O que é a arquitetura do medalhão lakehouse?
A arquitetura medalhão descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados na casa do lago. O Azure Databricks recomenda adotar uma abordagem em várias camadas para criar uma única fonte de verdade para produtos de dados corporativos.
Essa arquitetura garante atomicidade, consistência, isolamento e durabilidade à medida que os dados passam por várias camadas de validações e transformações antes de serem armazenados em um layout otimizado para análises eficientes. Os termos bronze (bruto), prata (validado) e ouro (enriquecido) descrevem a qualidade dos dados em cada uma dessas camadas.
Arquitetura Medallion como um padrão de design de dados
Uma arquitetura medallion é um padrão de design de dados usado para organizar dados logicamente. Seu objetivo é melhorar de forma incremental e progressiva a estrutura e a qualidade dos dados à medida que fluem através de cada camada da arquitetura (de Bronze ⇒ Prata ⇒ Ouro tables). As arquiteturas Medallion às vezes também são chamadas de arquiteturas multi-hop.
Ao progredir os dados através dessas camadas, as organizações podem melhorar incrementalmente a qualidade e a confiabilidade dos dados, tornando-os mais adequados para aplicativos de business intelligence e aprendizado de máquina.
Seguir a arquitetura medalhão é uma prática recomendada, mas não um requisito.
| Pergunta | Bronze | Silver | Gold |
|---|---|---|---|
| O que acontece nesta camada? | Ingestão de dados brutos | Limpeza e validação de dados | Modelação dimensional e agregação |
| Quem é o utilizador pretendido? | - Engenheiros de dados - Operações de dados - Equipas de compliance e auditoria |
- Engenheiros de dados - Analistas de dados (use a camada Silver para um conjunto de dados mais refinado que ainda retém informações detalhadas necessárias para uma análise aprofundada) - Cientistas de dados (construir modelos e realizar análises avançadas) |
- Analistas de negócios e desenvolvedores de BI - Cientistas de dados e engenheiros de machine learning (ML) - Executivos e decisores - Equipas operacionais |
Exemplo de arquitetura medalhão
Este exemplo de arquitetura de medalhão mostra camadas de bronze, prata e ouro para uso por uma equipe de operações de negócios. Cada camada é armazenada em uma schema diferente das operações catalog.
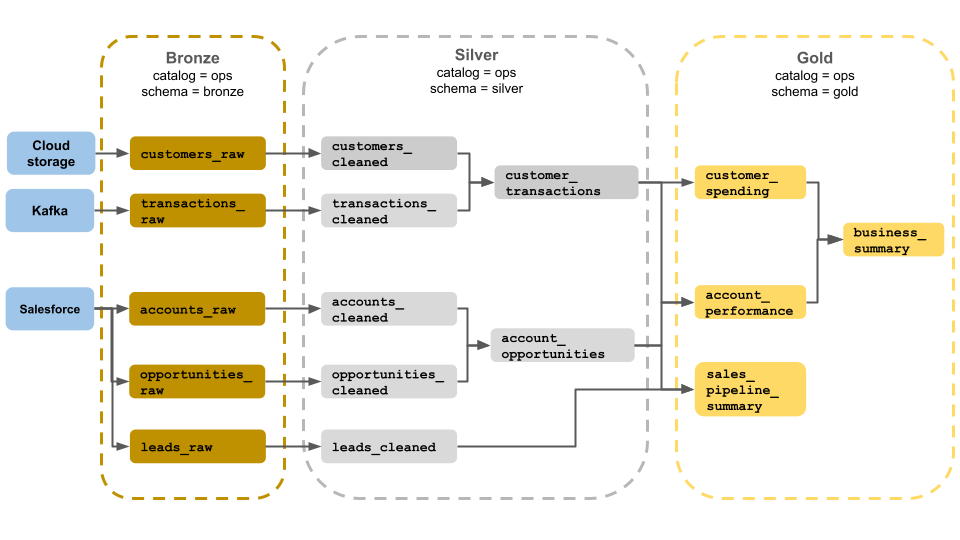
-
Camada bronze (
ops.bronze): Ingere dados brutos do armazenamento em nuvem, Kafka e Salesforce. Nenhuma limpeza ou validação de dados é realizada aqui. -
Camada prateada (
ops.silver): A limpeza e validação de dados são realizadas nesta camada.- Os dados sobre clientes e transações são limpos eliminando nulos e colocando em quarentena registros inválidos. Esses conjuntos de dados são unidos em um novo conjunto de dados chamado
customer_transactions. Os cientistas de dados podem usar esse conjunto de dados para análises preditivas. - Da mesma forma, contas e conjuntos de dados de oportunidade do Salesforce são unidos para criar
account_opportunitieso , que é aprimorado com informações de conta. - Os
leads_rawdados são limpos em um conjunto de dados chamadoleads_cleaned.
