Transforme dados no lago delta usando fluxos de dados de mapeamento
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Se não estiver familiarizado com o Azure Data Factory, veja Introdução ao Azure Data Factory.
Neste tutorial, você usa a tela de fluxo de dados para criar fluxos de dados que permitem analisar e transformar dados no Azure Data Lake Storage (ADLS) Gen2 e armazená-los no Delta Lake.
Pré-requisitos
- Subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta do Azure gratuita antes de começar.
- Conta de armazenamento do Azure. Você usa o armazenamento ADLS como fonte e armazena dados de coletor. Se não tiver uma conta de armazenamento, veja Criar uma conta de armazenamento do Azure para seguir os passos para criar uma.
O arquivo que estamos transformando neste tutorial é MoviesDB.csv, que pode ser encontrado aqui. Para recuperar o arquivo do GitHub, copie o conteúdo para um editor de texto de sua escolha para salvar localmente como um arquivo .csv. Para carregar o ficheiro para a sua conta de armazenamento, consulte Carregar blobs com o portal do Azure. Os exemplos fazem referência a um contêiner chamado 'sample-data'.
Criar uma fábrica de dados
Nesta etapa, você cria um data factory e abre o Data Factory UX para criar um pipeline no data factory.
Abra o Microsoft Edge ou o Google Chrome. Atualmente, a interface do usuário do Data Factory é suportada apenas nos navegadores Microsoft Edge e Google Chrome.
No menu à esquerda, selecione Criar um recurso>Integration>Data Factory
Na página Novo data factory, em Nome, insira ADFTutorialDataFactory
Selecione a subscrição do Azure na qual quer criar a fábrica de dados.
Em Grupo de Recursos, efetue um destes passos:
a. Selecione Utilizar existente e selecione um grupo de recursos já existente na lista pendente.
b. Selecione Criar novo e introduza o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, veja Utilizar grupos de recursos para gerir os recursos do Azure.
Em Versão, selecione V2.
Em Localização, selecione uma localização para a fábrica de dados. Só aparecem na lista pendente as localizações que são suportadas. Os armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e os cálculos (por exemplo, Azure HDInsight) usados pelo data factory podem estar em outras regiões.
Selecione Criar.
Após a conclusão da criação, você verá o aviso na Central de notificações. Selecione Ir para o recurso para navegar até a página Data factory.
Selecione Criar e Monitorizar para iniciar a IU do Data Factory num separador à parte.
Criar um pipeline com uma atividade de fluxo de dados
Nesta etapa, você cria um pipeline que contém uma atividade de fluxo de dados.
Na página inicial, selecione Orquestrar.
Na guia Geral do pipeline, digite DeltaLake para Nome do pipeline.
No painel Atividades, expanda o acordeão Mover e Transformar. Arraste e solte a atividade Fluxo de Dados do painel para a tela do pipeline.
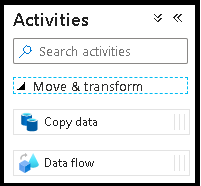
No pop-up Adicionando fluxo de dados, selecione Criar novo fluxo de dados e, em seguida, nomeie seu fluxo de dados como DeltaLake. Selecione Concluir quando terminar.
