Práticas recomendadas para gravar em arquivos no data lake com fluxos de dados
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Se não estiver familiarizado com o Azure Data Factory, veja Introdução ao Azure Data Factory.
Neste tutorial, você aprenderá as práticas recomendadas que podem ser aplicadas ao gravar arquivos no ADLS Gen2 ou no Armazenamento de Blobs do Azure usando fluxos de dados. Você precisará acessar uma Conta de Armazenamento de Blob do Azure ou uma conta Gen2 do Repositório Azure Data Lake para ler um arquivo de parquet e, em seguida, armazenar os resultados em pastas.
Pré-requisitos
- Subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta do Azure gratuita antes de começar.
- Conta de armazenamento do Azure. Você usa o armazenamento ADLS como fonte e armazena dados de coletor. Se não tiver uma conta de armazenamento, veja Criar uma conta de armazenamento do Azure para seguir os passos para criar uma.
As etapas neste tutorial assumirão que você tem
Criar uma fábrica de dados
Nesta etapa, você cria um data factory e abre o Data Factory UX para criar um pipeline no data factory.
Abra o Microsoft Edge ou o Google Chrome. Atualmente, a interface do usuário do Data Factory é suportada apenas nos navegadores Microsoft Edge e Google Chrome.
No menu à esquerda, selecione Criar um recurso>Integration>Data Factory
Na página Novo data factory, em Nome, insira ADFTutorialDataFactory
Selecione a subscrição do Azure na qual quer criar a fábrica de dados.
Em Grupo de Recursos, efetue um destes passos:
a. Selecione Utilizar existente e selecione um grupo de recursos já existente na lista pendente.
b. Selecione Criar novo e insira o nome de um grupo de recursos. Para saber mais sobre grupos de recursos, consulte Usar grupos de recursos para gerenciar seus recursos do Azure.
Em Versão, selecione V2.
Em Localização, selecione uma localização para a fábrica de dados. Só aparecem na lista pendente as localizações que são suportadas. Os armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e os cálculos (por exemplo, Azure HDInsight) usados pelo data factory podem estar em outras regiões.
Selecione Criar.
Após a conclusão da criação, você verá o aviso na Central de notificações. Selecione Ir para o recurso para navegar até a página Data factory.
Selecione Criar e Monitorizar para iniciar a IU do Data Factory num separador à parte.
Criar um pipeline com uma atividade de fluxo de dados
Nesta etapa, você criará um pipeline que contém uma atividade de fluxo de dados.
Na home page do Azure Data Factory, selecione Orquestrar.
Na guia Geral do pipeline, digite DeltaLake para Nome do pipeline.
Na barra superior de fábrica, deslize o controle deslizante de depuração do Fluxo de Dados. O modo de depuração permite testes interativos da lógica de transformação em um cluster Spark ao vivo. Os clusters de Fluxo de Dados levam de 5 a 7 minutos para aquecer e os usuários são recomendados a ativar a depuração primeiro se planejarem fazer o desenvolvimento do Fluxo de Dados. Para obter mais informações, consulte Modo de depuração.

No painel Atividades, expanda o acordeão Mover e Transformar. Arraste e solte a atividade Fluxo de Dados do painel para a tela do pipeline.
No pop-up Adicionando fluxo de dados, selecione Criar novo fluxo de dados e, em seguida, nomeie seu fluxo de dados como DeltaLake. Clique em Concluir quando terminar.
Criar lógica de transformação na tela de fluxo de dados
Você pegará todos os dados de origem (neste tutorial, usaremos uma fonte de arquivo Parquet) e usará uma transformação de coletor para pousar os dados no formato Parquet usando os mecanismos mais eficazes para ETL de data lake.

Objetivos do tutorial
- Escolha qualquer um dos seus conjuntos de dados de origem em um novo fluxo de dados 1. Use fluxos de dados para particionar efetivamente seu conjunto de dados do coletor
- Coloque seus dados particionados em pastas do lago ADLS Gen2
Iniciar a partir de uma tela de fluxo de dados em branco
Primeiro, vamos configurar o ambiente de fluxo de dados para cada um dos mecanismos descritos abaixo para dados de aterrissagem no ADLS Gen2
- Clique na transformação de origem.
- Clique no novo botão ao lado do conjunto de dados no painel inferior.
- Escolha um conjunto de dados ou crie um novo. Para esta demonstração, usaremos um conjunto de dados do Parquet chamado Dados do Usuário.
- Adicione uma transformação de coluna derivada. Usaremos isso como uma maneira de definir os nomes das pastas desejadas dinamicamente.
- Adicione uma transformação de coletor.
