Configurar computação (legado)
Nota
Estas são instruções para a interface do usuário de cluster de criação herdada e são incluídas apenas para precisão histórica. Todos os clientes devem estar usando a interface do usuário de criação de cluster atualizada.
Este artigo explica as opções de configuração disponíveis quando você cria e edita clusters do Azure Databricks. Ele se concentra na criação e edição de clusters usando a interface do usuário. Para outros métodos, consulte a CLI do Databricks, a API de Clusters e o provedor Databricks Terraform.
Para obter ajuda para decidir qual combinação de opções de configuração atende melhor às suas necessidades, consulte Práticas recomendadas de configuração de cluster.
Política de Clusters
Uma política de cluster limita a capacidade de configurar clusters com base num conjunto de regras. As regras de política limitam os atributos ou valores de atributos disponíveis para a criação de clusters. As políticas de cluster têm ACLs que limitam seu uso a usuários e grupos específicos e, portanto, limitam quais políticas você pode selecionar ao criar um cluster.
Para configurar uma política de cluster, selecione a política de cluster na lista suspensa de Política .
Nota
Se nenhuma política tiver sido criada no espaço de trabalho, a lista suspensa Política não será exibida.
Se tiver:
- Cluster criar permissão, você pode selecionar a política irrestrito e criar clusters totalmente configuráveis. A política Irrestrito não limita nenhum atributo de cluster ou valor de atributo.
- Ambos os clusters criam permissão e acesso a políticas de cluster, você pode selecionar a Política de irrestrita e as políticas às quais você tem acesso.
- Acesso apenas às políticas de cluster; pode selecionar as políticas às quais tem acesso.
Modo de clusters
Nota
Este artigo descreve a interface do usuário de clusters herdados. Para obter informações sobre a nova interface do usuário de clusters (em visualização), consulte Referência de configuração de computação. Isso inclui algumas alterações de terminologia para tipos e modos de acesso ao cluster. Para obter uma comparação dos tipos de cluster novos e herdados, consulte Alterações da interface do usuário de clusters e modos de acesso ao cluster. Na interface do usuário de visualização:
- Os clusters de modo padrão agora são chamados de clusters de modo de acesso compartilhado Sem Isolamento.
- Alta simultaneidade com ACLs de tabelas agora são chamadas de clusters de modo de acesso compartilhado .
O Azure Databricks dá suporte a três modos de cluster: Padrão, Alta Simultaneidade e Nó Único. O modo de cluster padrão é Padrão.
Importante
- Se seu espaço de trabalho estiver atribuído a um Unity Catalog metastore, os clusters de alta simultaneidade não estarão disponíveis. Em vez disso, você usa o modo de acesso para garantir a integridade dos controles de acesso e impor fortes garantias de isolamento. Consulte também Modos de acesso.
- Não é possível alterar o modo de cluster após a criação de um cluster. Se desejar um modo de cluster diferente, você deve criar um novo cluster.
A configuração do cluster inclui uma configuração de terminação automática cujo valor padrão depende do modo de cluster:
- Os clusters Standard e Single Node terminam automaticamente após 120 minutos por padrão.
- Os clusters de alta simultaneidade não são encerrados automaticamente por padrão.
Clusters padrão
Aviso
Os clusters de modo padrão (às vezes chamados de clusters compartilhados sem isolamento) podem ser compartilhados por vários usuários, sem isolamento entre os usuários. Se você usar o modo de cluster de alta simultaneidade sem configurações de segurança adicionais, como ACLs de tabela oude passagem de credenciais, as mesmas configurações serão usadas como clusters de modo padrão. Os administradores de conta podem impedir que credenciais internas sejam geradas automaticamente para administradores do espaço de trabalho Databricks nestes tipos de clusters. Para opções mais seguras, o Databricks recomenda alternativas como clusters de alta simultaneidade com ACLs de tabela.
Um cluster padrão é recomendado apenas para usuários individuais. Clusters padrão podem executar cargas de trabalho desenvolvidas em Python, SQL, R e Scala.
Clusters de alta simultaneidade
Um cluster de alta simultaneidade é um recurso de nuvem gerenciado. Os principais benefícios dos clusters de alta simultaneidade são que eles fornecem compartilhamento refinado para utilização máxima de recursos e latências mínimas de consulta.
Clusters de alta simultaneidade podem executar cargas de trabalho desenvolvidas em SQL, Python e R. O desempenho e a segurança dos clusters de alta simultaneidade são fornecidos pela execução do código do usuário em processos separados, o que não é possível no Scala.