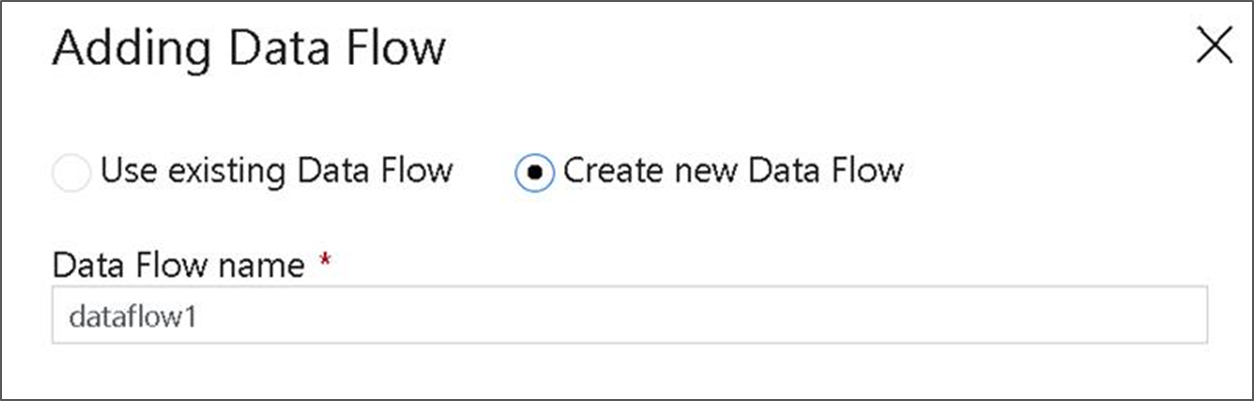
Na barra superior da tela do pipeline, deslize o controle deslizante de depuração do Fluxo de Dados. O modo de depuração permite testes interativos da lógica de transformação em um cluster Spark ao vivo. Os clusters de Fluxo de Dados levam de 5 a 7 minutos para aquecer e os usuários são recomendados a ativar a depuração primeiro se planejarem fazer o desenvolvimento do Fluxo de Dados. Para obter mais informações, consulte Modo de depuração.

Criar lógica de transformação na tela de fluxo de dados
Você gera dois fluxos de dados neste tutorial. O primeiro fluxo de dados é uma fonte simples de afundar para gerar um novo Delta Lake a partir do arquivo CSV de filmes. Por fim, você cria o design de fluxo a seguir para atualizar os dados no Delta Lake.

Objetivos do tutorial
- Use a fonte do conjunto de dados MoviesCSV a partir dos pré-requisitos e forme um novo Delta Lake a partir dela.
- Construa a lógica para atualizar as classificações dos filmes de 1988 para '1'.
- Exclua todos os filmes de 1950.
- Insira novos filmes para 2021 duplicando os filmes de 1960.
Iniciar a partir de uma tela de fluxo de dados em branco
Selecione a transformação de origem na parte superior da janela do editor de fluxo de dados e, em seguida, selecione + Novo ao lado da propriedade Dataset na janela Configurações de origem:
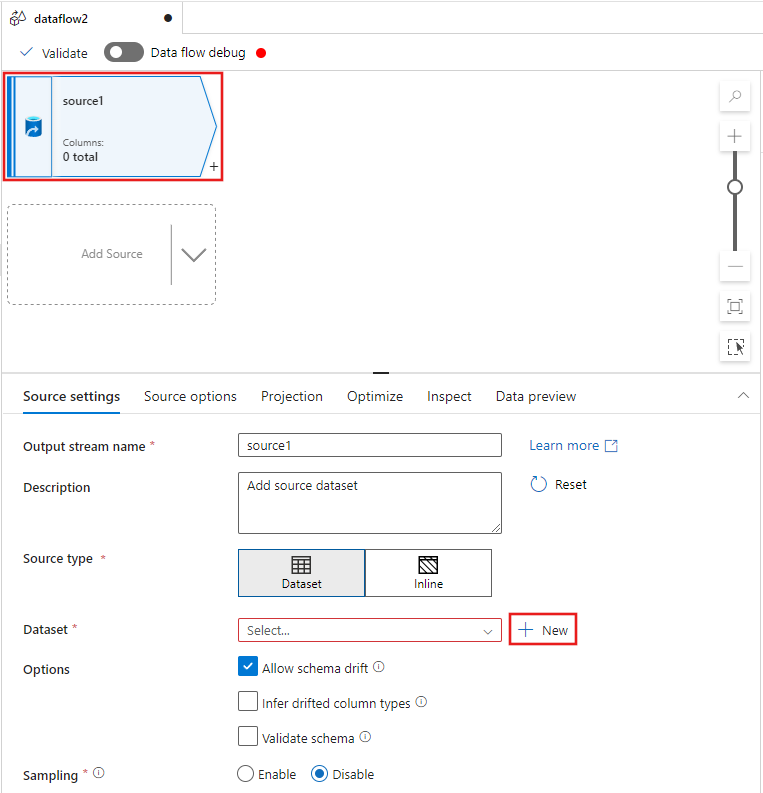
Selecione Azure Data Lake Storage Gen2 na janela Novo conjunto de dados exibida e selecione Continuar.
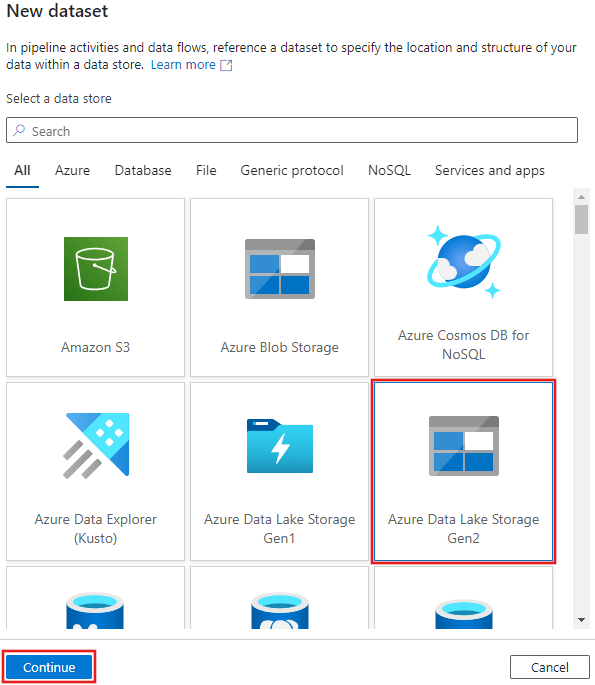
Escolha DelimitedText para o tipo de conjunto de dados e selecione Continuar novamente.

Nomeie o conjunto de dados "MoviesCSV" e selecione + Novo em Serviço vinculado para criar um novo serviço vinculado ao arquivo.
Forneça os detalhes da sua conta de armazenamento criada anteriormente na seção Pré-requisitos e procure e selecione o arquivo MoviesCSV que você carregou lá.
Depois de adicionar o serviço vinculado, marque a caixa de seleção Primeira linha como cabeçalho e selecione OK para adicionar a fonte.
Navegue até a guia Projeção da janela de configurações de fluxo de dados e selecione Detetar tipos de dados.
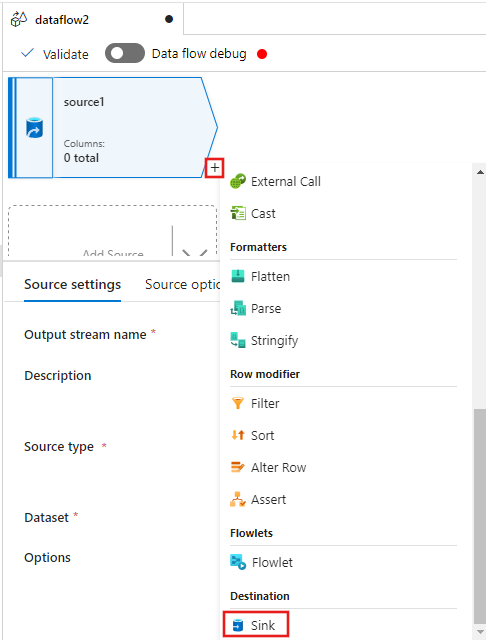
Agora, selecione o + depois da Origem na janela do editor de fluxo de dados e role para baixo até selecionar Coletor na seção Destino , adicionando um novo coletor ao seu fluxo de dados.
Na guia Coletor para as configurações do coletor que aparecem depois que o coletor é adicionado, selecione Inline para o tipo de coletor e, em seguida, Delta para o tipo de conjunto de dados embutido. Em seguida, selecione seu Azure Data Lake Storage Gen2 para o serviço vinculado.