- Os dados sobre clientes e transações são limpos eliminando nulos e colocando em quarentena registros inválidos. Esses conjuntos de dados são unidos em um novo conjunto de dados chamado
-
Camada de ouro (
ops.gold): Esta camada foi concebida para utilizadores empresariais. Ele contém menos conjuntos de dados do que prata e ouro.-
customer_spending: Gasto médio e total para cada cliente. -
account_performance: Desempenho diário para cada conta. -
sales_pipeline_summary: Informações sobre o pipeline de vendas de ponta a ponta. -
business_summary: Informação altamente agregada para o pessoal executivo.
-
Ingerir dados brutos para a camada de bronze
A camada de bronze contém dados brutos e não validados. Os dados ingeridos na camada de bronze normalmente têm as seguintes características:
- Contém e mantém o estado bruto da fonte de dados em seus formatos originais.
- É anexado incrementalmente e cresce ao longo do tempo.
- Destina-se ao consumo por cargas de trabalho que enriquecem dados para tablesprata, não para acesso por analistas e cientistas de dados.
- Serve como a única fonte de verdade, preservando a fidelidade dos dados.
- Permite o reprocessamento e a auditoria, retendo todos os dados históricos.
- Pode ser qualquer combinação de streaming e transações em lote de fontes, incluindo armazenamento de objetos na nuvem (por exemplo, S3, GCS, ADLS), barramentos de mensagens (por exemplo, Kafka, Kinesis, etc.) e sistemas federados (por exemplo, Lakehouse Federation).
Limit limpeza ou validação de dados
A validação mínima dos dados é realizada na camada de bronze. Para garantir contra dados descartados, o Azure Databricks recomenda armazenar a maioria dos campos como string, VARIANT ou binário para proteger contra alterações inesperadas de schema. Metadados columns podem ser adicionados, como a proveniência ou a fonte dos dados (por exemplo, _metadata.file_name ).
Validar e desduplicar dados na camada prateada
A limpeza e validação de dados são realizadas em camada prateada.
Construa a prata tables a partir da camada de bronze
Para construir a camada de prata, leia os dados de uma ou mais tablesde bronze ou prata e escreva dados em tablesde prata.
O Azure Databricks não recomenda escrever em tables prata diretamente da ingestão. Se escreveres diretamente a partir da fase de ingestão, introduzirás falhas devido a alterações de schema ou a registos corrompidos nas fontes de dados. Supondo que todas as fontes sejam somente acréscimo, configure a maioria das leituras de bronze como leituras de streaming. As leituras em lote devem ser reservadas para pequenos conjuntos de dados (por exemplo, pequena dimensão tables).
A camada prateada representa versões validadas, limpas e enriquecidas dos dados. A camada de prata:
- Deve sempre incluir pelo menos uma representação validada e não agregada de cada registo. Se as representações agregadas gerarem muitas cargas de trabalho downstream, essas representações podem estar na camada prata, mas normalmente estão na camada ouro.
- Durante o where, você realiza a limpeza, a deduplicação e a normalização de dados.
- Melhora a qualidade dos dados corrigindo erros e inconsistências.
- Estrutura os dados em um formato mais consumível para processamento a jusante.
