Tutorial: Migrar o Oracle WebLogic Server para Máquinas Virtuais do Azure com alta disponibilidade e recuperação de desastres
Este tutorial mostra uma maneira simples e eficaz de implementar alta disponibilidade e recuperação de desastres (HA/DR) para Java usando o Oracle WebLogic Server (WLS) em máquinas virtuais (VMs) do Azure. A solução ilustra como alcançar um RTO (Recovery Time Objetive, objetivo de tempo de recuperação) e um RPO (Recovery Point Objetive, objetivo de ponto de recuperação) baixos usando um aplicativo Jakarta EE simples e controlado por banco de dados em execução no WLS. HA/DR é um tema complexo, com muitas soluções possíveis. A melhor solução depende dos seus requisitos exclusivos. Para obter outras maneiras de implementar HA/DR, consulte os recursos no final deste artigo.
Neste tutorial, irá aprender a:
- Use as práticas recomendadas otimizadas do Azure para obter alta disponibilidade e recuperação de desastres.
- Configure um grupo de failover do Banco de Dados SQL do Microsoft Azure em regiões emparelhadas.
- Configure clusters WLS emparelhados em VMs do Azure.
- Configure um Gerenciador de Tráfego do Azure.
- Configure clusters WLS para alta disponibilidade e recuperação de desastres.
- Teste o failover do primário para o secundário.
O diagrama a seguir ilustra a arquitetura que você cria:

O Azure Traffic Manager verifica a integridade de suas regiões e roteia o tráfego de acordo com a camada de aplicativo. Tanto a região primária quanto a secundária têm uma implantação completa do cluster WLS. No entanto, apenas a região primária está atendendo ativamente às solicitações de rede dos usuários. A região secundária é passiva e ativada para receber tráfego somente quando a região primária sofre uma interrupção de serviço. O Azure Traffic Manager usa o recurso de verificação de integridade do Gateway de Aplicativo do Azure para implementar esse roteamento condicional. O cluster WLS primário está em execução e o cluster secundário é desligado. O RTO de failover geográfico da camada de aplicativo depende do tempo para iniciar VMs e executar o cluster WLS secundário. O RPO depende do Banco de Dados SQL do Azure porque os dados são persistentes e replicados no grupo de failover do Banco de Dados SQL do Azure.
A camada de banco de dados consiste em um grupo de failover do Banco de Dados SQL do Azure com um servidor primário e um servidor secundário. O servidor primário está no modo de leitura/gravação ativo e conectado ao cluster WLS primário. O servidor secundário está no modo pronto passivo e conectado ao cluster WLS secundário. Um failover geográfico alterna todos os bancos de dados secundários do grupo para a função principal. Para RPO e RTO de failover geográfico do Banco de Dados SQL do Azure, consulte Visão geral da continuidade de negócios.
Este artigo foi escrito com o serviço Banco de Dados SQL do Azure porque o artigo depende dos recursos de alta disponibilidade (HA) desse serviço. Outras opções de banco de dados são possíveis, mas você deve considerar os recursos de HA de qualquer banco de dados escolhido. Para obter mais informações, incluindo informações sobre como otimizar a configuração de fontes de dados para replicação, consulte Configurando fontes de dados para implantação ativa-passiva do Oracle Fusion Middleware.
Pré-requisitos
- Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
- Verifique se você tem a
Ownerfunção ou asContributorfunções eUser Access Administratorna assinatura. Você pode verificar a atribuição seguindo as etapas em Listar atribuições de função do Azure usando o portal do Azure. - Prepare uma máquina local com Windows, Linux ou macOS instalado.
- Instale e configure o Git.
- Instale uma implementação Java SE, versão 17 ou posterior (por exemplo, a compilação Microsoft do OpenJDK).
- Instale o Maven, versão 3.9.3 ou posterior.
Configurar um grupo de failover do Banco de Dados SQL do Azure em regiões emparelhadas
Nesta seção, você cria um grupo de failover do Banco de Dados SQL do Azure em regiões emparelhadas para uso com seus clusters WLS e aplicativo. Em uma seção posterior, você configura o WLS para armazenar seus dados de sessão e dados de log de transações (TLOG) para esse banco de dados. Essa prática é consistente com a Maximum Availability Architecture (MAA) da Oracle. Esta orientação fornece uma adaptação do Azure para MAA. Para obter mais informações sobre MAA, consulte Oracle Maximum Availability Architecture.
Primeiro, crie o Banco de Dados SQL do Azure primário seguindo as etapas do portal do Azure em Guia de início rápido: criar um único banco de dados - Banco de Dados SQL do Azure. Siga as etapas até, mas não incluindo, a seção "Limpar recursos". Use as seguintes instruções ao percorrer o artigo e, em seguida, retorne a este artigo depois de criar e configurar o Banco de Dados SQL do Azure:
Quando chegar à seção Criar um único banco de dados, use as seguintes etapas:
- Na etapa 4 para criar um novo grupo de recursos, salve de lado o valor do nome do grupo de recursos - por exemplo, myResourceGroup.
- Na etapa 5 para nome do banco de dados, salve de lado o valor Nome do banco de dados - por exemplo, mySampleDatabase.
- Na etapa 6 para criar o servidor, use as seguintes etapas:
- Salve de lado o nome exclusivo do servidor - por exemplo, sqlserverprimary-ejb120623.
- Em Local, selecione (EUA) Leste dos EUA.
- Em Método de autenticação, selecione Usar autenticação SQL.
- Salve de lado o valor de login do administrador do servidor - por exemplo, azureuser.
- Salve de lado o valor da senha .
- Na etapa 8, para Ambiente de carga de trabalho, selecione Desenvolvimento. Observe a descrição e considere outras opções para sua carga de trabalho.
- Na etapa 11, para Redundância de armazenamento de backup, selecione Armazenamento de backup com redundância local. Considere outras opções para seus backups. Para obter mais informações, consulte a seção Redundância de armazenamento de backup de Backups automatizados no Banco de Dados SQL do Azure.
- Na etapa 14, na configuração de regras de firewall, para Permitir que os serviços e recursos do Azure acessem este servidor, selecione Sim.
Quando chegar à seção Consultar o banco de dados, use as seguintes etapas:
Na etapa 3, insira as informações de entrada do administrador do servidor de autenticação SQL para entrar.
Nota
Se o início de sessão falhar com uma mensagem de erro semelhante a Cliente com endereço IP 'xx.xx.xx.xx' não tem permissão para aceder ao servidor, selecione Allowlist IP xx.xx.xx.xx no servidor <your-sqlserver-name> no final da mensagem de erro. Aguarde até que as regras de firewall do servidor concluam a atualização e selecione OK novamente.
Depois de executar a consulta de exemplo na etapa 5, limpe o editor e crie tabelas.
Insira a seguinte consulta para criar o esquema para TLOG.
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));
Após uma execução bem-sucedida, você verá a mensagem Consulta bem-sucedida: Linhas afetadas: 0.
Essas tabelas de banco de dados são usadas para armazenar log de transações (TLOG) e dados de sessão para seus clusters WLS e aplicativo. Para obter mais informações, consulte Usando um armazenamento TLOG JDBC e Usando um banco de dados para armazenamento persistente (persistência JDBC).
Em seguida, crie um grupo de failover do Banco de Dados SQL do Azure seguindo as etapas do portal do Azure em Configurar um grupo de failover para o Banco de Dados SQL do Azure. Você só precisa das seguintes seções: Criar grupo de failover e Testar failover planejado. Use as etapas a seguir ao longo do artigo e retorne a este artigo depois de criar e configurar o grupo de failover do Banco de Dados SQL do Azure:
Quando chegar à seção Criar grupo de failover, use as seguintes etapas:
- Na etapa 5 para criar o grupo de failover, selecione a opção para criar um novo servidor secundário e use as seguintes etapas:
- Insira e salve de lado o nome do grupo de failover - por exemplo, failovergroupname-ejb120623.
- Digite e salve de lado o nome exclusivo do servidor - por exemplo, sqlserversecondary-ejb120623.
- Introduza o mesmo administrador do servidor e palavra-passe que o servidor principal.
- Em Local, selecione uma região diferente daquela usada para o banco de dados primário.
- Certifique-se de que a opção Permitir que os serviços do Azure acedam ao servidor está selecionada.
- Na etapa 5 para configurar os bancos de dados dentro do grupo, selecione o banco de dados que você criou no servidor primário - por exemplo, mySampleDatabase.
- Na etapa 5 para criar o grupo de failover, selecione a opção para criar um novo servidor secundário e use as seguintes etapas:
Depois de concluir todas as etapas na seção Testar failover planejado, mantenha a página do grupo de failover aberta e use-a para o teste de failover dos clusters WLS mais tarde.
Nota
Este artigo orienta você a criar um banco de dados único do Banco de Dados SQL do Azure com autenticação SQL para simplificar, pois a configuração de HA/DR na qual este artigo se concentra já é muito complexa. Uma prática mais segura é usar autenticação do Microsoft Entra para SQL do Azure para autenticar a conexão do servidor de banco de dados. Para obter informações sobre como configurar a conexão de banco de dados com a autenticação do Microsoft Entra, consulte Configurar conexões de banco de dados sem senha para aplicativos Java no Oracle WebLogic Server.
Configurar clusters WLS emparelhados em VMs do Azure
Nesta seção, você cria dois clusters WLS em VMs do Azure usando a oferta Oracle WebLogic Server Cluster on Azure VMs . O cluster no Leste dos EUA é primário e é configurado como o cluster ativo posteriormente. O cluster no oeste dos EUA é secundário e é configurado como o cluster passivo posteriormente.
Configurar o cluster WLS primário
Primeiro, abra a oferta Oracle WebLogic Server Cluster on Azure VMs em seu navegador e selecione Criar. Você deve ver o painel Noções básicas da oferta.
Use as seguintes etapas para preencher o painel Noções básicas :
- Verifique se o valor mostrado para Assinatura é o mesmo que tem as funções listadas na seção de pré-requisitos.
- Você deve implantar a oferta em um grupo de recursos vazio. No campo Grupo de recursos, selecione Criar novo e preencha um valor exclusivo para o grupo de recursos - por exemplo, wls-cluster-eastus-ejb120623.
- Em Detalhes da instância, para Região, selecione Leste dos EUA.
- Em Credenciais para Máquinas Virtuais e WebLogic, forneça uma senha para a conta de administrador da VM e do Administrador WebLogic, respectivamente. Guarde de lado o nome de utilizador e a palavra-passe do WebLogic Administrator. Para maior segurança, considere usar Chave Pública SSH como o tipo de autenticação de VM.
- Deixe os padrões para outros campos.
- Selecione Avançar para ir para o painel Configuração TLS/SSL.

Deixe os padrões no painel Configuração TLS /SSL, selecione Avançar para ir para o painel Gateway de Aplicativo do Azure e use as etapas a seguir.
- Para Conectar ao Gateway de Aplicativo do Azure?, selecione Sim.
- Para a opção Selecionar certificado TLS/SSL desejado, selecione Gerar um certificado autoassinado.
- Selecione Avançar para ir para o painel Rede .

Você verá todos os campos pré-preenchidos com os padrões no painel Rede . Use as seguintes etapas para salvar a configuração de rede:
Selecione Editar rede virtual. Salve de lado o espaço de endereço da rede virtual - por exemplo, 10.1.4.0/23.
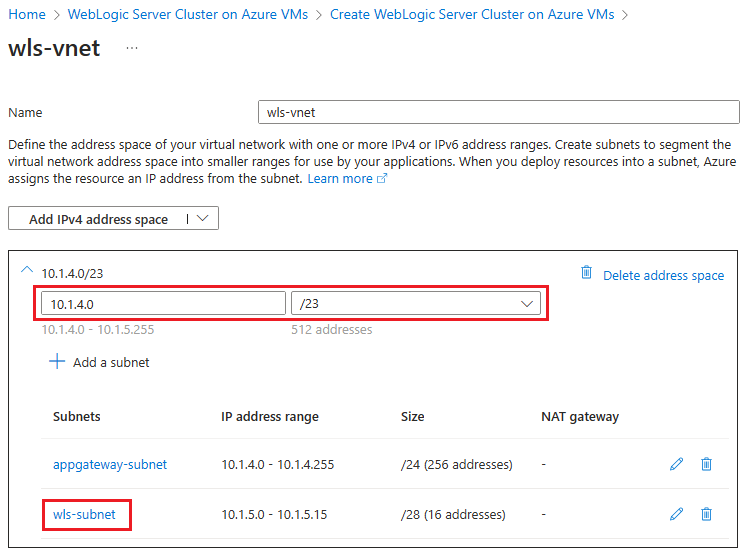
Selecione
wls-subnetpara editar a sub-rede. Em Detalhes da sub-rede, guarde o endereço inicial e o tamanho da sub-rede - por exemplo, 10.1.5.0 e /28.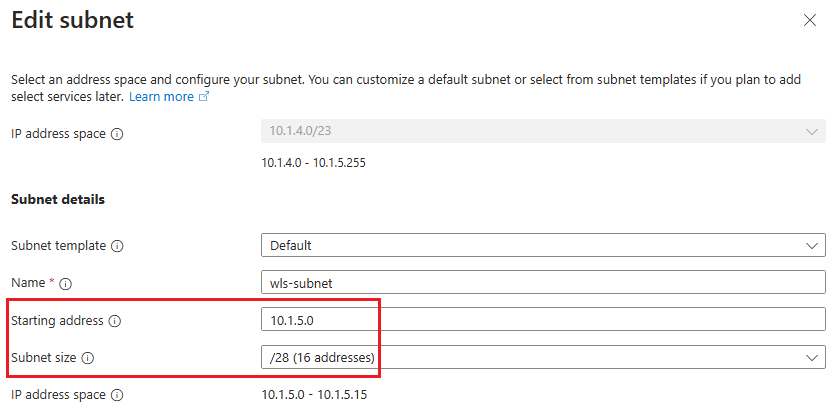
Se você fizer alguma modificação, salve as alterações.
Regresse ao painel Rede .
Selecione Avançar para ir para o painel Banco de dados .


As etapas a seguir mostram como preencher o painel Banco de dados :
- Em Conectar ao banco de dados?, selecione Sim.
- Em Escolher tipo de banco de dados, selecione Microsoft SQL Server (Suporte a conexão sem senha) .
- Para JNDI Name, digite jdbc/WebLogicCafeDB.
- Para DataSource Connection String, substitua os espaços reservados pelos valores salvos na seção anterior para o Banco de dados SQL primário - por exemplo, jdbc:sqlserver://sqlserverprimary-ejb120623.database.windows.net:1433; database=mySampleDatabase.
- Em Protocolo de transação global, selecione Nenhum.
- Para Nome de usuário do banco de dados, substitua os espaços reservados pelos valores salvos na seção anterior para o Banco de dados SQL primário - por exemplo, azureuser@sqlserverprimary-ejb120623.
- Introduza a palavra-passe de início de sessão do administrador do servidor que guardou anteriormente para a Palavra-passe da Base de Dados. Digite o mesmo valor para Confirmar senha.
- Deixe os padrões para os outros campos.
- Selecione Rever + criar.
- Aguarde até que a Execução da validação final... seja concluída com êxito e, em seguida, selecione Criar.

Nota
Este artigo orienta você a se conectar a um Banco de Dados SQL do Azure com autenticação SQL para simplificar, pois a configuração de HA/DR na qual este artigo se concentra já é muito complexa. Uma prática mais segura é usar autenticação do Microsoft Entra para SQL do Azure para autenticar a conexão do servidor de banco de dados. Para obter informações sobre como configurar a conexão de banco de dados com a autenticação do Microsoft Entra, consulte Configurar conexões de banco de dados sem senha para aplicativos Java no Oracle WebLogic Server.
Depois de um tempo, você verá a página Implantação onde a Implantação está em andamento é exibida.
Nota
Se vir algum problema durante a execução da validação final..., corrija-o e tente novamente.
Dependendo das condições da rede e de outras atividades na região selecionada, a implantação pode levar até 50 minutos para ser concluída. Depois disso, você verá o texto Sua implantação foi concluída exibido na página de implantação.
Enquanto isso, você pode configurar o cluster WLS secundário em paralelo.
Configurar o cluster WLS secundário
Siga as mesmas etapas na seção Configurar o cluster WLS primário para configurar o cluster WLS secundário na região Oeste dos EUA, exceto pelas seguintes diferenças:
No painel Noções básicas, use as seguintes etapas:
- No campo Grupo de recursos, selecione Criar novo e preencha um valor exclusivo diferente para o grupo de recursos - por exemplo, wls-cluster-westtus-ejb120623.
- Em Detalhes da instância, em Região, selecione Oeste dos EUA.
No painel Rede, use as seguintes etapas:
Para Editar rede virtual, insira o mesmo espaço de endereço da rede virtual que o cluster WLS principal - por exemplo, 10.1.4.0/23.
Nota
Você verá uma mensagem de aviso semelhante à seguinte: O espaço de endereço '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' se sobrepõe ao espaço de endereço '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' da rede virtual 'wls-vnet'. As redes virtuais com espaço de endereçamento sobreposto não podem ser emparelhadas. Se você pretende emparelhar essas redes virtuais, altere o espaço de endereço '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)'. Você pode ignorar essa mensagem porque precisa de dois clusters WLS com a mesma configuração de rede.
Para
wls-subnet, insira o mesmo endereço inicial e tamanho de sub-rede do cluster WLS principal - por exemplo, 10.1.5.0 e /28.
No painel Banco de dados, use as seguintes etapas:
- Para DataSource Connection String, substitua os espaços reservados pelos valores salvos na seção anterior para o Banco de dados SQL secundário - por exemplo, jdbc:sqlserver://sqlserversecondary-ejb120623.database.windows.net:1433; database=mySampleDatabase.
- Para Nome de usuário do banco de dados, substitua os espaços reservados pelos valores salvos na seção anterior para o Banco de dados SQL secundário - por exemplo, azureuser@sqlserversecondary-ejb120623.
Espelhar as configurações de rede para os dois clusters
Durante a fase de retomada de transações pendentes no cluster WLS secundário após um failover, o WLS verifica a propriedade do armazenamento TLOG. Para passar com êxito na verificação, todos os servidores gerenciados no cluster secundário devem ter o mesmo endereço IP privado que o cluster primário.
Esta seção mostra como espelhar as configurações de rede do cluster primário para o cluster secundário.
Primeiro, use as seguintes etapas para definir as configurações de rede para o cluster primário após a conclusão de sua implantação:
No painel Visão geral da página Implantação, selecione Ir para o grupo de recursos.
Selecione a interface
adminVM_NIC_with_pub_ipde rede .- Em Configurações, selecione Configurações de IP.
- Selecione
ipconfig1. - Em Configurações de endereço IP privado, selecione Estático para alocação. Deixe de lado o endereço IP privado.
- Selecione Guardar.
Retorne ao grupo de recursos do cluster WLS primário e repita a etapa 3 para as interfaces
mspVM1_NIC_with_pub_ipde rede ,mspVM2_NIC_with_pub_ipemspVM3_NIC_with_pub_ip.Aguarde até que todas as atualizações sejam concluídas. Você pode selecionar o ícone de notificações no portal do Azure para abrir o painel Notificações para monitoramento de status.

Retorne ao grupo de recursos do cluster WLS primário e copie o nome do recurso com o tipo Ponto de extremidade privado - por exemplo, 7e8c8bsaep. Use esse nome para encontrar a interface de rede restante - por exemplo, 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a. Selecione-o e siga as etapas anteriores para obter seu endereço IP privado.
Em seguida, use as seguintes etapas para definir as configurações de rede para o cluster secundário após a conclusão de sua implantação:
No painel Visão geral da página Implantação, selecione Ir para o grupo de recursos.
Para as interfaces
adminVM_NIC_with_pub_ipde rede ,mspVM1_NIC_with_pub_ip,mspVM2_NIC_with_pub_ip, emspVM3_NIC_with_pub_ip, siga as etapas anteriores para atualizar a alocação de endereço IP privado para Static.Aguarde até que todas as atualizações sejam concluídas.
Para as interfaces
mspVM1_NIC_with_pub_ipde rede ,mspVM2_NIC_with_pub_ip, emspVM3_NIC_with_pub_ip, siga as etapas anteriores, mas atualize o endereço IP privado para o mesmo valor usado com o cluster primário. Aguarde até que a atualização atual da interface de rede seja concluída antes de prosseguir para a próxima.Nota
Não é possível alterar o endereço IP privado da interface de rede que faz parte de um ponto de extremidade privado. Para espelhar facilmente os endereços IP privados das interfaces de rede para servidores gerenciados, considere atualizar o endereço IP privado para
adminVM_NIC_with_pub_ipum endereço IP que não seja usado. Dependendo da alocação de endereços IP privados em seus dois clusters, talvez seja necessário atualizar o endereço IP privado no cluster primário também.
A tabela a seguir mostra um exemplo de espelhamento das configurações de rede para dois clusters:
| Cluster | Interface de Rede | Endereço IP privado (antes) | Endereço IP privado (após) | Sequência de atualização |
|---|---|---|---|---|
| Primário | 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a |
10.1.5.4 |
10.1.5.4 |
|
| Primário | adminVM_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.7 |
|
| Primário | mspVM1_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.5 |
|
| Primário | mspVM2_NIC_with_pub_ip |
10.1.5.8 |
10.1.5.9 |
1 |
| Primário | mspVM3_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.6 |
|
| Secundária | 1696b0saep.nic.2e19bf46-9799-4acc-b64b-a2cd2f7a4ee1 |
10.1.5.8 |
10.1.5.8 |
|
| Secundária | adminVM_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.4 |
4 |
| Secundária | mspVM1_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.5 |
5 |
| Secundária | mspVM2_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.9 |
2 |
| Secundária | mspVM3_NIC_with_pub_ip |
10.1.5.4 |
10.1.5.6 |
3 |
Verifique o conjunto de endereços IP privados para todos os servidores gerenciados, que consiste no pool de back-end do Gateway de Aplicativo do Azure implantado em cada cluster. Se ele for atualizado, use as seguintes etapas para atualizar o pool de back-end do Gateway de Aplicativo do Azure de acordo:
- Abra o grupo de recursos do cluster.
- Encontre o recurso myAppGateway com o tipo Application gateway. Selecione-o para abri-lo.
-
Na seção Configurações, selecione Pools de back-end e, em seguida, selecione
myGatewayBackendPool. - Altere os valores de Destinos de back-end com o(s) endereço(s) IP privado atualizado(s) e selecione Salvar. Aguarde até que seja concluído.
- Na seção Configurações, selecione Sondas de integridade e, em seguida, selecione HTTPhealthProbe.
- Certifique-se de que quero testar a integridade do back-end antes de adicionar o teste de integridade está selecionado e, em seguida, selecione Testar. Você deve ver que o valor Status do pool
myGatewayBackendPoolde back-end está marcado como íntegro. Se não estiver, verifique se os endereços IP privados são atualizados conforme o esperado e se as VMs estão em execução e, em seguida, teste a investigação de integridade novamente. Você deve solucionar e resolver o problema antes de continuar.
No exemplo a seguir, o pool de back-end do Gateway de Aplicativo do Azure para cada cluster é atualizado:
| Cluster | Pool de back-end do Azure Application Gateway | Destinos de back-end (antes) | Destinos de back-end (depois) |
|---|---|---|---|
| Primário | myGatewayBackendPool |
(10.1.5.5, 10.1.5.8, 10.1.5.6) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
| Secundária | myGatewayBackendPool |
(10.1.5.7, 10.1.5.6, 10.1.5.4) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
Para automatizar o espelhamento de configurações de rede, considere usar a CLI do Azure. Para obter mais informações, consulte Introdução à CLI do Azure.
Verificar as implantações dos clusters
Você implantou um Gateway de Aplicativo do Azure e um servidor de administração WLS em cada cluster. O Gateway de Aplicativo do Azure atua como balanceador de carga para todos os servidores gerenciados no cluster. O servidor de administração WLS fornece um console da Web para configuração de cluster.
Use as etapas a seguir para verificar se o Gateway de Aplicativo do Azure e o console de administração WLS em cada cluster funcionam antes de passar para a próxima etapa:
- Retorne à página Implantação e selecione Saídas.
- Copie o valor da propriedade appGatewayURL. Anexe a string weblogic/ready e abra essa URL em uma nova guia do navegador. Você verá uma página vazia sem qualquer mensagem de erro. Caso contrário, você deve solucionar e resolver o problema antes de continuar.
- Copie e salve de lado o valor da propriedade adminConsole. Abra-o em uma nova guia do navegador. Você deve ver a página de entrada do WebLogic Server Administration Console. Entre no console com o nome de usuário e senha do administrador WebLogic que você salvou anteriormente. Se não conseguir iniciar sessão, tem de resolver o problema antes de continuar.
Use as etapas a seguir para obter o endereço IP do Gateway de Aplicativo do Azure para cada cluster. Você usa esses valores ao configurar o Gerenciador de Tráfego do Azure posteriormente.
- Abra o grupo de recursos onde o cluster está implantado - por exemplo, selecione Visão geral para voltar para o painel Visão geral da página de implantação. Em seguida, selecione Ir para o grupo de recursos.
- Encontre o recurso
gwipcom o tipo Endereço IP público e selecione-o para abri-lo. Procure o campo Endereço IP e guarde o seu valor.
Configurar um Azure Traffic Manager
Nesta seção, você cria um Gerenciador de Tráfego do Azure para distribuir o tráfego para seus aplicativos voltados para o público nas regiões globais do Azure. O ponto de extremidade primário aponta para o Gateway de Aplicativo do Azure no cluster WLS primário e o ponto de extremidade secundário aponta para o Gateway de Aplicativo do Azure no cluster WLS secundário.
Crie um perfil do Azure Traffic Manager seguindo Guia de início rápido: crie um perfil do Gerenciador de Tráfego usando o portal do Azure. Ignore a seção Pré-requisitos . Você só precisa das seguintes seções: Criar um perfil do Gerenciador de Tráfego, Adicionar pontos de extremidade do Gerenciador de Tráfego e Testar perfil do Gerenciador de Tráfego. Use as etapas a seguir ao percorrer essas seções e retorne a este artigo depois de criar e configurar o Gerenciador de Tráfego do Azure.
Quando chegar à secção Criar um perfil do Gestor de Tráfego, na etapa 2 Criar perfil do Gestor de Tráfego, execute os seguintes passos:
- Deixe de lado o nome de perfil exclusivo do Gerenciador de Tráfego para Nome - por exemplo,
tmprofile-ejb120623. - Deixe de lado o novo nome do grupo de recursos para grupo de recursos - por exemplo,
myResourceGroupTM1.
- Deixe de lado o nome de perfil exclusivo do Gerenciador de Tráfego para Nome - por exemplo,
Quando chegar à seção Adicionar pontos de extremidade do Gerenciador de Tráfego, use as seguintes etapas:
Execute esta ação extra após a etapa Selecione o perfil nos resultados da pesquisa.
Em Definições, selecione Configuração.
Para DNS time to live (TTL), digite 10.
Em Configurações do monitor de ponto final, para Caminho, digite /weblogic/ready.
Nas definições rápidas de failover de ponto de extremidade, utilize os seguintes valores:
- Em Sondagem interna, digite 10.
- Em Número tolerado de falhas, digite 3.
- Para o tempo limite da sonda, 5.
Selecione Guardar. Aguarde até que seja concluído.
Na etapa 4 para adicionar o ponto de extremidade primário
myPrimaryEndpoint, siga os passos seguintes:Em Tipo de recurso de destino, selecione Endereço IP público.
Selecione a lista suspensa Escolher endereço IP público e insira o endereço IP do Application Gateway implantado no cluster WLS do Leste dos EUA que você salvou anteriormente. Você verá uma entrada correspondida. Selecione-o para Endereço IP público.
Na etapa 6, para adicionar um ponto de falha ou endpoint secundário
myFailoverEndpoint, proceda da seguinte forma:Em Tipo de recurso de destino, selecione Endereço IP público.
Selecione a lista suspensa
Escolha o endereço IP público e insira o endereço IP do Application Gateway implantado no cluster WLSWest US 2 que você salvou anteriormente. Você verá uma entrada correspondida. Selecione-o para Endereço IP público.
Espere um pouco. Selecione Atualizar até que o valor de status do Monitor para ambos os pontos de extremidade seja Online.
Quando você chegar à seção Testar perfil do Gerenciador de Tráfego, use as seguintes etapas:
Na seção Verifique o nome DNS, na etapa 3, salve de lado o nome DNS do seu perfil do Gerenciador de Tráfego - por exemplo,
http://tmprofile-ejb120623.trafficmanager.net.Na seção Exibir o Gerenciador de Tráfego na ação, use as seguintes etapas:
Nas etapas 1 e 3, acrescente /weblogic/ready ao nome DNS do seu perfil do Gerenciador de Tráfego no navegador da Web - por exemplo,
http://tmprofile-ejb120623.trafficmanager.net/weblogic/ready. Você verá uma página vazia sem qualquer mensagem de erro.Depois de concluir todas as etapas, certifique-se de habilitar seu ponto de extremidade principal fazendo referência à etapa 2, mas substitua Desabilitado por Habilitado. Em seguida, volte para a página Pontos de extremidade .
Agora você tem os pontos de extremidade Habilitados e Online no perfil do Gerenciador de Tráfego. Mantenha a página aberta e use-a para monitorar o status do ponto final mais tarde.
Configurar os clusters WLS para alta disponibilidade e recuperação de desastres
Nesta seção, você configura clusters WLS para alta disponibilidade e recuperação de desastres.
Preparar o aplicativo de exemplo
Nesta seção, você cria e empacota um aplicativo CRUD Java/JakartaEE de exemplo que posteriormente implanta e executa em clusters WLS para teste de failover.
O aplicativo usa a persistência de sessão JDBC do WebLogic Server para armazenar dados de sessão HTTP. A fonte jdbc/WebLogicCafeDB de dados armazena os dados da sessão para habilitar o failover e o balanceamento de carga em um cluster de WebLogic Servers. Ele configura um esquema de persistência para persistir dados coffee de aplicativos na mesma fonte jdbc/WebLogicCafeDBde dados.
Use as seguintes etapas para criar e empacotar o exemplo:
Use os seguintes comandos para clonar o repositório de exemplo e verificar a tag correspondente a este artigo:
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206Se vir uma mensagem sobre
Detached HEADo , é seguro ignorá-lo.Use os seguintes comandos para navegar até o diretório de exemplo e, em seguida, compilar e empacotar o exemplo:
cd weblogic-cafe mvn clean package
Quando o pacote é gerado com sucesso, você pode encontrá-lo em >. Se não vir o pacote, tem de resolver o problema antes de continuar.
Implantar o aplicativo de exemplo
Agora, use as seguintes etapas para implantar o aplicativo de exemplo nos clusters, começando pelo cluster primário:
- Abra o adminConsole do cluster em uma nova guia do seu navegador da Web. Entre no Console de Administração do WebLogic Server com o nome de usuário e a senha do Administrador WebLogic que você salvou anteriormente.
- Localize >>Deployments no painel de navegação. Selecione Implementações.
- Selecione Bloquear & Editar>Instalação>Escolha o arquivo. Selecione o arquivo weblogic-café.war que você preparou anteriormente.
- Selecione Avançar>Próximo>Próximo. Selecione
cluster1com a opção Todos os servidores no cluster para os destinos de implantação. Selecione Seguinte>Concluir. Selecione Ativar alterações. - Alterne para a guia Controle e selecione
weblogic-cafena tabela de implantações. Selecione Iniciar com a opção Atendendo a todas as solicitações>Sim. Aguarde um pouco e atualize a página até ver que o estado da implantaçãoweblogic-cafeé Ativo. Alterne para a guia Monitoramento e verifique se a raiz de contexto do aplicativo implantado é /weblogic-café. Mantenha o console de administração do WLS aberto para que você possa usá-lo mais tarde para configuração adicional.
Repita as mesmas etapas no WebLogic Server Administration Console, mas para o cluster secundário na região Oeste dos EUA.
Atualizar o host front-end
Use as etapas a seguir para tornar seus clusters WLS cientes do Gerenciador de Tráfego do Azure. Como o Gerenciador de Tráfego do Azure é o ponto de entrada para solicitações de usuário, atualize o Host Frontal do cluster do WebLogic Server para o nome DNS do perfil do Gerenciador de Tráfego, começando a partir do cluster primário.
- Verifique se você está conectado ao WebLogic Server Administration Console.
- Navegue até >de domínio no painel de navegação. Selecione Clusters.
- Selecione
cluster1na tabela de clusters. - Selecione Bloquear & Editar>HTTP. Remova o valor atual para Frontend Host e digite o nome DNS do perfil do Gerenciador de Tráfego que você salvou anteriormente, sem a entrelinha
http://- por exemplo, tmprofile-ejb120623.trafficmanager.net. Selecione Salvar>Ativar alterações.
Repita as mesmas etapas no Console de Administração do WebLogic Server, mas para o cluster secundário na região Oeste dos EUA.
Configurar o repositório de log de transações
Em seguida, configure o JDBC Transaction Log Store para todos os servidores gerenciados de clusters, começando a partir do cluster primário. Essa prática é descrita em Usando arquivos de log de transações para recuperar transações.
Use as seguintes etapas no cluster WLS primário na região Leste dos EUA:
- Verifique se você está conectado ao Console de Administração do WebLogic Server.
- Navegue até >Servers no painel de navegação. Selecione Servidores.
- Você deve ver servidores
msp1,msp2emsp3listados na tabela de servidores. - Selecione
msp1>Serviços>Bloquear & Editar. Em Repositório de Log de Transações, selecione JDBC. - Em Type>Data Source, selecione
jdbc/WebLogicCafeDB. - Confirme se o valor para Nome do prefixo é TLOG_msp1_, que é o valor padrão. Se o valor for diferente, altere-o para TLOG_msp1_.
- Selecione Guardar.
- Selecione
msp2e repita as mesmas etapas, exceto que o valor padrão para Nome do Prefixo é TLOG_msp2_. - Selecione
msp3e repita as mesmas etapas, exceto que o valor padrão para Nome do Prefixo é TLOG_msp3_. - Selecione Ativar alterações.
Repita as mesmas etapas no WebLogic Server Administration Console, mas para o cluster secundário na região Oeste dos EUA.
Reinicie os servidores gerenciados do cluster primário
Em seguida, use as seguintes etapas para reiniciar todos os servidores gerenciados do cluster primário para que as alterações entrem em vigor:
- Verifique se você está conectado ao WebLogic Server Administration Console.
- Navegue até >Servers no painel de navegação. Selecione Servidores.
- Selecione a guia Controle . Selecione
msp1,msp2emsp3. Selecione Desligamento com a opção Quando o trabalho for>concluído Sim. Selecione o ícone de atualização. Aguarde até que o valor Status da Última Ação seja TAREFA CONCLUÍDA. Você deve ver que o valor State para os servidores selecionados é SHUTDOWN. Selecione o ícone de atualização novamente para interromper o monitoramento de status. - Selecione
msp1,msp2emsp3novamente. Selecione Iniciar >Sim. Selecione o ícone de atualização. Aguarde até que o valor Status da Última Ação seja TAREFA CONCLUÍDA. Você deve ver que o valor State para os servidores selecionados é RUNNING. Selecione o ícone de atualização novamente para interromper o monitoramento de status.
Pare as VMs no cluster secundário
Agora, use as seguintes etapas para parar todas as VMs no cluster secundário para torná-lo passivo:
- Abra a página inicial do portal do Azure em uma nova guia do seu navegador e selecione Todos os recursos. Na caixa Filtrar para qualquer campo..., insira o nome do grupo de recursos onde o cluster secundário está implantado - por exemplo, wls-cluster-westus-ejb120623.
- Selecione Tipo é igual a tudo para abrir o filtro Tipo . Em Valor, insira Máquina virtual. Você verá uma entrada correspondida. Selecione-o para Valor. Selecione Aplicar. Você deve ver 4 VMs listadas, incluindo
adminVM,mspVM1,mspVM2emspVM3. - Selecione para abrir cada uma das VMs. Selecione Parar e confirme para cada VM.
- Selecione o ícone de notificações no portal do Azure para abrir o painel Notificações .
- Monitore o evento Parando máquina virtual para cada VM até que o valor se torne Máquina virtual interrompida com êxito. Mantenha a página aberta para que você possa usá-la para o teste de failover mais tarde.
Agora, mude para a guia do navegador onde você monitora o status dos endpoints do Gerenciador de Tráfego. Atualize a página até ver que o ponto de extremidade myFailoverEndpoint está Degradado e o ponto de extremidade myPrimaryEndpoint está Online.
Nota
Uma solução HA/DR pronta para produção provavelmente desejaria obter um RTO mais baixo deixando as VMs em execução, mas apenas interrompendo o software WLS em execução nas VMs. Então, no caso de failover, as VMs já estariam em execução e o software WLS levaria menos tempo para iniciar. Este artigo optou por parar as VMs porque o software implantado pelo Oracle WebLogic Server Cluster em VMs do Azure inicia automaticamente o software WLS quando as VMs são iniciadas.
Verificar o aplicativo
Como o cluster primário está ativo e em execução, ele atua como o cluster ativo e lida com todas as solicitações de usuário roteadas pelo seu perfil do Gerenciador de Tráfego.
Abra o nome DNS do seu perfil do Azure Traffic Manager em uma nova guia do navegador, anexando a raiz de contexto /weblogic-café do aplicativo implantado - por exemplo, http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafe. Crie um novo café com nome e preço - por exemplo, Café 1 com preço 10. Essa entrada é mantida na tabela de dados do aplicativo e na tabela de sessão do banco de dados. A interface do usuário que você vê deve ser semelhante à seguinte captura de tela:

Se a interface do usuário não for semelhante, solucione o problema e resolva o problema antes de continuar.
Mantenha a página aberta para que você possa usá-la para testes de failover mais tarde.
Teste o failover do primário para o secundário
Para testar o failover, faça failover manualmente do servidor de banco de dados primário e do cluster para o servidor de banco de dados secundário e o cluster e, em seguida, faça failover usando o portal do Azure nesta seção.
Failover para o site secundário
Primeiro, use as seguintes etapas para desligar as VMs no cluster primário:
- Encontre o nome do seu grupo de recursos onde o cluster WLS primário é implantado - por exemplo, wls-cluster-eastus-ejb120623. Em seguida, siga as etapas na seção Parar VMs no cluster secundário, mas altere o grupo de recursos de destino para o cluster WLS primário, para parar todas as VMs nesse cluster.
- Mude para o separador do browser do Gestor de Tráfego, atualize a página até ver que o valor do estado do Monitor do ponto de extremidade myPrimaryEndpoint se torna Degradado.
- Alterne para a guia do navegador do aplicativo de exemplo e atualize a página. Você deve ver 504 Gateway Time-out ou 502 Bad Gateway porque nenhum dos pontos de extremidade está acessível.
Em seguida, use as seguintes etapas para fazer failover do Banco de Dados SQL do Azure do servidor primário para o servidor secundário:
- Alterne para a guia do navegador do seu grupo de failover do Banco de Dados SQL do Azure.
- Selecione Failover>Sim.
- Aguarde até que seja concluído.
Em seguida, use as seguintes etapas para iniciar todos os servidores no cluster secundário:
- Alterne para a guia do navegador onde você parou todas as VMs no cluster secundário.
- Selecione a VM
adminVM. Selecione Iniciar. - Monitore o evento Iniciando máquina virtual no
adminVMe aguarde até que o valor se torne Máquina virtual iniciada. - Alterne para a guia do navegador do Console de Administração do WebLogic Server para o cluster secundário e atualize a página até ver a página de boas-vindas para entrar.
- Volte para a guia do navegador onde todas as VMs no cluster secundário estão listadas. Para as VMs
mspVM1,mspVM2emspVM3, selecione cada uma delas para abri-la e, em seguida, selecione Iniciar. - Para as VMs , e , monitore o evento
mspVM2e aguarde até que os valores se tornemmspVM3.
Por fim, use as seguintes etapas para verificar o aplicativo de exemplo depois que o ponto de extremidade myFailoverEndpoint estiver no estado Online:
Mude para o separador do browser do Gestor de Tráfego e, em seguida, atualize a página até ver que o valor de estado do Monitor do ponto de extremidade
myFailoverEndpointentra no estado Online .Alterne para a guia do navegador do aplicativo de exemplo e atualize a página. Você deve ver os mesmos dados persistentes na tabela de dados do aplicativo e na tabela de sessão exibida na interface do usuário, conforme mostrado na captura de tela a seguir:
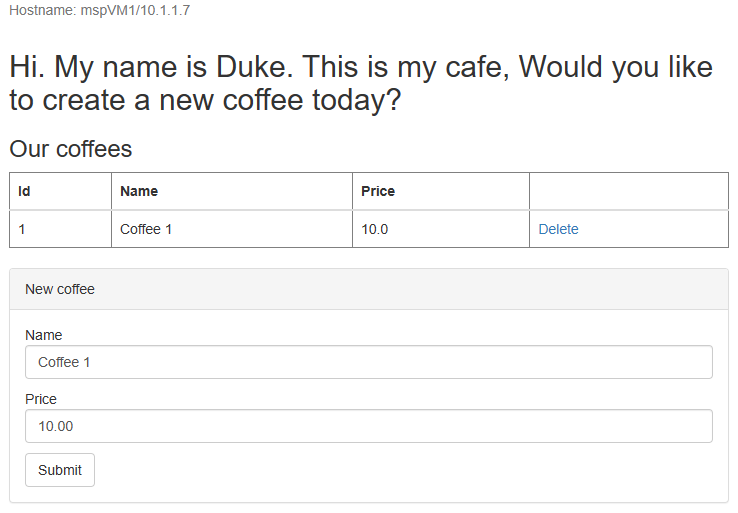
Se você não observar esse comportamento, pode ser porque o Gerenciador de Tráfego está demorando para atualizar o DNS para apontar para o site de failover. O problema também pode ser que seu navegador armazenou em cache o resultado da resolução de nomes DNS que aponta para o site com falha. Aguarde um pouco e atualize a página novamente.
Nota
Uma solução HA/DR pronta para produção seria responsável pela cópia contínua da configuração WLS dos clusters primários para os secundários em um cronograma regular. Para obter informações sobre como fazer isso, consulte as referências à documentação do Oracle no final deste artigo.
Para automatizar o failover, considere o uso de alertas nas métricas do Gerenciador de Tráfego e na Automação do Azure. Para obter mais informações, consulte a seção Alertas sobre métricas do Gerenciador de Tráfego de Métricas e alertas do Gerenciador de Tráfego e Usar um alerta para disparar um runbook de Automação do Azure.
Failback para o site primário
Use as mesmas etapas na seção Failover para o site secundário para fazer failover para o site primário, incluindo servidor de banco de dados e cluster, exceto para as seguintes diferenças:
- Primeiro, desligue as VMs no cluster secundário. Você verá que o ponto de extremidade
myFailoverEndpointse torna Degradado. - Em seguida, faça failover do Banco de Dados SQL do Azure do servidor secundário para o servidor primário.
- Em seguida, inicie todos os servidores no cluster primário.
- Por fim, verifique o aplicativo de exemplo depois que o ponto de extremidade
myPrimaryEndpointestiver Online.
Clean up resources (Limpar recursos)
Se você não vai continuar a usar os clusters WLS e outros componentes, use as seguintes etapas para excluir os grupos de recursos para limpar os recursos usados neste tutorial:
- Insira o nome do grupo de recursos dos servidores do Banco de Dados SQL do Azure (por exemplo,
myResourceGroup) na caixa de pesquisa na parte superior do portal do Azure e selecione o grupo de recursos correspondente nos resultados da pesquisa. - Selecione Eliminar grupo de recursos.
- Em Digite o nome do grupo de recursos para confirmar a exclusão, digite o nome do grupo de recursos.
- Selecione Eliminar.
- Repita as etapas 1 a 4 para o grupo de recursos do Gerenciador de Tráfego - por exemplo,
myResourceGroupTM1. - Repita as etapas 1 a 4 para o grupo de recursos do cluster WLS primário - por exemplo,
wls-cluster-eastus-ejb120623. - Repita as etapas 1 a 4 para o grupo de recursos do cluster WLS secundário - por exemplo,
wls-cluster-westus-ejb120623.
Próximos passos
Neste tutorial, você configura uma solução HA/DR que consiste em uma camada de infraestrutura de aplicativo ativo-passivo com uma camada de banco de dados ativo-passivo e na qual ambas as camadas abrangem dois sites geograficamente diferentes. No primeiro site, a camada de infraestrutura de aplicativo e a camada de banco de dados estão ativas. No segundo site, o domínio secundário é desligado e o banco de dados secundário está em espera.
Continue a explorar as seguintes referências para obter mais opções para criar soluções HA/DR e executar WLS no Azure: