Primeiros passos: aprimore e limpe dados
Este artigo de introdução orienta você pelo uso de um bloco de anotações do Azure Databricks para limpar e aprimorar os dados de nome de bebê do Estado de Nova York que foram carregados anteriormente em uma tabela no Catálogo Unity usando Python, Scala e R. Neste artigo, você altera nomes de coluna, altera maiúsculas e soletrar o sexo de cada nome de bebê na tabela de dados brutos - e, em seguida, salva o DataFrame em uma tabela prateada. Em seguida, você filtra os dados para incluir apenas os dados de 2021, agrupa os dados no nível estadual e, em seguida, classifica os dados por contagem. Finalmente, você salva esse DataFrame em uma tabela dourada e visualiza os dados em um gráfico de barras. Para obter mais informações sobre tabelas de prata e ouro, consulte arquitetura medalhão.
Importante
Este artigo de introdução baseia-se em Introdução: Ingerir e inserir dados adicionais. Você deve concluir as etapas nesse artigo para concluir este artigo. Para obter o bloco de anotações completo para esse artigo de introdução, consulte Ingerir blocos de anotações de dados adicionais.
Requisitos
Para concluir as tarefas neste artigo, você deve atender aos seguintes requisitos:
- Seu espaço de trabalho deve ter o Unity Catalog habilitado. Para obter informações sobre como começar a usar o Unity Catalog, consulte Configurar e gerenciar o Unity Catalog.
- Você deve ter o
WRITE VOLUMEprivilégio em um volume, oUSE SCHEMAprivilégio no esquema pai e oUSE CATALOGprivilégio no catálogo pai. - Você deve ter permissão para usar um recurso de computação existente ou criar um novo recurso de computação. Consulte Introdução: Configuração de conta e espaço de trabalho ou consulte o administrador do Databricks.
Gorjeta
Para obter um bloco de anotações completo para este artigo, consulte Limpar e aprimorar blocos de anotações de dados.
Etapa 1: Criar um novo bloco de anotações
Para criar um bloco de notas na sua área de trabalho, clique ![]() em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
Para saber mais sobre como criar e gerir blocos de notas, consulte Gerir blocos de notas.
Etapa 2: Definir variáveis
Nesta etapa, você define variáveis para uso no bloco de anotações de exemplo criado neste artigo.
Copie e cole o código a seguir na nova célula vazia do bloco de anotações. Substitua
<catalog-name>,<schema-name>e<volume-name>pelos nomes de catálogo, esquema e volume de um volume do Catálogo Unity. Opcionalmente, substitua otable_namevalor por um nome de tabela de sua escolha. Você salvará os dados do nome do bebê nesta tabela mais adiante neste artigo.Pressione
Shift+Enterpara executar a célula e criar uma nova célula em branco.Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Etapa 3: Carregar os dados brutos em um novo DataFrame
Esta etapa carrega os dados brutos salvos anteriormente em uma tabela Delta em um novo DataFrame em preparação para limpeza e aprimoramento desses dados para análise posterior.
Copie e cole o código a seguir na nova célula vazia do bloco de anotações.
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)Pressione
Shift+Enterpara executar a célula e, em seguida, vá para a próxima célula.
Etapa 4: Limpar e aprimorar dados brutos e salvar
Nesta etapa, você altera o nome da Year coluna, altera os dados na First_Name coluna para maiúsculas iniciais e atualiza os valores da Sex coluna para soletrar o sexo e, em seguida, salva o DataFrame em uma nova tabela.
Copie e cole o código a seguir em uma célula vazia do bloco de anotações.
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")Pressione
Shift+Enterpara executar a célula e, em seguida, vá para a próxima célula.
Etapa 5: agrupar e visualizar dados
Nesta etapa, você filtra os dados apenas para o ano de 2021, agrupa os dados por sexo e nome, agrega por contagem e ordena por contagem. Em seguida, salve o DataFrame em uma tabela e, em seguida, visualize os dados em um gráfico de barras.
Copie e cole o código a seguir em uma célula vazia do bloco de anotações.
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")Pressione
Ctrl+Enterpara executar a célula.-
- Ao lado da guia Tabela , clique em e, em + seguida, clique em Visualização.
No editor de visualização, clique em Tipo de Visualização e verifique se Barra está selecionada.
Na coluna X, selecione
First_Name.Clique em Adicionar coluna em Colunas Y e, em seguida, selecione Total_Count.
Em Agrupar por, selecione Sexo.
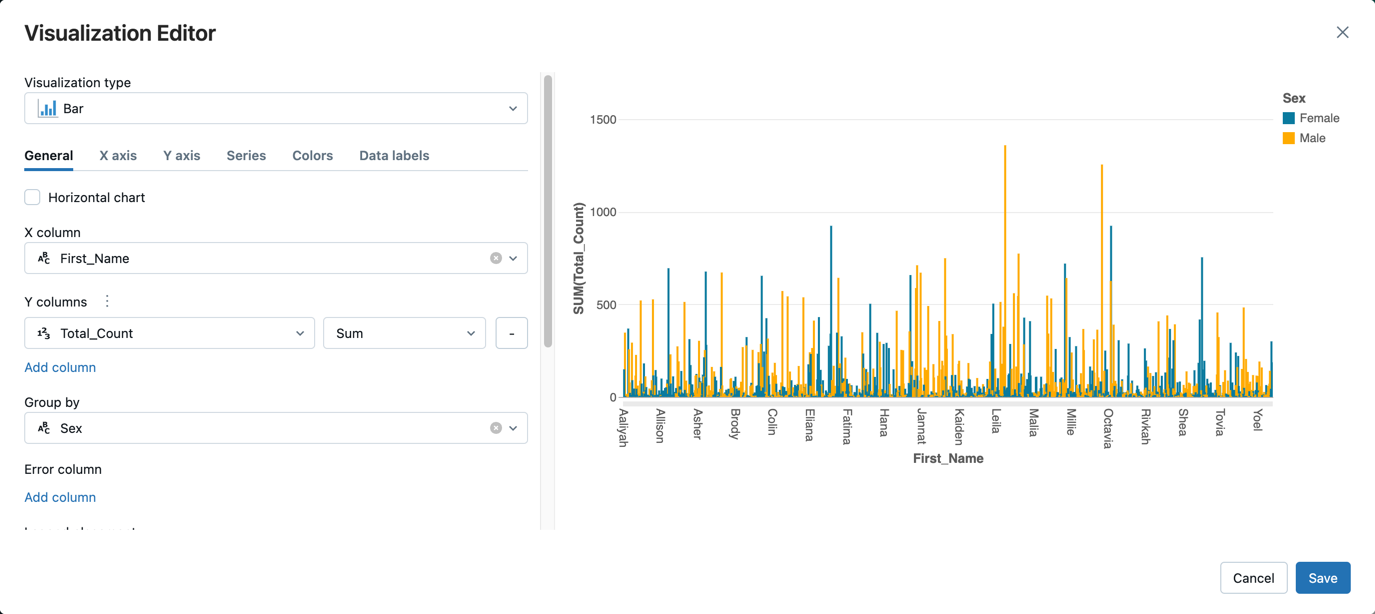
Clique em Guardar.
Limpe e aprimore blocos de anotações de dados
Use um dos seguintes blocos de anotações para executar as etapas neste artigo. Substitua <catalog-name>, <schema-name>e <volume-name> pelos nomes de catálogo, esquema e volume de um volume do Catálogo Unity. Opcionalmente, substitua o table_name valor por um nome de tabela de sua escolha.