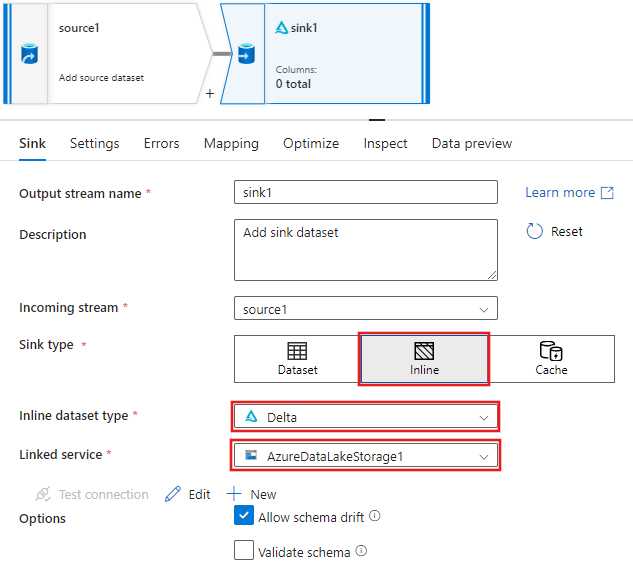
Escolha um nome de pasta em seu contêiner de armazenamento onde você gostaria que o serviço criasse o Delta Lake.
Finalmente, navegue de volta pelo designer de pipeline e selecione Depurar para executar o pipeline no modo de depuração apenas com essa atividade de fluxo de dados na tela. Isso gera seu novo Delta Lake no Azure Data Lake Storage Gen2.
Agora, no menu Recursos de fábrica à esquerda da tela, selecione + para adicionar um novo recurso e, em seguida, selecione Fluxo de dados.
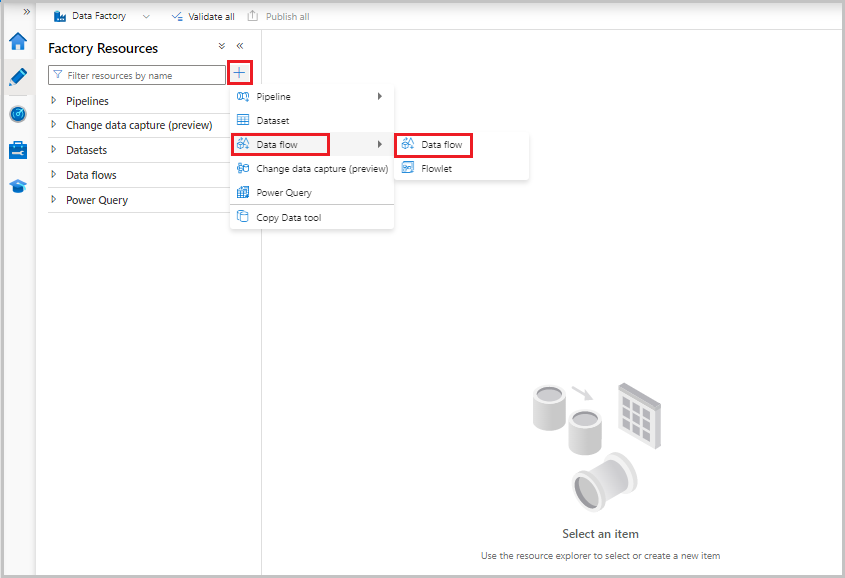
Como anteriormente, selecione o arquivo MoviesCSV novamente como fonte e, em seguida, selecione Detetar tipos de dados novamente na guia Projeção .
Desta vez, depois de criar a fonte, selecione a + na janela do editor de fluxo de dados e adicione uma transformação Filter à sua fonte.
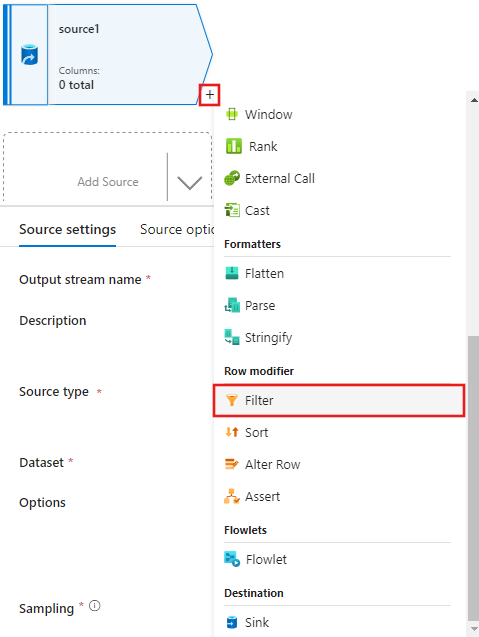
Adicione um Filtro na condição na janela Configurações de filtro que permita apenas linhas de filme correspondentes a 1950, 1960 e 1988.