Reforçar a qualidade dos dados
As seguintes operações são realizadas em prata tables:
- Schema aplicação
- Tratamento de valores nulos e ausentes do values
- Eliminação de dados duplicados
- Resolução de problemas de dados fora de ordem e de chegada tardia
- Controlos da qualidade dos dados e aplicação da legislação
- Schema evolução
- Tipo de fundição
- Associações
Iniciar a modelagem de dados
É comum começar a executar a modelagem de dados na camada prateada, incluindo a escolha de como representar dados fortemente aninhados ou semiestruturados:
- Use
VARIANTo tipo de dados. - Use
JSONcadeias de caracteres. - Crie estruturas, mapas e matrizes.
- Nivele schema ou normalize os dados em várias tables.
Análise de energia com a camada ouro
A camada ouro representa a views altamente refinada dos dados que impulsionam análises subsequentes, painéis, aprendizagem automática e aplicações. Os dados da camada Gold geralmente são altamente agregados e filtrados para períodos de tempo específicos ou regiões geográficas. Ele contém conjuntos de dados semanticamente significativos que mapeiam para funções e necessidades de negócios.
A camada de ouro:
- Consiste em dados agregados adaptados para análises e relatórios.
- Alinha-se com a lógica e os requisitos de negócios.
- É otimizado para desempenho em consultas e painéis.
Alinhe-se com a lógica e os requisitos de negócios
A camada de ouro é where; modelará os seus dados para relatórios e análises usando um modelo dimensional, estabelecendo relacionamentos e definindo medidas. Os analistas com acesso a dados em ouro devem ser capazes de encontrar dados específicos do domínio e responder a perguntas.
Como a camada ouro modela um domínio de negócios, alguns clientes criam várias camadas de ouro para atender a diferentes necessidades de negócios, como RH, finanças e TI.
Crie agregados personalizados para análises e relatórios
As organizações geralmente precisam criar funções agregadas para medidas como médias, contagens, máximos e mínimos. Por exemplo, se sua empresa precisa responder a perguntas sobre vendas semanais totais, você pode criar uma visão materializada chamada weekly_sales que pré-agrega esses dados para que analistas e outros não precisem recriar viewsmaterializados usados com frequência.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimize para desempenho em consultas e painéis
A otimização da camada de ouro tables para desempenho é uma prática recomendada porque estes conjuntos de dados são interrogados com frequência. Grandes quantidades de dados históricos são normalmente acessadas na camada de lasca e não materializadas na camada de ouro.
Controle os custos ajustando a frequência de ingestão de dados
Controle os custos determinando a frequência com que os dados devem ser ingeridos.
| Frequência de ingestão de dados | Custo | Latência | Exemplos declarativos | Exemplos processuais |
|---|---|---|---|---|
| Ingestão incremental contínua | Mais alto | Lower | - Streaming Table, usando spark.readStream para ingestão a partir de armazenamento em nuvem ou barramento de mensagens.- O pipeline Delta Live Tables que atualiza este fluxo de streaming table é executado continuamente. - Código de Streaming estruturado usando spark.readStream num notebook para ingerir de armazenamento em nuvem ou barramento de mensagens para um tableDelta.- O bloco de anotações é orquestrado usando um trabalho do Azure Databricks com um gatilho de trabalho contínuo. |
|
| Ingestão incremental desencadeada | Lower | Mais alto | - Ingestão de streaming Table a partir do armazenamento em nuvem ou do barramento de mensagens usando spark.readStream.- A canalização que atualiza este fluxo de table é acionada pelo gatilho de agendamento do trabalho ou por um gatilho de chegada de ficheiro. - Estruturado código de Streaming em um notebook com um Trigger.Available gatilho.- Este notebook é acionado pelo gatilho programado do trabalho ou por um gatilho de chegada de arquivo. |
|
| Ingestão em lote com ingestão incremental manual | Lower | Maior, por causa de corridas pouco frequentes. | - Ingestão de streaming Table a partir de armazenamento na nuvem usando spark.read.- Não utiliza Streaming Estruturado. Em vez disso, use primitivos como partition substituir para update uma partition inteira de uma só vez. - Requer uma extensa arquitetura upstream para set o processamento incremental, o que permite um custo semelhante às leituras/gravações do Structured Streaming. - Também requer particionamento de dados de origem por um campo datetime e, em seguida, processamento de todos os registros desse partition para o destino. |