Configurar o AI Gateway em pontos de extremidade de serviço de modelo
Neste artigo, você aprenderá a configurar o Mosaic AI Gateway em um modelo de ponto de extremidade de serviço.
Requisitos
- Um espaço de trabalho Databricks em um modelos externos suportados região ou região de taxa de transferência provisionada suportada.
- Um modelo de ponto de extremidade de serviço.
- Para criar um ponto de extremidade para modelos externos, conclua as etapas 1 e 2 do Criar um modelo externo que atenda.
- Para criar um ponto de extremidade para desempenho provisionado, consulte APIs do Modelo de Fundação de Desempenho Provisionado.
Configurar o AI Gateway usando a interface do usuário
Esta seção mostra como configurar o AI Gateway durante a criação do endpoint usando a interface do usuário de serviço. Se preferir fazer isso programaticamente, consulte o exemplo do Bloco de Anotações.
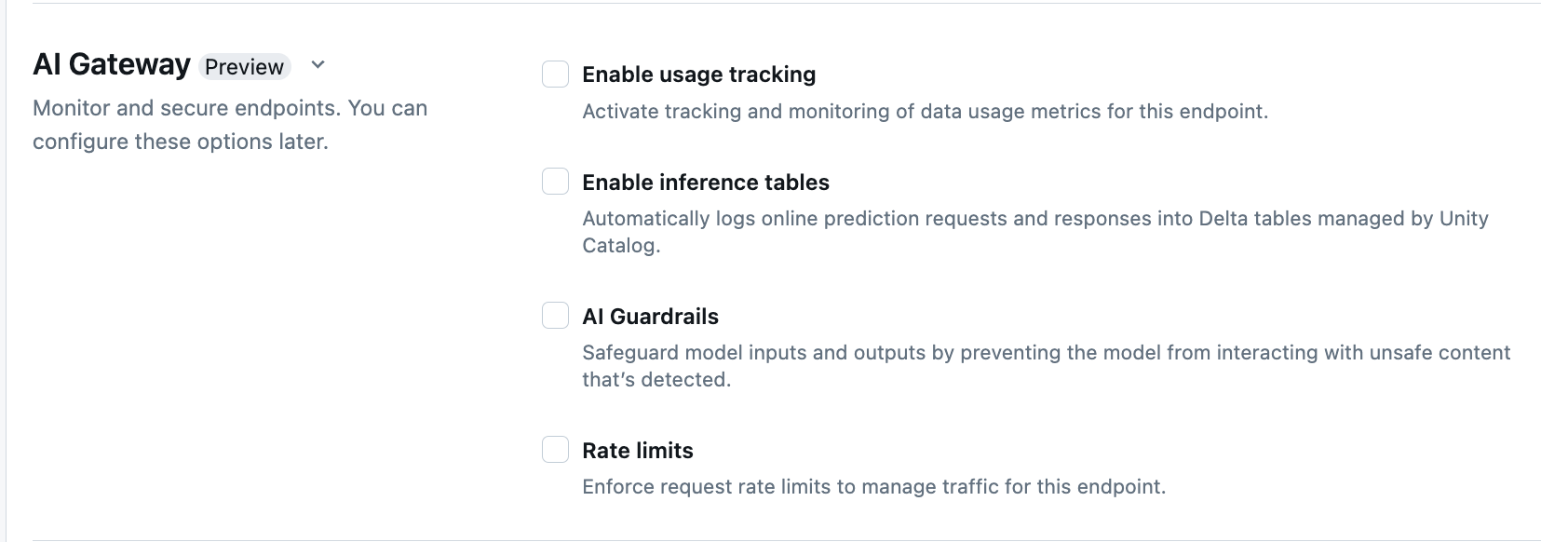
Na secção AI Gateway da página de criação de pontos finais, pode-se configurar individualmente as funcionalidades do AI Gateway. Consulte os Recursos suportados para saber quais funcionalidades estão disponíveis nos pontos de extremidade de serviço de modelo externo e nos pontos de extremidade de taxa de transferência provisionada.
| Caraterística | Como ativar | Detalhes |
|---|---|---|
| Controlo de utilização | Selecione Ativar controlo de utilização para permitir o rastreamento e monitorização de métricas de utilização de dados. | - Você deve ter o Unity Catalog ativado. - Os administradores de conta devem ativar o esquema de tabela do sistema de disponibilização antes de utilizar as tabelas do sistema: system.serving.endpoint_usage que captura contagens de tokens para cada pedido ao endpoint e system.serving.served_entities que armazena metadados para cada modelo fundacional.- Consulte os esquemas de tabelas de rastreamento de uso - Somente os administradores de contas têm permissão para visualizar ou consultar a tabela served_entities ou tabela endpoint_usage, ainda que o utilizador que gere o ponto de extremidade deva habilitar a monitorização de uso. Consulte Conceder acesso às tabelas do sistema- A contagem de tokens de entrada e saída é estimada como ( text_length+1)/4 se a contagem de tokens não for retornada pelo modelo. |
| Registo de carga útil | Selecione Ativar tabelas de inferência para registrar automaticamente solicitações e respostas do seu endpoint em tabelas Delta gerenciadas pelo Unity Catalog. | - Você deve ter o Unity Catalog habilitado e acesso CREATE_TABLE no esquema do catálogo especificado.- As tabelas de inferência habilitadas pelo AI Gateway têm um esquema diferente das tabelas de inferência criadas para endpoints de serviço de modelos que atendem a modelos personalizados. Consulte o esquema da tabela de inferência habilitado por "AI Gateway" - Os dados de log de carga útil preenchem essas tabelas menos de uma hora depois de consultar o ponto de extremidade. - Cargas maiores que 1 MB não são registradas. - A carga útil de resposta agrega a resposta de todas as partes retornadas. - Streaming é suportado. Em cenários de streaming, o conteúdo de resposta agrega a informação das partes retornadas. |
| AI Guardrails | Consulte Configurar guarda-corpos de IA na interface do usuário. | - Os guarda-corpos impedem que o modelo interaja com conteúdo inseguro e prejudicial que é detetado nas entradas e saídas do modelo. - Guarda-corpos de saída não são suportados para modelos de incorporação ou para streaming. |
| Limites de taxa | Você pode impor limites de taxa de solicitação para gerenciar o tráfego do seu endpoint por usuário e por ponto final | - Os limites de taxa são definidos em consultas por minuto (QPM). - O valor padrão é Sem limite por utilizador e por endpoint. |
| Roteamento de tráfego | Para configurar o roteamento de tráfego em seu ponto de extremidade, consulte Servir vários modelos externos a um ponto de extremidade. |
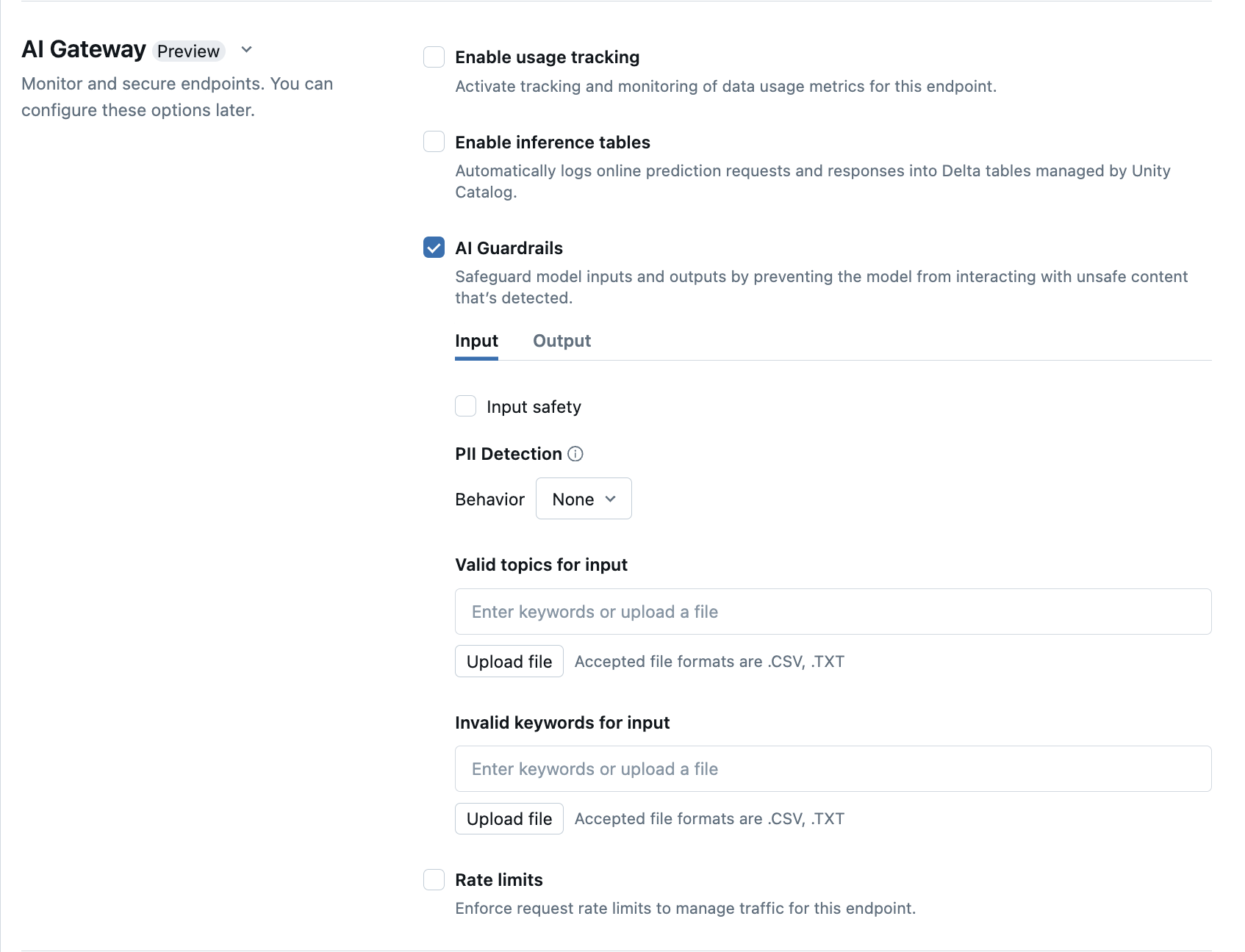
Configurar guarda-corpos de IA na interface do usuário
A tabela a seguir mostra como configurar guarda-corpos suportados.
| Guarda-corpo | Como ativar | Detalhes |
|---|---|---|
| Segurança | Selecione de segurança para ativar as proteções para impedir que seu modelo interaja com conteúdo inseguro e prejudicial. | |
| Deteção de informações de identificação pessoal (PII) | Selecione para deteção de PII para detetar dados de PII, como nomes, endereços e números de cartão de crédito. | |