Saída de pasta hierárquica
É muito comum usar valores exclusivos em seus dados para criar hierarquias de pasta para particionar seus dados no lago. Esta é uma maneira muito ideal de organizar e processar dados no lago e no Spark (o mecanismo de computação por trás dos fluxos de dados). No entanto, haverá um pequeno custo de desempenho para organizar sua saída dessa maneira. Espere ver uma pequena diminuição no desempenho geral do pipeline usando esse mecanismo no coletor.
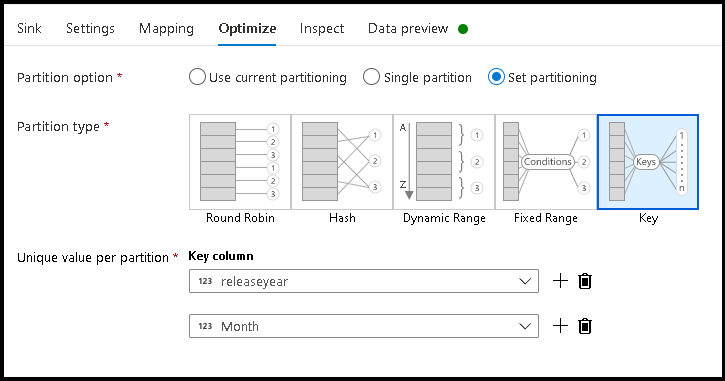
- Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima. Clique na transformação do coletor.
- Clique em Otimizar > Definir Chave de Particionamento >
- Escolha a(s) coluna(s) que deseja usar para definir sua estrutura hierárquica de pastas.
- Observe que o exemplo abaixo usa ano e mês como as colunas para nomeação de pastas. Os resultados serão pastas do formulário
releaseyear=1990/month=8. - Ao acessar as partições de dados em uma fonte de fluxo de dados, você apontará apenas para a pasta de nível superior acima
releaseyeare usará um padrão curinga para cada pasta subsequente, por exemplo:**/**/*.parquet - Para manipular os valores de dados, ou mesmo se precisar gerar valores sintéticos para nomes de pastas, use a transformação Coluna Derivada para criar os valores que você deseja usar em seus nomes de pasta.
Pasta de nomes como valores de dados
Uma técnica de coletor de desempenho ligeiramente melhor para dados de lago usando ADLS Gen2 que não oferece o mesmo benefício que o particionamento de chave/valor é Name folder as column data. Enquanto o estilo de particionamento de chave da estrutura hierárquica permitirá que você processe fatias de dados mais facilmente, essa técnica é uma estrutura de pastas nivelada que pode gravar dados mais rapidamente.
- Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima. Clique na transformação do coletor.
- Clique em Otimizar > conjunto de particionamento Usar particionamento > atual.
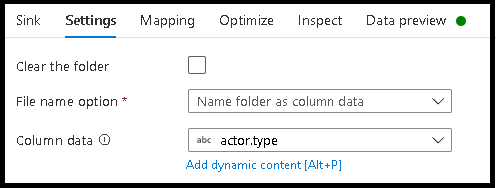
- Clique na pasta Nome das Configurações > como dados da coluna.
- Escolha a coluna que você deseja usar para gerar nomes de pastas.
- Para manipular os valores de dados, ou mesmo se precisar gerar valores sintéticos para nomes de pastas, use a transformação Coluna Derivada para criar os valores que você deseja usar em seus nomes de pasta.
Arquivo de nome como valores de dados
As técnicas listadas nos tutoriais acima são bons casos de uso para criar categorias de pastas em seu data lake. O esquema de nomenclatura de arquivo padrão que está sendo empregado por essas técnicas é usar o ID de trabalho do executor do Spark. Às vezes, você pode querer definir o nome do arquivo de saída em um coletor de texto de fluxo de dados. Esta técnica só é sugerida para uso com arquivos pequenos. O processo de mesclar arquivos de partição em um único arquivo de saída é um processo de longa execução.
- Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima. Clique na transformação do coletor.
- Clique em Otimizar > conjunto de particionamento Partição > única. É esse requisito de partição única que cria um gargalo no processo de execução à medida que os arquivos são mesclados. Esta opção só é recomendada para ficheiros pequenos.
- Clique em Configurações > Arquivo de nome como dados de coluna.
- Escolha a coluna que você deseja usar para gerar nomes de arquivo.
- Para manipular os valores de dados, ou mesmo se precisar gerar valores sintéticos para nomes de arquivo, use a transformação Coluna Derivada para criar os valores que você deseja usar em seus nomes de arquivo.
Conteúdos relacionados
Saiba mais sobre coletores de fluxo de dados.