Além disso, apenas clusters de alta simultaneidade suportam controle de acesso à tabela.
Para criar um cluster em Modo de Cluster de Alta Simultaneidade, defina para .
Clusters de nó único
Um cluster de nó único não tem trabalhadores e executa trabalhos do Spark no nó do driver.
Por outro lado, um cluster Standard requer pelo menos um nó de trabalho do Spark, além do nó do driver, para executar trabalhos do Spark.
Para criar um cluster de Nó Único, defina Modo de Cluster como de Nó Único.
Para saber mais sobre como trabalhar com clusters de nó único, consulte Computação de nó único ou de vários nós.
Piscinas
Para reduzir o tempo de início do cluster, você pode anexar um cluster a um pool predefinido de instâncias ociosas para os nós de driver e de trabalho. O cluster é criado usando instâncias nos pools. Se um pool não tiver recursos ociosos suficientes para criar o driver ou os nós de trabalho solicitados, o pool será expandido alocando novas instâncias do provedor de instância. Quando um cluster anexado é encerrado, as instâncias usadas são retornadas aos pools e podem ser reutilizadas por um cluster diferente.
Se selecionar um pool para os nodos de trabalho, mas não para o nodo de controlador, o nodo de controlador herdará o pool da configuração do nodo de trabalho.
Importante
Se você tentar selecionar um pool para o nó do driver, mas não para os nós de trabalho, ocorrerá um erro e o cluster não será criado. Este requisito evita uma situação em que o nó principal tenha que aguardar a criação de nós trabalhadores ou vice-versa.
Consulte Referência de configuração de pool para saber mais sobre como trabalhar com pools no Azure Databricks.
Tempo de execução do Databricks
Os tempos de execução do Databricks são o conjunto de componentes principais que são executados em seus clusters . Todos os tempos de execução do Databricks incluem o Apache Spark e adicionam componentes e atualizações que melhoram a usabilidade, o desempenho e a segurança. Para obter detalhes, consulte Versões e compatibilidade das notas de versão do Databricks Runtime.
O Azure Databricks oferece vários tipos de tempos de execução e várias versões desses tipos de tempo de execução no menu suspenso Versão de Tempo de Execução do Databricks quando você cria ou edita um cluster.
Aceleração de fótons
O Photon está disponível para clusters que executam o Databricks Runtime 9.1 LTS e superior.
Para ativar a aceleração de fótons, marque a caixa de seleção Usar Aceleração de Fótons.
Se desejar, você pode especificar o tipo de instância na lista suspensa Tipo de trabalhador e Tipo de driver.
O Databricks recomenda os seguintes tipos de instância para um preço e desempenho ideais:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
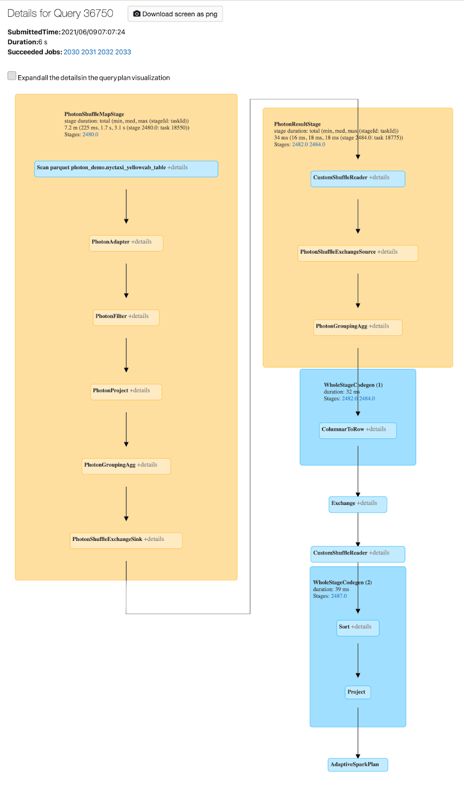
Você pode visualizar a atividade do Photon na interface do usuário do Spark. A captura de tela a seguir mostra os detalhes da consulta DAG. Há duas indicações de Fóton no DAG. Primeiro, os operadores de fótons começam com "Photon", por exemplo, PhotonGroupingAgg. Em segundo lugar, no DAG, os operadores e estágios de fótons são pêssegos coloridos, enquanto os não-fótons são azuis.
Imagens do Docker
Para algumas versões do Databricks Runtime, você pode especificar uma imagem do Docker ao criar um cluster. Exemplos de casos de uso incluem personalização de biblioteca, um ambiente de contêiner dourado que não muda e integração de CI/CD do Docker.
Você também pode usar imagens do Docker para criar ambientes personalizados de aprendizado profundo em clusters com dispositivos GPU.
Para obter instruções, consulte Personalizar contêineres com o Databricks Container Service e Databricks Container Services na computação GPU.
Tipo de nó de cluster
Um cluster consiste em um nó de driver e zero ou mais nós de trabalho.
Você pode escolher tipos de instância de provedor de nuvem separados para os nós de driver e de trabalho, embora, por padrão, o nó de driver use o mesmo tipo de instância que o nó de trabalho. Diferentes famílias de tipos de instância se ajustam a diferentes casos de uso, como cargas de trabalho com uso intensivo de memória ou computação.
Nota
Se seus requisitos de segurança incluírem isolamento de computação, selecione uma instância Standard_F72s_V2 como seu tipo de trabalhador. Esses tipos de instância representam máquinas virtuais isoladas que consomem todo o host físico e fornecem o nível necessário de isolamento necessário para suportar, por exemplo, cargas de trabalho IL5 (US Department of Defense Impact Level 5).
Nó do controlador
O nó de controlador mantém informações de estado de todos os blocos de notas anexados ao cluster. O nó de controlador também mantém o SparkContext e interpreta todos os comandos que forem executados a partir de um bloco de notas ou de uma biblioteca no cluster e executa o nó principal do Apache Spark que faz a coordenação com os executores do Spark.
O valor predefinido do tipo de nó de controlador é o mesmo que o tipo de nó de trabalho. Você pode escolher um tipo de nó de driver maior com mais memória se estiver planejando collect() muitos dados dos trabalhadores do Spark e analisá-los no notebook.
Gorjeta
Como o nó do driver mantém todas as informações de estado dos blocos de anotações conectados, certifique-se de desanexar os blocos de anotações não utilizados do nó do driver.
Nó de trabalho
Os nós de trabalho do Azure Databricks executam os executores do Spark e os outros serviços necessários para o correto funcionamento dos clusters. Quando distribui a sua carga de trabalho com o Spark, todo o processamento distribuído acontece nos nós de trabalho. O Azure Databricks executa um executor por nó de trabalho; portanto, os termos executor e worker são usados de forma intercambiável no contexto da arquitetura do Azure Databricks.
Gorjeta
Para executar um trabalho do Spark, você precisa de pelo menos um nó de trabalho. Se um cluster tiver zero funções de trabalho, poderá executar comandos que não sejam do Apache Spark no nó do controlador, mas os comandos do Apache Spark falharão.
Tipos de instância de GPU
Para tarefas computacionalmente desafiadoras que exigem alto desempenho, como aquelas associadas ao aprendizado profundo, o Azure Databricks dá suporte a clusters acelerados com unidades de processamento gráfico (GPUs). Para obter mais informações, consulte Computação habilitada para GPU.
Instâncias spot
Para economizar custos, você pode optar por usar instâncias spot, também conhecidas como VMs spot do Azure, marcando a caixa de seleção instâncias spot .

A primeira instância será sempre sob demanda (o nó do driver está sempre sob demanda) e as instâncias subsequentes serão instâncias spot. Se as instâncias spot forem removidas devido à indisponibilidade, as instâncias sob demanda serão implantadas para substituir as instâncias removidas.
Tamanho do cluster e dimensionamento automático
Ao criar um cluster do Azure Databricks, você pode fornecer um número fixo de trabalhadores para o cluster ou fornecer um número mínimo e máximo de trabalhadores para o cluster.
Quando você fornece um cluster de tamanho fixo, o Azure Databricks garante que seu cluster tenha o número especificado de trabalhadores. Quando você fornece um intervalo para o número de trabalhadores, o Databricks escolhe o número apropriado de trabalhadores necessários para executar seu trabalho. Isso é conhecido como dimensionamento automático.
Com o dimensionamento automático, o Azure Databricks realoca dinamicamente os trabalhadores para levar em conta as características do seu trabalho. Certas partes do seu pipeline podem ser mais exigentes computacionalmente do que outras, e o Databricks adiciona automaticamente trabalhadores adicionais durante essas fases do seu trabalho (e os remove quando não são mais necessários).
O dimensionamento automático facilita a utilização elevada de clusters, uma vez que não precisa de aprovisionar o cluster para corresponder a uma carga de trabalho. Isso se aplica especialmente a cargas de trabalho cujos requisitos mudam ao longo do tempo (como explorar um conjunto de dados durante um dia), mas também pode se aplicar a uma carga de trabalho única mais curta cujos requisitos de provisionamento são desconhecidos. O dimensionamento automático oferece, assim, duas vantagens:
- As cargas de trabalho podem ser executadas mais rapidamente em comparação com um cluster subprovisionado de tamanho constante.
- O dimensionamento automático de clusters pode reduzir os custos gerais em comparação com um cluster de tamanho estático.
Dependendo do tamanho constante do cluster e da carga de trabalho, o dimensionamento automático oferece um ou ambos os benefícios ao mesmo tempo. O tamanho do cluster pode ficar abaixo do número mínimo de trabalhadores selecionados quando o provedor de nuvem encerra instâncias. Nesse caso, o Azure Databricks tenta continuamente reprovisionar instâncias para manter o número mínimo de trabalhadores.
Nota
O dimensionamento automático não está disponível para trabalhos spark-submit.
How autoscaling behaves (Como se comporta o dimensionamento automático)
- Aumenta de min a max em 2 passos.
- Pode reduzir mesmo se o cluster não estiver ocioso observando o estado do arquivo aleatório.
- Reduz a escala com base em uma porcentagem dos nós atuais.
- Em clusters de trabalho, diminui se o cluster estiver subutilizado nos últimos 40 segundos.
- Em clusters multiuso, reduz se o cluster estiver subutilizado nos últimos 150 segundos.
- A
spark.databricks.aggressiveWindowDownSpropriedade de configuração do Spark especifica em segundos a frequência com que um cluster toma decisões de redução de escala. Aumentar o valor faz com que um cluster diminua mais lentamente. O valor máximo é 600.
Enable and configure autoscaling (Ativar e configurar o dimensionamento automático)
Para permitir que o Azure Databricks redimensione seu cluster automaticamente, habilite o dimensionamento automático para o cluster e forneça o intervalo mínimo e máximo de trabalhadores.
Ative o dimensionamento automático.
All-Purpose cluster - Na página Criar Cluster, selecione a caixa de seleção Ativar autoscaling na caixa de Opções do Autopilot:

Cluster de tarefas - Na página Configurar Cluster, marque a caixa de seleção Ativar o dimensionamento automático na caixa Opções do piloto automático:

Configure os trabalhadores min e max.

Quando o cluster está em execução, a página de detalhes do cluster exibe o número de trabalhadores alocados. Você pode comparar o número de trabalhadores alocados com a configuração de trabalho e fazer ajustes conforme necessário.
Importante
Se você estiver usando um pool de instâncias:
- Verifique se o tamanho do cluster solicitado é menor ou igual ao número mínimo de instâncias ociosas no pool. Se for maior, o tempo de arranque do cluster será equivalente a um cluster que não utiliza um conjunto.
- Verifique se o tamanho máximo do cluster é menor ou igual à capacidade máxima do pool. Se for maior, a criação do cluster falhará.
Exemplo de dimensionamento automático
Se você reconfigurar um cluster estático para ser um cluster de dimensionamento automático, o Azure Databricks redimensionará imediatamente o cluster dentro dos limites mínimo e máximo e, em seguida, iniciará o dimensionamento automático. Como exemplo, a tabela a seguir demonstra o que acontece com clusters com um determinado tamanho inicial se você reconfigurar um cluster para dimensionar automaticamente entre 5 e 10 nós.
| Tamanho inicial | Tamanho após reconfiguração |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Dimensionamento automático do armazenamento local
Muitas vezes, pode ser difícil estimar quanto espaço em disco um determinado trabalho ocupará. Para evitar que você precise estimar quantos gigabytes de disco gerenciado anexar ao cluster no momento da criação, o Azure Databricks habilita automaticamente o dimensionamento automático do armazenamento local em todos os clusters do Azure Databricks.
Com o dimensionamento automático do armazenamento local, o Azure Databricks monitora a quantidade de espaço livre em disco disponível nos trabalhadores do Spark do cluster. Se um trabalhador começar a ficar muito baixo no disco, o Databricks anexará automaticamente um novo disco gerenciado ao trabalhador antes que ele fique sem espaço em disco. Os discos são conectados até um limite de 5 TB de espaço total em disco por máquina virtual (incluindo o armazenamento local inicial da máquina virtual).
Os discos gerenciados anexados a uma máquina virtual são desanexados somente quando a máquina virtual é retornada ao Azure. Ou seja, os discos gerenciados nunca são desanexados de uma máquina virtual, desde que ela faça parte de um cluster em execução. Para reduzir o uso do disco gerenciado, o Azure Databricks recomenda usar esse recurso em um cluster configurado com tamanho e dimensionamento automático do cluster ou Encerramento inesperado.
Encriptação de disco local
Importante
Esta funcionalidade está em Pré-visualização Pública.
Alguns tipos de instância usados para executar clusters podem ter discos conectados localmente. O Azure Databricks pode armazenar dados aleatórios ou dados efêmeros nesses discos anexados localmente. Para garantir que todos os dados em repouso sejam criptografados para todos os tipos de armazenamento, incluindo dados aleatórios armazenados temporariamente nos discos locais do cluster, você pode habilitar a criptografia de disco local.
Importante
Suas cargas de trabalho podem ser executadas mais lentamente devido ao impacto no desempenho da leitura e gravação de dados criptografados de e para volumes locais.
Quando a criptografia de disco local está habilitada, o Azure Databricks gera uma chave de criptografia localmente que é exclusiva para cada nó de cluster e é usada para criptografar todos os dados armazenados em discos locais. O escopo da chave é local para cada nó de cluster e é destruído junto com o próprio nó de cluster. Durante o seu tempo de vida, a chave reside na memória para encriptação e desencriptação e é armazenada encriptada no disco.
Para habilitar a criptografia de disco local, você deve usar a API de Clusters. Durante a criação ou edição do cluster, defina:
{
"enable_local_disk_encryption": true
}
Consulte a API de Clusters para obter exemplos de como invocar essas APIs.
Aqui está um exemplo de uma chamada de criação de cluster que permite a criptografia de disco local:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Modo de segurança
Se o espaço de trabalho estiver atribuído a um metastore do Unity Catalog
Em Opções avançadas, selecione entre os seguintes modos de segurança de cluster:
- Nenhum: Sem isolamento. Não impõe o controlo de acesso às tabelas locais do espaço de trabalho nem a passagem de credenciais. Não é possível acessar os dados do Catálogo Unity.
- Usuário único: pode ser usado apenas por um único usuário (por padrão, o usuário que criou o cluster). Outros usuários não podem se conectar ao cluster. Ao acessar um modo de exibição de um cluster com modo de segurança de Usuário Único, o modo de exibição é executado com as permissões do usuário. Clusters de usuário único suportam cargas de trabalho usando Python, Scala e R. Scripts de inicialização, instalação de biblioteca e montagens DBFS são suportados em clusters de usuário único. Os trabalhos automatizados devem usar clusters de usuário único.
- Isolamento do usuário: pode ser compartilhado por vários usuários. Somente cargas de trabalho SQL são suportadas. A instalação da biblioteca, os scripts init e as montagens DBFS são desabilitados para impor um isolamento estrito entre os usuários do cluster.
- Somente ACL de tabela (Legado): Impõe o controle de acesso à tabela do espaço de trabalho, mas não pode acessar os dados do Unity Catalog.
- Somente passagem (Legado): Impõe a passagem de credenciais locais do espaço de trabalho, mas não pode acessar os dados do Catálogo Unity.
Os únicos modos de segurança suportados para cargas de trabalho do Unity Catalog são os de Usuário Único e de Isolamento de Usuário .
Para obter mais informações, consulte Modos de acesso.
Configuração do Spark
Para ajustar os trabalhos do Spark, você pode fornecer propriedades de configuração personalizadas do Spark em uma configuração de cluster.
Na página de configuração do cluster, clique no botão Opções Avançadas.
Clique na guia Faísca .
Em Configuração do Spark, insira as propriedades de configuração como um par chave-valor por linha.
Quando você configura um cluster usando o
O Databricks não recomenda o uso de scripts de inicialização global.
Para definir as propriedades do Spark para todos os clusters, crie um script de inicialização global :
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Recuperar uma propriedade de configuração do Spark de um segredo
O Databricks recomenda armazenar informações confidenciais, como senhas, em segredo em vez de texto sem formatação. Para fazer referência a um segredo na configuração do Spark, use a seguinte sintaxe:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Por exemplo, para definir uma propriedade de configuração do Spark chamada password para o valor do segredo armazenado em secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Para obter mais informações, consulte Gerenciar segredos.
Variáveis de ambiente
Você pode configurar variáveis de ambiente personalizadas que podem ser acessadas a partir de scripts init em execução em um cluster. O Databricks também fornece variáveis de ambiente predefinidas que você pode usar em scripts init. Não é possível substituir essas variáveis de ambiente predefinidas.
Na página de configuração do cluster, clique no botão Opções Avançadas.
Clique na guia Faísca .
Defina as variáveis de ambiente no campo
Variáveis de Ambiente. 
Você também pode definir variáveis de ambiente usando o campo spark_env_vars no Criar nova API de cluster ou Atualizar API de configuração de cluster.
Tags de cluster
As tags de cluster permitem que você monitore facilmente o custo dos recursos de nuvem usados por vários grupos em sua organização. Você pode especificar tags como pares chave-valor ao criar um cluster, e o Azure Databricks aplica essas tags a recursos de nuvem, como VMs e volumes de disco, bem como relatórios de uso de DBU.
Para clusters iniciados a partir de pools, as tags de cluster personalizadas são aplicadas apenas a relatórios de uso de DBU e não se propagam para recursos de nuvem.
Para obter informações detalhadas sobre como os tipos de tag pool e cluster funcionam juntos, consulte Uso de atributos usando tags.
Por conveniência, o Azure Databricks aplica quatro marcas padrão a cada cluster: Vendor, Creator, ClusterNamee ClusterId.
Além disso, em clusters de trabalho, o Azure Databricks aplica duas tags padrão: RunName e JobId.
Nos recursos usados pelo Databricks SQL, o Azure Databricks também aplica a marca SqlWarehouseIdpadrão .
Aviso
Não atribua uma tag personalizada com a chave Name a um cluster. Cada cluster tem uma etiqueta Name cujo valor é definido pelo Azure Databricks. Se você alterar o valor associado à chave Name, o cluster não poderá mais ser rastreado pelo Azure Databricks. Como consequência, o cluster pode não ser encerrado depois de ficar ocioso e continuará a incorrer em custos de uso.
Você pode adicionar tags personalizadas ao criar um cluster. Para configurar marcas de cluster:
Na página de configuração do cluster, clique no botão Opções Avançadas.
Na parte inferior da página, clique no separador Etiquetas .

Adicione um par chave-valor para cada tag personalizada. Você pode adicionar até 43 tags personalizadas.
Acesso SSH a clusters
Por motivos de segurança, no Azure Databricks a porta SSH é fechada por padrão. Se você quiser habilitar o acesso SSH aos seus clusters do Spark, entre em contato com o suporte do Azure Databricks.
Nota
O SSH só pode ser habilitado se seu espaço de trabalho for implantado em sua própria rede virtual do Azure.
Entrega de registos de clusters
Quando criar um cluster, pode especificar um local para entregar os registos para o nó do controlador, os nós de trabalho e os eventos do Apache Spark. Os registos são entregues a cada cinco minutos no destino escolhido. Quando um cluster é encerrado, o Azure Databricks garante entregar todos os logs gerados até que o cluster seja encerrado.
O destino dos logs depende da ID do cluster. Se o destino especificado for dbfs:/cluster-log-delivery, os logs de cluster para 0630-191345-leap375 serão entregues ao dbfs:/cluster-log-delivery/0630-191345-leap375.
Para configurar o local de entrega do log:
Na página de configuração do cluster, clique no botão Opções Avançadas.
Clique na guia Log .
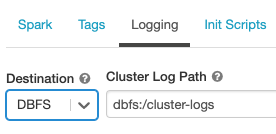
Selecione um tipo de destino.
Insira o caminho do log do cluster.
Nota
Esse recurso também está disponível na API REST. Consulte a API de Clusters.
Scripts init
Um script de inicialização de nó de cluster — ou init — é um script de shell que é executado durante a inicialização de cada nó de cluster antes que o driver do Spark ou a JVM de trabalho seja iniciado. Você pode usar scripts init para instalar pacotes e bibliotecas não incluídos no tempo de execução do Databricks, modificar o classpath do sistema JVM, definir propriedades do sistema e variáveis de ambiente usadas pela JVM ou modificar parâmetros de configuração do Spark, entre outras tarefas de configuração.
Você pode anexar scripts de inicialização a um cluster expandindo a seção Opções Avançadas e clicando na guia Scripts de inicialização .
Para obter instruções detalhadas, consulte O que são scripts init?.