| Tópicos válidos | Você pode digitar tópicos diretamente neste campo. Se você tiver várias entradas, certifique-se de pressionar enter após cada tópico. Em alternativa, pode carregar um .csv ficheiro OR .txt . |
É possível especificar um máximo de 50 tópicos válidos. Cada tópico não pode exceder 100 caracteres |
| Palavras-chave inválidas | Você pode digitar tópicos diretamente neste campo. Se você tiver várias entradas, certifique-se de pressionar enter após cada tópico. Em alternativa, pode carregar um .csv ficheiro OR .txt . |
Um máximo de 50 palavras-chave inválidas podem ser especificadas. Cada palavra-chave não pode exceder 100 caracteres. |
Esquemas de tabela de controle de uso
A tabela do sistema de controle de uso system.serving.served_entities tem o seguinte esquema:
| Nome da coluna | Description | Type |
|---|---|---|
served_entity_id |
O ID exclusivo da entidade atendida. | STRING |
account_id |
O ID da conta de cliente para o Delta Sharing. | STRING |
workspace_id |
O ID do espaço de trabalho do cliente do ponto de extremidade de serviço. | STRING |
created_by |
O ID do criador. | STRING |
endpoint_name |
O nome do ponto de extremidade de serviço. | STRING |
endpoint_id |
A ID exclusiva do ponto de extremidade de serviço. | STRING |
served_entity_name |
O nome da entidade atendida. | STRING |
entity_type |
Tipo da entidade que é atendida. Pode ser FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL, ou CUSTOM_MODEL |
STRING |
entity_name |
O nome subjacente da entidade. Diferente do served_entity_name que é um nome fornecido pelo usuário. Por exemplo, entity_name é o nome do modelo Unity Catalog. |
STRING |
entity_version |
A versão da entidade atendida. | STRING |
endpoint_config_version |
A versão da configuração do ponto de extremidade. | INT |
task |
O tipo de tarefa. Pode ser llm/v1/chat, llm/v1/completions, ou llm/v1/embeddings. |
STRING |
external_model_config |
Configurações para modelos externos. Por exemplo, {Provider: OpenAI} |
ESTRUTURA |
foundation_model_config |
Configurações para modelos de fundação. Por exemplo{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
ESTRUTURA |
custom_model_config |
Configurações para modelos personalizados. Por exemplo{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
ESTRUTURA |
feature_spec_config |
Configurações para especificações de recursos. Por exemplo, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
ESTRUTURA |
change_time |
Carimbo de data/hora da alteração para a entidade atendida. | CARIMBO DE DATA/HORA |
endpoint_delete_time |
Carimbo de data/hora da exclusão da entidade. O ponto de extremidade é o contêiner para a entidade atendida. Depois que o ponto de extremidade é excluído, a entidade atendida também é excluída. | CARIMBO DE DATA/HORA |
A tabela do sistema de controle de uso system.serving.endpoint_usage tem o seguinte esquema:
| Nome da coluna | Description | Type |
|---|---|---|
account_id |
O ID da conta de cliente. | STRING |
workspace_id |
A ID do espaço de trabalho do cliente do ponto de extremidade de serviço. | STRING |
