Preparar dados para o ajuste fino do modelo básico
Importante
Este recurso está na visualização pública nas seguintes regiões: centralus, eastus, eastus2, northcentraluse westus.
Este artigo descreve os formatos de arquivo de dados de treinamento e avaliação aceitos para o ajuste fino do Modelo de Base (agora parte do Treinamento do Modelo de IA do Mosaic).
Notebook: Validação de dados para treinamentos
O bloco de notas seguinte mostra como validar os seus dados. Ele é projetado para funcionar de forma independente antes de começar a treinar. Ele valida se seus dados estão no formato correto para o ajuste fino do modelo básico e inclui código para ajudá-lo a estimar os custos durante a execução do treinamento, tokenizando seu conjunto de dados bruto.
Validar dados para o bloco de notas de execução de treino
Preparar dados para a conclusão do chat
Para tarefas de conclusão de chat, os dados formatados em chat devem estar em um arquivo .jsonl, onde cada linha é um objeto JSON separado representando uma única sessão de chat. Cada sessão de chat é representada como um objeto JSON com uma única chave, messages, que mapeia para uma matriz de objetos de mensagem. Para treinar com dados de chat, forneça o task_type = 'CHAT_COMPLETION' quando você criar a sua sessão de treino.
As mensagens em formato de chat são formatadas automaticamente de acordo com o modelo de chat do modelo, portanto, não há necessidade de adicionar tokens de chat especiais para sinalizar manualmente o início ou o fim de um turno de bate-papo. Um exemplo de um modelo que usa um modelo de chat personalizado é Meta Llama 3.1 8B Instruct.
Cada objeto de mensagem na matriz representa uma única mensagem na conversa e tem a seguinte estrutura:
-
role: Uma cadeia de caracteres que indica o autor da mensagem. Os valores possíveis sãosystem,usereassistant. Se a função forsystem, deve ser o primeiro bate-papo na lista de mensagens. Deve haver pelo menos uma mensagem com a funçãoassistant, e todas as mensagens após o prompt do sistema (opcional) devem alternar funções entre usuário/assistente. Não deve haver duas mensagens adjacentes com a mesma função. A última mensagem na matrizmessagesdeve ter a funçãoassistant. -
content: Uma cadeia de caracteres que contém o texto da mensagem.
Nota
Os modelos Mistral não aceitam system funções em seus formatos de dados.
Segue-se um exemplo de dados formatados em chat:
{"messages": [
{"role": "system", "content": "A conversation between a user and a helpful assistant."},
{"role": "user", "content": "Hi there. What's the capital of the moon?"},
{"role": "assistant", "content": "This question doesn't make sense as nobody currently lives on the moon, meaning it would have no government or political institutions. Furthermore, international treaties prohibit any nation from asserting sovereignty over the moon and other celestial bodies."},
]
}
Preparar dados para pré-formação contínua
Para tarefas contínuas de pré-treinamento , os dados de treinamento são seus dados de texto não estruturados. Os dados de treinamento devem estar em um volume do Catálogo Unity contendo arquivos .txt. Cada arquivo .txt é tratado como uma única amostra. Se seus arquivos .txt estiverem em uma pasta de volume do Catálogo Unity, esses arquivos também serão obtidos para seus dados de treinamento. Todos os arquivos não-txt no volume são ignorados. Consulte Carregar arquivos para um volume do Catálogo Unity.
A imagem a seguir mostra exemplos de arquivos .txt em um volume do Catálogo Unity. Para usar estes dados na sua configuração de execução contínua de pré-treinamento, defina train_data_path = "dbfs:/Volumes/main/finetuning/cpt-data" e task_type = 'CONTINUED_PRETRAIN'.
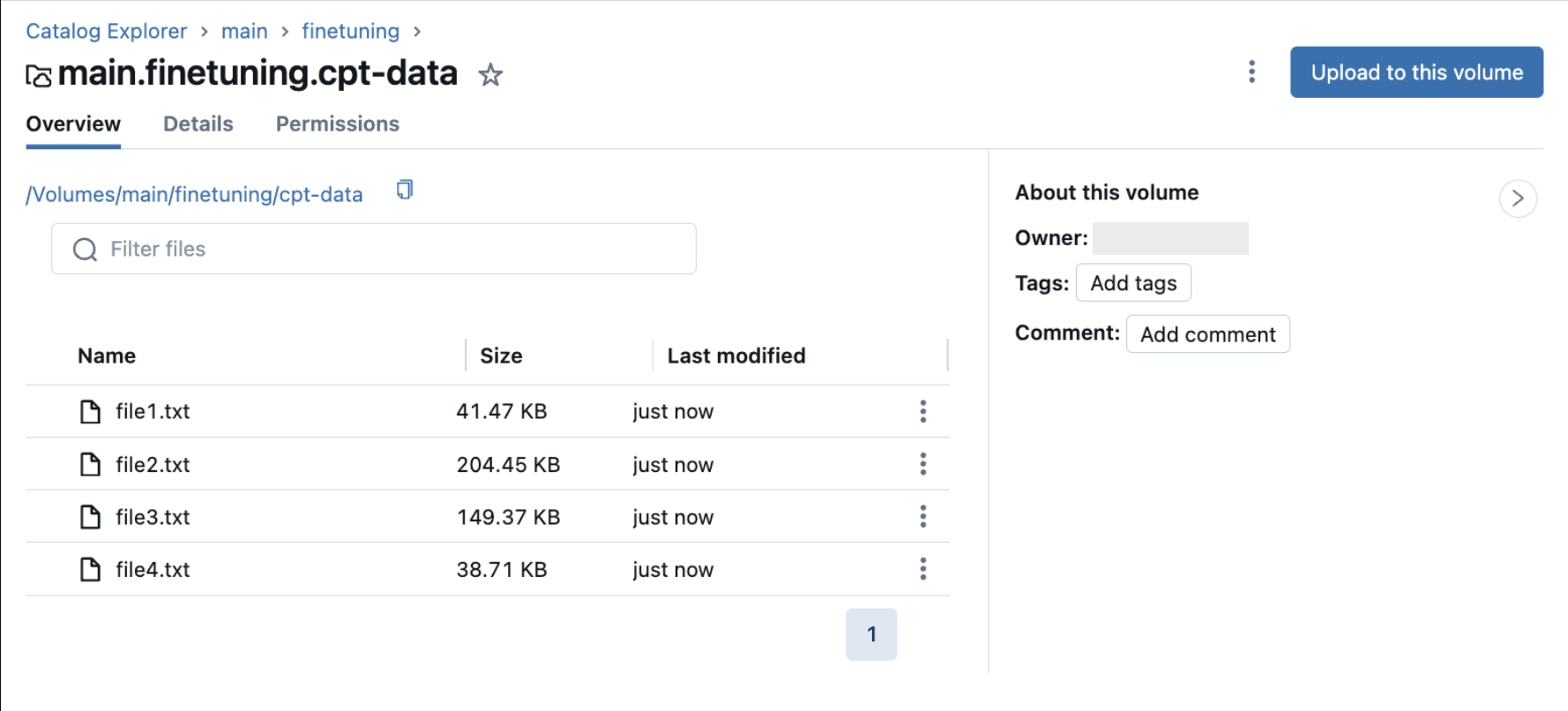
Formate os dados você mesmo
Advertência
As orientações nesta seção não são recomendadas, mas estão disponíveis para cenários em que a formatação de dados personalizados é necessária.
O Databricks recomenda vivamente a utilização de dados formatados para chat para que a formatação adequada seja aplicada automaticamente aos seus dados com base no modelo que está a utilizar.
O ajuste fino do modelo de base permite que você faça a formatação de dados por conta própria. Qualquer formatação de dados deve ser aplicada ao treinar e servir seu modelo. Para treinar seu modelo usando seus dados formatados, defina task_type = 'INSTRUCTION_FINETUNE' quando você criar sua corrida de treinamento.
Os dados de treinamento e avaliação devem estar em um dos seguintes esquemas:
Pares de prompt e resposta.
{"prompt": "your-custom-prompt", "response": "your-custom-response"}Pares de pronto e conclusão.
{"prompt": "your-custom-prompt", "completion": "your-custom-response"}
Importante
Prompt-response e prompt-completion não são modelados, portanto, qualquer modelo específico do modelo, como a formatação de instruções do Mistral, deve ser executado como uma etapa de pré-processamento.
Formatos de dados suportados
Os seguintes são os formatos de dados suportados:
Um volume de catálogo Unity com um
.jsonlarquivo. Os dados de treinamento devem estar no formato JSONL, onde cada linha é um objeto JSON válido. O exemplo a seguir mostra um exemplo de par de prompt e resposta:{"prompt": "What is Databricks?","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."}Uma tabela Delta que adere a um dos esquemas aceitos mencionados acima. Para tabelas Delta, você deve fornecer um
data_prep_cluster_idparâmetro para processamento de dados. Consulte Configurar uma execução de treinamento.Um conjunto de dados público do Hugging Face.
Se você usar um conjunto de dados público do Hugging Face como seus dados de treinamento, especifique o caminho completo com a divisão, por exemplo,
mosaicml/instruct-v3/train and mosaicml/instruct-v3/test. Isso conta para conjuntos de dados que têm esquemas de divisão diferentes. Não há suporte para conjuntos de dados aninhados do Hugging Face.Para um exemplo mais extenso, consulte o
mosaicml/dolly_hhrlhfconjunto de dados em Abraçando o rosto.As linhas de dados de exemplo a seguir são do
mosaicml/dolly_hhrlhfconjunto de dados.{"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: what is Databricks? ### Response: ","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."} {"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Van Halen famously banned what color M&Ms in their rider? ### Response: ","response": "Brown."}