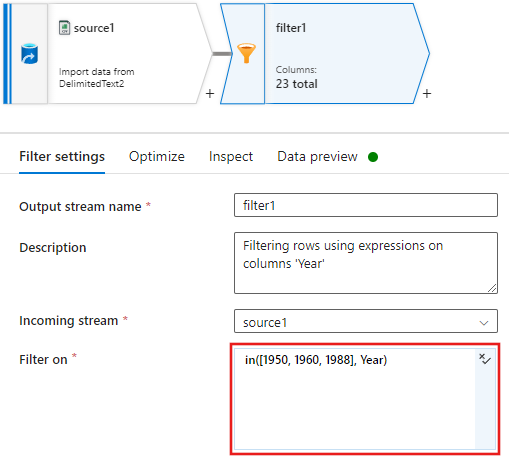
Agora, adicione uma transformação de coluna derivada para atualizar as classificações de cada filme de 1988 para '1'.
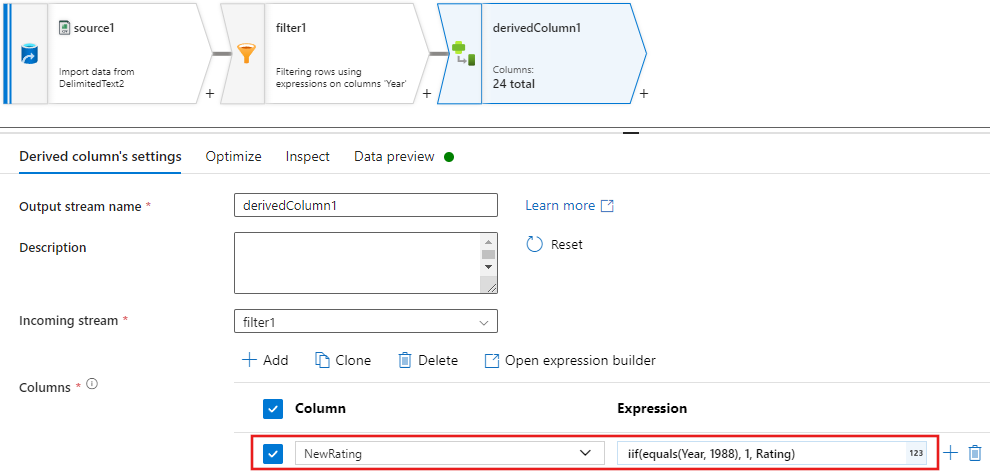
Update, insert, delete, and upsertas políticas são criadas na transformação alter Row. Adicione uma transformação de linha alter após a coluna derivada.Suas políticas de linha de alteração devem ter esta aparência.

Agora que você definiu a política adequada para cada tipo de linha de alteração, verifique se as regras de atualização adequadas foram definidas na transformação do coletor
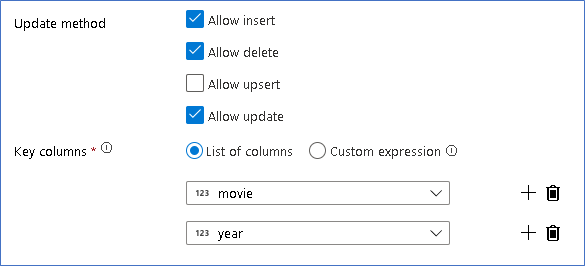
Aqui estamos usando o coletor Delta Lake para seu data lake do Azure Data Lake Storage Gen2 e permitindo inserções, atualizações e exclusões.
Observe que as colunas de chave são uma chave composta composta pela coluna Chave primária do filme e pela coluna do ano. Isso porque criamos filmes falsos de 2021 duplicando as linhas de 1960. Isso evita colisões ao procurar as linhas existentes, fornecendo exclusividade.
Download de amostra concluída
Aqui está uma solução de exemplo para o pipeline Delta com um fluxo de dados para linhas de atualização/exclusão no lago.
Conteúdos relacionados
Saiba mais sobre a linguagem de expressão de fluxo de dados.