client_request_id |
O usuário forneceu o identificador de solicitação que pode ser especificado no corpo da solicitação de serviço do modelo. | STRING |
databricks_request_id |
Um identificador de solicitação gerado pelo Azure Databricks anexado a todas as solicitações de serviço de modelo. | STRING |
requester |
A ID do usuário ou entidade de serviço cujas permissões são usadas para a solicitação de invocação do ponto de extremidade de serviço. | STRING |
status_code |
O código de status HTTP que foi retornado do modelo. | INTEIRO |
request_time |
O carimbo de data/hora no qual a solicitação é recebida. | CARIMBO DE DATA/HORA |
input_token_count |
A contagem de tokens da entrada. | LONGO |
output_token_count |
A contagem de tokens da saída. | LONGO |
input_character_count |
A contagem de caracteres da cadeia de caracteres de entrada ou prompt. | LONGO |
output_character_count |
A contagem de caracteres da cadeia de caracteres de saída da resposta. | LONGO |
usage_context |
O usuário forneceu um mapa contendo identificadores do usuário final ou do aplicativo do cliente que faz a chamada para o ponto de extremidade. Consulte Definir melhor o uso com usage_context. | MAPA |
request_streaming |
Se a solicitação está no modo de fluxo. | BOOLEANO |
served_entity_id |
O ID exclusivo usado para associar à tabela de dimensão system.serving.served_entities para procurar informações sobre o endpoint e a entidade servida. |
STRING |
Defina melhor o uso com usage_context
Ao consultar um modelo externo com o controle de uso habilitado, você pode fornecer o parâmetro com o usage_context tipo Map[String, String]. O mapeamento de contexto de uso aparece na tabela de controle de uso na coluna usage_context. O tamanho do usage_context mapa não pode exceder 10 KiB.
Os administradores de conta podem agregar diferentes linhas com base no contexto de uso para obter informações e podem unir essas informações com as informações na tabela de registro de carga útil. Por exemplo, você pode adicionar end_user_to_charge ao para rastrear a usage_context atribuição de custos para usuários finais.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Atualizar funcionalidades do AI Gateway nos endpoints
Você pode atualizar as funções do AI Gateway nos pontos de extremidade de serviço de modelo que tinham essas funções habilitadas anteriormente e nos pontos de extremidade que não tinham. As atualizações das configurações do AI Gateway levam cerca de 20 a 40 segundos para serem aplicadas, no entanto, as atualizações de limitação de taxa podem levar até 60 segundos.
A seguir mostra como atualizar os recursos do AI Gateway em um modelo de ponto de extremidade de serviço usando a interface do usuário de serviço.
Na seção Gateway da página do ponto de extremidade, você pode ver quais recursos estão habilitados. Para atualizar esses recursos, clique em Editar o Gateway de IA.

Exemplo de bloco de notas
O bloco de anotações a seguir mostra como habilitar e usar programaticamente os recursos do Databricks Mosaic AI Gateway para gerenciar e controlar modelos de provedores. Consulte o seguinte para obter detalhes da API REST: