseadas na linguagem de consulta SQL e podem ser usadas para filtrar, classificar, agregar e unir facilmente dados de streaming durante um período de tempo. Você também pode estender essa linguagem SQL com JavaScript e funções definidas pelo usuário (UDFs) em C#. Você pode facilmente ajustar as opções de ordenação de eventos e a duração das janelas de tempo ao executar operações de agregação por meio de construções e/ou configurações de linguagem simples.
Cada trabalho tem uma ou várias saídas para os dados transformados e você pode controlar o que acontece em resposta às informações analisadas. Por exemplo, pode:
- Envie dados para serviços como Azure Functions, Tópicos do Service Bus ou Filas para acionar comunicações ou fluxos de trabalho personalizados a jusante.
- Envie dados para um painel do Power BI para painéis em tempo real.
- Armazene dados em outros serviços de armazenamento do Azure (por exemplo, Azure Data Lake, Azure Synapse Analytics etc.) para executar análises em lote ou treinar modelos de aprendizado de máquina com base em pools muito grandes e indexados de dados históricos.
- Armazene projeções (também chamadas de "exibições materializadas") em bancos de dados (Banco de Dados SQL, Azure Cosmos DB).
Aplicativos de replicação sem monitoração de estado no Azure Functions
Para tarefas de replicação sem estado em que você deseja encaminhar eventos sem considerar suas cargas úteis ou processá-los individualmente sem ter que considerar as relações de eventos (exceto sua ordem relativa), você pode usar o Azure Functions, que fornece enorme flexibilidade.
O Azure Functions tem gatilhos pré-criados e escalonáveis e associações de saída para Hubs de Eventos do Azure, Hub IoT do Azure, Barramento de Serviço do Azure, Grade de Eventos do Azure e Armazenamento de Filas do Azure, bem como extensões personalizadas para RabbitMQe Apache Kafka. A maioria dos gatilhos se adaptará dinamicamente às necessidades de taxa de transferência, dimensionando o número de instâncias executadas simultaneamente para cima e para baixo com base em métricas documentadas.
Para criar projeções de log, o Azure Functions dá suporte a associações de saída para o Azure Cosmos DB e o Armazenamento de Tabela do Azure.
O Azure Functions pode ser executado sob uma identidade gerenciada do Azure e, com isso, ele pode manter os valores de configuração para credenciais em armazenamento de acesso rigorosamente controlado dentro do Cofre de Chaves do Azure.
Além disso, o Azure Functions permite que as tarefas de replicação se integrem diretamente às redes virtuais e pontos de extremidade de serviço do Azure para todos os serviços de mensagens do Azure e é prontamente integrado ao Azure Monitor.
Com o plano de consumo do Azure Functions, os gatilhos pré-criados podem até mesmo ser reduzidos a zero enquanto nenhuma mensagem estiver disponível para replicação, o que significa que você não incorre em custos para manter a configuração pronta para aumentar a escala; A principal desvantagem de usar o plano de consumo é que a latência para tarefas de replicação "acordando" desse estado é significativamente maior do que com os planos de hospedagem em que a infraestrutura é mantida em execução.
Em contraste com tudo isso, os mecanismos de replicação mais comuns para mensagens e eventos, como o MirrorMaker do Apache Kafka, exigem que você forneça um ambiente de hospedagem e dimensione o mecanismo de replicação por conta própria. Isso inclui configurar e integrar os recursos de segurança e rede e facilitar o fluxo de dados de monitoramento, e então você ainda não tem a oportunidade de injetar tarefas de replicação personalizadas no fluxo.
Escolher entre o Azure Functions e o Azure Stream Analytics
O Azure Stream Analytics (ASA) é a melhor opção sempre que você precisar processar a carga útil de seus eventos enquanto os replica. O ASA pode copiar eventos um a um ou pode criar agregações que condensam as informações de fluxos de eventos antes de encaminhá-las. Ele pode se apoiar prontamente na complementação de dados de referência mantidos no Armazenamento de Blobs do Azure ou no Banco de Dados SQL do Azure sem precisar importar esses dados para um fluxo.
Com o ASA, você pode criar facilmente visualizações persistentes e materializadas de fluxos em bancos de dados de hiperescala. É uma abordagem muito superior ao desajeitado modelo de "compactação de log" do Apache Kafka e às projeções voláteis de tabelas do lado do cliente do Kafka Streams.
O ASA pode processar prontamente eventos com cargas codificadas nos formatos CSV, JSON e Apache Avro e você pode conectar desserializadores personalizados para qualquer outro formato.
Para todas as tarefas de replicação em que você deseja copiar fluxos de eventos "no estado em que se encontram" e sem tocar nas cargas úteis, ou se precisar implementar um roteador, executar trabalho criptográfico, alterar a codificação de cargas úteis ou se precisar de controle total sobre o conteúdo do fluxo de dados, o Azure Functions é a melhor opção.
Passos Seguintes
Neste artigo, exploramos uma variedade de padrões de federação e explicamos a função do Azure Functions como o tempo de execução da replicação de eventos e mensagens no Azure.
Em seguida, convém ler como configurar um aplicativo replicador com o Azure Stream Analytics ou o Azure Functions e, em seguida, como replicar fluxos de eventos entre Hubs de Eventos e vários outros sistemas de eventos e mensagens: