Julho de 2018
Esses recursos e aprimoramentos da plataforma Azure Databricks foram lançados em julho de 2018.
A API de bibliotecas suporta arquivos de roda Python
31 de julho a 7 de agosto de 2018: Versão 2.77
Agora você pode instalar bibliotecas de rodas usando a API de bibliotecas. Quando você instala uma biblioteca de rodas em um cluster que executa o Databricks Runtime 4.2 ou superior, todas as dependências especificadas no arquivo de biblioteca setup.py são incluídas. Quando você instala uma biblioteca de rodas em um cluster que executa o PYTHONPATH Databricks Runtime 4.1 ou inferior, o arquivo é adicionado à variável, sem instalar as dependências.
Exportação de blocos de Notas de Python
31 de julho a 7 de agosto de 2018: Versão 2.77
Quando você exporta um bloco de anotações do Azure Databricks para o formato de bloco de anotações IPython, os resultados agora são incluídos na exportação.
Âmbitos de segredos apoiados pelo Azure Key Vault
19 a 24 de julho de 2018: Versão 2.76
Os segredos agora dão suporte a escopos apoiados por um Cofre de Chaves do Azure. Depois de criar o escopo, você pode acessar todos os segredos no Cofre da Chave correspondente a partir desse escopo. Para obter detalhes, consulte Gerenciar escopos secretos.
Nota
O escopo secreto apoiado pelo Cofre de Chaves do Azure é uma interface somente leitura para o Cofre de Chaves. Para gerenciar segredos no Cofre da Chave do Azure, você deve usar a API REST do Azure Definir Segredo ou a interface do usuário do portal do Azure.
Áreas de trabalho Premium de Avaliação
20 a 24 de julho de 2018: Versão 2.76
O Azure Databricks agora oferece espaços de trabalho Premium de avaliação. Durante uma avaliação de 14 dias, você tem acesso a DBUs gratuitos do Azure Databricks. Para obter mais informações, consulte Criar um espaço de trabalho.
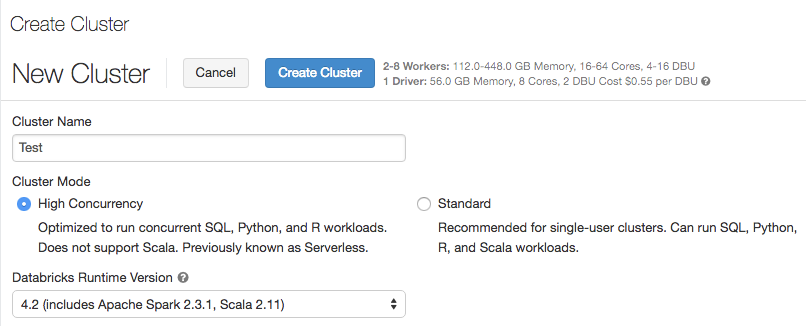
Modo de cluster e clusters de alta simultaneidade
19 a 24 de julho de 2018: Versão 2.76
Ao criar um cluster, a opção Tipo de Cluster foi renomeada para Modo de Cluster. A opção Pool sem servidor foi substituída pelo modo de cluster de alta simultaneidade . Os clusters de alta simultaneidade são ajustados para fornecer utilização eficiente de recursos, isolamento, segurança e o melhor desempenho quando compartilhados por vários usuários ativos simultaneamente. Um cluster High Concurrency suporta apenas as linguagens SQL, Python e R. Os clusters de alta simultaneidade fornecem todos os benefícios dos pools sem servidor, ao mesmo tempo em que permitem flexibilidade no Spark e na configuração de recursos. Para obter mais informações, consulte Clusters de alta simultaneidade.
Controlo de acesso a tabelas
19 a 24 de julho de 2018: Versão 2.76
A caixa de seleção Controle de Acesso à Tabela está disponível apenas para clusters de Alta Simultaneidade.

Os tipos de nós de clusters não disponíveis aparecem a cinzento
3 a 10 de julho de 2018: Versão 2.75
Os tipos de nó de cluster que não estão disponíveis para sua assinatura e região agora estão acinzentados e você não pode selecioná-los ao criar um cluster.
Suporte para R Markdown
3 a 10 de julho de 2018: Versão 2.75
Os blocos de anotações do Azure Databricks R podem ser exportados para o formato R Markdown e os documentos R Markdown podem ser importados como blocos de anotações do Azure Databricks.
Novo design da home page, com a possibilidade de largar ficheiros para importar dados
3 a 10 de julho de 2018: Versão 2.75
A nova página inicial adiciona uma interface mais limpa e simples, com links para um tutorial de Introdução aprimorado e a capacidade de arrastar e soltar arquivos para importar dados. Consulte Explorar e criar tabelas no DBFS.
Comportamento predefinido dos widgets
3 a 10 de julho de 2018: Versão 2.75
O comportamento de execução padrão quando um novo valor é selecionado para um widget agora é Não fazer nada. Você deve atualizar as configurações do widget se quiser executar novamente um bloco de anotações completo ou apenas comandos relacionados a valores quando alterar um valor de widget. Consulte Definir configurações do widget.
Interface de criação de tabela
3 a 10 de julho de 2018: Versão 2.75
Ao criar uma tabela na interface do usuário, você seleciona Adicionar dados na página Dados.
![]()
Consulte Explorar e criar tabelas no DBFS.
Importação de dados JSON multilinhas
3 a 10 de julho de 2018: Versão 2.75
Agora você pode importar arquivos de dados JSON de várias linhas ao criar tabelas. Anteriormente, os arquivos de dados JSON tinham que ser nivelados em uma linha. Consulte Explorar e criar tabelas no DBFS.